







ELFK日志分析平台
- ELFK是一套日志分析的解决方案,可以收集并分析服务日志并可视化。下面以Web服务为例来使用搭建使用ELFK平台。
Web集群架构图

- 购买主机(弹性云服务器ECS):只有私网IP
- nfs服务器:192.168.1.10,1CPU(1核)、1G内存(1G)。用于公共存储网页文件。
- web-0001服务器:192.168.1.11,2核4G
web-0002服务器:192.168.1.12,2核4G
web-0003服务器:192.168.1.13,2核4G
- 购买负载均衡(弹性负载均衡ELB):私网IP(192.168.1.250),绑定公网IP(110.41.189.225)

部署NFS服务
- 说明:NFS的共享文件
/etc/exports中的no_root_squash:允许root写入,不改变root权限。- 默认情况下,如果一个远程主机上的root用户通过NFS访问本机文件系统,该root用户将被映射为一个匿名用户(一般是nobody),并且本机可能会限制该root用户对文件系统的操作权限。这是因为root用户具有最高的特权,可以对文件系统进行修改和破坏。
- 在NFS服务器上启用了no_root_squash选项,这将允许远程主机上的root用户以其本来的身份进行访问,并拥有与本地root用户相同的权限。
// 部署NFS服务
跳板机(192.168.1.252)传输网页文件到NFS云主机(nfs,192.168.1.10,Web集群公共的网页存储):
[root@ecs-proxy ~]# rsync -av /root/s4/public/website.tar.gz 192.168.1.10:
NFS服务器(192.168.1.10):
// 准备公共的网页存储目录,放入网页文件
[root@nfs ~]# ls website.tar.gz
website.tar.gz
[root@nfs ~]# mkdir -p /var/webroot // 创建公共的网页文件目录
[root@nfs ~]# tar -zxf ~/website.tar.gz -C /var/webroot/ // 放入网页文件
/*
[root@nfs ~]# ls /var/webroot // info.php脚本会返回服务器IP地址和服务器主机名
404.html archives.html css fonts index.html info.php single.html
about.html contact.html favicon.ico images info.html js
*/
// 安装nfs-utils,配置,启服务
[root@nfs ~]# dnf install -y nfs-utils
[root@nfs ~]# cat /etc/exports // 共享网页存储目录
/var/webroot 192.168.1.0/24(rw,no_root_squash) // no_root_squash允许root写入,不改变root权限
[root@nfs ~]# systemctl enable --now nfs-server.service
说明:NFS的共享文件/etc/exports中的`no_root_squash`:允许root写入,不改变root权限。
默认情况下,如果一个远程主机上的root用户通过NFS访问本机文件系统,该root用户将被映射为一个匿名用户(一般是nobody),并且本机可能会限制该root用户对文件系统的操作权限。这是因为root用户具有最高的特权,可以对文件系统进行修改和破坏。
在NFS服务器上启用了no_root_squash选项,这将允许远程主机上的root用户以其本来的身份进行访问,并拥有与本地root用户相同的权限。
部署Web服务
- 部署Web服务:安装启动apache或nginx——》将NFS共享目录挂载到网页文件根目录——》设置开机自动挂载
- 注意:设置开机自动挂载NFS共享目录后,需要先启动NFS服务器再启动Web服务器。
// ansible部署Web服务:装包启服务,开机自动挂载NFS共享目录,立即挂载
跳板机(ecs-proxy,192.168.1.252,公网139.159.201.186):
[root@ecs-proxy ~]# mkdir website
[root@ecs-proxy ~]# cd website/
[root@ecs-proxy website]# cat ansible.cfg
[defaults]
inventory = hostlist
host_key_checking = False // 不显示安全提示信息询问
[root@ecs-proxy website]# cat hostlist
[web]
192.168.1.[11:13]
[root@ecs-proxy website]# ansible web -m ping // 测试连接
[root@ecs-proxy website]# cat web_install.yaml
---
- name: 部署 web 集群
hosts: web
tasks:
- name: 安装 apache 服务
dnf:
name: httpd,php,nfs-utils
state: latest
update_cache: yes // 安装前执行yum makecache,更新YUM仓库缓存
- name: 启动 httpd 服务
service:
name: httpd
state: started
enabled: yes
- name: 编辑 fstab 文件,添加开机自动挂载 NFS
lineinfile:
path: /etc/fstab
regexp: '^192.168.1.10:/.*'
line: '192.168.1.10:/var/webroot /var/www/html nfs defaults,_netdev,nolock 1 1'
create: yes
- name: 挂载 NFS
shell:
cmd: mount /var/www/html // 系统会检查 /etc/fstab 文件中是否存在关于 /var/www/html 的配置
/* 说明:/etc/fstab中的`192.168.1.10:/var/webroot /var/www/html nfs defaults,_netdev,nolock 1 1`
defaults:使用默认的挂载选项。
_netdev:告诉系统将此挂载标记为网络设备。这样,系统先开启网络服务再尝试挂载。
nolock:表示不启动文件锁定机制。这可以提高性能,但却不会提供文件锁定的功能。
1:用于备份的字段,该字段指定在系统引导时是否应该自动备份文件系统。在这种情况下,它设置为1,表示应该备份。
1:用于检查文件系统的字段,该字段指定在系统引导时是否应该自动检查文件系统。在这种情况下,它设置为1,表示应该检查。
*/
// 设置语言环境(剧本用英文编写,如果语言环境是zh_CN执行剧本会报错)
[root@ecs-proxy website]# locale // locale显示或设置当前系统所使用的区域设置
LANG=en_US.UTF-8 // 如果语言环境是zh_CN执行剧本会报错
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
[root@ecs-proxy website]# export LANG="en_US.UTF-8" LC_ALL="en_US.UTF-8" // 临时设置系统语言
[root@ecs-proxy website]# echo 'export LANG="en_US.UTF-8"' >> /etc/profile.d/lang.sh // 永久设置系统语言
// 执行 playbook 完成安装
[root@ecs-proxy website]# ansible-playbook web_install.yaml
// 服务器的启动顺序:NFS服务器——》Web集群
负载均衡(ELB)

-
华为云负载均衡(弹性负载均衡ELB)
——》购买:基础配置(共享型、按需计费),网络配置(不勾选IPv4公网,IPv4地址手动指定为192.168.1.250)
——》负载均衡添加监听器(将端口80监听的请求转发到后端服务器的端口80):配置监听器、配置后端分配策略、添加后端服务器、配置健康检测
——》内网访问负载均衡,测试效果
——》负载均衡绑定公网IP
——》公网访问负载均衡



// 测试:内网访问负载均衡(192.168.1.250)的80端口
跳板机(ecs-proxy,192.168.1.252,公网139.159.201.186):
[root@ecs-proxy ~]# curl http://192.168.1.250/info.php // 测试轮询效果。info.php脚本会返回服务器IP地址和服务器主机名
<pre>
Array
(
[REMOTE_ADDR] => 192.168.1.252
[REQUEST_METHOD] => GET
[HTTP_USER_AGENT] => curl/7.61.1
[REQUEST_URI] => /info.php
)
php_host: web-0001 // 轮询web-0001、web-0002、web-0003
1229
// 统计方式一:
[root@ecs-proxy ~]# for i in {1..99}; do curl -s http://192.168.1.250/info.php | grep php_host; done | awk '{A[$2]++}END{for(a in A)print A[a],a}'
33 web-0001
33 web-0002
33 web-0003
// 统计方式二:
[root@ecs-proxy ~]# for i in {1..99}; do curl -s http://192.168.1.250/info.php | grep php_host; done | sort | uniq -c
33 php_host: web-0001
34 php_host: web-0002
32 php_host: web-0003
/*
curl命令选项-s(silent)静默模式,即不显示进度或错误信息,只返回服务器的响应结果。
uniq -c <file> :找出连续重复的行,并将其压缩成一行,并输出重复的次数
sort <file> | uniq -c :先对文件进行排序,再找出相邻的重复行
*/
// 测试:公网访问负载均衡(公网110.41.189.225)的80端口
客户端浏览器访问负载均衡http://110.41.189.225/,成功返回网页
ELFK日志分析平台架构
- ELK是一套日志分析的解决方案,包括三款软件:Elasticsearch(负责日志检索和存储)、Logstash(负责日志的收集、分析、处理)、Kibana(负责日志的可视化)
- ELK:Web日志——》Logstash收集日志(格式转换为json,与Web服务同机)——》写入Elasticsearch——》Kibana展示
- ELFK:Web日志——》filebeat收集日志并转发——》Logstash接收日志(格式转换为json,与Web服务不同机)——》写入Elasticsearch——》Kibana展示
- EFK:Web日志(json格式,无需格式转换)——》filebeat收集日志并转发——》写入Elasticsearch——》Kibana展示
- Elastic Stack:是由Elasticsearch、Logstash、Beats和Kibana组合而成的一套工具集,用于处理和分析大规模数据的全文搜索、日志分析和数据可视化。Beats提供了多个采集器,如Filebeat用于采集日志文件、Metricbeat用于采集系统和服务指标、Packetbeat用于采集网络数据等。
- 服务器的启动顺序:NFS服务器——》Web集群——》ES集群——》Logstash服务器

Elasticsearch 日志检索和存储
ES的特点和概念
-
Elasticsearch是一个基于Lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎,基于RESTful API的Web接口。
- Elasticsearch本身可以作为数据库存储数据,也可以通过接口提供搜索引擎功能。
- Lucene是一个开源的全文搜索引擎库。
- Elasticsearch拥有集群协调子系统,可以从只有几个节点的小集群无缝扩展到拥有数百个节点的大集群。
-
Elasticsearch主要特点:
- 倒排索引。通过关键字找到对应的索引,应用:百度等搜索引擎
- 实时分析,文档导向,分布式实时文件存储。
- 高可用性,易扩展,支持集群(Cluster)、分片(Shards)、复制(Replicas)。
- 只支持JSON格式。
- 是一种面向文档的数据库。
-
Elasticsearch的概念:
-
Node:ES服务器节点。
-
Cluster:多个Node组成的集群。
-
Shards:索引的分片,每一个分片就是一个Shard。
-
Replicas:索引的拷贝(副本、备份)
-
Index:索引,拥有相似特征的文档的集合。类比Database库。
-
Type:类型,索引中可以定义一种或多种类型。类比Table表。
-
Document:文档,可被搜索的基础信息单元,一条数据,由一组Field组成。类比Row行。
-
Field:字段,Document中的单个数据。每个字段都有一个字段名和字段值。类比Column列。
-
PUT:增
-
DELETE:删
-
POST:改
-
GET:查
-
举例:
-
索引:products
类型:electronics
文档1: { “brand”: “Apple”, “price”: 1999, “screen_size”: 13.3 }
文档2: { “brand”: “Dell”, “price”: 1299, “screen_size”: 15.6 }
在"products"索引的"electronics"类型中,我们有两个文档,一个表示苹果笔记本电脑,另一个表示戴尔笔记本电脑。每个文档都有"brand"、"price"和"screen_size"字段,这些字段用于描述各自的特征和属性。
-
-
部署ES集群
- 购买五台云主机:es-0001~es-0005:192.168.1.21~25,2核4G
// 将适配rocky8版本的ELK软件包添加到自定义YUM仓库/var/localrepo
跳板机(ecs-proxy,192.168.1.252,公网139.159.201.186):
[root@ecs-proxy ~]# ls ~/s4/elk/
elasticsearch-7.17.8-x86_64.rpm kibana-7.17.8-x86_64.rpm metricbeat-7.17.8-x86_64.rpm
filebeat-7.17.8-x86_64.rpm logstash-7.17.8-x86_64.rpm
[root@ecs-proxy ~]# rsync -av ~/s4/elk/ /var/localrepo/elk/
[root@ecs-proxy ~]# createrepo --update /var/localrepo // 更新repodata
es-0001部署ES服务
- 注意:
- 集群名称。集群内节点指定同一个集群名。
- 集群广播成员。广播自身的集群信息和集群状态,重启系统会离开集群。一个成员如果重启则集群崩溃,至少需要两个成员(不能同时重启)。
- 集群创始人成员。投票超半数通过,失败继续投票。一个成员可以,两个成员单点故障全故障,高可用最少三个成员。
- 查看集群状态:
curl http://创始人成员IP地址:9200/_cat/nodes?pretty
ES服务器(es-0001,192.168.1.21):
// 增加域名解析
[root@es-0001 ~]# vim /etc/hosts
192.168.1.21 es-0001
192.168.1.22 es-0002
192.168.1.23 es-0003
192.168.1.24 es-0004
192.168.1.25 es-0005
// 安装ES,配置,启服务
[root@es-0001 ~]# yum repoinfo
[root@es-0001 ~]# dnf install -y elasticsearch
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml // yaml格式注意空格的使用
17 cluster.name: my-es // 集群名称。集群内节点指定同一个集群名
23 node.name: es-0001 // 本节点名称
56 network.host: 0.0.0.0 // 服务监听的地址
70 discovery.seed_hosts: ["es-0001", "es-0002", "es-0003"] // 这里的是IP地址,已做域名解析
// 集群广播成员。广播自身的集群信息和集群状态,重启系统会离开集群。一个成员如果重启则集群崩溃,至少需要两个成员(不能同时重启)
74 cluster.initial_master_nodes: ["es-0001", "es-0002", "es-0003"] // 这里的是IP地址,已做域名解析
// 集群创始人成员。投票超半数通过,失败继续投票。一个成员可以,两个成员单点故障全故障,高可用最少三个成员
[root@es-0001 ~]# systemctl enable --now elasticsearch.service // 会等待es-0002与es-0003投票,投票失败集群组建失败,但依旧可以开启本身的ES服务
// 查看ES服务(端口9200),成功访问
[root@es-0001 ~]# curl http://127.0.0.1:9200
{
"name" : "es-0001",
"cluster_name" : "my-es",
"cluster_uuid" : "_na_",
"version" : {
"number" : "7.17.8",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "120eabe1c8a0cb2ae87cffc109a5b65d213e9df1",
"build_date" : "2022-12-02T17:33:09.727072865Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
// 此时,查看集群my-es状态,集群组建失败。只有超半数创始人成员开启ES服务才可以成功组建集群
[root@es-0001 ~]# curl http://es-0001:9200/_cat/nodes?pretty
{
"error" : {
"root_cause" : [
{
"type" : "master_not_discovered_exception",
"reason" : null
}
],
"type" : "master_not_discovered_exception",
"reason" : null
},
"status" : 503
}
es-0002部署ES服务
ES服务器(es-0002,192.168.1.22):
// 增加域名解析
[root@es-0002 ~]# vim /etc/hosts
192.168.1.21 es-0001
192.168.1.22 es-0002
192.168.1.23 es-0003
192.168.1.24 es-0004
192.168.1.25 es-0005
// 安装ES,配置,启服务
[root@es-0002 ~]# dnf install -y elasticsearch
[root@es-0002 ~]# vim /etc/elasticsearch/elasticsearch.yml
17: cluster.name: my-es
23: node.name: es-0002 // 本节点名称
56: network.host: 0.0.0.0
70: discovery.seed_hosts: ["es-0001", "es-0002", "es-0003"]
74: cluster.initial_master_nodes: ["es-0001", "es-0002", "es-0003"]
[root@es-0002 ~]# systemctl enable --now elasticsearch
// 此时,查看集群my-es状态,集群组建成功。超半数创始人成员开启ES服务,ES集群my-es组建成功
[root@es-0002 ~]# curl http://es-0001:9200/_cat/nodes?pretty // 通过节点es-0001查看集群状态
192.168.1.21 24 88 1 0.16 0.24 0.10 cdfhilmrstw - es-0001
192.168.1.22 8 87 19 0.54 0.29 0.13 cdfhilmrstw * es-0002
[root@es-0002 ~]# curl http://es-0002:9200/_cat/nodes?pretty // 通过节点es-0002查看集群状态
192.168.1.22 8 87 1 0.46 0.28 0.13 cdfhilmrstw * es-0002
192.168.1.21 24 88 1 0.14 0.23 0.10 cdfhilmrstw - es-0001
ansible部署ES服务
- ES集群的说明:主节点是随机的,客户端可以通过访问任一节点来访问集群的服务,其他节点会将请求转发给主节点,而对客户端来说是感受不到这一转发行为的。当主节点故障时,集群会随机指定新的主节点。这就是ES集群的高可用。
// ansible部署ES服务:域名解析,装包、配置、启服务
跳板机(ecs-proxy,192.168.1.252,公网139.159.201.186):
// ansible管理ES集群
[root@ecs-proxy ~]# mkdir es
[root@ecs-proxy ~]# cd es
[root@ecs-proxy es]# vim ansible.cfg
[defaults]
inventory = hostlist
host_key_checking = False
[root@ecs-proxy es]# vim hostlist
[es]
192.168.1.[21:25]
[root@ecs-proxy es]# rsync -av 192.168.1.21:/etc/elasticsearch/elasticsearch.yml elasticsearch.j2
[root@ecs-proxy es]# vim elasticsearch.j2
23 node.name: {{ ansible_hostname }} // ansible变量,主机名
[root@ecs-proxy es]# vim es_install.yaml // 剧本部署ES服务:域名解析、安装ES、配置、启服务
---
- name: 部署 Elasticsearch 集群
hosts: es
tasks:
- name: 设置 /etc/hosts
copy:
dest: /etc/hosts
owner: root
group: root
mode: '0644'
content: |
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
{% for i in groups.es %} // 循环来遍历"es"组中的主机
{{ hostvars[i].ansible_eth0.ipv4.address }} {{ hostvars[i].ansible_hostname }}
{% endfor %}
- name: 安装 ES
dnf:
name: elasticsearch
state: latest
update_cache: yes
- name: 拷贝配置文件
template: // template模块支持变量
src: elasticsearch.j2
dest: /etc/elasticsearch/elasticsearch.yml
owner: root
group: elasticsearch
mode: '0660'
- name: 启动 ES 服务
service:
name: elasticsearch
state: started
enabled: yes
[root@ecs-proxy es]# ansible-playbook es_install.yaml
// 查看集群my-es状态
[root@ecs-proxy es]# curl http://192.168.1.21:9200/_cat/nodes?pretty
192.168.1.23 24 95 5 0.20 0.18 0.08 cdfhilmrstw - es-0003
192.168.1.24 21 95 5 0.21 0.17 0.07 cdfhilmrstw - es-0004
192.168.1.21 32 88 0 0.00 0.01 0.02 cdfhilmrstw - es-0001
192.168.1.22 15 89 0 0.00 0.02 0.04 cdfhilmrstw * es-0002
192.168.1.25 7 95 6 0.23 0.18 0.07 cdfhilmrstw - es-0005
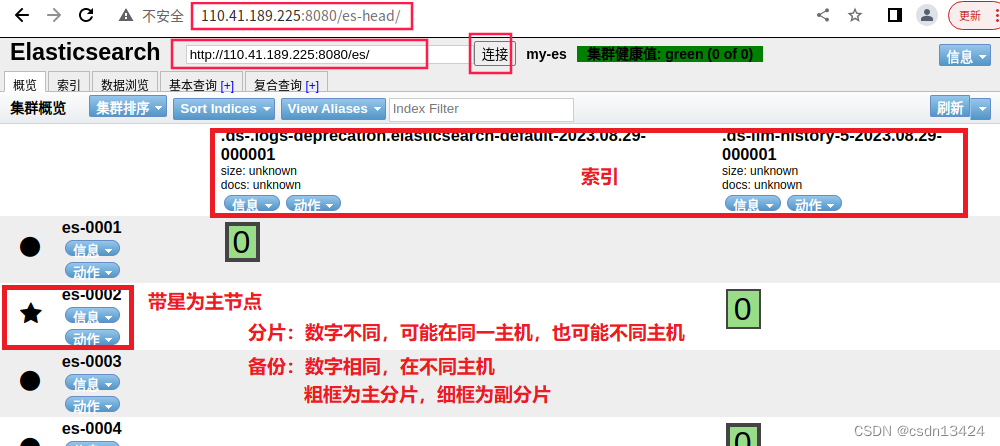
网页管理集群(掌握)
Head插件
- Head插件可以让管理员通过网页对ES集群进行查询和管理。Head插件的本质是一组网页。
- 展现ES集群的拓扑结构,并且可以通过它来进行索引(index)和节点(node)级别的操作。
- 提供一组针对集群的查询API,并将结果以json和表格形式返回。
- 提供一些快捷菜单,用以展现集群的各种状态。

部署插件页面
// 将插件head.tar.gz传输到es-0001主机
跳板机(ecs-proxy,192.168.1.252,公网139.159.201.186):
[root@ecs-proxy ~]# ls ~/s4/public/head.tar.gz
/root/s4/public/head.tar.gz
[root@ecs-proxy ~]# rsync -av ~/s4/public/head.tar.gz 192.168.1.21:
#-------------------------------------------------
// 在ES服务器es-0001上安装Web服务,并部署插件
ES服务器(es-0001,192.168.1.21):
[root@es-0001 ~]# dnf install -y nginx
[root@es-0001 ~]# systemctl enable --now nginx
[root@es-0001 ~]# ls head.tar.gz
head.tar.gz
[root@es-0001 ~]# tar zxf head.tar.gz -C /usr/share/nginx/html/ // 将插件解压到网页文件根目录,得到es-head目录
// 对外提供服务:HEAD插件(Web页面)通过负载均衡向公网提供服务
负载均衡(公网110.41.189.225)添加监听器:listener-8080(Web集群已经占用该负载均衡的80端口),后端服务器es-0001端口80
客户端浏览器访问es-0001的nginx服务 http://110.41.189.225:8080/,返回nginx欢迎页
客户端浏览器访问es-0001的HEAD插件 http://110.41.189.225:8080/es-head/,该插件默认连接ES服务"http://localhost:9200"
客户端浏览器访问ES集群数据库 http://110.41.189.225:8080/es/,返回数据库的信息,但没有密码

认证和代理
-
在Nginx配置文件中增加认证和代理:匹配URL
location ~* ^/es/(.*)$- 反向代理:
proxy_pass http://127.0.0.1:9200/$1; - 设置身份验证弹窗的提示信息:
auth_basic "Elasticsearch admin"; - 认证,指定用户身份验证文件的路径:
auth_basic_user_file /etc/nginx/auth-user;
- 反向代理:
-
htpasswd -cm /etc/nginx/auth-user admin:创建HTTP身份验证文件/etc/nginx/auth-user并添加用户admin的基本身份验证条目。- 选项
-c:创建一个新的身份验证文件。 - 选项
-m:启用MD5加密。
- 选项
// 给ES集群数据库设置认证密码
ES服务器(es-0001,192.168.1.21):
[root@es-0001 ~]# cat /etc/nginx/default.d/esproxy.conf
location ~* ^/es/(.*)$ {
proxy_pass http://127.0.0.1:9200/$1; # 反向代理,路径转发
auth_basic "Elasticsearch admin"; # 设置身份验证弹窗的提示信息
auth_basic_user_file /etc/nginx/auth-user; # 认证,指定用户身份验证文件的路径
}
[root@es-0001 ~]# dnf install -y httpd-tools
[root@es-0001 ~]# htpasswd -cm /etc/nginx/auth-user admin // 生成用户名admin的密码
New password: 1234.com
Re-type new password: 1234.com
Adding password for user admin
[root@es-0001 ~]# systemctl reload nginx.service
此时,客户端浏览器访问ES集群数据库 http://110.41.189.225:8080/es/,需要用户密码认证,用户admin密码1234.com
客户端浏览器访问es-0001的HEAD插件 http://110.41.189.225:8080/es-head/,修改连接数据库"http://110.41.189.225:8080/es/"
管理
使用网页管理:
客户端浏览器访问es-0001的HEAD插件 http://110.41.189.225:8080/es-head/
创建索引:
——》菜单栏"索引"——》"新建索引"——》键入名称、分片数量、副本数量——》确定
// 分片数量建议同节点数量,分片编号从0起计
// 副本数量为1:则说明每个数据有两份,任意损坏一台机器不丢失数据
// 副本数量为2:则说明每个数据有三份,任意损坏两台机器不丢失数据
删除索引:
——》右击具体的索引——》点击右击菜单的删除——》输入"删除"——》确定
API原语管理(了解)
- Elasticsearch提供了基于HTTP协议的管理方式(API)
- HTTP请求由三部分组成:请求行、消息报头/请求头、请求正文/请求体。
- 请求行:请求行包含了请求方法(Method)、请求URL(Request-URL)和HTTP协议的版本(HTTP-Version)。
- HTTP请求方法(不区分大小写):
- 常见:GET,POST,HEAD
- 其他:OPTIONS,PUT,DELETE,TRACE,CONNECT
- 没有指定请求方法时,默认使用GET。
- HTTP请求方法(不区分大小写):
- 请求头:请求头包含了客户端的一些附加信息,用于告诉服务器更多关于请求的细节。
- 常见的请求头:Content-Type、User-Agent、Authorization等。
- 与Elasticsearch交互的数据需使用json格式:因此请求头:
-H 'Content-Type: application/json'
- 请求体:请求体是可选的,当使用POST或PUT请求方法时,请求体用于携带需要提交给服务器的数据。
- 请求行:请求行包含了请求方法(Method)、请求URL(Request-URL)和HTTP协议的版本(HTTP-Version)。
- 借助工具 curl 命令来自定义请求头:
curl -X "请求方法" -H "请求头1" -H "请求头n" http://请求URL/请求正文_cat关键字用来查询集群状态、节点信息等。?v:显示详细信息。?help:显示帮助信息。?pretty:json格式使用易读方式显示。
// `_cat`关键字
[root@es-0001 ~]# curl http://es-0001:9200/_cat/ // 两下Tab键
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
/_cat/ml/anomaly_detectors
/_cat/ml/anomaly_detectors/{job_id}
/_cat/ml/trained_models
/_cat/ml/trained_models/{model_id}
/_cat/ml/datafeeds
/_cat/ml/datafeeds/{datafeed_id}
/_cat/ml/data_frame/analytics
/_cat/ml/data_frame/analytics/{id}
/_cat/transforms
/_cat/transforms/{transform_id}
集群状态查询 GET
[root@es-0001 ~]# curl [-XGET] http://es-0001:9200/_cat/master // 查询主节点
JUv0F6tzSHGPWPkXDToDkQ 192.168.1.22 192.168.1.22 es-0002
[root@es-0001 ~]# curl [-XGET] http://es-0001:9200/_cat/master?v // ?v查看每个字段的详细信息
id host ip node
JUv0F6tzSHGPWPkXDToDkQ 192.168.1.22 192.168.1.22 es-0002
[root@es-0001 ~]# curl [-XGET] http://es-0001:9200/_cat/master?help // ?help查看每个字段的具体含义
id | | node id
host | h | host name
ip | | ip address
node | n | node name
[root@es-0001 ~]# curl [-XGET] http://127.0.0.1:9200/_cat/master?pretty // ?pretty显示易读格式
JUv0F6tzSHGPWPkXDToDkQ 192.168.1.22 192.168.1.22 es-0002
创建索引 PUT
- 指定索引的名称,指定分片数量,指定副本数量
// 设置索引模板(默认分片数量和副本数量)
[root@es-0001 ~]# curl -XPUT -H 'Content-Type: application/json' \
http://127.0.0.1:9200/_template/index_defaults -d '{
"template": "*",
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}'
{"acknowledged":true}[root@es-0001 ~]#
/* 说明
-XPUT:请求方法,增加
-H 'Content-Type: application/json' :请求头,使用json格式
http://127.0.0.1:9200/_template/index_defaults :设置索引模板
-d '{ ... }' : 这是请求的数据体,用于定义索引模板的具体配置
"template": "*" :表示该模板适用于索引名称中包含任意内容的索引
"settings": { ... } :指定索引的一些基本设置
"number_of_shards": 5 :分片数量为5,即每个索引有5个主分片
"number_of_replicas": 1 :副本数量为1,即每个索引的主分片有1个副本分片
*/
// 创建 terc 索引
[root@es-0001 ~]# curl -XPUT http://127.0.0.1:9200/terc?pretty // PUT创建
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "terc"
}
增加数据 PUT
[root@es-0001 ~]# curl -XPUT -H "Content-Type: application/json" \
http://127.0.0.1:9200/terc/teacher/1?pretty -d '{
"职业": "诗人","名字": "李白","称号": "诗仙","年代": "唐"
}'
{
"_index" : "terc", // 索引terc
"_type" : "teacher", // 类型teacher
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
查询数据 GET
[root@es-0001 ~]# curl -XGET http://127.0.0.1:9200/terc/teacher/_search?pretty
[root@es-0001 ~]# curl -XGET http://127.0.0.1:9200/terc/teacher/1?pretty
修改数据 POST
[root@es-0001 ~]# curl -XPOST -H "Content-Type: application/json" \
http://127.0.0.1:9200/terc/teacher/1/_update -d '{
"doc": {"年代":"公元701"}
}'
{"_index":"terc","_type":"teacher","_id":"1","_version":2,"result":"updated","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":1,"_primary_term":1}[root@es-0001 ~]#
删除数据 DELETE
// 删除一条文档document
[root@es-0001 ~]# curl -XDELETE http://127.0.0.1:9200/terc/teacher/1
{"_index":"terc","_type":"teacher","_id":"1","_version":3,"result":"deleted","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":2,"_primary_term":1}[root@es-0001 ~]#
// 删除索引index
[root@es-0001 ~]# curl -XDELETE http://127.0.0.1:9200/terc
{"acknowledged":true}[root@es-0001 ~]#
Logstash 日志收集分析处理
- json格式中的两种数据结构:键值对和数组,可以嵌套(键值对嵌套键值对,数组嵌套数组,键值对嵌套数组,数组嵌套键值对),可以多层嵌套。
json格式的两种数据结构:键值对和数组
键值对:{"key":"value"}
数组:["a1","a2","a3"]
单层嵌套:
键值对嵌套键值对:{"key":{"k1":"v1"}}
数组嵌套数组:["a1","a2",["b1","b2","b3"]]
键值对嵌套数组:{"key":["a1","a2","a3"]}
数组嵌套键值对:["a1",{"k1":"v1"},{"k2":"v2"}]
多层嵌套:
写法一:{"key":{"kk":["a1","a2",{"k1":"v1"}]}}
写法二:
{
"key":{
"kk":[
"a1",
"a2",
{"k1":"v1"}
]
}
}
yaml格式的两种数据结构:键值对和数组
键值对:
key: value
数组:
- a1
- a2
- a3
特殊的,logstash中的键值对写为:"key" => "value"
[root@logstash ~]# cat /etc/logstash/logstash-sample.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
Logstash的简介
-
Elasticsearch处理的都是json格式的数据,需要通过Logstash来收集数据并加工为json格式后传输给Elasticsearch。
-
Logstash是一个使用 Java开发的数据采集、加工处理以及传输的工具。
- 所有类型的数据集中处理
- 不同模式和格式数据的正常化
- 自定义日志格式的迅速扩展
- 为自定义数据源轻松添加插件
-
Logstash不支持同时启动两个进程
-
Logstash的模块
- input:收集数据。
- filter:处理数据。
- output:输出数据。
-
Logstash支持的数据类型:布尔、字节、字符串、数值、数组、键值对
-
Logstash支持的判断方法:
==、!=、>、>=、<、<=、=~(带正则表达式的匹配)、!~ -
Logstash支持的逻辑判断:
in、notin、and、or(至少一个成立)、nand(至少一个不成立)、xor(只有一个成立 )

安装Logstash
- 购买云主机:logstash,192.168.1.27,4核8G
- Logstash没有默认的配置文件,需要手动配置。
- Logstash默认安装在
/usr/share/logstash,配置文件在/etc/logstash,由于程序找不到配置文件路径,需手动创建软链接/usr/share/logstash/config指向/etc/logstash。
- Logstash默认安装在
// 安装logstash
logstash服务器(logstash,192.168.1.27):
// 域名解析
[root@logstash ~]# vim /etc/hosts
192.168.1.21 es-0001
192.168.1.22 es-0002
192.168.1.23 es-0003
192.168.1.24 es-0004
192.168.1.25 es-0005
192.168.1.27 logstash
// 安装logstash
[root@logstash ~]# dnf install -y logstash // logstash会自己安装jdk
[root@logstash ~]# ls /usr/share/logstash/jdk/
bin conf include jmods legal lib man NOTICE release
// 创建配置文件的软链接
[root@logstash ~]# ln -s /etc/logstash /usr/share/logstash/config
[root@logstash ~]# ls /etc/logstash/logstash-sample.conf // 配置文件的示例,但复杂且不全
/etc/logstash/logstash-sample.conf
// 配置文件,编写一个最简单的配置
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input { # input模块收集数据
stdin {}
}
filter{ # filter模块过滤数据
}
output{ # output模块输出数据
stdout{}
}
// 启服务
[root@logstash ~]# /usr/share/logstash/bin/logstash // 启动。启动成功后,只要输入内容就会转换为json格式
Using bundled JDK: /usr/share/logstash/jdk
……省略一万字
[2023-08-30T09:41:59,715][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2023-08-30T09:41:59,764][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
hahaxixi // 输入内容后回车会自动转换为json格式
{
"@timestamp" => 2023-08-30T01:44:11.672Z,
"host" => "logstash",
"@version" => "1",
"message" => "hahaxixi"
}
// Ctrl+C或Ctrl+D关闭logstash进程。logstash不支持同时启动两个进程。
[2023-08-30T09:46:23,701][INFO ][logstash.javapipeline ][main] Pipeline terminated {"pipeline.id"=>"main"}
[2023-08-30T09:46:24,166][INFO ][logstash.pipelineslogstash] Removed pipeline from logstash successfully {:pipeline_id=>:main}
[2023-08-30T09:46:24,200][INFO ][logstash.runner ] Logstash shut down.
插件与调试格式
-
Logstash对数据的处理依赖插件。
- 插件的管理命令:
- 查看插件:
/usr/share/logstash/bin/logstash-plugin list - 安装插件:
/usr/share/logstash/bin/logstash-plugin install - 卸载插件:
/usr/share/logstash/bin/logstash-plugin uninstall
- 查看插件:
- 插件与模块的关系:
- 插件
logstash-input-xxx:只能用于input模块。 - 插件
logstash-filter-xxx:只能用于filter模块。 - 插件
logstash-output-xxx:只能用于output模块。 - 字符编码插件
logstash-codec-xxx:不受模块的限制。
- 插件
- 插件的管理命令:
-
官方手册:https://www.elastic.co/guide/en/logstash/current/index.html
- 官方手册——》选择版本——》选择插件,进入插件的手册页——》查看示例,查看配置选项Configuration Options(选项名setting,类型type,是否必需required)——》点击必需的配置选项,查看用法,示例array——》复制插件示例和配置选项示例,根据实际需求修改。
// 查看Logstash版本
[root@logstash ~]# /usr/share/logstash/bin/logstash --version
Using bundled JDK: /usr/share/logstash/jdk
logstash 7.17.8
// 查看Logstash插件
[root@logstash ~]# /usr/share/logstash/bin/logstash-plugin list // 查看所有插件
logstash-codec-avro // 字符编码插件,三个模块都可以使用,配合其它插件使用
logstash-codec-cef
logstash-codec-collectd
logstash-codec-dots
logstash-codec-edn
logstash-codec-edn_lines
logstash-codec-es_bulk
logstash-codec-fluent
logstash-codec-graphite
logstash-codec-json
logstash-codec-json_lines
logstash-codec-line
logstash-codec-msgpack
logstash-codec-multiline
logstash-codec-netflow
logstash-codec-plain
logstash-codec-rubydebug
logstash-filter-aggregate
logstash-filter-anonymize
logstash-filter-cidr
logstash-filter-clone
logstash-filter-csv
logstash-filter-date
logstash-filter-de_dot
logstash-filter-dissect
logstash-filter-dns
logstash-filter-drop
logstash-filter-elasticsearch
logstash-filter-fingerprint
logstash-filter-geoip
logstash-filter-grok
logstash-filter-http
logstash-filter-json
logstash-filter-kv
logstash-filter-memcached
logstash-filter-metrics
logstash-filter-mutate
logstash-filter-prune
logstash-filter-ruby
logstash-filter-sleep
logstash-filter-split
logstash-filter-syslog_pri
logstash-filter-throttle
logstash-filter-translate
logstash-filter-truncate
logstash-filter-urldecode
logstash-filter-useragent
logstash-filter-uuid
logstash-filter-xml
logstash-input-azure_event_hubs
logstash-input-beats
└── logstash-input-elastic_agent (alias)
logstash-input-couchdb_changes
logstash-input-dead_letter_queue
logstash-input-elasticsearch
logstash-input-exec
logstash-input-file
logstash-input-ganglia
logstash-input-gelf
logstash-input-generator
logstash-input-graphite
logstash-input-heartbeat
logstash-input-http
logstash-input-http_poller
logstash-input-imap
logstash-input-jms
logstash-input-pipe
logstash-input-redis
logstash-input-s3
logstash-input-snmp
logstash-input-snmptrap
logstash-input-sqs
logstash-input-stdin // input { stdin{} }
logstash-input-syslog
logstash-input-tcp
logstash-input-twitter
logstash-input-udp
logstash-input-unix
logstash-integration-elastic_enterprise_search
├── logstash-output-elastic_app_search
└── logstash-output-elastic_workplace_search
logstash-integration-jdbc
├── logstash-input-jdbc
├── logstash-filter-jdbc_streaming
└── logstash-filter-jdbc_static
logstash-integration-kafka
├── logstash-input-kafka
└── logstash-output-kafka
logstash-integration-rabbitmq
├── logstash-input-rabbitmq
└── logstash-output-rabbitmq
logstash-output-cloudwatch
logstash-output-csv
logstash-output-elasticsearch
logstash-output-email
logstash-output-file
logstash-output-graphite
logstash-output-http
logstash-output-lumberjack
logstash-output-nagios
logstash-output-null
logstash-output-pipe
logstash-output-redis
logstash-output-s3
logstash-output-sns
logstash-output-sqs
logstash-output-stdout // output { stdout{} }
logstash-output-tcp
logstash-output-udp
logstash-output-webhdfs
logstash-patterns-core
// 字符编码插件的作用
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input { # input模块收集数据
stdin {}
}
filter{ # filter模块过滤数据
}
output{ # output模块输出数据
stdout{}
}
json格式字符串: {"a":"1", "b":"2", "c":"3"}
此时,启动logstash服务,输入上面的json格式字符串,发现logstash不会将其识别为json格式,而是依旧识别为非json格式来进行格式转换
停止logstash服务,更改配置文件,使用插件logstash-codec-json和logstash-codec-rubydebug
插件logstash-codec-json:用于将输入的数据编码为JSON格式,或者将以JSON格式编码的数据解码为可读的数据格式
插件logstash-codec-rubydebug:用于将输入的数据以Ruby调试格式进行编码,或者对以Ruby调试格式编码的数据进行解码
Ruby调试格式:将单行的json格式显示为多行,并使用"=>"代替键值对的":"
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
stdin { codec => "json" }
}
filter{
}
output{
stdout{ codec => "rubydebug" } // 调试格式(多行)
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
{"a":"1", "b":"2", "c":"3"}
{
"c" => "3",
"b" => "2",
"@timestamp" => 2023-08-30T02:29:42.993Z,
"host" => "logstash",
"@version" => "1",
"a" => "1"
}
字符编码插件
- 插件logstash-codec-json:用于将输入的数据编码为JSON格式,或者将以JSON格式编码的数据解码为可读的数据格式
- 插件logstash-codec-rubydebug:用于将输入的数据以Ruby调试格式进行编码,或者对以Ruby调试格式编码的数据进行解码
- Ruby调试格式:将单行的json格式显示为多行,并使用
=>代替键值对的:
- Ruby调试格式:将单行的json格式显示为多行,并使用
// 字符编码插件的作用
json格式字符串: {"a":"1", "b":"2", "c":"3"}
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input { # input模块收集数据
stdin {}
}
filter{ # filter模块过滤数据
}
output{ # output模块输出数据
stdout{}
}
[root@logstash ~]# /usr/share/logstash/bin/logstash // 启服务
{"a":"1", "b":"2", "c":"3"} // 键入json格式字符串。此时识别为非json格式
{
"@timestamp" => 2023-10-03T08:01:46.744Z,
"@version" => "1",
"message" => "{\"a\":\"1\", \"b\":\"2\", \"c\":\"3\"}",
"host" => "logstash"
}
此时,发现logstash会将json格式字符串识别为非json格式来进行格式转换
// 停止logstash服务,修改配置文件:使用插件logstash-codec-json和logstash-codec-rubydebug
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
stdin { codec => "json" }
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash // 启服务
{"a":"1", "b":"2", "c":"3"} // 键入json格式字符串。此时识别为json格式
{
"c" => "3",
"b" => "2",
"@timestamp" => 2023-08-30T02:29:42.993Z,
"host" => "logstash",
"@version" => "1",
"a" => "1"
}
此时,发现logstash会将json格式字符串识别为json格式
插件logstash-input-file
- 插件logstash-input-file可以实时监视文件的变化,从本地文件中读取数据并将其发送到Logstash的事件流中,也可以处理已经存在的文件,将文件的每一行转换为一个事件。
- file插件可以写多个,一般一类文件写一个。一个
file{}生成一个.sincedb文件,path中一个"文件路径"生成一行信息。 - file插件使用
.sincedb书签文件来记录文件的元数据信息(每行对应一个文件),包括已读取的文件路径、文件的大小和读取的位置等。在Logstash重新启动或文件轮转时,会根据.sincedb文件记录的读取位置来开始读取,避免重复读取已经处理过的部分数据。- 默认情况下,
.sincedb文件存储在/var/lib/logstash/plugins/inputs/file/目录下,也可以通过file插件的sincedb_path参数指定其他文件路径。
- 默认情况下,
- 参数
start_position:- 默认
start_position => "end":Logstash读取新文件(.sincedb文件没有记录)时,会丢弃其历史记录(不读取已存在的数据)。 start_position => "beginning":Logstash读取新文件会从文件的开始位置读取数据(包括历史记录)。- 如果要实现每次重新启动Logstash时都从文件的开始位置读取数据:
sincedb_path => "/dev/null"且start_position => "beginning":不记录文件元数据信息,每次读取都当作新文件从头开始读取。
- 默认
// 插件logstash-input-file
[root@logstash ~]# ll -A /var/lib/logstash/plugins/inputs/file/
total 0
[root@logstash ~]# touch /tmp/{a,b}.log
[root@logstash ~]# echo 'string 01' >>/tmp/a.log
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/a.log", "/tmp/b.log"]
}
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
#---------------------------------------------------
// 此时,在第二个终端模拟写入日志
[root@logstash ~]# echo 'string 02' >>/tmp/a.log
/* 此时,第一个终端实时输出数据
{
"@version" => "1",
"@timestamp" => 2023-10-03T09:23:56.066Z,
"path" => "/tmp/a.log",
"message" => "string 02",
"host" => "logstash"
}
*/
[root@logstash ~]# echo 'string 03' >>/tmp/b.log
/* 此时,第一个终端实时输出数据
{
"@version" => "1",
"@timestamp" => 2023-10-03T09:24:12.161Z,
"path" => "/tmp/b.log",
"message" => "string 03",
"host" => "logstash"
}
*/
#---------------------------------------------------
// 停止logstash服务
// 查看默认的`.sincedb` 文件:一个file{}生成一个.sincedb文件,path中一个文件生成一行信息
[root@logstash ~]# ll -A /var/lib/logstash/plugins/inputs/file/
total 4
-rw-r--r-- 1 root root 96 Oct 3 17:25 .sincedb_ab3977c541d1144f701eedeb3af4956a
[root@logstash ~]# cat /var/lib/logstash/plugins/inputs/file/.sincedb_ab3977c541d1144f701eedeb3af4956a
2372447 0 64769 10 1696325657.259229 /tmp/b.log
2372446 0 64769 20 1696325655.2263021 /tmp/a.log
// 新文件
[root@logstash ~]# cat /tmp/{a.log,b.log} >/tmp/c.log
[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"]
start_position => "beginning" # 指定了从path新文件的开始位置读取数据
sincedb_path => "/var/lib/logstash/sincedb" # 指定了sincedb文件的路径,该文件记录了已经读取的位置
}
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
{
"host" => "logstash",
"path" => "/tmp/c.log",
"@timestamp" => 2023-10-03T10:24:53.911Z,
"message" => "string 01",
"@version" => "1"
}
{
"host" => "logstash",
"path" => "/tmp/c.log",
"@timestamp" => 2023-10-03T10:24:53.931Z,
"message" => "string 02",
"@version" => "1"
}
{
"host" => "logstash",
"path" => "/tmp/c.log",
"@timestamp" => 2023-10-03T10:24:53.932Z,
"message" => "string 03",
"@version" => "1"
}
[root@logstash ~]# cat /var/lib/logstash/sincedb
2372450 0 64769 30 1696328693.9325988 /tmp/c.log
[root@logstash ~]# /usr/share/logstash/bin/logstash // 不返回内容,因为文件内容已经全部读取了,记录在sincedb文件
[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"]
start_position => "beginning"
sincedb_path => "/dev/null" # 不记录读取位置,每次都是新文件
}
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash // 每次都会读取全部内容,但不记录
插件logstash-filter-grok
- grok插件:
- 解析各种非结构化的日志数据。
- 使用正则表达式把非结构化的数据结构化再分组匹配。
- 正则表达式需要根据具体数据结构编写,虽编写困难,但几乎可以应用于各类数据。
- 官方准备了正则表达式的宏文件以方便使用。
准备测试数据
// 从 Web 服务器查找一条日志写入到日志文件/tmp/c.log
[root@logstash ~]# echo '60.26.217.109 - admin [13/Jan/2023:14:31:52 +0800] "GET /es/ HTTP/1.1" 200 148209 "http://127.70.79.1/es/" "curl/7.61.1"' >/tmp/c.log
/* 日志格式说明
60.26.217.109 # 来访用户的 IP 地址
- # 远端登录名
admin # 认证使用的用户名
[13/Jan/2023:14:31:52 +0800] # 请求发送的时间
GET # 请求的方法
/es/ # 请求的URL地址
HTTP/1.1 # 协议及版本
200 # 返回的状态码
148209 # 网页大小
http://127.70.79.1/es/ # 访问前的跳转页面
curl/7.61.1 # 访问的客户端程序
*/
// 测试
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf // 没有filter{}过滤的配置文件
input {
file {
path => ["/tmp/c.log"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash // 启动
{
"path" => "/tmp/c.log",
"@version" => "1",
"host" => "logstash",
"message" => "60.26.217.109 - admin [13/Jan/2023:14:31:52 +0800] \"GET /es/ HTTP/1.1\" 200 148209 \"http://127.70.79.1/es/\" \"curl/7.61.1\"",
"@timestamp" => 2023-10-03T12:12:43.848Z
}
正则表达式匹配
- 正则表达式匿名分组匹配:
(正则表达式)
正则表达式命名分组匹配:(?<自定义名>正则表达式) - 正则表达式调用宏匹配:
%{宏名称:自定义名}- 宏文件路径:
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns - 宏文件中每行的内容:
宏名称 对应的正则表达式
- 宏文件路径:
// 测试:正则表达式匹配IP地址
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
grok {
# 命名分组匹配:`(?<自定义名>正则表达式) `
match => { "message" => "(?<userIP>((25[0-5]|2[0-4]\d|1?\d?\d)\.){3}(25[0-5]|2[0-4]\d|1?\d?\d))" }
}
grok {
# 调用宏匹配:`%{宏名称:自定义名} `
match => { "message" => "%{IP:clientIP}" }
}
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
{
"clientIP" => "60.26.217.109", // 自定义的clientIP,调用宏匹配
"@timestamp" => 2023-10-03T12:29:09.335Z,
"userIP" => "60.26.217.109", // 自定义的userIP,使用普通正则表达式匹配
"message" => "60.26.217.109 - admin [13/Jan/2023:14:31:52 +0800] \"GET /es/ HTTP/1.1\" 200 148209 \"http://127.70.79.1/es/\" \"curl/7.61.1\"",
"host" => "logstash",
"@version" => "1",
"path" => "/tmp/c.log"
}
正则表达式的宏文件
// Logstash的正则表达式的宏文件
// 查看宏文件
[root@logstash ~]# find /usr/share/logstash -name patterns -type d
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/lib/logstash/patterns
[root@logstash ~]# cd /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/
// tree查看所有宏文件
[root@logstash patterns]# tree
.
├── ecs-v1
│ ├── aws
│ ├── bacula
│ ├── bind
│ ├── bro
│ ├── exim
│ ├── firewalls
│ ├── grok-patterns
│ ├── haproxy
│ ├── httpd
│ ├── java
│ ├── junos
│ ├── linux-syslog
│ ├── maven
│ ├── mcollective
│ ├── mongodb
│ ├── nagios
│ ├── postgresql
│ ├── rails
│ ├── redis
│ ├── ruby
│ ├── squid
│ └── zeek
└── legacy
├── aws
├── bacula
├── bind
├── bro
├── exim
├── firewalls
├── grok-patterns // grok插件的宏文件。每行内容是: 宏名称 对应的正则表达式
├── haproxy
├── httpd
├── java
├── junos
├── linux-syslog
├── maven
├── mcollective
├── mcollective-patterns
├── mongodb
├── nagios
├── postgresql
├── rails
├── redis
├── ruby
└── squid
2 directories, 44 files
// ls -R查看所有宏文件
[root@logstash patterns]# ls -R
.:
ecs-v1 legacy
./ecs-v1:
aws bro grok-patterns java maven nagios redis zeek
bacula exim haproxy junos mcollective postgresql ruby
bind firewalls httpd linux-syslog mongodb rails squid
./legacy:
aws bro grok-patterns java maven mongodb rails squid
bacula exim haproxy junos mcollective nagios redis
bind firewalls httpd linux-syslog mcollective-patterns postgresql ruby
// 查找grok-patterns宏文件中关于IP地址的宏
[root@logstash patterns]# grep -i ^IP legacy/grok-patterns
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
IP (?:%{IPV6}|%{IPV4})
IPORHOST (?:%{IP}|%{HOSTNAME})
// 查看关于httpd的宏文件
[root@logstash patterns]# cat legacy/httpd
HTTPDUSER %{EMAILADDRESS}|%{USER}
HTTPDERROR_DATE %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{YEAR}
# Log formats // 日志相关的正则表达式
HTTPD_COMMONLOG %{IPORHOST:clientip} %{HTTPDUSER:ident} %{HTTPDUSER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" (?:-|%{NUMBER:response}) (?:-|%{NUMBER:bytes})
HTTPD_COMBINEDLOG %{HTTPD_COMMONLOG} %{QS:referrer} %{QS:agent}
# Error logs // 错误日志相关的正则表达式
HTTPD20_ERRORLOG \[%{HTTPDERROR_DATE:timestamp}\] \[%{LOGLEVEL:loglevel}\] (?:\[client %{IPORHOST:clientip}\] ){0,1}%{GREEDYDATA:message}
HTTPD24_ERRORLOG \[%{HTTPDERROR_DATE:timestamp}\] \[(?:%{WORD:module})?:%{LOGLEVEL:loglevel}\] \[pid %{POSINT:pid}(:tid %{NUMBER:tid})?\]( \(%{POSINT:proxy_errorcode}\)%{DATA:proxy_message}:)?( \[client %{IPORHOST:clientip}:%{POSINT:clientport}\])?( %{DATA:errorcode}:)? %{GREEDYDATA:message}
HTTPD_ERRORLOG %{HTTPD20_ERRORLOG}|%{HTTPD24_ERRORLOG}
# Deprecated // 不建议使用,在今后版本可能会被移除
COMMONAPACHELOG %{HTTPD_COMMONLOG}
COMBINEDAPACHELOG %{HTTPD_COMBINEDLOG}
使用宏格式化日志
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter{
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" } # 正则表达式调用宏匹配
remove_field => ["message"] # 移除字段
}
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
{
"referrer" => "\"http://127.70.79.1/es/\"",
"auth" => "admin",
"@version" => "1",
"agent" => "\"curl/7.61.1\"",
"ident" => "-",
"@timestamp" => 2023-10-03T12:54:10.896Z,
"clientip" => "60.26.217.109",
"request" => "/es/",
"path" => "/tmp/c.log",
"httpversion" => "1.1",
"verb" => "GET",
"timestamp" => "13/Jan/2023:14:31:52 +0800",
"host" => "registry",
"response" => "200",
"bytes" => "148209"
}
插件logstash-output-elasticsearch
- elasticsearch插件主要作用是把通过filter处理过的json数据写入到elasticsearch集群中。
检查ES集群是否正常:
方式一:客户端浏览器访问 http://110.41.189.225:8080/es-head/,用户admin密码1234.com,看到5个节点
方式二:
[root@logstash ~]# curl http://192.168.1.21:9200/_cluster/health?pretty
看到status为green,number_of_nodes为5,number_of_data_nodes为5
// 修改配置文件并启动服务
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"]
start_position => "beginning" # 指定了从path新文件的开始位置读取数据
sincedb_path => "/dev/null" # 不记录读取的位置
}
}
filter{
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" } # 正则表达式调用宏匹配
remove_field => ["message"] # 移除字段
}
}
output{
stdout{ codec => "rubydebug" }
elasticsearch {
hosts => ["es-0002:9200","es-0003:9200"] # ES集群内的节点,写两台高可用
index => "weblog-%{+YYYY.MM.dd}" # 索引名
}
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
此时,客户端浏览器访问 http://110.41.189.225:8080/es-head/,用户admin密码1234.com,可以看到新生成的索引weblog-2023.08.30
Web日志实时分析 5044
- 实现Web日志实时分析的两种方法:
- 方法一:在每台Web服务器上安装部署Logstash
- 由于Logstash使用Java开发,占用资源巨大,甚至比Web服务本身消耗的资源还大,因此该方法不适用。
- 方法二:使用filebeat收集日志并通过网络转发,Logstash通过input模块的beats插件(端口5044)接收filebeat转发的日志。
- 注意:Logstash和Elasticsearch都可以接收filebeat转发的日志,当日志非json格式时需要使用Logstash转换格式,当日志为json格式时,可以直接写入Elasticsearch。
- 方法一:在每台Web服务器上安装部署Logstash

插件logstash-input-beats 接收日志 5044
- beats插件(端口5044)是logstash input模块的插件,专门用来接收filebeat发送过来的日志,可以同时接收多台主机发送过来的日志信息。
// Logstash启用beats插件接收日志
Logstash服务器(logstash,192.168.1.27):
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
beats {
port => 5044
}
}
# filter { 不做任何修改 }
filter{
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => ["message"]
}
}
# output { 不做任何修改 }
output{
stdout{ codec => "rubydebug" }
elasticsearch {
hosts => ["es-0002:9200","es-0003:9200"]
index => "weblog-%{+YYYY.MM.dd}"
}
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
……省略一万字
[2023-08-31T09:18:00,546][INFO ][org.logstash.beats.Server][main][929e7ce3d1db31a5c059ad1c31fb71bfbcc59735f2948c953cfe2042471de8d3] Starting server on port: 5044
// 第二个终端查看beats插件是否启用(端口5044)
[root@logstash ~]# ss -ntulp | grep :5044
tcp LISTEN 0 1024 *:5044 *:* users:(("java",pid=1346,fd=125))
Filebeat 转发日志
- filebeat是使用Go语言时间的轻量级日志采集器。
- filebeat占用资源非常小,可以忽略不计。
- filebeat本质是一个agent,可以安装在应用服务器各个节点上,根据配置读取对应位置的日志文件,并通过网络转发到相应的服务中。
- 软件:
filebeat
服务:filebeat.service
配置文件:/etc/filebeat/filebeat.yml
软件安装路径:/usr/share/filebeat
Web服务器启用filebeat服务
- 使用filebeat收集日志并通过网络转发,Logstash通过input模块的beats插件(端口5044)接收filebeat转发的日志。
// 先确保Web集群的Web服务正常,ES集群的服务正常,再安装配置filebeat(在单台Web服务器测试)
// 安装filebeat,配置,启服务
Web服务器(web-0001,192.168.1.11):
[root@web-0001 ~]# dnf install -y filebeat
[root@web-0001 ~]# vim /etc/filebeat/filebeat.yml
# ============================== Filebeat inputs ===============================
15 filebeat.inputs:
22 - type: filestream
25 id: my-filestream-id // 每个收集任务的id标识,唯一。不同软件的日志文件得创建多个收集任务
28 enabled: yes // 修改该行。启用收集模块
31 paths: // 收集的日志文件的路径,多个路径可以使用`-`写多行
32 - /var/log/httpd/access_log // 修改该行。apache的日志文件路径
# ---------------------------- Elasticsearch Output ----------------------------
135 #output.elasticsearch: // 注释该行。输出给ES
137 # hosts: ["localhost:9200"] // 注释该行。ES服务地址
# ------------------------------ Logstash Output -------------------------------
148 output.logstash: // 解除注释。输出给Logstash
150 hosts: ["192.168.1.27:5044"] // 解除注释,修改该行。Logstash服务地址,beats插件5044
# ================================= Processors =================================
163 #processors: // 注释该行。用于收集系统信息
164 # - add_host_metadata: // 注释该行。收集主机信息。
165 # when.not.contains.tags: forwarded// 注释该行。判断是否为容器
166 # - add_cloud_metadata: ~ // 注释该行。收集cloud云主机信息
167 # - add_docker_metadata: ~ // 注释该行。收集docker信息
168 # - add_kubernetes_metadata: ~ // 注释该行。收集kubernetes信息
/* 查看有效配置
[root@web-0001 ~]# grep -Pv '^\s*(#|$)' /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /var/log/httpd/access_log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.logstash:
hosts: ["192.168.1.27:5044"]
*/
[root@web-0001 ~]# rm -f /var/log/httpd/* /* 为获取实时数据,清除Web的历史日志数据*/
[root@web-0001 ~]# systemctl restart httpd.service // 重启httpd服务
[root@web-0001 ~]# systemctl enable filebeat.service --now
// 验证: 访问web-0001的Web服务,观察logstash是否输出信息,ES集群是否新增索引
Logstash服务器开启logstash服务:[root@logstash ~]# /usr/share/logstash/bin/logstash
查看ES数据库(负载均衡的8080端口):客户端浏览器访问http://110.41.189.225:8080/es-head/(连接http://110.41.189.225:8080/es/)
查看ES数据库:删除旧的索引。(命令行方式删除:curl -XDELETE "http://192.168.1.21:9200/weblog-*")
访问Web服务:curl http://192.168.1.11/info.php
// 也可以客户端浏览器访问http://110.41.189.225/info.php,但需要负载均衡器将Web服务请求分配给web-0001,web-0001上的filebeat才能收集Web日志并转发给logstash,logstash接收转换格式后写入ES数据库
查看ES数据库:由于web-0001被访问,ES数据库出现新的索引weblog-2023.08.31
重复测试:ES数据库删除该索引weblog-2023.08.31后,再次访问Web服务web-0001,ES数据库再次出现新的索引weblog-2023.08.31
日志标签
- 如果filebeat有多个收集任务收集不同的软件日志并转发,logstash对不同的收集内容有不同的处理方法,则可以通过标签来区分不同的收集任务。filebeat给收集任务添加标签,logstash匹配标签。
// 日志标签
/* 示例:多日志、打标签
[root@web-0001 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /var/log/httpd/access_log
fields: # 添加标签,会随日志转发
aa: bb # 自定义键值对
- type: filestream
id: dblog # id不能重复
enabled: true
paths:
- /var/log/db.log
fields:
cc: dd
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.logstash:
hosts: ["192.168.1.27:5044"]
*/
// filebeat添加标签
Web服务器(web-0001,192.168.1.11):
[root@web-0001 ~]# vim /etc/filebeat/filebeat.yml
49 fields: // 解除注释。定义字段,添加标签
50 logtype: apache_log // 新增该行。键和值都可以自定义
[root@web-0001 ~]# systemctl restart filebeat.service
// logstash匹配标签
Logstash服务器(logstash,192.168.1.27):
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
# input { 不做任何修改 }
input {
beats {
port => 5044
}
}
filter{
if [fields][logtype] == "apache_log" { // 外套一个if判断{},匹配标签
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => ["message"]
}}
}
output{
stdout{ codec => "rubydebug" }
if [fields][logtype] == "apache_log" { // 外套一个if判断{},匹配标签
elasticsearch {
hosts => ["es-0004:9200", "es-0005:9200"]
index => "weblog-%{+YYYY.MM.dd}"
}}
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
// 验证:访问web-0001的Web服务,观察logstash是否输出信息,ES集群是否新增索引
查看ES数据库(负载均衡的8080端口):客户端浏览器访问http://110.41.189.225:8080/es-head/(连接http://110.41.189.225:8080/es/)
查看ES数据库:删除旧的索引
访问Web服务:curl http://192.168.1.11/info.php
查看ES数据库:由于web-0001被访问,ES数据库出现新的索引weblog-2023.08.31
重复测试:ES数据库删除该索引weblog-2023.08.31后,再次访问Web服务web-0001,ES数据库再次出现新的索引weblog-2023.08.31
/* 查看logstash服务,格式转换的输出信息(冗余):
{
"host" => {
"name" => "web-0001"
},
"request" => "/info.php",
"timestamp" => "31/Aug/2023:10:47:56 +0800",
"clientip" => "192.168.1.11",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"verb" => "GET",
"referrer" => "\"-\"",
"ecs" => { // 假设ecs不需要
"version" => "1.12.0"
},
"httpversion" => "1.1",
"bytes" => "171",
"auth" => "-",
"input" => {
"type" => "filestream"
},
"ident" => "-",
"agent" => { // 假设agent不需要
"version" => "7.17.8",
"id" => "a704a071-430e-4b1f-9bb5-db2bf28e4e2d",
"ephemeral_id" => "f5a2e383-8a52-48c2-8bc0-1151b1b7a476",
"name" => "web-0001",
"hostname" => "web-0001",
"type" => "filebeat"
},
"log" => { // 假设log不需要
"file" => {
"path" => "/var/log/httpd/access_log"
},
"offset" => 884 // 假设offset不需要
},
"response" => "200",
"@version" => "1",
"@timestamp" => 2023-08-31T02:47:58.193Z,
"fields" => { // filebeat自定义的标签
"logtype" => "apache_log"
}
}
*/
清理冗余数据
- 如果收集的日志中有部分数据是不需要的,filebeat可以通过
processors模块的drop_fields功能过滤掉部分数据。
// 清理冗余数据:过滤日志数据
Web服务器(web-0001,192.168.1.11):
[root@web-0001 ~]# vim /etc/filebeat/filebeat.yml
163 # ================================= Processors =================================
164 processors: // 解除注释
165 - drop_fields: // 新增该行。处理器,用于过滤字段
166 fields: // 新增该行。指定要过滤的字段
167 - log // 新增该行。
168 - offset // 新增该行。
169 - agent // 新增该行。
170 - ecs // 新增该行。
// 166-170行的数组也可以写为:fields: ["log","offset","agent","ecs"]
[root@web-0001 ~]# systemctl restart filebeat.service
// 验证:访问web-0001的Web服务,观察logstash是否输出信息,ES集群是否新增索引
查看ES数据库(负载均衡的8080端口):客户端浏览器访问http://110.41.189.225:8080/es-head/(连接http://110.41.189.225:8080/es/)
查看ES数据库:暂不删除旧的索引
访问Web服务:curl http://192.168.1.11/info.php
查看logstash服务:接收到数据,格式转换,但由于存入已有索引的时候缺少部分数据,会报错
查看ES数据库:删除旧的索引
再次访问Web服务:curl http://192.168.1.11/info.php
查看logstash服务:接收到数据,格式转换,不报错
/* 查看logstash服务,格式转换的输出信息(简洁):
{
"host" => {
"name" => "web-0001"
},
"request" => "/info.php",
"timestamp" => "31/Aug/2023:10:59:00 +0800",
"clientip" => "192.168.1.11",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"verb" => "GET",
"referrer" => "\"-\"",
"httpversion" => "1.1",
"bytes" => "171",
"auth" => "-",
"input" => {
"type" => "filestream"
},
"ident" => "-",
"agent" => "\"curl/7.61.1\"",
"response" => "200",
"@version" => "1",
"@timestamp" => 2023-08-31T02:59:04.533Z,
"fields" => {
"logtype" => "apache_log"
}
}
*/
Web集群批量部署filebeat服务
// Web集群批量部署filebeat服务
跳板机(ecs-proxy,192.168.1.252,公网139.159.201.186):
[root@ecs-proxy ~]# cd website
[root@ecs-proxy website]# rsync -av 192.168.1.11:/etc/filebeat/filebeat.yml filebeat.j2
[root@ecs-proxy website]# cat filebeat_install.yaml
---
- name: Web集群安装部署filebeat
hosts: web
tasks:
- name: 安装filebeat
dnf:
name: filebeat
state: latest
update_cache: yes
- name: 配置filebeat
template:
src: filebeat.j2
dest: /etc/filebeat/filebeat.yml
owner: root
group: root
mode: '0600'
- name: filebeat开机自启
service:
name: filebeat
enabled: yes
- name: 清理apache历史日志
file:
path: "{{ item }}"
state: absent
loop:
- /var/log/httpd/access_log
- /var/log/httpd/error_log
- name: 重启apace、filebeat服务
service:
name: "{{ item }}"
state: restarted
loop:
- httpd
- filebeat
[root@ecs-proxy website]# ansible-playbook filebeat_install.yaml
// 验证:访问web-0001的Web服务,观察logstash是否输出信息,ES集群是否新增索引
Logstash服务器开启logstash服务:[root@logstash ~]# /usr/share/logstash/bin/logstash
查看ES数据库(负载均衡的8080端口):客户端浏览器访问http://110.41.189.225:8080/es-head/(连接http://110.41.189.225:8080/es/)
查看ES数据库:删除旧的索引。(命令行方式删除:curl -XDELETE "http://192.168.1.21:9200/weblog-*")
访问Web服务:客户端浏览器访问http://110.41.189.225/info.php
查看ES数据库:不管是web-0001或web-0002或web-0003被访问,均出现新的索引weblog-2023.08.31
重复测试:ES数据库删除该索引weblog-2023.08.31后,再次访问Web服务,ES数据库再次出现新的索引weblog-2023.08.31
Kibana 数据可视化 5601
- Kibana是数据可视化平台工具
- 可视化平台、灵活分析
- 实时流量统计报表
- 种类繁多的数据图表,柱状图、折线图、地图等
- 支持插件和扩展,并提供了许多内置的数据分析工具和仪表板模板,为不同用户定制分析界面
部署Kibana服务
- 购买云主机:kibana,192.168.1.26,2核4G
// 部署Kibana服务
Kibana服务器(kibana,192.168.1.26):
// 域名解析
[root@kibana ~]# vim /etc/hosts
192.168.1.21 es-0001
192.168.1.22 es-0002
192.168.1.23 es-0003
192.168.1.24 es-0004
192.168.1.25 es-0005
192.168.1.26 kibana
// 装包、配置、启服务
[root@kibana ~]# dnf install -y kibana
[root@kibana ~]# vim /etc/kibana/kibana.yml
02 server.port: 5601 // 解除注释。监听端口
07 server.host: "0.0.0.0" // 解除注释,修改该行。监听IP地址
23 server.publicBaseUrl: "http://192.168.1.26:5601" // 解除注释,修改该行。设置基础域名为kibana服务器内网IP地址
32 elasticsearch.hosts: ["http://es-0004:9200", "http://es-0005:9200"] // 解除注释,修改该行。指定ES集群节点,两台高可用
115 i18n.locale: "zh-CN" // 解除注释,修改该行。Kibana界面显示的语言设置为中文(简体)
[root@kibana ~]# systemctl enable --now kibana.service
[root@kibana ~]# ss -ntulp | grep :5601
tcp LISTEN 0 511 0.0.0.0:5601 0.0.0.0:* users:(("node",pid=1359,fd=22))
server.publicBaseUrl是Kibana服务器发送数据包的地址信息:
情况1:客户端访问代理服务器的公网IP,再转发到内网的Kibana服务器,则server.publicBaseUrl使用Kibana服务器的内网IP地址,这样代理服务器才能识别
情况2:客户端直接访问Kibana服务器的公网IP,则server.publicBaseUrl使用Kibana服务器的公网IP地址,这样客户端才能识别
Kibana成功连接ES数据库后,ES数据库会写入Kibana的元数据,索引名以".kibana"开头,如果删除则Kibana无法连接ES数据库
如果要重置Kibana:停止Kibana服务——》删除ES数据库中关于Kibana的索引——》卸载Kibana,删除相关文件——》安装Kibana、配置、启服务
// 对外发布服务
负载均衡(公网110.41.189.225)添加监听器listener-5601,后端服务器kibana端口5601,设置白名单(只允许自己的公网IP访问)
客户端浏览器访问Kibana服务 http://110.41.189.225:5601/


Kibana使用
Kibana成功连接ES数据库后,ES数据库会写入Kibana的元数据,索引名以".kibana"开头,如果删除则Kibana无法连接ES数据库
客户端浏览器访问Kibana服务 http://110.41.189.225:5601/,Kibana可视化查看ES服务
——》左上角三横线
——》Management,Stack Management
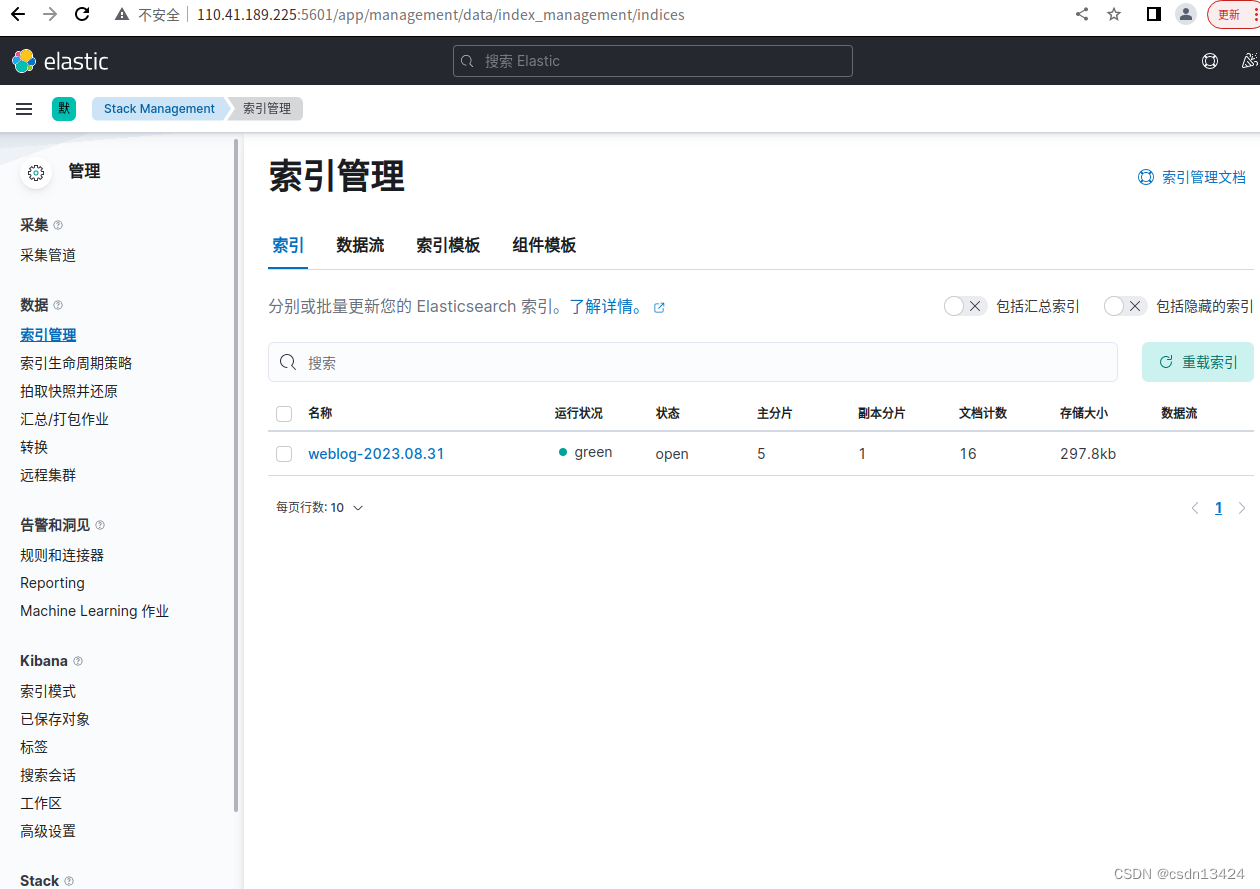
——》Kibana的索引模式,创建索引模式,名称"weblog-*",时间戳字段"@timestamp",创建索引模式
——》数据-索引管理,可以看见匹配到的索引"weblog-2023.08.31"
——》Analytics,Discover,可以看见数据和图表
——》Analytics,Dashboard,创建仪表板,创建可视化

















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









