






 文章介绍了在数据库中处理多对多标签关联时,如何使用SQL查询来筛选包含特定标签、仅有一个标签、以及包含多个指定标签的文件。涉及JOIN、GROUPBY、HAVING和EXISTS等SQL技术的应用。
文章介绍了在数据库中处理多对多标签关联时,如何使用SQL查询来筛选包含特定标签、仅有一个标签、以及包含多个指定标签的文件。涉及JOIN、GROUPBY、HAVING和EXISTS等SQL技术的应用。
背景
在实践中经常遇到给数据加标签的情况,为了数据本身的整洁,标签可能是保存在独立的table中,通过外键关联。
假设数据与标签的关系是多对多的
此时,
- 如何筛选包含某一个标签的数据?
- 如何筛选有且仅有一个标签的数据?
- 如何筛选包含某几个标签的数据?
- 如何筛选有且仅有某几个标签的数据?
我们将数据库简化为下面3个表
- 文件
files
| id | file-name |
|---|---|
| 1 | file1 |
| 2 | file2 |
| 3 | file3 |
| 4 | file4 |
- 文件tag
tags
| id | tag-name |
|---|---|
| 1 | tag1 |
| 2 | tag2 |
| 3 | tag3 |
| 4 | tag4 |
| 5 | tag5 |
- 文件与tag的关系表
fileTagRelations
| id | tag-id | file-id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 2 |
| 4 | 1 | 3 |
| 5 | 2 | 3 |
| 6 | 3 | 3 |
一个tag
检索包含某个tag的文件
假设我们想要检索所有包含tag1的file,那么利用JOIN结合WHERE即可
SELECT f.*
FROM files f
JOIN fileTagRelations ftr ON f.id = ftr.file-id
WHERE ftr.tag-id = 1;
此时结果是
| id | file-name |
|---|---|
| 1 | file1 |
| 2 | file2 |
| 3 | file3 |
因为file1、file2和file3都包含了tag1。
这个比较容易理解,就是将files和fileTagRelations的列拼接起来,利用拼接后的数据中的tag-id,找到目标file。这里有个隐形假设:同一file不会有相同的tag,否则file会出现多次。
检索有且仅有某个tag的文件
那么如果更近一步,检索只有一个指定tag的file,比如有且只有一个tag1的file,又该如何修改呢?
这个问题麻烦的地方在于,file和tag的绑定关系是relation表中一条一条的记录,这些记录之间想要关联起来是比较麻烦的。
想到关联多条记录,自然会想到GROUP BY,结合HAVING对分组内的数据进一步筛选。
检索文件,所以以文件id作为分组条件。对于组内的进一步筛选条件,是file对应满足条件的tag数量,等于file的tag总数量。
具体实现如下
SELECT f.*
FROM files f
JOIN fileTagRelations ftr ON f.id = ftr.file-id
WHERE ftr.tag-id = 1
GROUP BY
f.id
HAVING
COUNT(DISTINCT ftr.tag-id ) =
(SELECT COUNT(DISTINCT ftr2.tag-id )
FROM fileTagRelations ftr2
WHERE ftr2.file-id = f.id );
检索包含多个指定tag的文件
对于想要指定多个tag的情况,也是类似。如果只要求检索包含多个指定标签的文件,如果熟悉SQL的各种工具,包括JOIN、GROUP BY、HAVING、EXISTS、DISTINCT等,其实可以想到许多种方案:
方案一
在上面提到包含一个tag的基础上实现,利用两个JOIN去检索包含两个指定tag的情况。
SELECT f.*
FROM files f
JOIN fileTagRelations ftr1 ON f.id = ftr1.file-id
JOIN fileTagRelations ftr2 ON f.id = ftr2.file-id
WHERE ftr1.tag-id = 1 AND ftr2.tag-id = 2;
这种方案的问题在于扩展性不好,如果想要检索包含更多tag的情况,需要更多JOIN。
方案二
另一种方案,可以不使用多个JOIN,而是结合GROUP BY和HAVING,对分组后的数据进一步筛选。
方案是:
- 利用
JOIN结合files和fileTagRelations表后,挑选满足要求的tag,比如我们挑选tag-id为1或者2的情况。 - 利用
files.id对结果进行分组,每组数据满足条件的tag需要和挑选的tag数目一致。
SELECT f.*
FROM files f
JOIN fileTagRelations ftr ON f.id = ftr.file-id
WHERE ftr.tag-id IN (1,2)
GROUP BY
f.id
HAVING
COUNT(DISTINCT ftr.tag-id) = 2;
结合上面检索有且仅有一个tag时的想法,可以实现检索有且仅有指定个数tag的file。
SELECT f.*
FROM files f
JOIN fileTagRelations ftr ON f.id = ftr.file-id
WHERE ftr.tag-id IN (1,2)
GROUP BY
f.id
HAVING
COUNT(DISTINCT ftr.tag-id ) = 2 AND COUNT(DISTINCT ftr.tag-id ) =
(SELECT COUNT(DISTINCT ftr2.tag-id )
FROM fileTagRelations ftr2
WHERE ftr2.file-id = f.id);
方案三
另外一种方案,可以结合EXISTS语句。
SELECT *
FROM files f
WHERE EXISTS (
SELECT 1
FROM fileTagRelations ftr
WHERE ftr.file-id = f.id AND ftr.tag-id IN (1,2)
GROUP BY
f.id
HAVING
COUNT(DISTINCT ftr.tag-id) = 2
);
同样的方案三结合上面检索有且仅有一个tag时的想法,也可以实现检索有且仅有指定个数tag的file。
SELECT *
FROM files f
WHERE EXISTS (
SELECT 1
FROM fileTagRelations ftr
WHERE ftr.file-id = f.id AND ftr.tag-id IN (1,2)
GROUP BY
f.id
HAVING
COUNT(DISTINCT ftr.tag-id) = 2 AND COUNT(DISTINCT ftr.tag-id ) =
(SELECT COUNT(DISTINCT ftr2.tag-id )
FROM fileTagRelations ftr2
WHERE ftr2.file-id = f.id)
);
背景知识
SELECT DISTINCT
检索某一列时,执行去重操作。
JOIN
把两个或多个表的行,结合起来
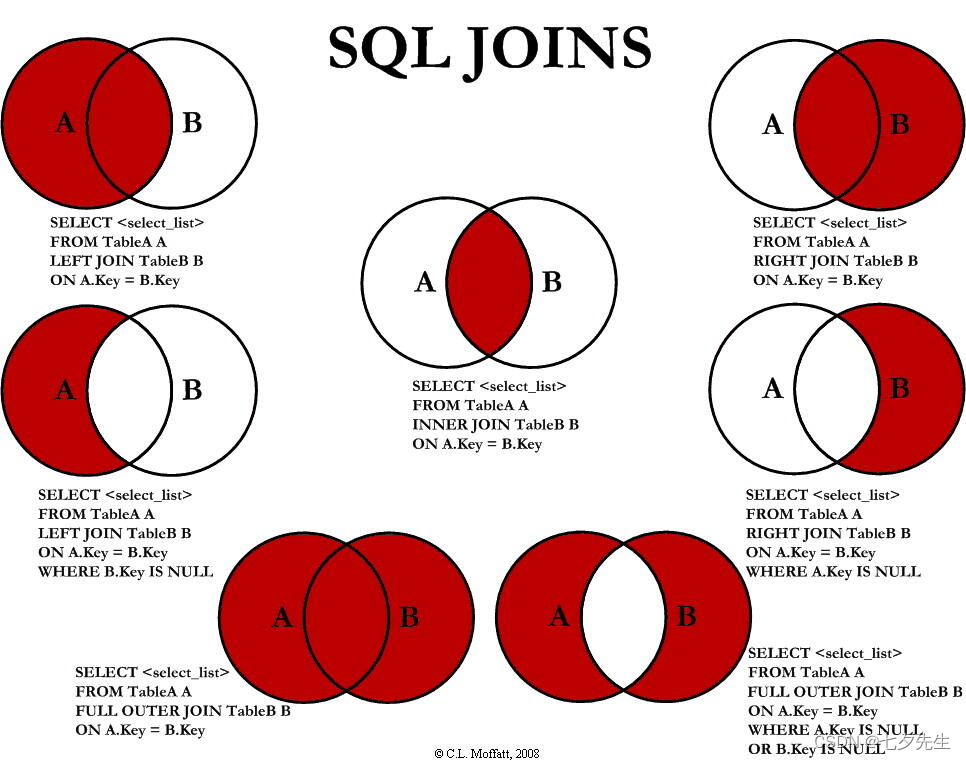
GROUP BY
根据一个或多个列,对结果进行分组。
HAVING
结合GROUP BY,对分组后的各组数据进行筛选。
EXISTS
用来判断子语句查询结果是否有记录,如果有返回true,否则返回false


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









