







论文概要
作者提出,增广算法是通过增加图片数据集的多样性来提高算法的效果,但是有两个影响多样性的因素一直没有被人提及,分别是多样性的定义以及多样性与正则化效应的量化关系。作者提出了Variance Diversity来度量多样性,并证明了Variance Diversity是影响数据增广的正则化效应效果的因素。同时,作者还提出了一个基于采样的非监督增广框架DivAug,通过最大化Variance Diversity来提升增广的效果。
搜索空间
论文沿用了AutoAugment中的搜索空间,定义了16种基础的图片处理操作:Sharpness, ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Color, Brightness, Cutout, Sample Pairing, and Contrast.并定义:
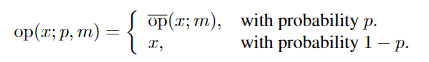
表示用p的概率以m的程度系数对输入图片x进行op操作,其中op是16种操作之一。
而在以往的自动增广方法中,每两个op操作组成一个sub-policy,一共有25种不同的候选sub-policy,以往的自动增广方法在这25种方法种排序,取最终的5种sub-policy组成最终的final policy。final-policy在整个训练过程中会不断变化,而对于每个batch的图片,只有一个sub-policy会被应用到图片中。
本文的搜索空间基本和上述说的一样,除了有两个不同的地方:(1)p和m被设定为0-1之间的值(2)候选的sub-policy不止25种,而是所有可能的集合。















 5905
5905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









