






摘要
在当今 AI 时代,数据工程作为人工智能发展的基石,正变得愈发关键。数据工程师们肩负着搭建高效数据架构、处理海量数据以及保障数据质量等重任,为 AI 模型训练与应用提供坚实支撑。本文深入探讨了 AI 时代下数据工程的诸多关键能力,包括数据架构设计、数据处理与转换、数据质量保障等,并结合实际应用场景详细讲解了相应的代码示例、架构图以及流程图,旨在为广大数据工程从业者提供有价值的参考与借鉴,助力大家在 AI 潮流中打磨自身能力,更好地应对各种挑战与机遇。
一、引言
随着人工智能技术的飞速发展,各行业纷纷加快智能化转型步伐,数据作为 AI 的核心驱动力,其重要性被提升到了前所未有的高度。数据工程作为围绕数据的采集、存储、处理、分析以及服务等一系列活动的关键环节,直接决定了数据的质量与可用性,进而影响 AI 模型的性能与业务价值的实现。在这样的背景下,数据工程师们需要精准把握 AI 时代需求,锤炼核心能力,以更高效地构建数据基础设施,挖掘数据潜在价值,推动 AI 应用的蓬勃发展。
二、数据工程的关键能力剖析
(一)数据架构设计能力
-
概念阐释 数据架构是整个数据系统的骨架,它定义了数据的存储、流转、处理以及各组件之间的交互方式。优秀的数据架构能够确保数据的高效存储与快速访问,满足不同业务场景下对数据的需求,同时具备良好的可扩展性以适应数据量的增长与业务的演变。在 AI 时代,数据架构还需兼顾 AI 模型训练与推理过程中的数据供给要求,如支持大规模数据并行处理、低延迟数据访问等。
-
架构图示例
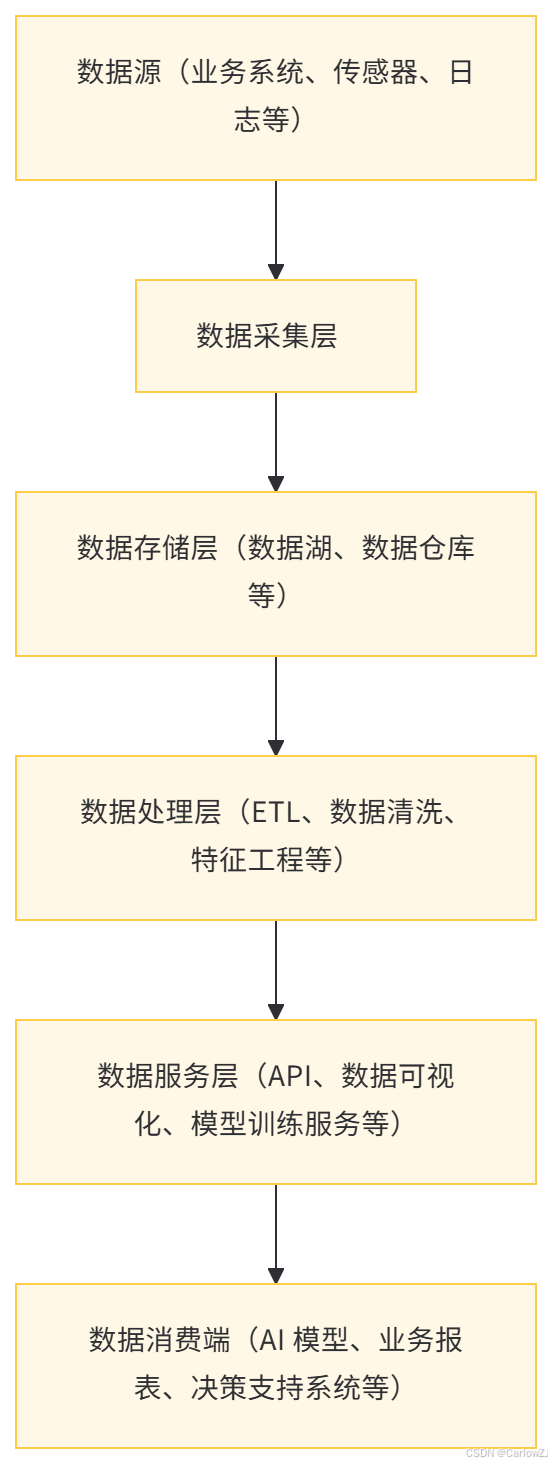
-
设计要点
-
根据业务需求与数据特点选择合适的存储方案,如对非结构化数据可采用数据湖存储,对结构化分析型数据可使用数据仓库。
-
合理设计数据流转通道,确保数据在各层级之间的高效传输,减少数据冗余与重复处理。
-
考虑数据安全与隐私保护,在架构中融入加密、访问控制等机制。
-
(二)数据处理与转换能力
-
核心内容 数据从原始状态到可用于 AI 模型训练或业务分析,往往需要经过一系列处理与转换过程。这包括数据清洗(去除噪声、缺失值处理、异常值检测)、数据集成(合并多源数据)、数据变换(归一化、标准化、编码等)以及特征工程(特征选择、特征构造、特征提取)等环节。有效的数据处理与转换能够提升数据质量,挖掘数据潜在特征,直接影响 AI 模型的训练效果与泛化能力。
-
代码示例
以下是一个基于 Python 的简单数据处理与特征工程代码片段,以处理一份包含用户信息的数据集为例:
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# 加载数据
data = pd.read_csv("user_data.csv")
# 数据清洗:处理缺失值
numerical_cols = data.select_dtypes(include=['int64', 'float64']).columns
categorical_cols = data.select_dtypes(include=['object']).columns
numerical_imputer = SimpleImputer(strategy='mean') # 数值型特征用均值填充
categorical_imputer = SimpleImputer(strategy='most_frequent') # 类别型特征用众数填充
data[numerical_cols] = numerical_imputer.fit_transform(data[numerical_cols])
data[categorical_cols] = categorical_imputer.fit_transform(data[categorical_cols])
# 数据变换:数值型特征标准化,类别型特征 one-hot 编码
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_cols),
('cat', OneHotEncoder(), categorical_cols)
])
processed_data = preprocessor.fit_transform(data)
print(processed_data)-
应用场景
-
在金融风控领域,通过对用户交易数据、信用数据等进行处理与特征工程,提取出能有效反映用户违约风险的特征,用于训练信贷风险评估模型。
-
在电商平台,处理用户行为数据(如浏览、购买、收藏等),构建用户画像特征,以支撑个性化推荐系统。
-
(三)数据质量保障能力
-
重要性阐述 高质量的数据是 AI 项目成功的基石。数据质量不佳,如存在大量错误数据、不一致数据或过时数据,会导致 AI 模型学习到错误的模式,产生偏差结果,进而影响业务决策的准确性。数据质量保障涉及数据准确性、完整性、一致性、时效性以及可信度等多个维度,需要建立一套完善的监控与评估体系。
-
数据质量评估流程图
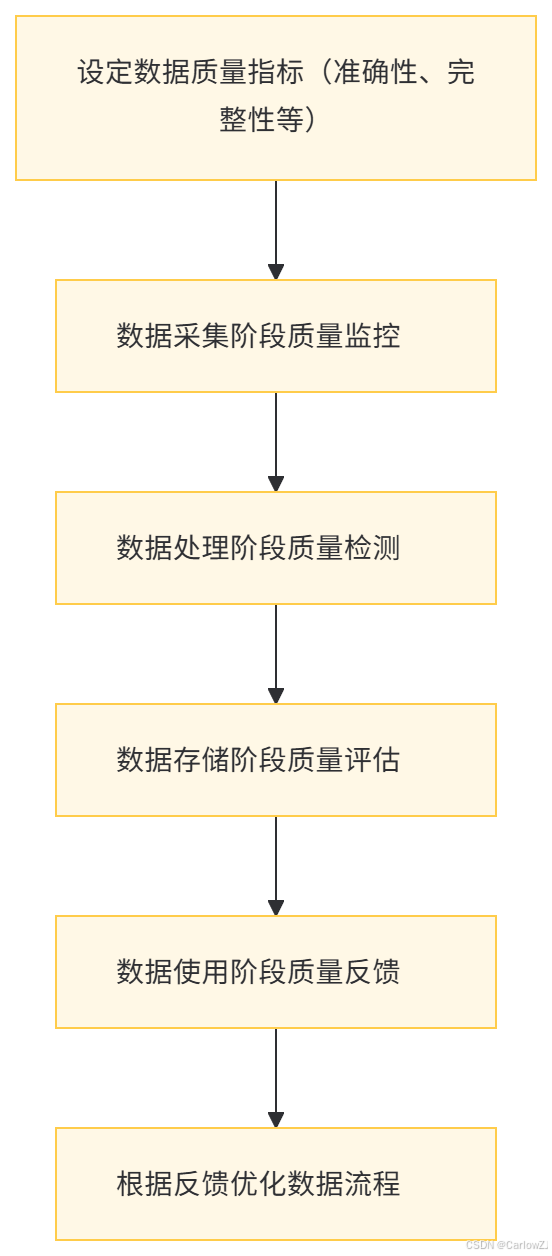
-
保障措施
-
建立数据质量规则库,明确各类数据的质量检验规则,如数据格式校验、数据范围检查、数据间一致性约束等。
-
实施数据质量监控工具,对数据全流程进行实时监测,及时发现并告警质量问题。
-
定期开展数据质量审计与评估,分析质量问题根源,制定并执行改进措施。
-
三、数据工程在 AI 应用场景中的实践
(一)智能客服系统
-
数据工程角色 在智能客服场景中,数据工程负责收集来自多渠道的客户交互数据(如语音、文本对话、客户基本信息、历史工单等),将其进行清洗、整合与转换,构建客户画像数据仓库。同时,为自然语言处理模型训练提供高质量的对话数据集,并在模型推理过程中实时获取相关数据以辅助对话生成。
-
数据流图
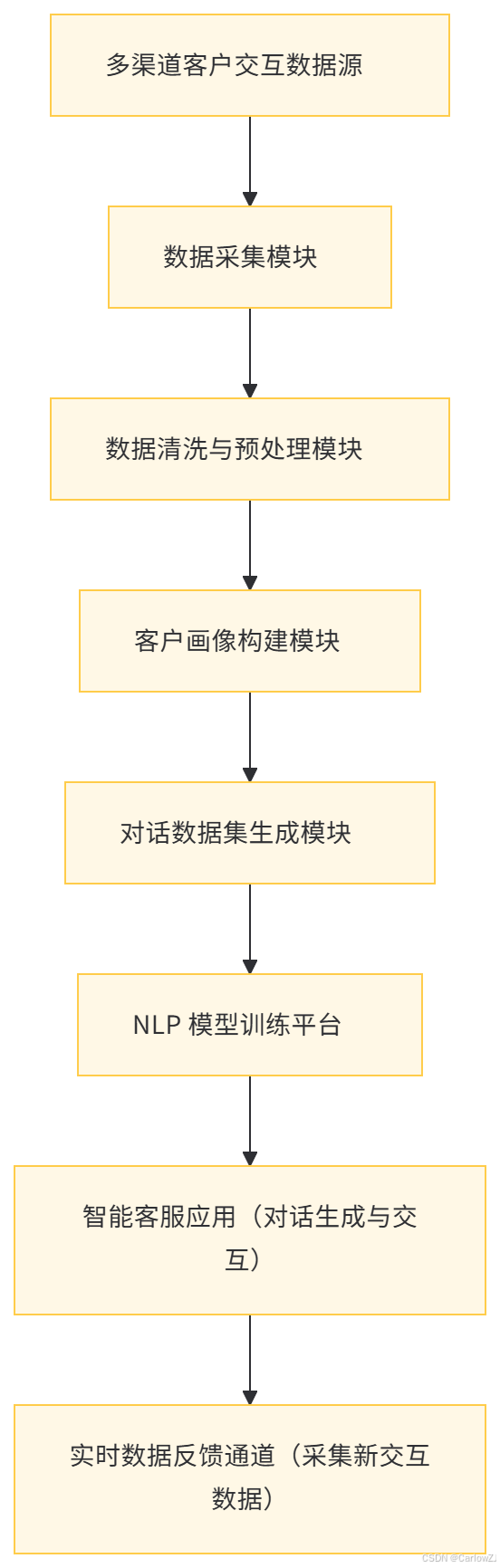
(二)医疗影像诊断辅助系统
-
数据工程贡献 数据工程团队采集、整理与存储海量医疗影像数据(如 X 光、CT、MRI 等)以及对应的诊断报告文本数据。通过数据标注流程,为影像数据添加诊断标签,构建训练数据集。同时,优化数据存储架构,确保 AI 模型在训练与推理过程中能够快速访问高分辨率影像数据,保障诊断效率。
-
架构图示例
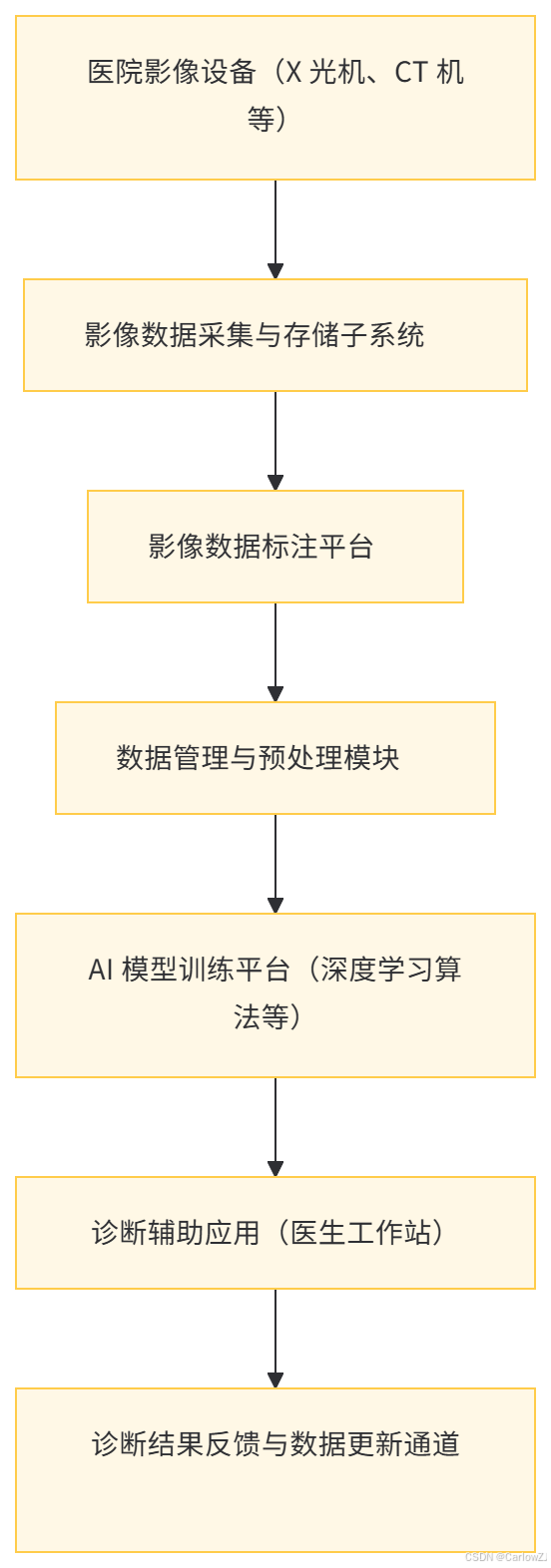
四、数据工程实践中的注意事项
(一)性能优化与成本控制
-
问题描述 在处理大规模数据时,数据工程系统容易面临性能瓶颈,如数据处理速度慢、存储成本过高等问题。若不加以优化与控制,将严重影响系统的可用性与企业的可持续发展。
-
解决策略
-
对数据存储进行分层管理,将热数据存储在高性能存储介质(如 SSD),冷数据归档到低成本存储(如磁带库)。
-
优化数据处理流程,采用分布式计算框架(如 Spark)合理分区与并行处理数据,减少数据传输与计算冗余。
-
建立资源弹性伸缩机制,根据业务负载动态调整计算与存储资源,避免资源浪费。
-
(二)数据安全与隐私保护
-
风险分析 随着数据量的激增与数据应用场景的拓展,数据安全与隐私泄露风险日益严峻。在数据工程实践中,数据可能遭受黑客攻击、内部人员违规操作以及数据共享过程中的不当使用等威胁,一旦发生数据泄露事件,将对企业和用户造成巨大损失。
-
防护措施
-
采用数据加密技术,对敏感数据在存储与传输过程中进行加密处理,确保数据即使被窃取也无法轻易解读。
-
实施严格的访问控制策略,基于角色与权限对数据进行精细化管理,限制数据访问与操作权限。
-
在数据共享时进行脱敏处理,去除或替换数据中的敏感信息,保障数据隐私。
-
五、总结
在 AI 时代,数据工程作为人工智能发展的关键支撑力量,数据架构设计、数据处理与转换、数据质量保障等能力至关重要。通过深入理解这些关键能力,结合实际应用场景进行实践,并关注性能优化、成本控制以及数据安全隐私等注意事项,数据工程师们能够构建高效、可靠的数据工程体系,为 AI 模型训练与应用提供高质量数据,助力企业在智能化浪潮中把握先机,实现业务的创新与突破,推动各行业向智能化、数字化的纵深发展,创造更大的价值与效益。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











