







爬虫
经常看到有人用Python作爬虫玩,自己也手痒痒,之前看过一些介绍,但是当时什么都不懂,html和计算机网络都不知道是什么。现在算是懂一点点了,就学着写一个玩玩。
感觉爬虫主要就是获取目标网站的源代码,然后提取需要的东西。用到的python工具主要是urllib、re、requests、BeautifulSoup之类的。懂一些html、计算机网络、正则表达式的知识就可以上路了。
当然Python有个不错的开源项目,专门的爬虫Scrapy【http://scrapy.org/】,有兴趣的可以学习下。
简单的例子
先给出别人写的一个例子
import re, requests
SAVE_DIR_PATH = '/home/xlzd/temp/'
URL = 'http://www.zhihu.com/question/35038311'
save = lambda url: open(SAVE_DIR_PATH + url[url.rfind('/')+1:], 'wb').write(requests.get(url).content)
if __name__ == '__main__':
map(save, ['http:' + url for url in re.findall(ur'<img src=[\'"](//pic.+?)[\'"].+?>', requests.get(URL).content)])
作者:xlzd
链接:https://www.zhihu.com/question/35038311/answer/61630687
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。(只是用来交流学习的,希望作者不要怪我直接贴过来了)
这个代码算是很简洁了,如果初学者不知道这里的map、lambda是什么东西的话,可以去看看廖雪峰老师的Python教程:
map:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014317852443934a86aa5bb5ea47fbbd5f35282b331335000
lambda:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431843456408652233b88b424613aa8ec2fe032fd85a000
简单分析这段代码的话,就是从该网站的源代码中获取所有的图片链接,然后下载保存在本地。
下面是我自己写的,可能略显丑陋
import urllib
from BeautifulSoup import *
import re
import requests
url = raw_input('Please input the url: ')
save_path = 'F:/temp/'
limit = int(raw_input('limit: '))
i = 0
html = urllib.urlopen(url).read()
soup = BeautifulSoup(html)
imgs = soup('img')
for img in imgs:
if i >= limit:
break
img = img.get('src')
if img and re.search(r'^https://pic.*?_b\..*[gf]$', img):
fw = open(save_path + img[img.rfind('/')+1:], 'wb')
fw.write(requests.get(img).content)
fw.close()
i += 1
limit是数量上限。主要是觉得反正用来玩的,没必要全部爬取。
至于这里为什么用这个BeautifulSoup,当然可以省去的,直接拿正则表达式提取就可以了。BeautifulSoup的作用主要是规范化html源代码,保证程序能够很方便的处理。
这里对img标签进行分析,提取src属性,然后用正则表达式判断是否是自己想要的图片类型。在这里比上面的代码稍微优化了一点,考虑到知乎上的图片不全是用户上传到回答中的,有一些是头像之类的,而且每个人回答的第一张图片会有一个缩略图副本,所以需要对信息进行过滤。通过观察发现,后缀前面是 _b 的表示这是大图,缩略图后缀前面一般是 200*112 ,头像一般是 _s ,还存在 src="//zhstatic.zhihu.com/assets/zhihu/ztext/whitedot.jpg" 这种空白干扰。我们想要的当然是大图了,所以提取的时候找出那些以 https://pic 开头,并且以 _b.(jpg/png/jpeg/gif) 结尾的。(我不清楚有没有gif的,但是其他三种是有的)
找到地址后就好说了,下载到自己的硬盘里就可以了,简单的写文件操作。
总感觉不放一张图大家会没多少兴趣啊。
就是这么简单,然后文件夹里就充满图片了。
你问我为什么图片都变模糊了?少年要注意保护视力呀,屏幕看多了就该休息下了,不然就会这样子。
进一步分析
到了这里还没完呢,我们只是下载了一个原始页面的信息,如果该问题下面有很多回答,有的回答不会直接显示的,当然你也爬不到了。奇怪的是,我检查了下知乎那个 “更多” 按钮,发现并没有链接到其他网页。如果是像一些网站一样是下一页的话就容易的多了。

就是这里,并没有链接。。。
然后我查看了网页源代码,进行查找,发现根本找不到这个按钮。。。

然后点击更多之后,再次查看源代码,发现源代码没有任何变化。。。
然后我查找了下源代码最后一个人的回答,在页面中显示的是中间位置,也就是说下部分的源代码根本没看到。看来还是需要模拟浏览器滚动页面来加载的。
一些好玩的
工作邀请
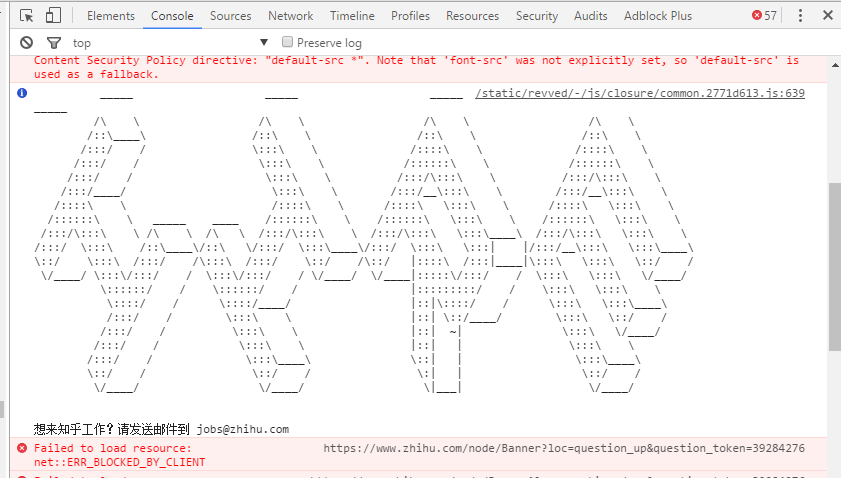
没错,知乎就是这么调皮。。。(我这样暴露它是不是不好?)
图片位置
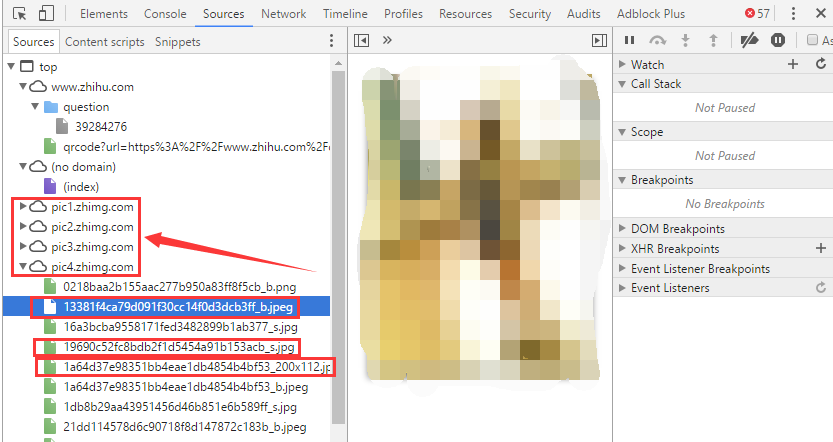
这个问题下的图片有这么4个位置,仓库名是有规律的,不知道一共有多少个图片仓库。下面圈出来的3个名称是为了验证我之前说的,图片有这么几种,后缀前面那个东西决定了这张图片的用途。
一些瞎想
你可能觉得既然知道图片仓库位置了,那不是能直接爬下来图片了?Too young!
我们来看看这个图片名称的长度,以 _b 这种为例,一共32位,十六进制,这能表示多大的数呢?
1632≈3.4028236738 16 32 ≈ 3.40282367 38
恐怕知乎再发展几年也难以达到这个数量级吧。
在这种情况下想猜对图片的Hash值(应该是用的Hash吧),也就是对应的名字,基本不可能。
另外,对于重复的图片会不会只存一次?这个问题要内部人员才知道了。
对Hash算法有兴趣的可以看看Wikipedia:https://zh.wikipedia.org/wiki/SHA%E5%AE%B6%E6%97%8F















 3128
3128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









