






摘要
在当今信息爆炸的时代,用户面临着海量的信息选择,智能推荐系统应运而生。它通过分析用户的行为数据和偏好,为用户提供个性化的推荐内容,从而提高用户体验和平台的运营效率。本文将深入探讨基于人工智能的智能推荐系统,包括其核心概念、实现技术、应用场景以及注意事项。通过详细的代码示例、架构图和流程图,读者可以快速了解智能推荐系统的构建过程,并掌握其在实际应用中的关键要点。
一、引言
1.1 问题背景
-
随着互联网的快速发展,用户面临的选项越来越多,如何快速找到感兴趣的内容成为难题。
-
智能推荐系统通过分析用户行为和偏好,为用户提供个性化的推荐内容,帮助用户节省时间并提升体验。
1.2 研究意义
-
提高用户满意度和平台粘性。
-
优化平台运营效率,提升商业价值。
二、智能推荐系统的基本概念
2.1 推荐系统的定义
-
推荐系统是一种信息过滤系统,旨在预测用户对物品的偏好,并向用户推荐可能感兴趣的物品。
-
推荐系统的主要目标是解决信息过载问题,帮助用户快速找到有价值的内容。
2.2 推荐系统的类型
-
基于内容的推荐(Content-Based Recommendation):
-
根据用户过去的行为和偏好,推荐具有相似特征的物品。
-
优点:不需要用户之间的交互数据,适合冷启动。
-
缺点:容易陷入“信息茧房”,推荐内容较为单一。
-
-
协同过滤推荐(Collaborative Filtering Recommendation):
-
基于用户之间的相似性或物品之间的相似性进行推荐。
-
用户基协同过滤(User-Based CF):找到与目标用户相似的用户,推荐这些用户喜欢的物品。
-
物品基协同过滤(Item-Based CF):找到与目标物品相似的物品,推荐给用户。
-
优点:能够发现用户的潜在兴趣。
-
缺点:需要大量的用户行为数据,存在冷启动问题。
-
-
混合推荐(Hybrid Recommendation):
-
结合多种推荐技术,克服单一推荐方法的局限性。
-
例如,结合基于内容的推荐和协同过滤推荐。
-
2.3 推荐系统的评价指标
-
准确率(Accuracy):衡量推荐结果与用户实际兴趣的匹配程度。
-
召回率(Recall):衡量推荐系统能够覆盖多少用户感兴趣的物品。
-
F1分数(F1 Score):准确率和召回率的调和平均值。
-
多样性(Diversity):推荐结果的丰富程度,避免“信息茧房”。
-
新颖性(Novelty):推荐结果中用户未接触过的内容比例。
-
覆盖率(Coverage):推荐系统能够推荐的物品范围。
三、基于AI的智能推荐系统架构设计
3.1 系统架构图
使用Mermaid格式绘制系统架构图:
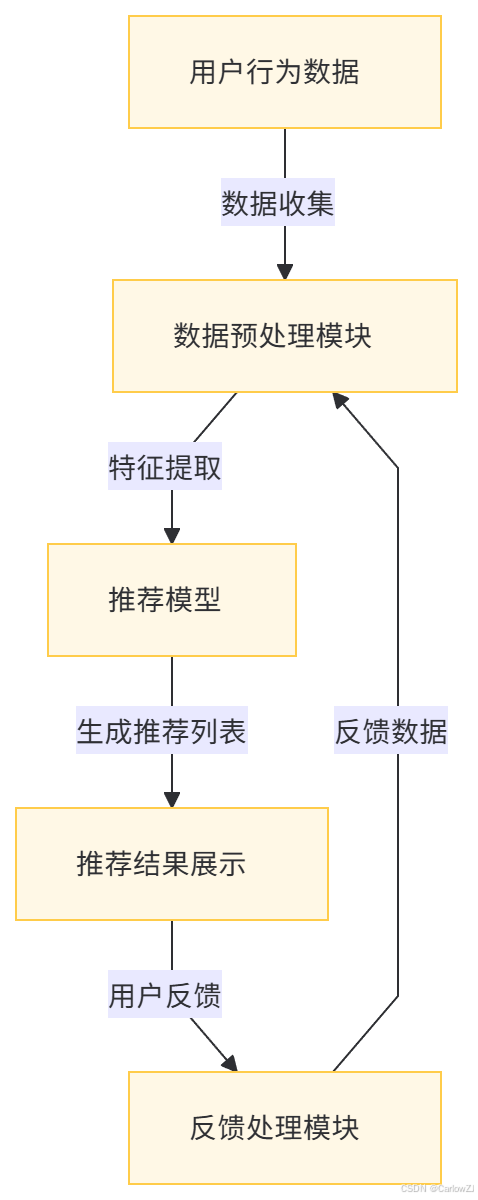
3.2 数据收集
-
用户行为数据:用户的浏览历史、购买记录、评分等。
-
物品特征数据:物品的属性、描述、标签等。
-
上下文数据:用户的地理位置、时间、设备等。
3.3 数据预处理
-
数据清洗:去除噪声数据、处理缺失值。
-
特征工程:提取有用的特征,如用户画像、物品特征等。
-
数据归一化:将数据转换到相同的尺度,便于模型处理。
3.4 推荐模型
-
基于内容的推荐模型:
-
使用文本挖掘技术提取物品的特征。
-
计算用户与物品的相似度,推荐相似度高的物品。
-
-
协同过滤推荐模型:
-
用户基协同过滤:计算用户之间的相似度,推荐相似用户喜欢的物品。
-
物品基协同过滤:计算物品之间的相似度,推荐与用户历史行为相似的物品。
-
-
深度学习推荐模型:
-
使用神经网络(如CNN、RNN、Transformer)学习用户和物品的复杂关系。
-
例如,使用深度协同过滤(Deep Collaborative Filtering)模型。
-
3.5 推荐结果展示
-
个性化推荐列表:根据用户偏好生成推荐列表。
-
推荐理由展示:向用户解释推荐的原因,提高用户对推荐结果的信任度。
3.6 用户反馈处理
-
显式反馈:用户对推荐结果的评分、评论等。
-
隐式反馈:用户的点击行为、停留时间等。
-
反馈数据的利用:将用户反馈数据用于模型的优化和调整。
四、代码示例
4.1 数据预处理代码
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 加载数据
data = pd.read_csv("user_behavior.csv")
# 数据清洗
data = data.dropna()
# 特征提取
user_features = data[['age', 'gender', 'location']]
item_features = data[['item_id', 'category', 'price']]
# 数据归一化
scaler = StandardScaler()
user_features = scaler.fit_transform(user_features)4.2 协同过滤推荐模型代码
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 示例:用户-物品评分矩阵
user_item_matrix = np.array([
[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4],
])
# 计算用户之间的相似度
user_similarity = cosine_similarity(user_item_matrix)
# 为用户生成推荐
def recommend_items(user_id, user_similarity, user_item_matrix, top_n=2):
user_index = user_id - 1
similar_users = np.argsort(user_similarity[user_index])[-2:][::-1]
recommendations = []
for user in similar_users:
user_items = user_item_matrix[user]
recommended_items = np.argsort(user_items)[-top_n:][::-1]
recommendations.extend(recommended_items)
return recommendations
# 示例:为用户1生成推荐
recommendations = recommend_items(1, user_similarity, user_item_matrix)
print("Recommended items for user 1:", recommendations)4.3 深度学习推荐模型代码
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Flatten, Dense, Dot
# 定义模型
num_users = 1000
num_items = 500
embedding_size = 50
user_input = Input(shape=[1], name='user_id')
item_input = Input(shape=[1], name='item_id')
user_embedding = Embedding(num_users, embedding_size, input_length=1)(user_input)
item_embedding = Embedding(num_items, embedding_size, input_length=1)(item_input)
user_embedding = Flatten()(user_embedding)
item_embedding = Flatten()(item_embedding)
dot_product = Dot(axes=1)([user_embedding, item_embedding])
output = Dense(1, activation='sigmoid')(dot_product)
model = Model(inputs=[user_input, item_input], outputs=output)
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
# 假设已经准备好了训练数据
# model.fit([user_ids, item_ids], ratings, epochs=10, batch_size=32)五、应用场景
5.1 电商平台
-
个性化商品推荐:根据用户的浏览和购买历史,推荐用户可能感兴趣的商品。
-
促销活动推荐:向用户推荐适合他们的促销活动,提高用户参与度。
5.2 社交媒体平台
-
内容推荐:推荐用户可能感兴趣的文章、视频、图片等。
-
社交关系推荐:推荐用户可能认识的人,拓展社交圈子。
5.3 在线教育平台
-
课程推荐:根据用户的学习历史和兴趣,推荐适合的课程。
-
学习路径推荐:为用户规划个性化的学习路径,提高学习效果。
5.4 新闻媒体平台
-
新闻推荐:根据用户的阅读偏好,推荐用户可能感兴趣的新闻。
-
专题推荐:向用户推荐相关的专题报道,提升用户体验。
六、注意事项
6.1 数据隐私与安全
-
数据加密:确保用户数据在传输和存储过程中的安全性。
-
隐私保护:遵守相关法律法规,保护用户的隐私。
6.2 模型的可解释性
-
解释推荐结果:向用户解释推荐的原因,提高用户对推荐系统的信任度。
-
可视化技术:使用可视化工具展示推荐系统的决策过程。
6.3 冷启动问题
-
新用户冷启动:通过问卷调查、默认推荐等方式,为新用户提供初始推荐。
-
新物品冷启动:通过内容分析、专家推荐等方式,为新物品提供初始曝光。
6.4 推荐结果的多样性
-
避免信息茧房:引入多样性算法,推荐用户可能感兴趣但未接触过的内容。
-
探索与利用的平衡:在推荐系统中平衡探索新内容和利用已知偏好。
七、数据流图
使用Mermaid格式绘制数据流图:
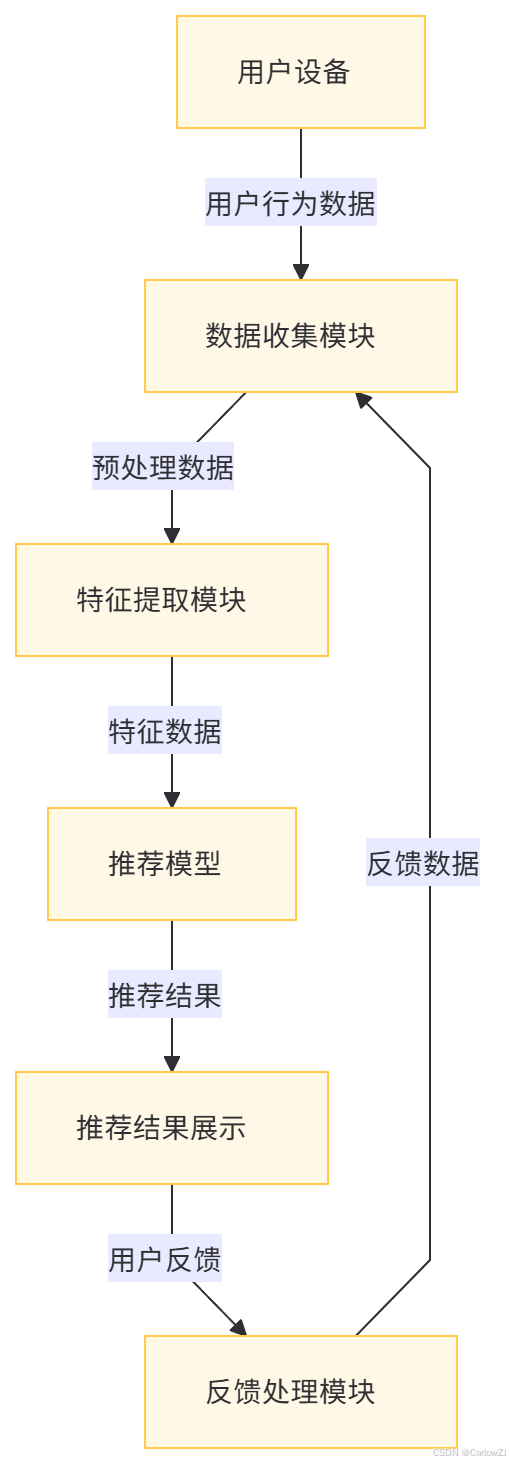
八、总结
8.1 本文的主要贡献
-
详细介绍了基于AI的智能推荐系统的原理、实现和应用场景。
-
提供了完整的代码示例和架构图,帮助读者快速理解和实现推荐系统。
-
讨论了在实际应用中需要注意的问题,如数据隐私、模型可解释性等。
8.2 未来研究方向
-
模型优化:进一步优化推荐模型的性能,提高推荐的准确率和多样性。
-
多模态推荐:结合文本、图像、视频等多种数据类型,提升推荐系统的性能。
-
实时推荐:实现实时推荐,提高推荐系统的响应速度和用户体验。
-
跨平台推荐:研究跨平台的推荐系统,整合不同平台的用户数据,提供更全面的推荐服务。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











