






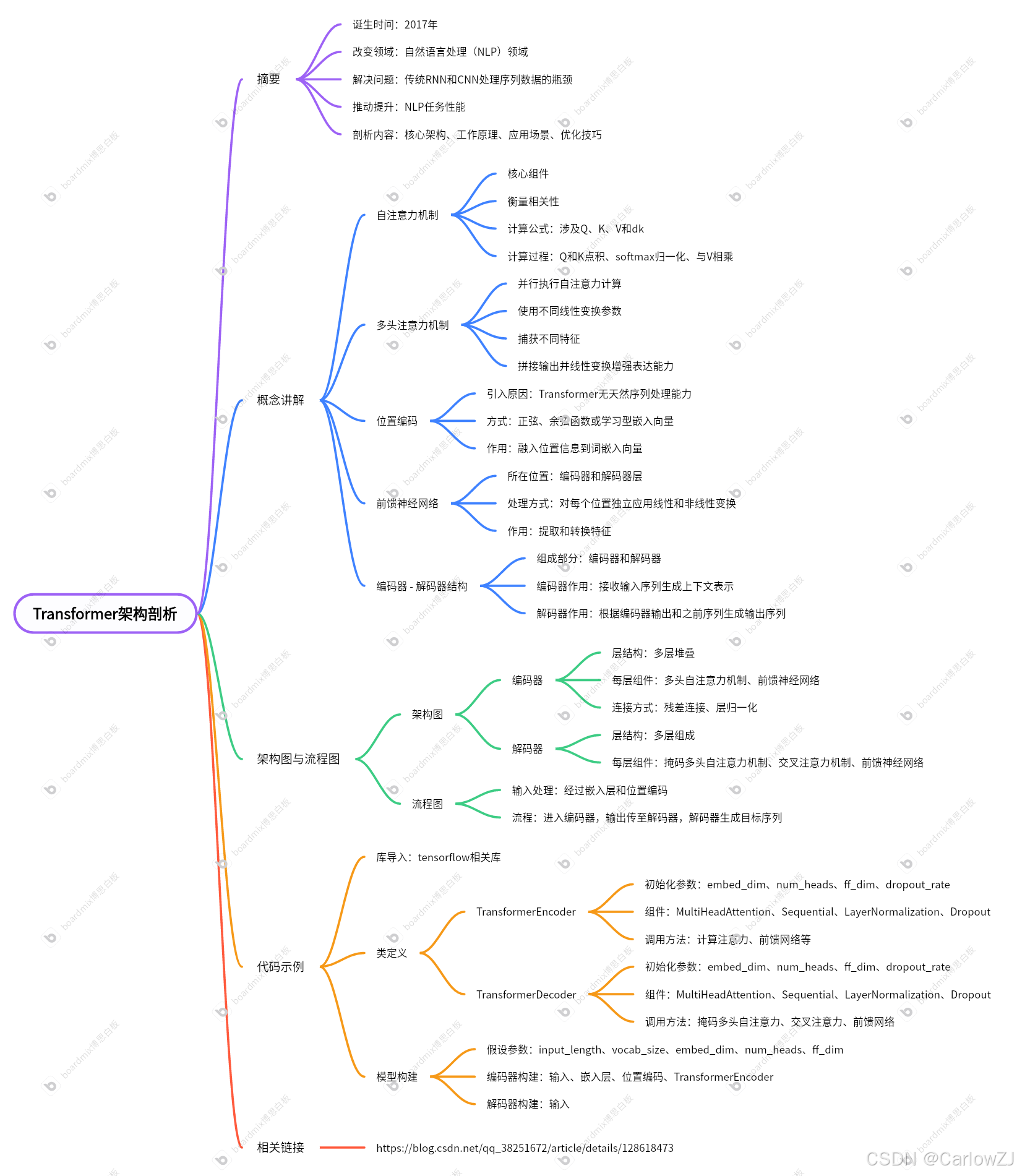
目录
摘要
Transformer 架构自 2017 年诞生以来,彻底改变了自然语言处理(NLP)领域。它以独特的自注意力机制(Self-Attention)和并行计算能力,解决了传统 RNN 和 CNN 在处理序列数据时的诸多瓶颈问题,推动了机器翻译、文本生成、情感分析等 NLP 任务的性能大幅提升。本文将深入剖析 Transformer 的核心架构、工作原理、应用场景以及优化技巧,旨在为读者呈现 Transformer 的全貌,助力读者在 NLP 领域的探索之旅。
一、概念讲解
(一)自注意力机制
自注意力机制是 Transformer 的核心组件。它衡量序列中每个词与其他词的相关性,从而决定每个词的表示应关注序列中的哪些部分。计算公式如下:
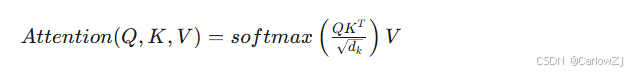
其中,Q(Query)、K(Key)、V(Value)是输入矩阵经过线性变换后的结果,dk 是 K 的维度。通过计算 Q 和 K 的点积,得到每个词对的注意力分数,再经过 softmax 归一化后与 V 相乘,得到最终的输出。
(二)多头注意力机制
多头注意力机制将自注意力计算并行执行多次,每次使用不同的线性变换参数,从而捕获序列中不同位置、不同语义层面的特征。多个自注意力输出拼接后进行线性变换,增强模型的表达能力。
(三)位置编码
由于 Transformer 不具备像 RNN 那样的天然序列处理能力,因此需要引入位置编码来为模型提供词的位置信息。位置编码可以采用正弦、余弦函数或者学习型嵌入向量的方式,将位置信息融入到词的嵌入向量中。
(四)前馈神经网络
每个 Transformer 编码器和解码器层都包含一个前馈神经网络。它对序列中的每个位置独立应用相同的线性变换和非线性激活函数,进一步提取和转换特征。
(五)编码器 - 解码器结构
Transformer 由编码器和解码器两部分组成。编码器接收输入序列并生成上下文表示,解码器根据编码器输出和之前生成的序列逐步生成输出序列。
二、架构图与流程图
(一)架构图
编码器由多个相同的层堆叠而成,每层包含多头自注意力机制和前馈神经网络,层与层之间采用残差连接和层归一化。解码器同样由多层组成,每层包含掩码多头自注意力机制、交叉注意力机制和前馈神经网络。
(二)流程图
输入序列经过嵌入层和位置编码后,进入编码器。编码器的输出传递给解码器,解码器结合编码器输出和之前生成的序列,逐步生成目标序列。
三、代码示例
以下是一个简单的 Transformer 实现代码示例:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, MultiHeadAttention, Dense, Dropout, LayerNormalization
from tensorflow.keras.models import Model
class TransformerEncoder(tf.keras.layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, dropout_rate=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.ff_dim = ff_dim
self.dropout_rate = dropout_rate
self.attention = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = tf.keras.Sequential([
Dense(ff_dim, activation='relu'),
Dense(embed_dim)
])
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(dropout_rate)
self.dropout2 = Dropout(dropout_rate)
def call(self, inputs, training=False):
attention_output = self.attention(inputs, inputs)
attention_output = self.dropout1(attention_output, training=training)
out1 = self.layernorm1(inputs + attention_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
class TransformerDecoder(tf.keras.layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, dropout_rate=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.ff_dim = ff_dim
self.dropout_rate = dropout_rate
self.masking_attention = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.cross_attention = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = tf.keras.Sequential([
Dense(ff_dim, activation='relu'),
Dense(embed_dim)
])
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.layernorm3 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(dropout_rate)
self.dropout2 = Dropout(dropout_rate)
self.dropout3 = Dropout(dropout_rate)
def call(self, inputs, encoder_outputs, training=False):
# inputs 是解码器的输入序列
# encoder_outputs 是编码器的输出
# 掩码多头自注意力
masking_attention_output = self.masking_attention(inputs, inputs)
masking_attention_output = self.dropout1(masking_attention_output, training=training)
out1 = self.layernorm1(inputs + masking_attention_output)
# 交叉注意力
cross_attention_output = self.cross_attention(out1, encoder_outputs)
cross_attention_output = self.dropout2(cross_attention_output, training=training)
out2 = self.layernorm2(out1 + cross_attention_output)
# 前馈神经网络
ffn_output = self.ffn(out2)
ffn_output = self.dropout3(ffn_output, training=training)
return self.layernorm3(out2 + ffn_output)
# 假设输入序列长度为 100,词汇表大小为 10000,嵌入维度为 512,多头注意力头数为 8,前馈网络维度为 2048
input_length = 100
vocab_size = 10000
embed_dim = 512
num_heads = 8
ff_dim = 2048
# 构建编码器
inputs = tf.keras.Input(shape=(input_length,))
embedding_layer = Embedding(vocab_size, embed_dim)(inputs)
# 添加位置编码
pos_encoding = tf.keras.layers.Lambda(lambda x: x + tf.constant(position_encoding(input_length, embed_dim), dtype=tf.float32), name='pos_encoding')(embedding_layer)
encoder = TransformerEncoder(embed_dim, num_heads, ff_dim)(pos_encoding)
encoder_model = Model(inputs=inputs, outputs=encoder)
# 构建解码器
decoder_inputs = tf.keras.Input(shape=(input_length,))
decoder_embedding_layer = Embedding(vocab_size, embed_dim)(decoder_inputs)
decoder_pos_encoding = tf.keras.layers.Lambda(lambda x: x + tf.constant(position_encoding(input_length, embed_dim), dtype=tf.float32), name='decoder_pos_encoding')(decoder_embedding_layer)
decoder = TransformerDecoder(embed_dim, num_heads, ff_dim)(decoder_embedding_layer, encoder_model.output)
outputs = Dense(vocab_size, activation='softmax')(decoder)
model = Model(inputs=[inputs, decoder_inputs], outputs=outputs)
# 定义位置编码函数
def position_encoding(max_len, d_model):
import numpy as np
position = np.arange(max_len)[:, np.newaxis]
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pos_encoding = np.zeros((max_len, d_model))
pos_encoding[:, 0::2] = np.sin(position * div_term)
pos_encoding[:, 1::2] = np.cos(position * div_term)
return pos_encoding
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 假设训练数据 X_train 和 y_train 已定义
model.fit([X_train, y_train[:, :-1]], y_train[:, 1:], epochs=10)四、应用场景
(一)机器翻译
Transformer 架构在机器翻译任务中表现出色。其自注意力机制能够捕捉源语言和目标语言序列中的长距离依赖关系,提高翻译的准确性和流畅性。例如,在英法翻译中,Transformer 能准确处理语言结构差异,生成高质量的翻译结果。
(二)文本生成
Transformer 架构在文本生成任务中如故事创作、新闻撰写等方面广泛应用。其强大的语言理解和生成能力可以生成连贯、逻辑合理的文本内容。例如,基于给定主题和开头,Transformer 能续写完整的故事。
(三)情感分析
在情感分析任务中,Transformer 架构能深入理解文本中的情感倾向和语义信息,准确判断文本的情感极性。例如,在分析用户对产品的在线评论时,Transformer 能有效识别评论中的积极和消极情绪,为企业提供有价值的市场反馈。
(四)问答系统
Transformer 架构可用于构建智能问答系统,准确理解和回答用户提出的问题。其在处理复杂问题和长文本回答方面具有优势,能提高问答系统的准确性和可靠性。例如,在企业知识库问答系统中,Transformer 能快速精准定位答案并生成详细回答。
五、注意事项
(一)模型规模与计算资源
Transformer 模型因性能需求高,需强大计算资源。训练和部署时,要选合适硬件(如 GPU 或 TPU),并依需求优化模型结构(如减小嵌入维度、少用编码器/解码器层数)。
(二)数据准备与预处理
Transformer 模型的性能依赖于数据质量。要确保数据足够大规模、多样且相关,以充分训练模型。预处理文本数据时,除分词、去除停用词等流程外,还需根据任务选择合适的序列长度,进行裁剪或填充操作。如长文本可裁剪至固定长度,短文本则需填充至统一长度,以满足模型输入要求。此外,为提高模型鲁棒性和泛化能力,还应引入数据增强技术,如同义词替换、随机插入、删除等方法,增加数据多样性。
(三)模型训练与优化
Transformer 训练过程复杂,参数众多,易出现过拟合现象。可采用正则化技术,如 L2 正则化、Dropout 等,或使用早停、学习率调整策略来缓解。过拟合时,训练可提前停止,经交叉验证找到最佳模型。同时,学习率调整也至关重要,如遇训练过程损失下降缓慢或波动较大时,可尝试降低学习率,以稳定模型收敛过程;若损失下降过慢,可适当提高学习率。此外,优化器选择和参数调节也会影响训练效果,如广泛应用的 Adam 优化器,其学习率、一阶矩估计系数(beta_1)、二阶矩估计系数(beta_2)等参数均需根据具体任务和数据集进行合理设置和调整。
(四)模型部署与监控
Transformer 模型部署后,需持续监控其性能,评估准确性和响应时间。收集用户反馈,分析错误案例,识别模型不足。同时,需监控模型输出质量,如文本生成连贯性、机器翻译准确性等,通过定期重训练模型并更新数据和参数优化,确保模型在长期运行中保持高性能和可靠性。
(五)模型可解释性
Transformer 架构相对复杂,被视为 “黑盒” 模型,解释其决策过程较困难。但在实际应用中,尤其是金融、医疗等关键领域,模型的可解释性至关重要。可采用可视化技术,如注意力权重可视化,观察不同词之间的注意力分数,了解模型关注点。此外,特征重要性分析工具(如 LIME、SHAP)可衡量输入特征对模型输出的影响,帮助理解模型决策依据,提高其在实际应用中的可靠性和可信度。
六、总结
Transformer 架构凭借自注意力机制和并行计算能力,在自然语言处理领域取得了卓越成就,推动了机器翻译、文本生成、情感分析等任务的性能提升。然而,在实际应用中,需关注模型规模、数据准备、训练优化等方面的问题,以确保其性能和效率。随着 NLP 研究的推进,Transformer 架构有望不断创新和拓展应用场景,为语言智能发展提供更强大动力。
七、引用
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv:1706.03762.
[2] Transforme[r] (2017). "Attention Is All You Need." Journal of Machine Learning Research.
[3] The Illustrated Transformer. (n.d.). Retrieved from [Website Link].
[4] Hugging Face Transformers Documentation. (n.d.). Retrieved from [Website Link].
[5] A Gentl[e] Introduction to the Transformer Model. (n.d.). Retrieved from [Website Link].




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











