







一.管道容量:管道容量分为pipi capacity 和 pipe_buf .这两者的区别在于pipe_buf定义的是内核管道缓冲区的大小,这个值的大小是由内核设定的,这个值仅需一条命令就可以查到;而pipe capacity指的是管道的最大值,即容量,是内核内存中的一个缓冲区。
pipe_buf: 命令:ulimit -a
在终端输入该命令就会出现如下一表:

管道容量 sizeof(pipe_buf)= 512 bytes* 8 = 4kb
pipi capacity:
当管道满的时候 O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
pipi capacity的大小需要写一段程序去检测,代码如下所示:
<span style="font-family:SimSun;font-size:12px;color:#33ff33;">#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include<errno.h>
#include<string.h>
#include<signal.h>
#define ERR_EXIT(m) \
do { \
perror(m); \
exit(EXIT_FAILURE); \
} while(0)
int main(int argc, char *argv[])
{
int pipefd[2];
if (pipe(pipefd) == -1)
ERR_EXIT("pipe error");
int ret;
int count = 0;
int flags = fcntl(pipefd[1], F_GETFL);
fcntl(pipefd[1], F_SETFL, flags | O_NONBLOCK); // 设置为非阻塞
while (1)
{
ret = write(pipefd[1], "A", 1);
if (ret == -1)
{
printf("err=%s\n", strerror(errno));
break;
}
count++;
}
printf("count=%d\n", count); //管道容量
return 0;
}</span>

由此图可知 pipe capacity的大小为 65536
二.管道缓冲区
1、管道(pipe)
管道是进程间通信的主要手段之一。一个管道实际上就是个只存在于内存中的文件,对这个文件的操作要通过两个已经打开文件进行,它们分别代表管道的两端。管道是一种特殊的文件,它不属于某一种文件系统,而是一种独立的文件系统,有其自己的数据结构。根据管道的适用范围将其分为:无名管道和命名管道。
● 无名管道
主要用于父进程与子进程之间,或者两个兄弟进程之间。在linux系统中可以通过系统调用建立起一个单向的通信管道,且这种关系只能由父进程来建立。因此,每个管道都是单向的,当需要双向通信时就需要建立起两个管道。管道两端的进程均将该管道看做一个文件,一个进程负责往管道中写内容,而另一个从管道中读取。这种传输遵循“先入先出”(FIFO)的规则。
● 命名管道
命名管道是为了解决无名管道只能用于近亲进程之间通信的缺陷而设计的。命名管道是建立在实际的磁盘介质或文件系统(而不是只存在于内存中)上有自己名字的文件,任何进程可以在任何时间通过文件名或路径名与该文件建立联系。为了实现命名管道,引入了一种新的文件类型——FIFO文件(遵循先进先出的原则)。实现一个命名管道实际上就是实现一个FIFO文件。命名管道一旦建立,之后它的读、写以及关闭操作都与普通管道完全相同。虽然FIFO文件的inode节点在磁盘上,但是仅是一个节点而已,文件的数据还是存在于内存缓冲页面中,和普通管道相同。
管道通讯如下图:

管道通讯带来的问题:管道容量不像其他文件一样不加检索的增长
1.使用单个固定缓冲区也会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写。
2.读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件结束的问题。
注意,从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛弃,释放空间以便写更多的数据。
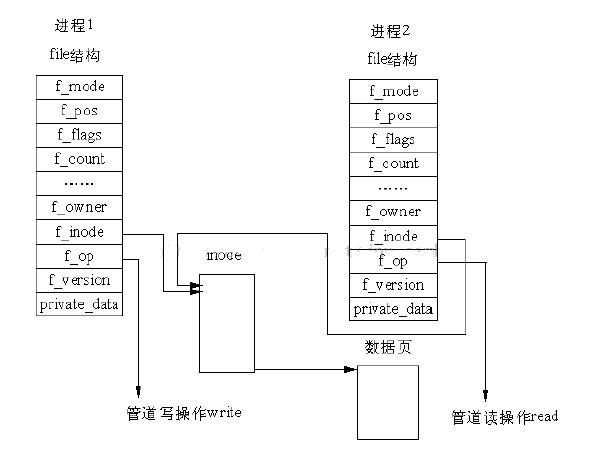
管道的结构:在Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file 结构和VFS 的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。如下图所示。

















 2722
2722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









