







Jmeter_性能测试(4):
性能测试脚本的优化
以PHP论坛为例:http://47.107.178.45/phpwind/
根据上一篇的性能测试(3)的脚本进行优化;见下图:

如上图中,把发帖和回帖的事务添加到随机控制器中,登录操作添加到仅一次控制器中,线程组中循环5次操作,在察看结果树中看执行结果或者去网站界面查看结果
Jmeter_性能测试(5):负载测试和压力测试
负载测试
负载测试/容量测试:通过在测试过程中不断的调整负载,找到在多少用户量情况下,系统出现性能下降拐点;也被称为容量测试;
举例:
微信发送红包的负载测试:
1、找运维人员了解目前系统的在线用户数,以该值作为参考比如500;通过下方的用户数量一步步增加负载,找到最终可负载的用户数比如2200;
500用户 ----- 广义并发执行发红包脚本 ----- 3小时 ==》CPU、内存、tps等正常
1000用户 ----- 广义并发执行发红包脚本 ----- 3小时 ==》CPU、内存、tps等正常
3000用户 ----- 广义并发执行发红包脚本 ----- 3小时 ==》CPU、内存、tps等不正常
2000用户 ----- 广义并发执行发红包脚本 ----- 3小时 ==》CPU、内存、tps等正常
2500用户 ----- 广义并发执行发红包脚本 ----- 3小时 ==》CPU、内存、tps等不正常
一般情况下,负载测试要优先于压力测试执行
负载测试设置:
以下图举例:正常在项目中的用户数量比下图中的线程数要多

压力测试(并发测试)
压力测试/强度测试:在项目中用户常用的功能进行高负载的测试,防止局部崩溃问题;
以上方微信发红包为例经过负载测试之后,得出负载极限用户为2200
瞬间高压:2300用户 ----- 同时执行发红包脚本 ----- 1次 ==》CPU、内存、tps等正常
长时间的高负载:2150 用户 ----- 运行性能测试2-3天 ==》CPU、内存、tps等正常
压力测试:模拟狭义的并发(集合点),一般使用同步定时器完成并发测试;
同步定时器参考地址:https://i.cnblogs.com/posts/edit;postId=16071878

Jmeter_性能测试(6):收集性能测试结果
收集性能测试结果
性能测试执行过程中,场景监控的主要任务是收集测试结果,测试结果有事 务响应时间、吞吐量、TPS、服务器硬件性能、JVM使用情况和数据库性能状态 等。Jmeter中通过监听器及其它外置工具来完成测试结果收集工作
事务响应时间
用户从发出请求到接收完响应之间的总耗时,它由网络传输耗时、服务处理 耗时等多个部分组成。通常以毫秒(ms)作为单位。站在用户角度来说,你可 以将软件性能看作是软件对用户操作的响应时间。
吞吐量
指在一次性能测试过程中网络上传输的数据量的总和。对于交互式应用来说, 吞吐量指标反映的是服务器承受的压力,在容量规划的测试中,吞吐量是一个重 点关注的指标,因为它能够说明系统级别的负载能力,另外,在性能调优过程中, 吞吐量指标也有重要的价值。如一个大型工厂,他们的生产效率与生产速度很快, 一天生产10W吨的货物,结果工厂的运输能力不行,就两辆小型三轮车一天拉2 吨的货物
吞吐率
单位时间内网络上传输的数据量,也可以指单位时间内处理客户请求数量。 它是衡量网络性能的重要指标,通常情况下,吞吐率用“字节数/秒”来衡量,当然, 你可以用“请求数/秒”和“页面数/秒”来衡量。其实,不管是一个请求还是一个页面, 它的本质都是在网络上传输的数据,那么来表示数据的单位就是字节数。
HTTP 服务的吞吐率通常以 RPS(Requests Per Second 请求数每秒)作 为单位。吞吐量越高,代表服务处理效率就越高。也可以说就是网站的性能越高。
注意:吞吐率和并发数是两个完全独立的概念。
TPS
Transaction Per Second:每秒事务数,指服务器在单位时间内(秒)可以处理 的事务数量,一般以request/second为单位;它是衡量系统处理能力的重要指标。
QPS
Query Per Second:每秒查询率,指服务器在单位时间内(秒)处理的查 询请求速率,属于TPS的子集。
资源利用率
资源利用率指的是对不同系统资源的使用程度,例如服务器的CPU利用率、 磁盘利用率等。资源利用率是分析系统性能指标而改善性能的主要依据,因此, 它是Web性能测试工作的重点。
CPU使用率
指用户进程与系统进程消耗的CPU时间百分比,长时间情况下, 一般可接受上限不超过85%;
内存利用率
内存利用率=(1-空闲内存/总内存大小)*100%,一般至少有10% 可用内存,内存使用率可接受上限为75% ,85%;
磁盘I/O
磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对 应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操 作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘 读写性能
网络带宽
一般使用计数器Bytes Total/sec来度量,其表示为发送和接收字节的 速率,包括帧字符在内;判断网络连接速度是否是瓶颈,可以用该计数器的值和 目前网络的带宽比较
Jmeter(7):利用jmeter插件收集性能测试结果&汇总报告和聚合报告
利用jmeter插件收集性能测试结果
汇总报告(Summary Report )
用来收集性能测试过程中的请求以及事务各项指标。通过监听器--汇总报告 可以添加该元件。界面如下图所示

汇总报告界面介绍:
所有数据写入一个文件:保存测试结果到本地。
文件名:指定保存结果。
仅错误日志:仅保存日志中报错的部分。
仅成功日志:保存日志中成功的部分。
配置:设置结果属性,即保存哪些结果字段到文件。一般保存必要的字段信息即可,保存的越多,对负载机的IO会产生影响。
Label:取样器名称(或者是事务名)。
#样本:取样器运行次数(提交了多少笔业务)。
平均值:请求(事务)的平均响应时间,单位为毫秒。
最小值:请求的最小响应时间,单位为毫秒。
最大值:请求的最大响应时间,单位为毫秒。
标准偏差:响应时间的标准偏差。(反应的是系统的稳定性)
异常%:事务错误率。
吞吐率:即TPS。 ==》每秒事务数 == 单位时间内的事务数
接收 KB/sec:每秒数据包流量,单位是KB。
发送 KB/sec:每秒数据包流量,单位是KB。
平均字节数:平均数据流量,单位是Byte。平均字节数 * #样本 = 吞吐量
聚合报告(Aggregate Report)
用来收集性能测试过程中的请求以及事务各项指标。通过监听器--聚合报告 可以添加该元件。界面如下图所示
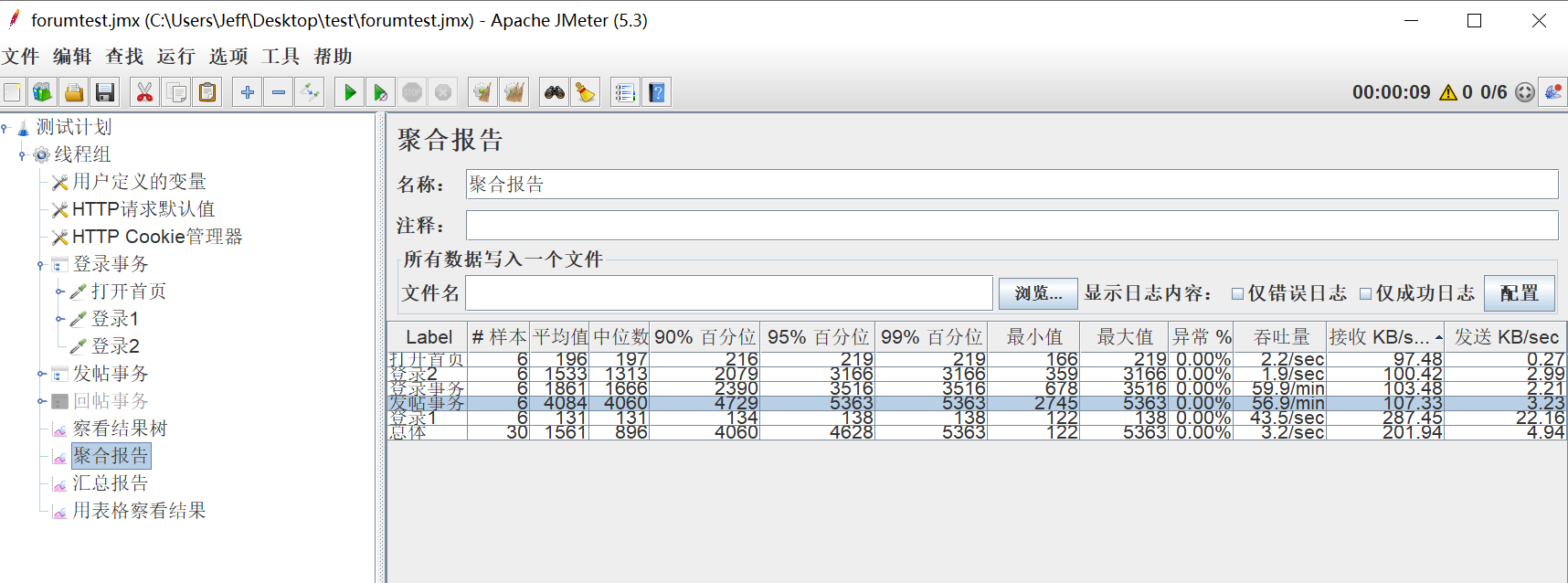
聚合报告界面介绍:
所有数据写入一个文件:保存测试结果到本地。
文件名:指定保存结果。
仅错误日志:仅保存日志中报错的部分。
仅成功日志:保存日志中成功的部分。
配置:设置结果属性,即保存哪些结果字段到文件。一般保存必要的字段 信息
即可,保存的越多,对负载机的IO会产生影响。
Label:取样器名称(或者是事务名)。
#样本:取样器运行次数(提交了多少笔业务)。
平均值:请求(事务)的平均响应时间,单位为毫秒。
中位数:50%的请求耗时都在这个时间之下
90%百分位:90%的请求耗时都在这个时间之下
95%百分位:95%的请求耗时都在这个时间之下
99%百分位:99%的请求耗时都在这个时间之下(汇总报告中,标准偏差很大,使用百分位的值作为参考)
最小值:请求的最小响应时间,单位为毫秒。
最大值:请求的最大响应时间,单位为毫秒。
异常%:事务错误率。
吞吐率:即TPS。
接收 KB/sec:每秒数据包流量,单位是KB。
发送 KB/sec:每秒数据包流量,单位是KB。
Jmeter(8):利用PerfMon插件收集监控服务器资源指标
利用PerfMon插件收集监控服务器资源指标
在使用Jmeter执行性能测试时,为了尽量减少负载机的资源消耗,一般不建 议使用服务器资源监控的功能。而可以使用第三方工具去监控收集服务器资源。 但一些普通的场景(负载小)还是可以利用Jmeter来进行服务器资源监控的。
监控服务器资源(如:CPU、内存等)
方式一、利用jmeter第三方插件
配置如下:
1、安装jmeter第三方插件管理工具jmeter-plugins-manager-*.**.jar,下载该文件放置到jmeter安装目录/lib/ext,然后重启jmeter即安装完毕
2、从菜单--选项--Plugins Manager,进入插件管理界面,下载PerfMon(Servers Performance Monitoring)插件,重启Jmeter,在监听器中可看到该插件
PerfMon插件安装参考:https://www.cnblogs.com/YouJeffrey/p/16212939.html
3、下载ServerAgent-*.*.*.zip,把该压缩包在被测服务器上解压,解压后在dos命令窗口运行startAgent.sh命令,默认使用4444端口
3.1、安装JDK1.8以上版本
3.2、解压ServerAgent压缩包
3.3、windows系统上双击startAgent.bat开始监控 / mac和linux系统可在dos命令 sh startAgent.sh或者./startAgent.sh 执行开启;
ServerAgent网盘地址:
链接:https://pan.baidu.com/s/1AtOwv0d3F2KYeyLhe2Ks-A
提取码:whse

4、在Jmeter工具端输入被测服务器IP 和端口4444 ,查看被测服务器是否有收到相应信息,收到表示连接正常,如果连接异常检查防火墙是否没有关闭(在项目中要和运维协调关闭防火墙)等原因。
5、在Jmeter控制机添加一个PerfMon Metrics Collector监听器,点击运行即可获取
注:不能再同一个插件上监控不同的指标,如想监控不同指标比如CPU和内存可打开两个PerfMon插件监控;如下图

在进行性能测试的时候是通过命令行执行脚本,但是又想监控服务器的资源,怎么办?
1、通过jmeter -n -t 脚本路径 -l 指定jtl文件路径;使用该命令执行的时候,不能让jp@gc - PerfMon Metrics Collector插件生成结果,因为jtl文件中没有结果;
处理办法:
1、在脚本中增加jp@gc - PerfMon Metrics Collector插件并配置好结果生成的路径即可;会在命令行执行结束后再指定的路径生成自己定义的jtl结果文件;

2、在命令行执行完脚本后,打开jmeter在监听器中添加jp@gc - PerfMon Metrics Collector,并把生成的cpu.jtl文件导入查看资源占用的结果;


Jmeter(9):硬件性能监控指标
硬件性能监控指标
一、性能监控初步介绍
性能测试的主要目标
1.在当前的服务器配置情况,最大的用户数
2.平均响应时间ART,找出时间较长的业务
3.每秒事务数TPS,服务器的处理能力
性能测试涉及的内容
1.客户端性能测试:web前端性能、app性能
2. 网络性能测试
3. 服务器应用程序性能
4. 服务器硬件性能
5. 数据库的性能
二、linux性能监控--CPU
CPU相关的指标
1. CPU使用率:sys% user%(系统的cpu使用率和用户的cpu使用率)
2. 队列长度
1. 查看CPU使用率
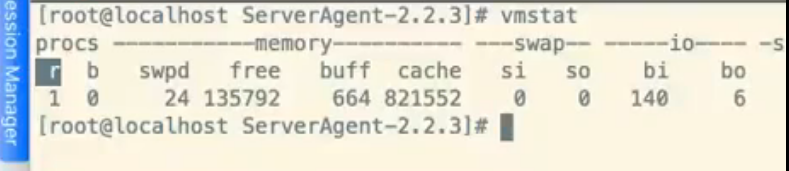
使用vmstat 或top 查看CPU使用情况 us 和sy
标准: cpu使用率: us+sy不能超过75%,偶尔可以100%
vmstat 5:每5秒采集一次

vmstat 主要参数说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我 本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M (这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断。
- cs 每秒上下文切换次数,上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间。
2.查看队列长度
使用vmstat -5 执行,查看 r列的数据
标准:队列长度不能超过2,有队列的产生,或者CPU处理不过来
r值<=2
r值在[3,5]
r值在(5,10]
r值在 >10
3.查看CPU使用较大的进程
ps -aux查看进程的CPU使用情况
目的:找出高CPU的进程
ps auxw|head -1;ps auxw|sort -rn -k3|head -1 (查看CPU使用较大的前10个进程)

三、linux性能监控--内存
核心指标
1. 可用物理内存的比例
2. 是否使用了虚拟内存
3.是否存在内存泄漏
1. 查看物理内存的使用情况
free命令查看使用情况

标准:linux的可用物理内存可为0,全部用完,只要不使用虚拟内存
2.查看是否使用了虚拟内存
方法1: vmstat 查看si so列
标准: si 和so大于0,表示物理内存不够用或者内存泄露了

方法2: sar –W 10 3 (10和3代表了每个10秒监控一次,总共监控3次)
标准:值大于0,就说明内存已经饱和了
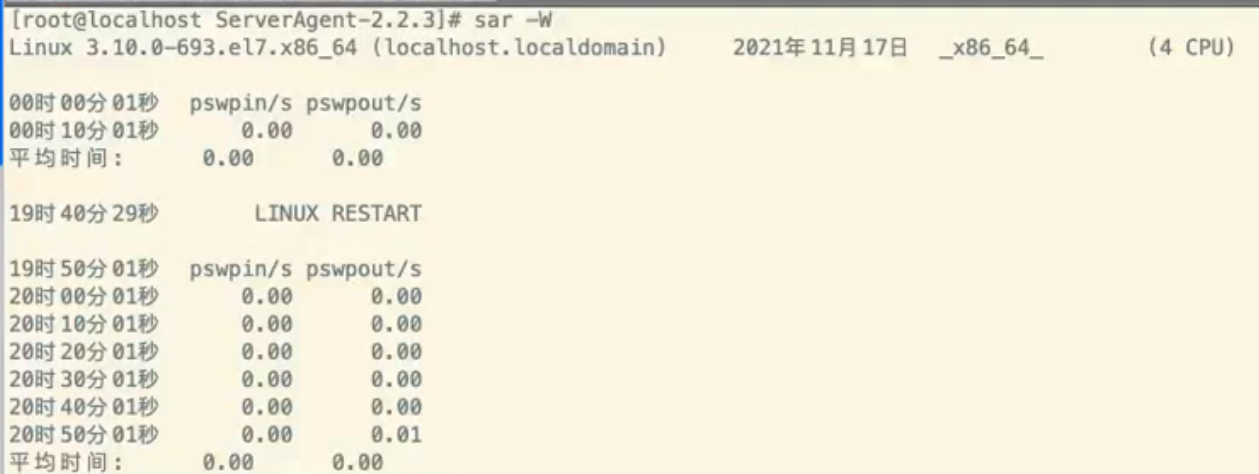
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
3. 找出高内存使用的进程
3.1内存消耗最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k4|head -10
3.2 虚拟内存使用最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k5|head
%MEM 进程的内存占用率
VSZ 进程所使用的虚存的大小
RSS 进程使用的驻留集大小或者是实际内存的大小
四、linux性能监控--硬盘IO的监控
核心指标
1.硬盘的使用率
2.物理硬盘驱动器忙于读或写入的时间
工具:iostat、iotop、pt-ioprofile
1. 查看硬盘的使用率: df -lh

2. 查看具体的那个硬盘的IO较高:
使用iostat 工具来查
ostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该 命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所 需的统计信息
安装iostat 安装命令: yum install sysstat

语法: iostat [ -c ] [ -d ] [ -h ] [ -N ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ] [ device
[...] | ALL ] [ -p [ device [,...] | ALL ] ] [ interval [ count ] ]
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以K为单位显示
-m 以M为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS使用情况
-p 可以报告出每块磁盘的每个分区的使用情况
-t 显示终端和CPU的信息 -x 显示详细信息
iostat -d -k 2
参数 -d 表示,显示设备(磁盘)使用状态;-k 某些使用 block为单位的列强制使用Kilobytes为单位;2表示,数据显示每隔2秒刷新一次。

iostat -x 5 查看:%util

%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒);
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
标准:物理硬盘驱动器忙于读或写入的时间 40% 60% 80%
3. 查看哪个进程耗IO比较高
使用iotop 命令: 查询出较大的IO 的进程
iotop是一个用来监视磁盘I/O使用状况的 top 类工具,可监测到哪一个程序使用的磁盘IO的信息
安装:yum install iotop
查看:iotop 按 o 只显示有磁盘 IO 活动的进程

语法:iotop [OPTIONS]
- --version #显示版本号
- -h, --help #显示帮助信息
- -o, --only #显示进程或者线程实际上正在做的I/O,而不是全部的,可以随时切换按o
- -b, --batch #运行在非交互式的模式
- -n NUM, --iter=NUM #在非交互式模式下,设置显示的次数,
- -d SEC, --delay=SEC #设置显示的间隔秒数,支持非整数值
- -p PID, --pid=PID #只显示指定PID的信息
- -u USER, --user=USER #显示指定的用户的进程的信息
- -P, --processes #只显示进程,一般为显示所有的线程
- -a, --accumulated #显示从iotop启动后每个线程完成了的IO总数
- -k, --kilobytes #以千字节显示
- -t, --time #在每一行前添加一个当前的时间
4. 定位来源文件
pt-ioprofile定位负载来源文件,通过iotop或ps找出负载较高的进程
安装: 下载地址https://www.percona.com/downloads/percona-toolkit/LATEST/
CentOS 7下安装:
yum -y install https://www.percona.com/downloads/perconatoolkit/3.0.1/binary/redhat/7/x86_64/percona-toolkit-3.0.1-1.el7.x86_64.rpm
使用:
命令格式:pt-ioprofile --profile-pid=xxx
pt-ioprofile --profile-pid=xxx --cell=size
pt-ioprofile --profile-pid=需要监控的PID --cell=size
pt-ioprofile的原理是对某个pid附加一个strace进程进行IO分析。
步骤1:iotop 查询出高io的pid
步骤2:pt-ioprofile --profile-pid=需要监控的PID --cell=size
对于定位问题更有用的是通过IO的吞吐量来进行定位。
使用参数 --cell=sizes,该参数将结果已 B/s 的方式展示出来
pt-ioprofile --profile-pid=需要监控的PID --cell=sizes
五、linux性能监控--网络监控
网络的监测是所有 Linux 子系统里面最复杂的,有太多的 因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与 Linux 主机相连的路由器、交换机、无线信号都会影响到整体 网络并且很难判断是因为 Linux 网络子系统的问题还是别的设 备的问题,增加了监测和判断的复杂度。
核心指标
1. 网络带宽是否够用
2. 丢包率、错误重传
3. 网络延迟/堵塞
4. 网络错误
监控网络操作步骤
1.查每秒接受和发送的数据量,检查当前带宽是否够用
使用nicstat 工具查看网卡的利用率
nicstat可以提供更加全面的网卡信息。
- 显示TCP流量统计
- 显示UDP流量统计
- 报告进出网卡的字节数
- 报告进出网卡的数据数
- 报告网卡利用率
- 报告NIC饱和度和其他信息
nicstat下载
cd /usr/local/src
wget http://nchc.dl.sourceforge.net/project/nicstat/nicstat-1.92.tar.gz
nicstat安装
tar -xzf nicstat-1.92.tar.gz
cd nicstat-1.92
cp Makefile.Linux Makefile
make
nicstat使用
./nicstat.sh

Time列:表示当前采样的响应时间
lo and eth0 : 网卡名称。
rKB/s : 每秒接收到千字节数。
wKB/s : 每秒写的千字节数。
rPk/s : 每秒接收到的数据包数目。
wPk/s : 每秒写的数据包数目。
rAvs : 接收到的数据包平均大小。
wAvs : 传输的数据包平均大小。
%Util : 网卡利用率(百分比)。
Sat : 网卡每秒的错误数.网卡是否接近饱满的一个指标.尝试去诊断网络问题的时候,推荐使用-x选项去查看更多的统计信息。
./nicstat.sh –t 用于查看tcp信息

InKB : 表示每秒接收到的千字节
OutKB : 表示每秒传输的千字节
InSeg : 表示每秒接收到的TCP数据段(TCP Segments)
OutSeg : 表示每秒传输的TCP数据段(TCP Segments)
Reset : 表示TCP连接从ESTABLISHED或CLOSE-WAIT状态直接转变为CLOSED状态的次数
AttF : 表示TCP连接从SYN-SENT或SYN-RCVD状态直接转变为CLOSED状态的次数,再加上TCP连接从SYN-RCVD状态直接转变为LISTEN状态的次数
%ReTX : 表示TCP数据段(TCP Segments)重传的百分比.即传输的TCP数据段包含有一个或多个之前传输的八位字节
InConn : 表示TCP连接从LISTEN状态直接转变为SYN-RCVD状态的次数
OutCon : 表示TCP连接从CLOSED状态直接转变为SYN-SENT状态的次数
Drops : 表示从完成连接(completed connection)的队列和未完成连接(incomplete connection)的队列中丢弃的连接次数
./nicstat.sh -u 用于查看UDP信息

InDG : 每秒接收到的UDP数据报(UDP Datagrams)
OutDG : 每秒传输的UDP数据报(UDP Datagrams)
InErr : 接收到的因包含错误而不能被处理的数据包
OutErr :因错误而不能成功传输的数据包
./nicstat.sh –x 查看扩展信息
./nicstat.sh -a 等同于执行-t -u -x
2. 丢包率、错误重传
查看丢包方法1:使用ifconfig,查看 dropped是否有计数,有计数的话存在丢包的情况
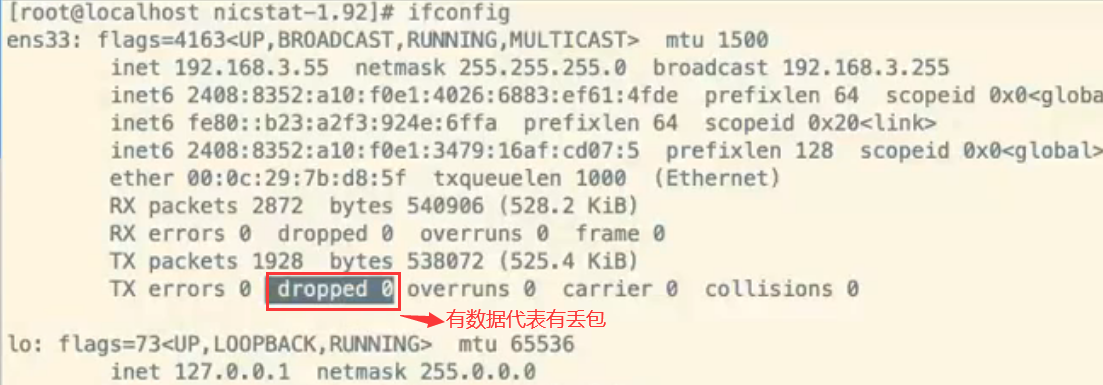
查看丢包方法2:sar -n EDEV 查看 #rxdrop/s
当由于缓冲区满的时候,网卡设备接收端每秒钟丢掉的网络包的数目

查看丢包的方法3:网络延迟:ping -c 次数 服务器IP或域名 查看packet los
例如: ping –c 100 www.baidu.com
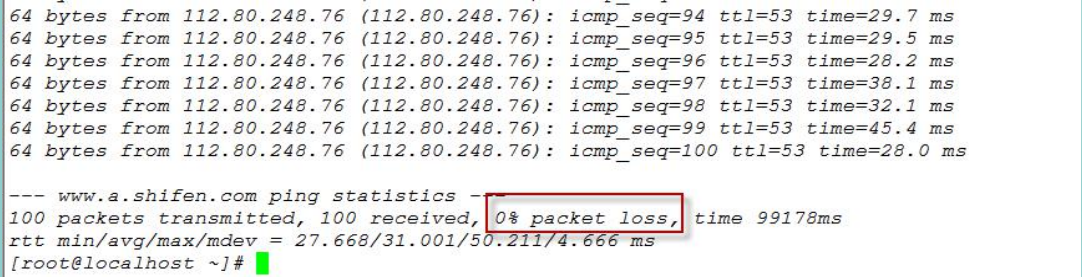
错误重传: ./nicstat.sh -t 查看%ReTX : TCP报文重传率
标准:<1%

3.网络延迟
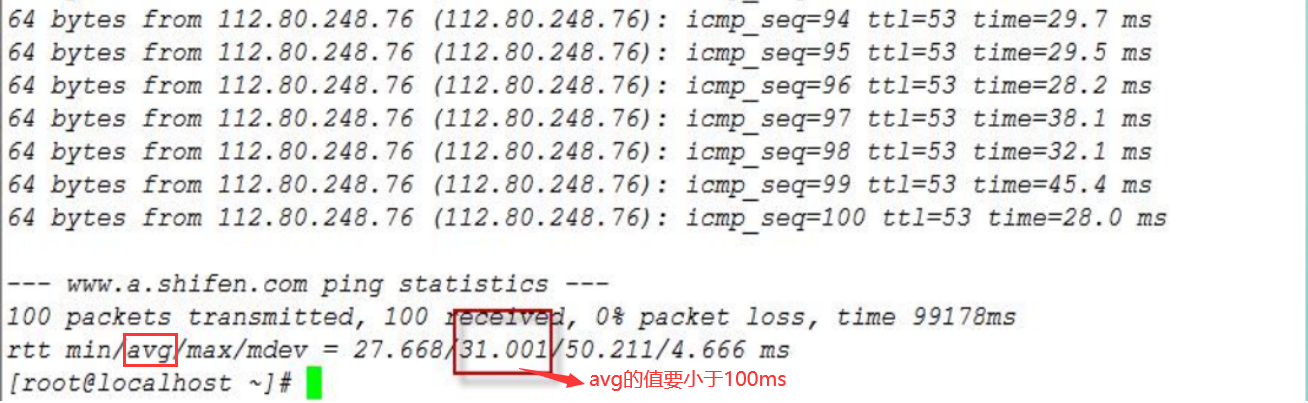
网络延迟:ping -c 次数 服务器IP或域名
标准:avg<100ms
例如: ping –c 100 www.baidu.com
4.网络错误
方法1: sar -n EDEV 查看:#txerr/s 每秒钟发送的数据包错误数

方法2: ifconfig 出现:"errors"
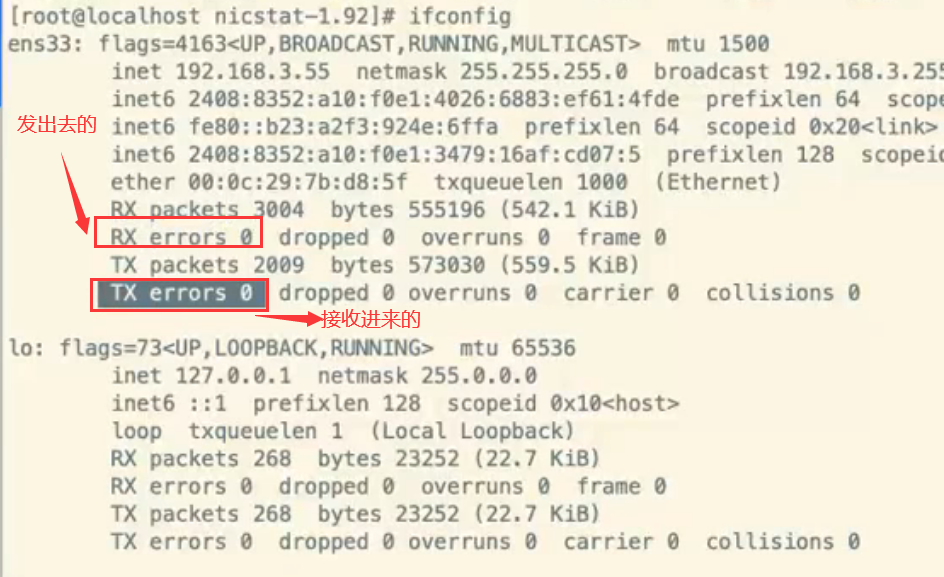
标准:不能出现错误
Jmeter(10):nmon性能系统监控工具
一、Nmon介绍
Nmon得名于 Nigel 的监控器,是IBM的员工 Nigel Griffiths 为 AIX 和 Linux 系统开发的,使用 Nmon 可以很轻松的监控系统的CPU、内存、网络、硬盘、文件系统、NFS、高耗进程、资源和 IBM Power 系统的微分区的信息
Nmon是一款计算机性能系统监控工具,因 为它免费,体积小,安装简单,耗费资源 低,广泛应用于AIX和Linux系统
监控硬件主要的指标
1. CPU
2. 内存
3. 硬盘IO
4. 网络
二、Nmon下载、安装
1.查看linux系统版本
方式1:cat /etc/redhat-release

方式2:cat /proc/version
方式3:uname –a

2.下载对应的版本
官网手动下载,地址: http://nmon.sourceforge.net/pmwiki.php?n =Site.Download

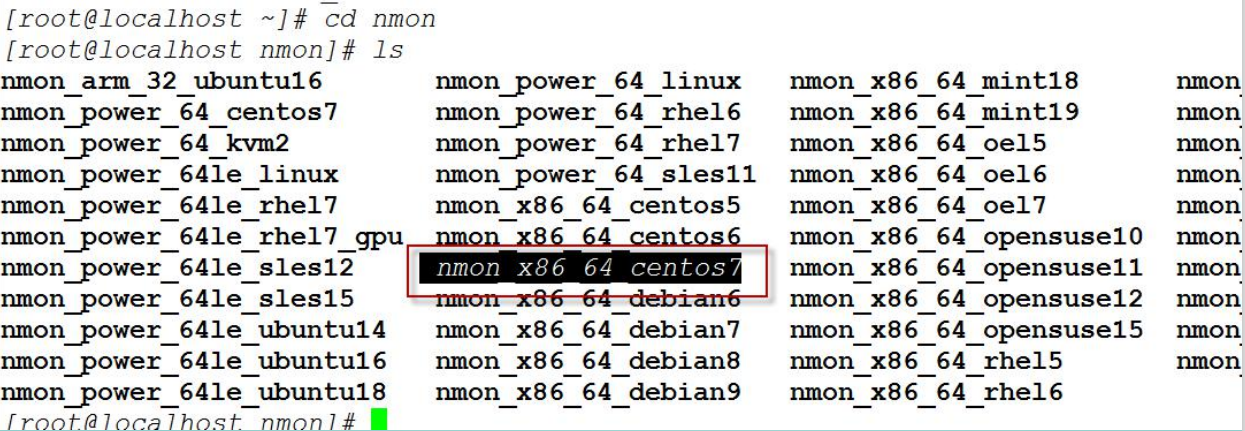
3. 解压安装
将下载的nmon16h_helpsystems_v2.tar.gz上传到centos7 操作系统上,并解压到一个文件夹中,然后从文件夹中找 到自己的系统对应的执行文件 nmon_x86_64_centos7
4. 授权、添加执行权限:
命令:chmod +x nmon_x86_64_centos7
5. 把执行文件复制到/usr/local/bin并改名为nmon
命令:mv nmon_x86_64_centos7/usr/local/bin/nmon
三、运行Nmon
在目录/usr/local/bin中,输入nmon命令启 动Nmon

参数说明
- q : 停止并退出 Nmon
- h : 查看帮助
- c : 查看 CPU 统计数据
- m : 查看内存统计数据
- d : 查看硬盘统计数据
- k : 查看内核统计数据
- n : 查看网络统计数据
- N : 查看 NFS 统计数据
- j : 查看文件系统统计数据
- t : 查看高耗进程
- V : 查看虚拟内存统计数据
- v : 详细模式
按下c,m,d等键后如下图,CPU、内存、磁盘等的消耗 情况都直观的展现出来了,按q键可以退出。

四、数据采集
执行性能场景的时候,我们需要根据测试场景的执行 情况,分析一段时间内系统资源的变化,这时需要nmon 采集数据并保存下来;
以下是常用的参数:
- -f 参数:生成文件,文件名=主机名+当前时间.nmon
- -T 参数:显示资源占有率较高的进程
- -s 参数:-s 10表示每隔10秒采集一次数据
- -c 参数:-c 10表示总共采集十次数据
- -m 参数:指定文件保存目录
先新建一个目录用例存放nmon的结果,例如: mkdir /root/nmon_result
监控1分钟:nmon -f -T -s 5 -c 12 -m /root/nmon_result,结果文件自动新建,文件名=主机名+当前时间.nmon
监控10分钟:nmon -f -T -s 10 -c 60 -m /root/nmon_result
监控1小时:nmon -f -T -s 30 -c 120 -m /root/nmon_res
监控24小时(15分钟采集一次):
nmon -f -T -s 900 -c 48 -m /root/nmon_resul
如果执行压力测试4小时,需要通过命令:nmon -f -T -s 60 -c 240 -m /root/nmon_result(通过nmon每隔60秒采集一次,一共采集240次,刚好4小时)

五、数据分析
数据分析,需要用到nmon analyser工具
1.下载nmon analyser
以前可以在IBM的官网下载: https://www.ibm.com/developerworks/community/wikis/home?lang= en#!/wiki/Power+Systems/page/nmon_analyser
目前下载路径如下: http://nmon.sourceforge.net/pmwiki.php?n=Site.Nmon- Analyser
NA_UserGuide v61.docx 是说明文档
nmon analyser v61.xlsm 分析工具
将之前的后缀名为nmon文件下载到windows操作系统中
2.打开nmon analyser,开启宏
Excel表直接开启宏就可以了;

如果是wps需要下载一个插件;地址: https://pan.baidu.com/s/1QzW4ebQxYQtxgVfkTmxVJ 下载 VBA7.0.1590_For WPS(中文).exe后,先退出WPS,再直接 安装就行,再次打开nmon analyser,启用宏
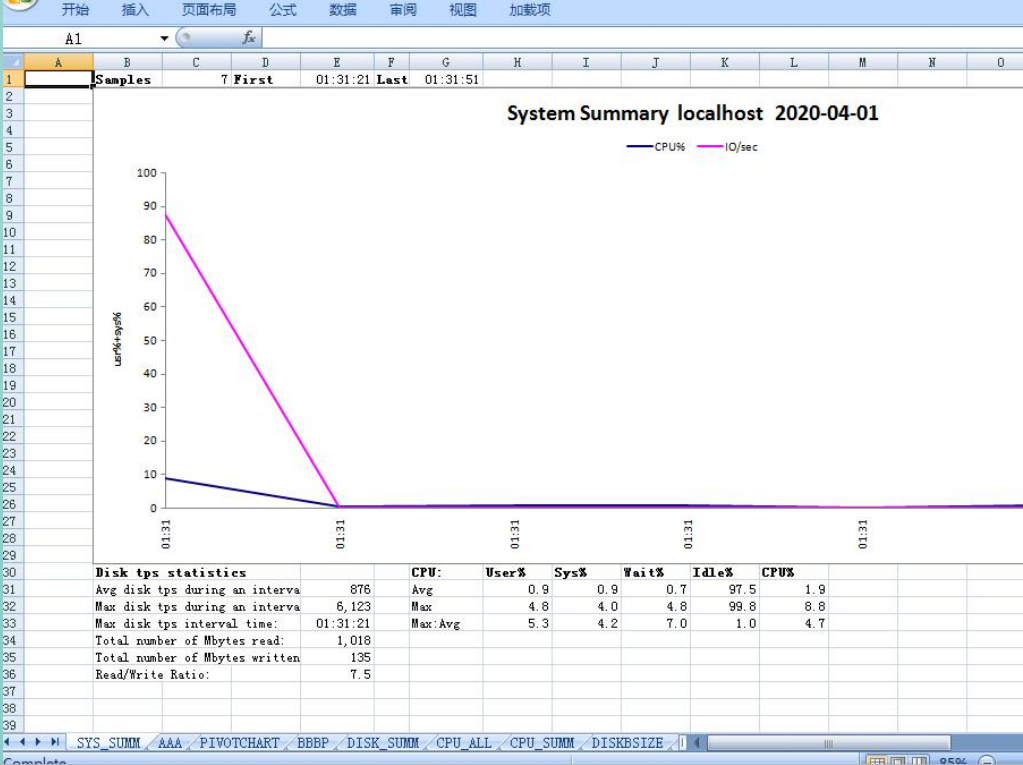
3.使用nmon analyser,加载我们上一步收 集的nmon文件

生成的Excel文件
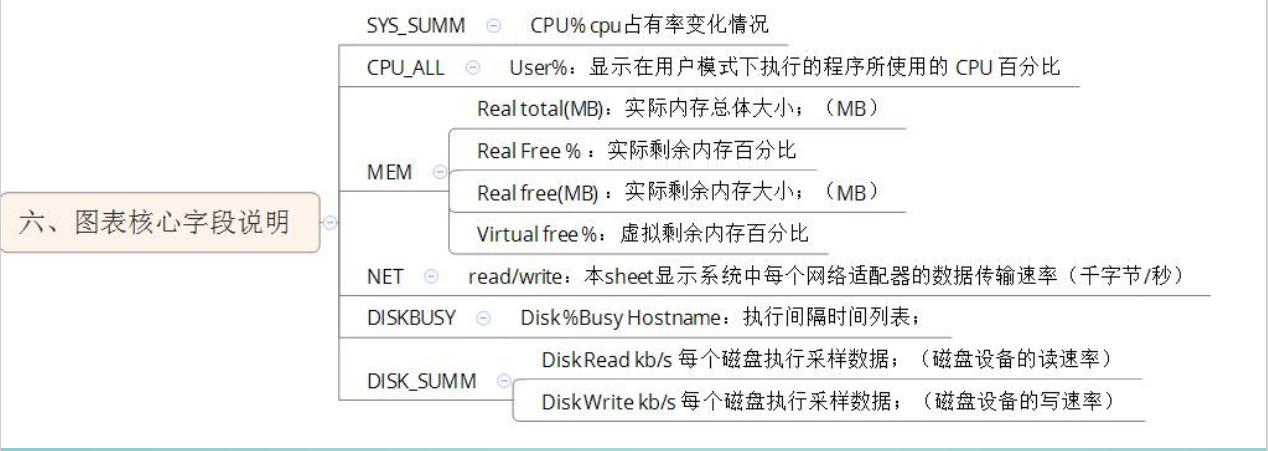
六、图表核心字段说明



核心需要熟悉的关键指标
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









