







JVM看这一篇
写在前面:本篇文章主要搬自本人的云笔记,主要以总结为主;有不当之处,欢迎指正,共同学习;
JVM整体认识
JVM内存分为:
**类加载器**(ClassLoader)
**运行时数据区**(Runtime Data Area)
**执行引擎**(Execution Engine)
**本地库接口**(Native Interface)
各个组成部分的职能:
程序在执行之前先要把java代码转换成字节码(class文件),jvm首先需要把字节码通过一定的方式 类加载器(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area) ,
而字节码文件是jvm的一套指令集规范,并不能直接交个底层操作系统去执行,
因此需要特定的命令解析器 执行引擎(Execution Engine) 将字节码翻译成底层系统指令再交由CPU去执行,
而这个过程中需要调用其他语言的接口 本地库接口(Native Interface)来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。
而我们通常所说的jvm组成指的是运行时数据区(Runtime Data Area),
因为通常需要程序员调试分析的区域就是“运行时数据区”,或者更具体的来说就是“运行时数据区”里面的Heap(堆)模块
,那接下来我们来看运行时数据区(Runtime Data Area)是由哪些模块组成的
JVM运行时数据区
总结如下表
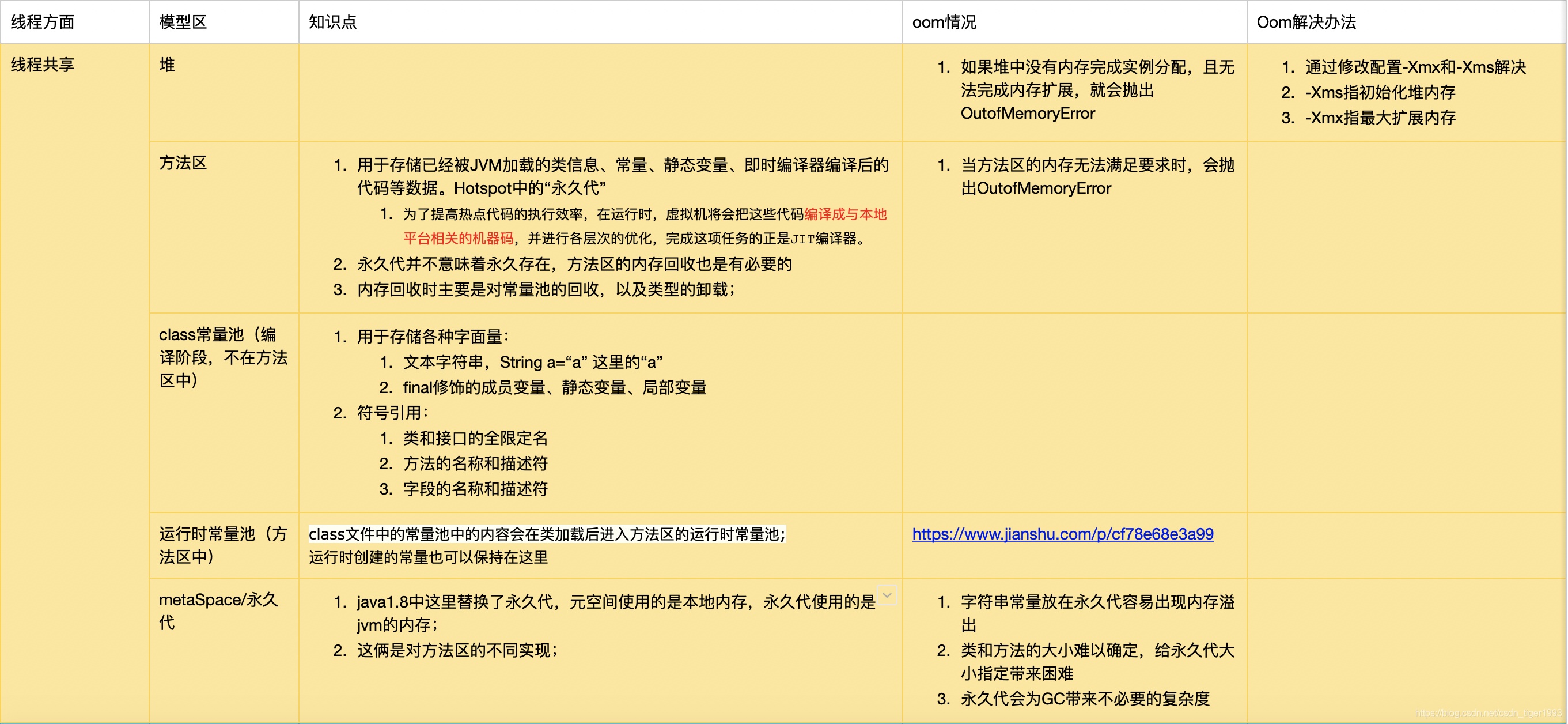

最常用jvm参数
-Xss:每个线程虚拟机栈的大小
-Xms:堆的初始值(一般设置-Xms512m)
-Xmx:堆的最大值(一般设置-Xmx2048m)
-XX:SurvivorRotio:用来标识Eden和Survivor的内存大小比例
-XX:NewRotio:用来标识老年代和年轻代的内存大小比例
-XX:MaxTenuringThreshold:标识对象从年轻代晋升到老年代经历GC的次数的最大阈值
内存分配策略
- 静态存储:编译时确定
- 栈式存储:数据区编译时未知,运行时入口确定
- 堆式存储:编译时或运行时模块入口无法确定,动态存储
堆和栈的区别
1. 管理方式:栈自动释放内存,堆需要进行GC
2. 空间大小:栈比堆小
3. 碎片相关:栈产生的碎片远远小于堆
4. 分配方式:栈支持静态和动态分配,堆只有动态分配
5. 效率:栈的效率高于堆
JVM垃圾回收机制
首先什么数据需要回收呢?
堆中不被引用的数据才需要回收
这里有两种方式确定哪些文件不被引用:
1. 引用计数算法:每个对象实例上都有一个引用计数器,当引用计数器=0时,则认为可以被GC;
优点:效率高;
缺点:无法测定出循环引用的情况,导致内存泄漏
2. 可达性分析算法:这是判定为垃圾的主流算法,通过判断对象(GCROOT)的应用链是否可达类决定对象是否可以被回收;
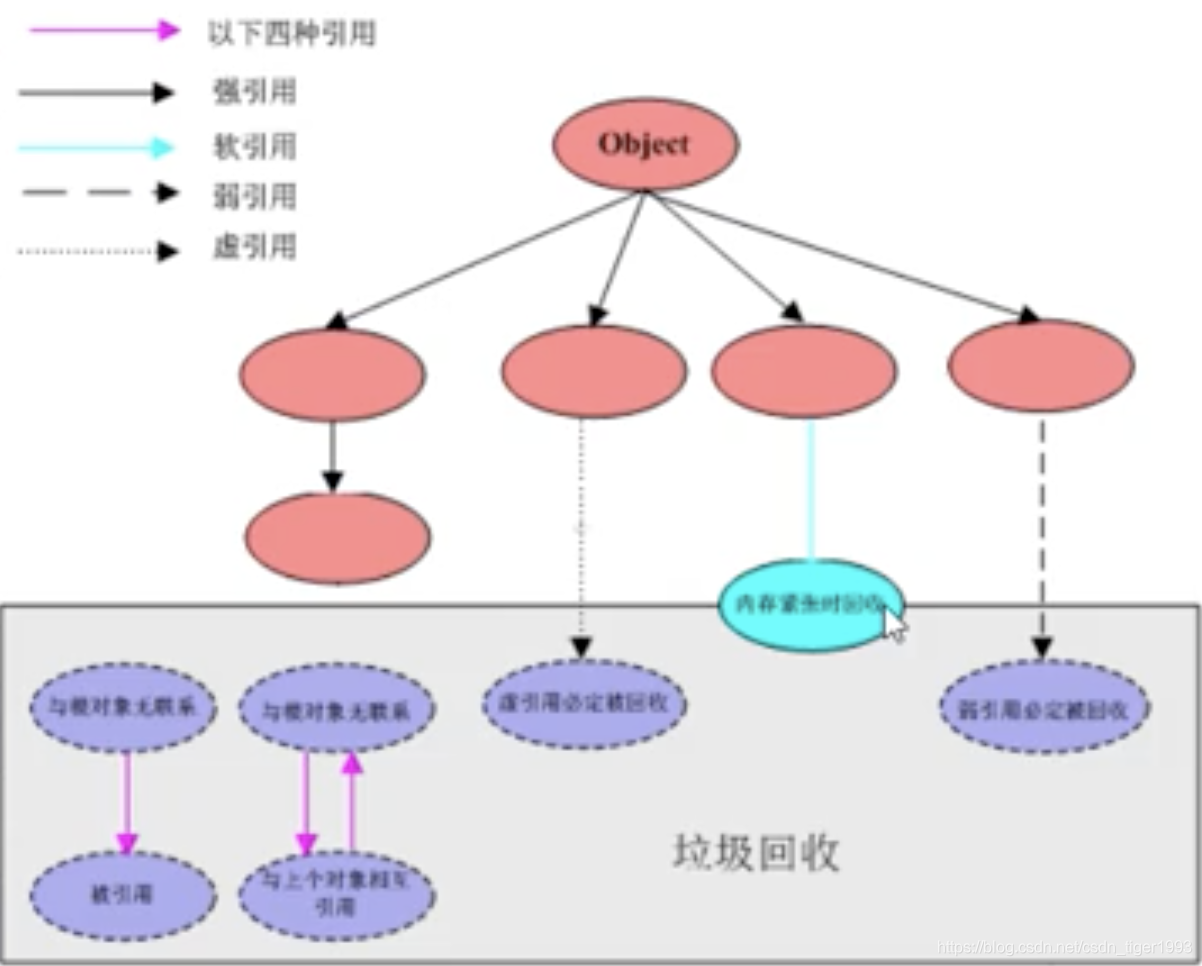
可以作为GCROOT的对象:
1. 虚拟机栈中引用的对象
2. 方法区中常量引用的对象
3. 方法区中类静态属性引用的对象
4. 本地方法栈中JNI(native)的引用对象
5. 活跃线程的引用对象
什么时候会发生垃圾收集:
1. 年轻代中Eden或者S区的内存不足的时候
2. 老年代空间不足的时候
3. 方法区内存不足的时候
4. System.gc()可能会进行收集
常用的垃圾回收算法:
1. 标记-清除算法(Mark -sweep):这里只清除未被标记的对象
1. 碎片化:由于只清除未被标记的对象,清理时会产生大量不连续的碎片块;当需要使用的大量连续的内存时,就不得不再触发一次GC;
2. 复制算法(copying):这里需要使用两个面
1. 对象面:这里进行创建对象
2. 空闲面:当对象面快用完了,就将对象面还存活着的对象copy到空闲面上,再把对象面上的对象进行清空;
3. 使用对象:对象存活率低的场景,如年轻代(10%),这里解决了碎片化的问题,顺序分配内存,简单高效;
3. 标记-整理(compacting):
1. 标记:从根集合进行扫描,对存活的对象进行标记
2. 整理清除:移动所有存活的对象,且按照内存地址次序依次排序,然后将末端内存地址以后的内存回收
3. 优点:
1. 相对于标记清除算法,避免了内存的不连续行
2. 相对于复制算法,不用设置两块内存进行互换
3. 适用于存活率高的场景,如老年代
分代收集算法:
1. 年轻代(占内存三分之一):主要使用复制算法,发生Minor GC,尽可能的回收生命周期短的对象
1. 这里分为Eden区:主要用于创建对象
2. 还有两个survivor分区,主要进行复制收集存活的对象
3. 当Eden区内存不足时就会触发Minor GC
4. 年轻代如何晋升到老年代
1. 经历一定次数的Minor GC仍存活的对象,默认15次
2. survivor区中存不下时,根据分配担保晋升到老年代
3. Eden区创建的对象太大了
2. 老年代:主要使用标记-整理、标记-清除算法,发生FULL GC,或者叫做Major GC
1. Full GC比Minor GC慢,但是执行的频率比较低,但是触发Full GC的时候,也会回收年轻代的垃圾
2. 触发FullGC的条件:
1. 老年代空间不足的时候
2. 永久代空间不足的时候,这里只针对JDK8之前,8之后取消了永久代,新增了元空间;
3. CMS GC出现:
4. MinorGC晋升到老年代的平均大小>l老年代剩余空间了
5. 调用了system.gc();这里只是进行提示,收集的主动权还在jvm
6. 使用RMI进行RPC或者管理JDK应用,每小时执行一次Full GC
Stop-the-world:
1. JVM 由于要进行GC,而停止了应用程序的执行,这就叫做stop-the-world
2. 任何一种GC都会发生STW
3. GC优化主要就是优化STW的时间
Safepoint
1. 分析过程中对象引用关系不会发生变化的点
2. 产生safeponit的地方:方法调用,循环跳转,异常跳转
3. 安全点数量得适中,过多的话就会发生频繁GC,过少的话,GC等待的时间有过长
常用的垃圾收集器:
1. Serial收集器:(-XX:+UseSerialGC,复制算法)
1. 这是一种单线程的收集器:收集时需要暂停所有的工作线程
2. 简单高效,这是Client模式下默认的年轻代收集器

2. ParNew收集器:(-XX:UseParNewGC,复制算法)
1. 多线程收集:行为特点与Serial一样
2. 只有在多核条件下才有优势

3. Parallel Scavenge收集器:(-XX:+UseParallelGC,复制算法)
1. 吞吐量=运行用户代码时间/运行用户代码时间+垃圾收集时间
2. 该收集器更关注吞吐量,前面俩收集器更关注线程停段时间
3. 在多核执行才有优势,这是server模式下默认的年轻代垃圾收集器;
4. 有个自适应机制可以配置
4. Serial Old收集器:(-XX:+UseSerialOld GC,标记整理算法)
1. 工作原理跟年轻代的Serial类似,都是单线程的,但是使用的是标记-整理算法
2. 简单高效,是Client模式下默认的老年代收集器
5. Parallel Old收集器:(-XX:+UseParallelOld GC,标记整理算法)
1. 该收集器是JDK6开始才问世的,且不是跟Parallel Scavenge一起出现的
2. 该收集器主要关注吞吐量,且多核下才有优势
6. CMS收集器:(-XX:+UseConcMarkSweepGC,标记-清除算法),该收集器几乎可以做到和用户线程同时工作,CMS工作原理主要分为以下六步骤:
1. 初始化标记:首次stop-the-world,这次时间很短,因为只标记GCROOT直接相连的对象
2. 并发标记:并发追溯标记,程序不停止,标记线程可与用户线程共存
3. 并发预处理:查找执行并发标记时,从年轻代晋升到老年代的对象
4. 重新标记:再次stop-the-world,扫描CMS堆中的剩余对象
5. 并发清理:清理垃圾对象,程序不停顿(会有碎片问题)
6. 并发重置:重置CMS收集器的数据结构,等待下一次收集

7. G1收集器:(复制和标记-整理算法),该收集器既收集年轻代,又收集老年代;它的使命就是来代替CMS收集器,因为CMS收集器,会产生碎片化的问题;该收集器主要与以下四个特征:
1. 并发和并行,这里主要是为了缩短STW的时间
2. 分代收集:复制算法收集年轻代,标记-整理算法收集老年代
3. 空间整合:使用Compacting解决CMS的碎片化问题
4. 可预测的停顿:
5. 这里再多说点,该收集器会将内存成多个region,这里的region是一个1~31m的独立单元(2的幂),而且年轻代和老年代不再是物理隔离的,也就是当前区域现在是年轻代,过了一阵经过GC后,可能就用了存储老年代了;
几种垃圾收集器的组合选择
1. 单核服务器:
1. -XX:+UseSerialGC,年轻代使用Serial,老年代使用Serial Old
2. 多核,追求吞吐,如计算应用型服务器
1. -XX:+UseParallelGC或者-XX:+UseParallelOldGC,年轻代Parallel,老年代ParallelOld
3. 多核,追求响应速度,低停顿
1. -XX:+UseConcMarkSweepGC,年轻代ParNew,老年代CMS,备用担保SerialOld
下面将一下finalize()方法:
当一个对象被标记为可回收对象的时候,垃圾收集器并不会立即收集它,如果这个对象实现了finalize()方法,并且该方法已经执行了,或者没有实现finalize()那么垃圾收集器一会就会回收它;如果被标记后,还没有调用finalize()方法,那么该对象会被放入到一个叫做F-Queue的队列中,等待执行finalize(),这是最后一次逃离收集的机会,因为该方法只会被执行一次;
JVM调优知识点(没有调优实战)
1、首先看一下jvm参数查询的命令
1、查看JVM参数的方式一,多步骤
查看进程:jps -l
查看该进程号具体JVM参数的信息:jinfo -flag 具体参数 进程号
查看该进程号所有JVM参数的信息:jinfo -flags 进程号
2、查看JVM参数的方式二
查看JVM初始参数:java -XX:+PrintFlagsInitial -version
查看修改后的JVM参数:java -XX:+PrintFlagsFinal -version
=表示是初始值
:=表示是修改后的值
查看修改后的(:=)JVM参数java -XX:+PrintCommandLineFlags -version
2、JVM中重要参数的含义
-Xms1024m = -XX:InitialHeapSize=1024m 默认单位为字节,默认大小为内存的1/64
-Xmx1024m = -XX:MaxHeapSize=1024m 默认单位为字节,默认大小为内存的1/4
-Xss1m = -XX:ThreadStackSize=1m 一般为512k~1024k,ThreadStackSize为0时,表示使用默认的栈内存,32位默认为512k,64位默认为1024k,linux上默认为1024k,不同版本的系统还有出入;
-Xms 设置年轻代大小
-XX:MetaSpaceSize 元空间尽量设置大点,占用本机内存一般512m
-XX:MaxMetaspaceSize1024m
-XX:+PrintGCDetails 输出GC详细的日志信息
-XX:SurvivorRatio eden区和survivor区的大小比值,默认为8
-XX:NewRatio 老年代与新生代内存占比,默认为2
-XX:MaxTenuringThreshold 年轻代最大年龄,超过了,就会成为老年代
3、几种常见OOM
1、StackOverFlowError
2、OutOfMerroryError:java heap space
.intern();
3、OutOfMerroryError:GC overhead limit exceeded 花费98%的时间,回收的堆内存不到2%,CPU占用会增大到100%
-XX:MaxDirectMemorySize=5m 直接内存的大小
4、OutOfMerroryError:Direct buffer memory 直接内存被占满,主要是nio程序中会出现
5、OutOfMerroryError:Unable to create new native thread 不能创建过多的native线程,Linux默认创建1024个
为什么是native
private native void start0();
ulimit -u查询用户下的最大线程数
less /etc/security/limits.d/90-nproc.conf
6、OutOfMerroryError:MetaSpace 元空间满了
4、查看jvm的GC情况
jstat -gcutil 进程号
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 34.42 5.21 96.86 94.12 2 0.190 7 1.465 1.655
这里的full gc次数 和时间 指标很能显示系统性能问题,这两个指标很大,很大程度上说明了程序中有问题,垃圾一直回收不掉
S0 — Heap 上的 Survivor space 0 区已使用空间的百分比
S1 — Heap 上的 Survivor space 1 区已使用空间的百分比
E — Heap 上的 Eden space 区已使用空间的百分比
O — Heap 上的 Old space 区已使用空间的百分比
M — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间( 单位秒 )
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间( 单位秒 )
GCT — 从应用程序启动到采样时用于垃圾回收的总时间( 单位秒)
总结
工作几年了,也积累了一些内容,陆续都会搬到博客上了,整理不宜,转载请指明出处,共同进步吧!

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









