







bitmap
使用场景
用户签到
准备数据
SETBIT key offset value对指定的key的value的指定偏移(offset)的位置1或0, 其中key我们可以设置为当天的年月日,offset是用户uid(这里暂时只考虑uid是纯数字的情况),value的话1表示已签到。
SETBIT 20190601 12500 1
SETBIT 20190602 12500 1
SETBIT 20190603 12500 1
SETBIT 20190601 12501 1
SETBIT 20190602 12502 1
SETBIT 20190601 12503 1
SETBIT 20190602 12503 1
SETBIT 20190603 12504 1
SETBIT 20190603 12503 1#查询用户某天是否签到
GETBIT 20190501 12500,返回1表示已签到,0未签到。#如果需要查询某天有多少人签到
BITCOUNT 2019050
#查询连续签到的有多少人
bitop AND 3_201906_sign 20190601 20190602 20190603
BITCOUNT 3_201906_sign
判断登录状态
#第一步,执行以下指令,表示用户已登录。
SETBIT login_status 10086 1
#第二步,检查该用户是否登陆,返回值 1 表示已登录。
GETBIT login_status 10086
#第三步,登出,将 offset 对应的 value 设置成 0。
SETBIT login_status 10086 0
小结
思路才是最重要,当我们遇到的统计场景只需要统计数据的二值状态,比如用户是否存在、 ip 是否是黑名单、以及签到打卡统计等场景就可以考虑使用 Bitmap。
Set
使用场景
网站UV
#用户编号 89757 访问 「Redis 为什么这么快 」时,我们将这个信息放到 Set 中。
SADD Redis为什么这么快:uv 89757
#通过 SCARD 命令,统计「Redis 为什么这么快」页面 UV。
SCARD Redis为什么这么快:uv
交集-共同好友
比如 QQ 中的共同好友正是聚合统计中的交集。我们将账号作为 Key,该账号的好友作为 Set 集合的 value。
模拟两个用户的好友集合:
SADD user:码哥字节 R大 Linux大神 PHP之父
SADD user:大佬 Linux大神 Python大神 C++菜鸡
交集
SINTERSTORE user:共同好友 user:码哥字节 user:大佬
差集-每日新增好友数
比如,统计某个 App 每日新增注册用户量,只需要对近两天的总注册用户量集合取差集即可。
比如,2021-06-01 的总注册用户量存放在 key = user:20210601 set 集合中,2021-06-02 的总用户量存放在 key = user:20210602 的集合中。
SDIFFSTORE user:new user:20210602 user:20210601
并集-总共新增好友
还是差集的例子,统计 2021/06/01 和 2021/06/02 两天总共新增的用户量,只需要对两个集合执行并集。
SUNIONSTORE userid:new user:20210602 user:20210601
Hash
使用场景
网站UV
#输入数据
HSET uv 89757 1
HSET uv 89758 1
#统计 UV
HLEN uv
HyperLogLog
使用场景
网站UV
Set 虽好,如果文章非常火爆达到千万级别,一个 Set 就保存了千万个用户的 ID,页面多了消耗的内存也太大了。同理,Hash数据类型也是如此。咋办呢?HyperLogLog是王者方案
PFADD
将访问页面的每个用户 ID 添加到 HyperLogLog 中。
PFADD Redis主从同步原理:uv userID1 userID 2 useID3
PFCOUNT
利用 PFCOUNT 获取 「Redis主从同步原理」页面的 UV值。
PFCOUNT Redis主从同步原理:uv
UV数据合并
将多个 HyperLogLog 合并在一起形成一个新的 HyperLogLog 值
PFMERGE destkey sourcekey [sourcekey ...]
比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。
其中页面的 UV 访问量也需要合并,那这个时候 PFMERGE 就可以派上用场了,也就是同样的用户访问这两个页面则只算做一次。
如下所示:Redis、MySQL 两个 Bitmap 集合分别保存了两个页面用户访问数据。
PFADD Redis数据 user1 user2 user3
PFADD MySQL数据 user1 user2 user4
PFMERGE 数据库 Redis数据 MySQL数据
PFCOUNT 数据库 // 返回值 = 4
List
使用场景
最新评论
只有不需要分页(比如每次都只取列表的前 5 个元素)或者更新频率低(比如每天凌晨统计更新一次)的列表才适合用 List 类型实现。
对于需要分页并且会频繁更新的列表,需用使用有序集合 Sorted Set 类型实现。
每当一个用户评论,则利用 LPUSH key value [value ...] 插入到 List 队头。
LPUSH 码哥字节 1 2 3 4 5 6
接着再用 LRANGE key star stop 获取列表指定区间内的元素。
LRANGE 码哥字节 0 4
结果
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"
Sorted Set
需求场景
排行榜
我们将《青花瓷》和《花田错》《菊花台》播放量添加到 musicTop 集合中:
ZADD musicTop 100000000 青花瓷 8999999 花田错 200000000 菊花台
歌曲每播放一次就通过 ZINCRBY指令将 score + 1
ZINCRBY musicTop 1 青花瓷
ZINCRBY musicTop 1 花田错
获取榜单
#获取第一名
ZREVRANGE musicTop 0 0 WITHSCORES
#获取前两名
ZREVRANGE musicTop 0 1 WITHSCORES
#显示有序列表
ZRANGEBYSCORE musicTop -inf +inf
# 显示整个有序集及成员的 score 值
ZRANGEBYSCORE musicTop -inf +inf WITHSCORES
#显示点播量 <=100000000 的所有歌曲
ZRANGEBYSCORE salary -inf 100000000 WITHSCORES
#显示点播量在8999999和100000000的所有歌曲
ZRANGEBYSCORE salary (8999999 100000000
ZREVRANGE
可通过 ZREVRANGE key start stop [WITHSCORES]指令。
其中元素的排序按 score 值递减(从大到小)来排列。
具有相同 score 值的成员按字典序的逆序(reverse lexicographical order)排列。
小结
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议优先考虑使用 Sorted Set。
string
分布式锁
方案一:SETNX + EXPIRE
方案二:SETNX + value值是(系统时间+过期时间)
方案三:使用Lua脚本(包含SETNX + EXPIRE两条指令)
方案四:SET的扩展命令(SET EX PX NX)
方案五:SET EX PX NX + 校验唯一随机值,再释放锁
方案六: 开源框架~Redisson
方案七:多机实现的分布式锁Redlock
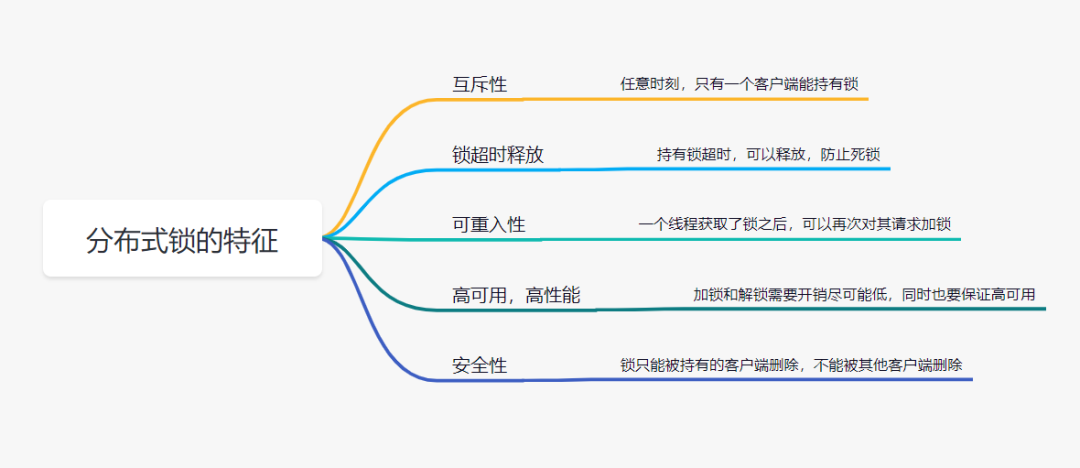
分布式锁特征
实现
消息队列
非阻塞队列
#入队列
LPUSH queue msg2
#出队列
RPOP queue

阻塞队列
#入队列
LPUSH bqueue msg2
#出队列
如果设置为 0,则表示不设置超时,直到有新消息才返回,否则会在指定的超时时间后返回 NULL
brpop bqueue 0

消息订阅
多消费者同时消费同一批数据
#发布
PUBLISH queueReading msg3
#订阅
SUBSCRIBE queueReading
Pub/Sub 的优缺点:
支持发布 / 订阅,支持多组生产者、消费者处理消息
消费者下线,数据会丢失
不支持数据持久化,Redis 宕机,数据也会丢失
消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失
有没有发现,除了第一个是优点之外,剩下的都是缺点。
所以,很多人看到 Pub/Sub 的特点后,觉得这个功能很「鸡肋」。
也正是以上原因,Pub/Sub 在实际的应用场景中用得并不多。

Stream
在 Redis 5.0 版本,作者把 disque 功能移植到了 Redis 中,并给它定义了一个新的数据类型:Stream。
XADD:发布消息
XADD key ID field value [field value ...]
XADD 命令发布消息,其中的「*」表示让 Redis 自动生成唯一的消息 ID
XADD queue * name zhangsan
XREAD:读取消息
XREAD COUNT 1 BLOCK 1000 mystream $
XREAD COUNT 1 BLOCK 1000 mystream 0-0
XREAD COUNT 1 mystream $
XREAD COUNT 1 mystream 0-0
#$,从当前时间开始接收,0-0,从第一条开始接收,COUNT接收一条,BLOCK等待1000ms
#注意block这里等待是等待服务器回复才会继续,等待是服务器等待

#队列长度
XLEN mystream
stream特性
Stream支持阻塞式拉取消息
可以的,在读取消息时,只需要增加 BLOCK 参数即可。
stream支持发布/订阅模式
XGROUP:创建消费者组
XREADGROUP:在指定消费组下,开启消费者拉取消息
Stream支持确认机制,重新消费
当一组消费者处理完消息后,需要执行 XACK 命令告知 Redis,这时 Redis 就会把这条消息标记为「处理完成」
stream支持发布消息时,你可以指定队列的最大长度,防止队列积压导致内存爆炸
XADD queue MAXLEN 10000 * name
Stream 还支持查看消息长度(XLEN)
查看消费者状态(XINFO)等命令
小结
Redis 本身可能会丢数据
面对消息积压,Redis 内存资源紧张
到这里,Redis 是否可以用作队列,我想这个答案你应该会比较清晰了。
如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
而且,Redis 相比于 Kafka、RabbitMQ,部署和运维也更加轻量。
如果你的业务场景对于数据丢失非常敏感,而且写入量非常大,消息积压时会占用很多的机器资源,那么我建议你使用专业的消息队列中间件。
延时队列
原理解析
实际上,redisson 使用了 两个list + 一个 sorted-set + pub/sub 来实现延时队列,而不是单一的sort-set。
sorted-set:存放未到期的消息&到期时间,提供消息延时排序功能
list-0:存放未到期消息,作为消息的原始顺序视图,提供如查询、删除指定第几条消息的功能(分析源码得出的,查看哪些地方有使用这个list)
list-q:消费队列,存放到期后的消息,提供消费
使用样例
public class DelayTest {
public static void main(String[] args) throws InterruptedException, UnsupportedEncodingException {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RBlockingQueue<String> blockingQueue = redisson.getBlockingQueue("dest_queue3");
RDelayedQueue<String> delayedQueue = redisson.getDelayedQueue(blockingQueue);
new Thread() {
public void run() {
while(true) {
try {
//阻塞队列有数据就返回,否则wait
System.err.println( blockingQueue.take()+" time="+System.currentTimeMillis());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
}.start();
for(int i=1;i<=5;i++) {
// 向阻塞队列放入数据
delayedQueue.offer("fffffffff"+i, 10*i, TimeUnit.SECONDS);
}
System.out.println("over!!!");
}
}来源
Redis位图实现7天连续签到_weixin_45970536的博客-CSDN博客_redis连续签到功能
实战!Redis 巧用数据类型实现亿级数据统计!_不才陈某的博客-CSDN博客
Redis的数据结构之List_笑我归无处的博客-CSDN博客_redis的list数据结构
redis | 六、redis之Set_雨中散步撒哈拉的博客-CSDN博客_redis set
redis计数操作_小周同学666的博客-CSDN博客_redis 计数














 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









