







大家好,尽管创建机器学习模型相对容易,但实现高准确率却是每个数据科学家梦寐以求的目标。常常我们会不断进行参数调整、尝试不同的算法,以及应用各种优化技术来提升模型的性能,但这些过程耗费了大量时间和精力。2019年学术界和业界逐步实现了AutoML(自动机器学习)框架,可以帮助自动化这些繁琐的过程,在这些AutoML框架中,FLAML备受推崇。FLAML不仅能够简化参数调整、算法选择和优化技术的应用,同时还能够显著减少时间消耗,并提供高准确率的机器学习模型。
在当今日益复杂和多样化的数据环境中,FLAML以其高效的自动化能力和智能优化技术成为了机器学习和AI操作的首选引擎。本文将介绍FLAML如何通过自动化工作流程、优化模型性能以及提供定制化解决方案,随着人工智能应用领域的不断拓展,FLAML将持续助力数据科学的发展。
1.FLAML及安装
FLAML(A Fast and Lightweight AutoML Library)是快速轻量级自动机器学习框架,是一个Python库,可帮助构建高准确率的机器学习模型。该库由微软开发并支持,为用户提供低计算成本的即用超参数优化。具体来说,在使用这个库时,无需为获得更高的准确率选择学习器或调整超参数,该库会自动执行所有这些任务,并提供最佳准确率的结果,本质上提出了解决特定问题的最佳算法。它基于大型语言模型、机器学习模型等自动化工作流程,并优化其性能。
-
FLAML使得基于多代理对话构建下一代GPT-X应用变得轻而易举。它简化了复杂GPT-X工作流程的编排、自动化和优化。它最大程度地提升了GPT-X模型的性能,并改进模型缺点。
-
对于常见的机器学习任务,如分类和回归,可以在提供的数据上快速找到质量优秀的模型,并消耗较少的计算资源。FLAML易于定制或扩展,可以从流畅的范围中找到期望的定制化。
-
它支持快速、经济的自动调整(例如,为基础模型进行推断超参数、在MLOps/LMOps工作流程中进行配置、管道、数学/统计模型、算法、计算实验、软件配置等),能够处理具有异构评估成本和复杂约束/指导/提前停止的大搜索空间。
使用pip命令可安装库:
pip install flaml
2.autoGen
autogen软件包利用通用的多代理对话框架实现了下一代GPT-X应用,它提供了可定制和可对话的代理,这些代理集成了LLMs(大型语言模型)、工具和人类。通过自动化多个能力强大的代理之间的对话,大家可以轻松地使它们集体自主执行任务。
from flaml import autogen
import openai
openai.api_key = "sk-api_keyapi_keyapi_keyapi_key"
assistant = autogen.AssistantAgent("assistant")
user_proxy = autogen.UserProxyAgent("user_proxy")
user_proxy.initiate_chat(
assistant,
message="Show me the YTD gain of 10 largest technology companies as of today.",
)Autogen 还有助于充分利用昂贵的大型语言模型(LLMs),如 ChatGPT 和 GPT-4。它提供了 openai.Completion 或 openai.ChatCompletion 的可替换方案,并具有诸如调整、缓存、模板化、过滤等强大功能。例如,您可以通过自己的调整数据、成功度量和预算来优化大型语言模型的生成。
# perform tuning
config, analysis = autogen.Completion.tune(
data=tune_data,
metric="success",
mode="max",
eval_func=eval_func,
inference_budget=0.05,
optimization_budget=3,
num_samples=-1,
)
# perform inference for a test instance
response = autogen.Completion.create(context=test_instance, **config)3.autoML
只需很短的几行代码,便可以将这个经济快捷的自动机器学习引擎作为 scikit-learn 风格的估算器开始使用。
from flaml import AutoML
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建AutoML对象并拟合数据
automl = AutoML()
automl.fit(X, y, task="classification", estimator_list=['rf', 'extra_tree', 'lrl1'])
# 打印最佳模型及其性能
print("Best _best_estimator:", automl._best_estimator)
print("Best accuracy:", automl.best_config)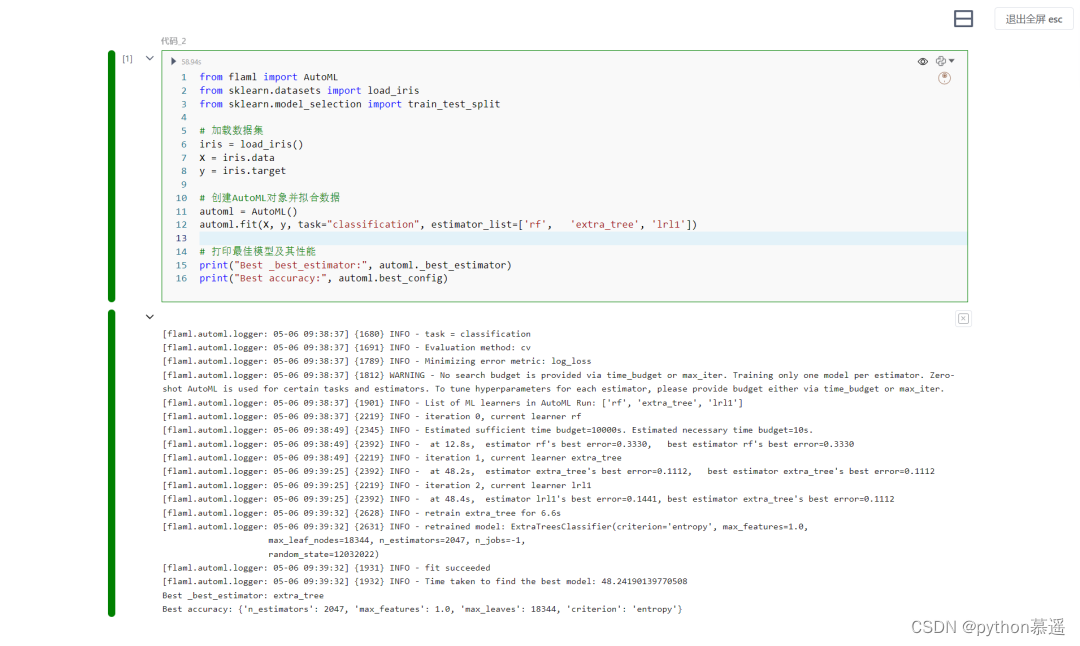
4.Zero-shot AutoML
零封装自动机器学习(Zero-shot AutoML)允许使用现有的 lightgbm、xgboost 等训练 API,同时又能够获取 AutoML 的优点,以选择每个任务的高性能超参数配置。
from flaml.default import LGBMRegressor
# Use LGBMRegressor in the same way as you use lightgbm.LGBMRegressor.
estimator = LGBMRegressor()
# The hyperparameters are automatically set according to the training data.
estimator.fit(X, y)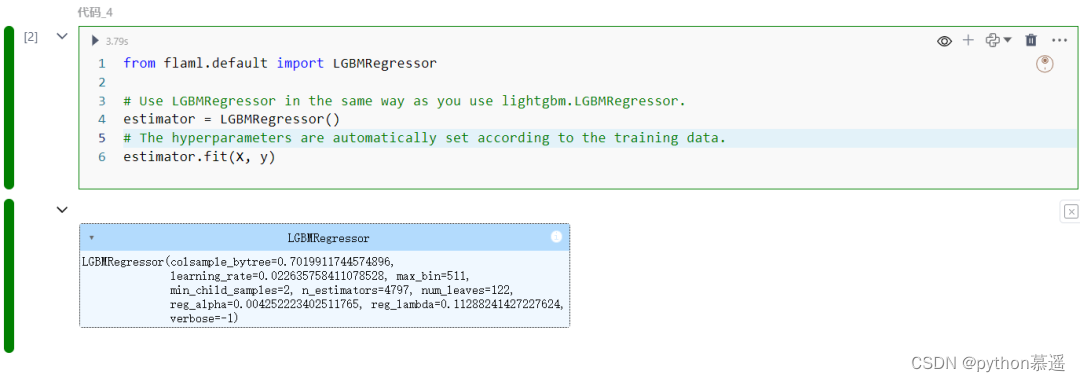
5.自定义调优函数
flaml.tune 是一个用于经济性超参数调优的模块,在内部被 flaml.AutoML 使用,也可以用来直接调优用户定义的函数(UDF),这不限于机器学习模型训练。
from flaml import tune
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 拆分数据集为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义要调优的函数
def train_model(config):
n_estimators = config["n_estimators"]
max_depth = config["max_depth"]
clf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
clf.fit(X_train, y_train)
accuracy = clf.score(X_val, y_val)
return accuracy
# 定义调优空间
config_space = {
"n_estimators": tune.randint(lower=50, upper=200),
"max_depth": tune.randint(lower=2, upper=20)
}
# 运行调优过程
analysis = tune.run(
train_model,
config=config_space,
mode="max",
resources_per_trial={"cpu": 1},
num_samples=10,
)
# 打印最佳配置和性能
best_config = analysis.get_best_config( mode="max")
best_accuracy = analysis.get_best_trial( mode="max")
print("Best config:", best_config)
print("Best accuracy:", best_accuracy)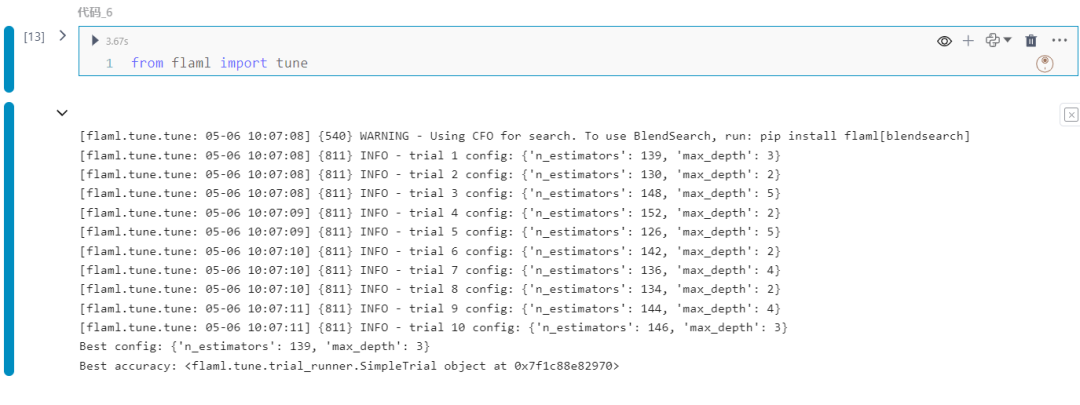
综上所述,FLAML是一个高效的自动机器学习框架,为用户提供了简化参数调整、算法选择和优化技术的应用,显著减少了时间消耗,同时提供高准确率的机器学习模型。它不仅能够应用于常见的机器学习任务,还能轻松构建下一代智能应用,FLAML的灵活性和便利性使其成为当今数据科学领域的首选引擎。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











