






第六章 External DataSource
在SparkSQL模块,提供一套完成API接口,用于方便读写外部数据源的的数据(从Spark 1.4版本提供),框架本身内置外部数据源:
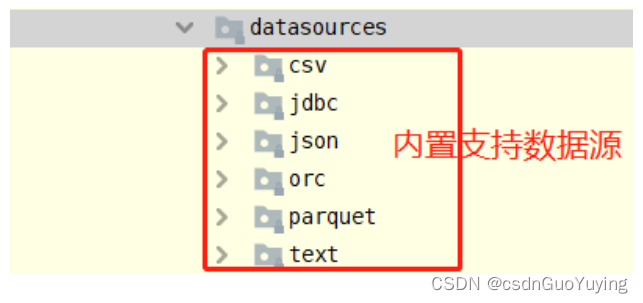
在Spark 2.4版本中添加支持Image Source(图像数据源)和Avro Source。
6.1 数据源与格式
数据分析处理中,数据可以分为结构化数据、非结构化数据及半结构化数据。

1)、结构化数据(Structured)
- 结构化数据源可提供有效的存储和性能。例如,Parquet和ORC等柱状格式使从列的子集中提取值变得更加容易。
- 基于行的存储格式(如Avro)可有效地序列化和存储提供存储优势的数据。然而,这些优点通常以灵活性为代价。如因结构的固定性,格式转变可能相对困难。
2)、非结构化数据(UnStructured)
- 相比之下,非结构化数据源通常是自由格式文本或二进制对象,其不包含标记或元数据以定义数据的结构。
- 报纸文章,医疗记录,图像,应用程序日志通常被视为非结构化数据。这些类型的源通常要求数据周围的上下文是可解析的。
3)、半结构化数据(Semi-Structured)
- 半结构化数据源是按记录构建的,但不一定具有跨越所有记录的明确定义的全局模式。每个数据记录都使用其结构信息进行扩充。
- 半结构化数据格式的好处是,它们在表达数据时提供了最大的灵活性,因为每条记录都是自我描述的。但这些格式的主要缺点是它们会产生额外的解析开销,并且不是特别为ad-hoc(特定)查询而构建的。
6.2 加载/保存数据
SparkSQL提供一套通用外部数据源接口,方便用户从数据源加载和保存数据,例如从MySQL表中既可以加载读取数据:load/read,又可以保存写入数据:save/write。
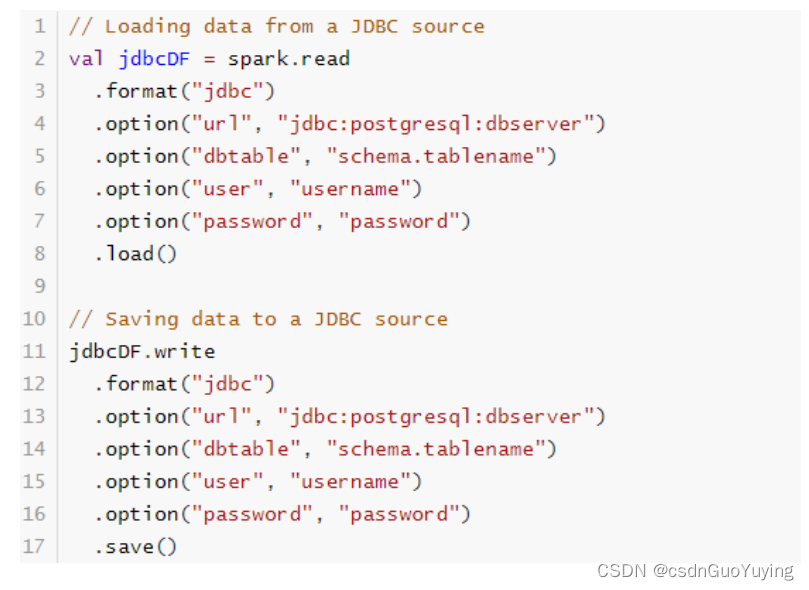
由于SparkSQL没有内置支持从HBase表中加载和保存数据,但是只要实现外部数据源接口,也能像上面方式一样读取加载数据。
Load 加载数据
在SparkSQL中读取数据使用SparkSession读取,并且封装到数据结构Dataset/DataFrame中。
DataFrameReader专门用于加载load读取外部数据源的数据,基本格式如下:

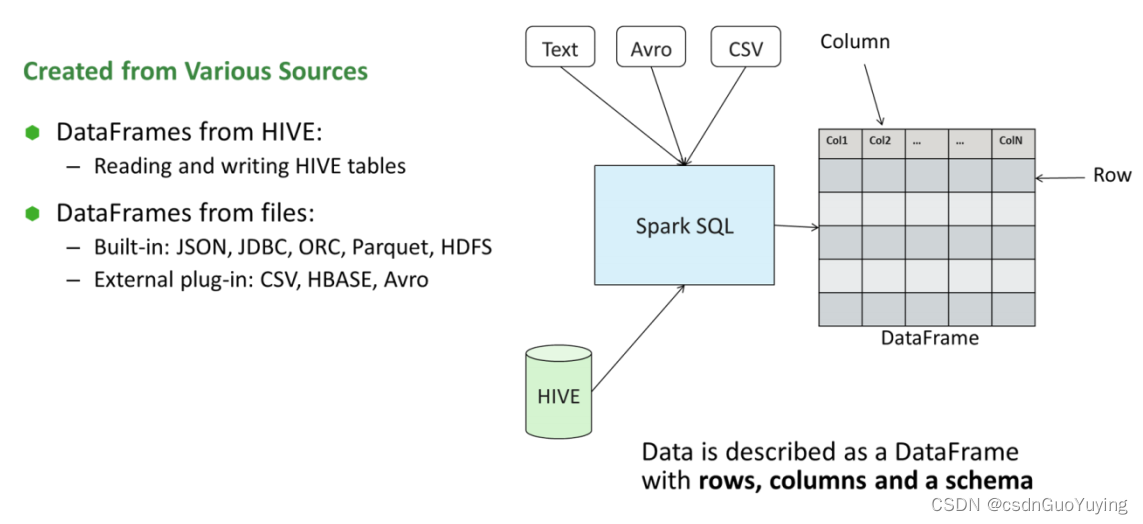
SparkSQL模块本身自带支持读取外部数据源的数据:

总结起来三种类型数据,也是实际开发中常用的:
第一类:文件格式数据
- 文本文件text、csv文件和json文件
第二类:列式存储数据 - Parquet格式、ORC格式
第三类:数据库表 - 关系型数据库RDBMS:MySQL、DB2、Oracle和MSSQL
- Hive仓库表
官方文档:http://spark.apache.org/docs/2.4.5/sql-data-sources-load-save-functions.html
此外加载文件数据时,可以直接使用SQL语句,指定文件存储格式和路径:

Save 保存数据
SparkSQL模块中可以从某个外部数据源读取数据,就能向某个外部数据源保存数据,提供相应接口,通过DataFrameWrite类将数据进行保存。

与DataFrameReader类似,提供一套规则,将数据Dataset保存,基本格式如下:

SparkSQL模块内部支持保存数据源如下:

所以使用SpakrSQL分析数据时,从数据读取,到数据分析及数据保存,链式操作,更多就是ETL操作。当将结果数据DataFrame/Dataset保存至Hive表中时,可以设置分区partition和分桶bucket,形式如下:

案例演示
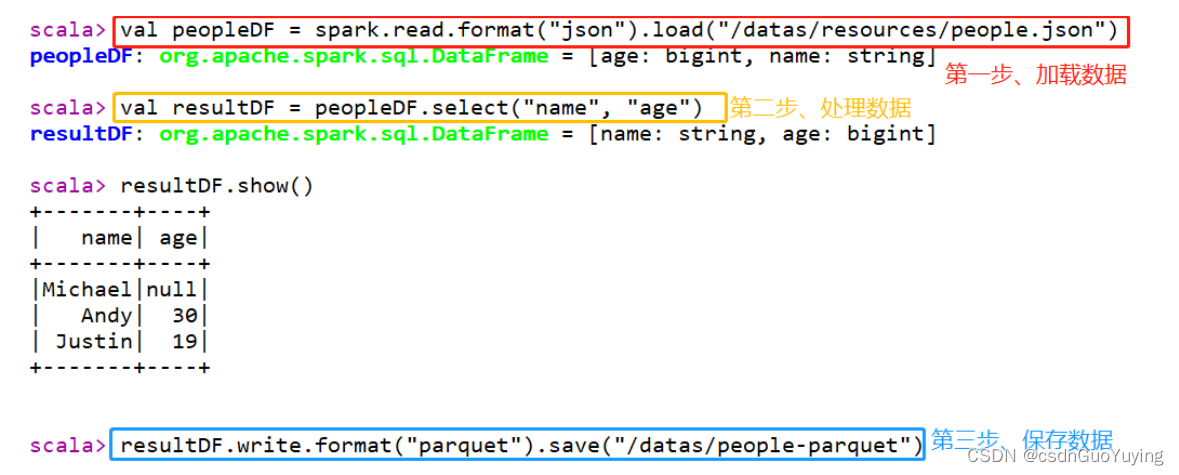
加载json格式数据,提取name和age字段值,保存至Parquet列式存储文件。
// 加载json数据
val peopleDF = spark.read.format("json").load("/datas/resources/people.json")
val resultDF = peopleDF.select("name", "age")
// 保存数据至parquet
resultDF.write.format("parquet").save("/datas/people-parquet")
在spark-shell上执行上述语句,截图结果如下:
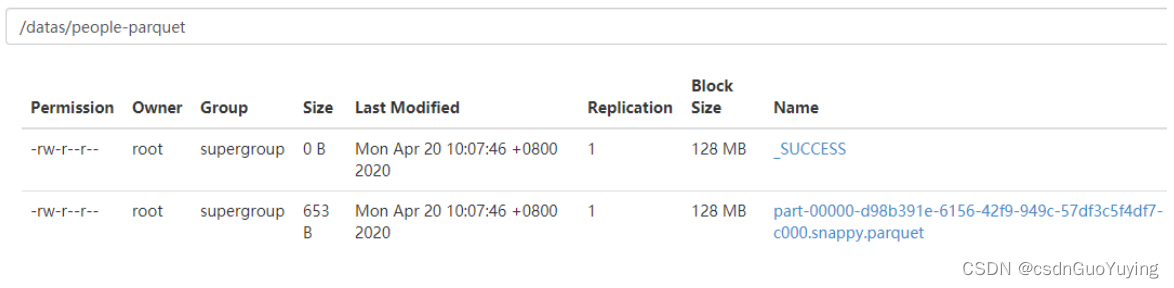
查看HDFS文件系统目录,数据已保存值parquet文件,并且使用snappy压缩。
保存模式(SaveMode)
将Dataset/DataFrame数据保存到外部存储系统中,考虑是否存在,存在的情况下的下如何进行保存,DataFrameWriter中有一个mode方法指定模式:

通过源码发现SaveMode时枚举类,使用Java语言编写,如下四种保存模式:
第一种:Append 追加模式,当数据存在时,继续追加;
第二种:Overwrite 覆写模式,当数据存在时,覆写以前数据,存储当前最新数据;
第三种:ErrorIfExists 存在及报错;
第四种:Ignore 忽略,数据存在时不做任何操作;
实际项目依据具体业务情况选择保存模式,通常选择Append和Overwrite模式。















 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











