






Flink 概述
Apache Flink 是一个计算框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink 提供了诸多更高抽象层的 API 以便用户编写分布式任务:
-
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用 Flink 提供的各种操作符对分布式数据集进行处理,支持 Java、Scala。
-
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持 Java 和 Scala。Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类 SQL 的 DSL 对关系表进行各种查询操作,支持 Java 和 Scala。
-
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类 SQL 的 DSL 对关系表进行各种查询操作,支持 Java、Scala和 python。
背景
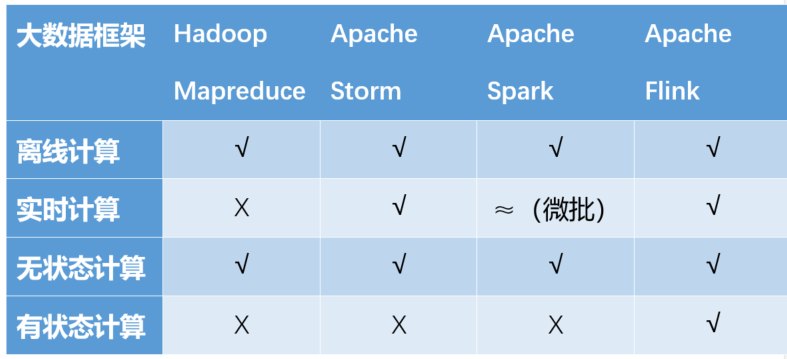
在数据激增的时代,大数据处理框架起到举足轻重的作用。根据时效性,数据的处理可分为离线计算(批量处理)和实时计算(流处理)。根据计算过程和结果,可分为无状态计算和有状态计算。目前比较流行的大数据处理框架对比如下:
Flink 的优势
-
高吞吐、低延迟、纯流式架构
-
支持对乱序事件的处理
-
有状态、提供 exactly-once 计算
-
灵活的窗口机制
-
失败恢复、故障转移、水平扩展
-
批处理、流处理统一的 API
系统架构
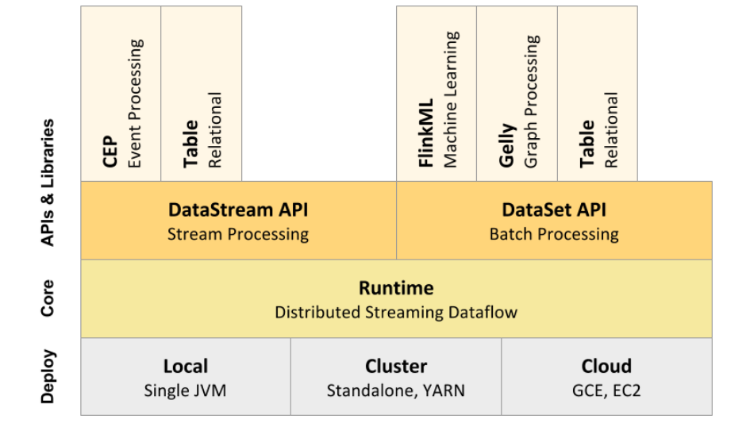
Flink 包含了各种各样的组件,包括部署、Flink core(runtime)以及 API 和各种库。
分布式执行
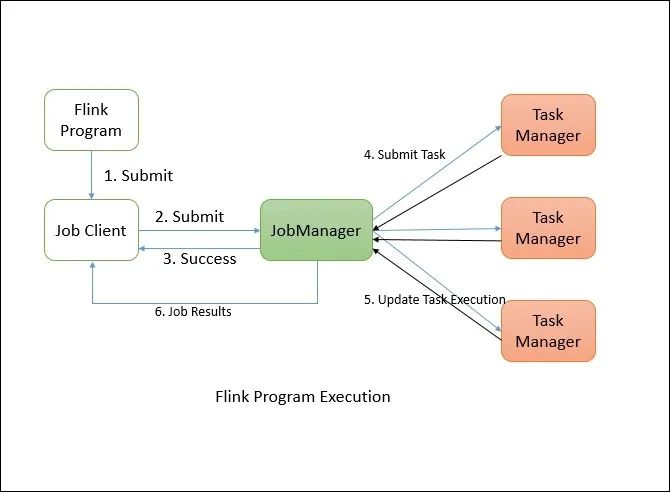
Flink 分布式程序包含 2 个主要的进程:JobManager 和 TaskManager。当程序运行时,不同的进程就会参与其中,包括 JobManager、TaskManager 和 JobClient。
JobManager
Master 进程,负责 Job 的管理和资源的协调。包括任务调度,检查点管理,失败恢复等。当然,对于集群 HA 模式,可以同时多个 master 进程,其中一个作为 leader,其他作为 standby。当 leader 失败时,会选出一个 standby 的 master 作为新的 leader(通过 zookeeper 实现 leader 选举)。
TaskManager
Task Managers 是具体执行 tasks 的 worker 节点,执行发生在一个 JVM 中的一个或多个线程中。Task 的可设置的并行度大小依赖在 Task Manager 中的 task slots 的数量,可支持的最大并行度由所有 task manager 的 task slot 的总数量决定。如果一个 Task Manager 有 4 个 slots,那么 JVM 的内存将分配给每个 task slot 25% 的内存。一个 Task slot 中可以运行 1 个或多个线程,同一个 slot 中的线程又可以共享相同的 JVM。
Job Client
Job Client 并不是 Flink 程序执行中的内部组件,而是程序执行的入口。Job Client 负责接收用户提交的程序,并创建一个 data flow,然后将生成的 data flow 提交给 Job Manager。一旦执行完成,Job Client 将返回给用户结果。通常我们可以通过 Flink 提供的 UI 提交 Job,也可以使用 Flink 的脚本,甚至自己写代码提交 Job。
程序结构介绍
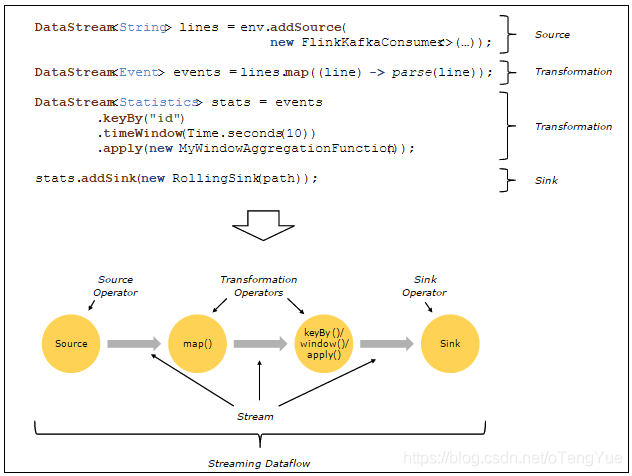
Flink 程序的 Operators 负责将一条或多条流进行转换成新的流,程序可以自由组合多个转换过程进入数据流拓扑结构。按照功能可以将 Operator 划分成:Source, Transformation, Sink。Source 负责流的数据来源,Transformation 则对数据进行转换,Sink 负责对数据最终的输出。以下是一个简单流处理程序的结构:
核心概念
Flink算子
算子的分类
Source
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Source 就是数据的来源地。Flink 中你可以使用 StreamExecutionEnvironment.addSource (sourceFunction) 来为你的程序添加数据来源。Flink 已经提供了若干实现好了的 source,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
Sink
sink 是程序的数据输出,可以通过 StreamExecutionEnvironment.addSink (sinkFunction) 来为程序添加一个 sink。flink 提供了大量的已经实现好的 sink,也可以通过实现 SinkFunction 自定义 sink。
Transformation
Transformation 是对数据流的变换操作,一个程序可以组合多个 Transformation 形成一个复杂的数据流拓扑。常用的 Transformation 有:Map, FlatMap, Filter, Reduce 等等。
Flink 基石
Apache Flink 之所以能越来越受欢迎,我们认为离不开它最重要的四个基石:Time、Window、State、Checkpoint。
Time
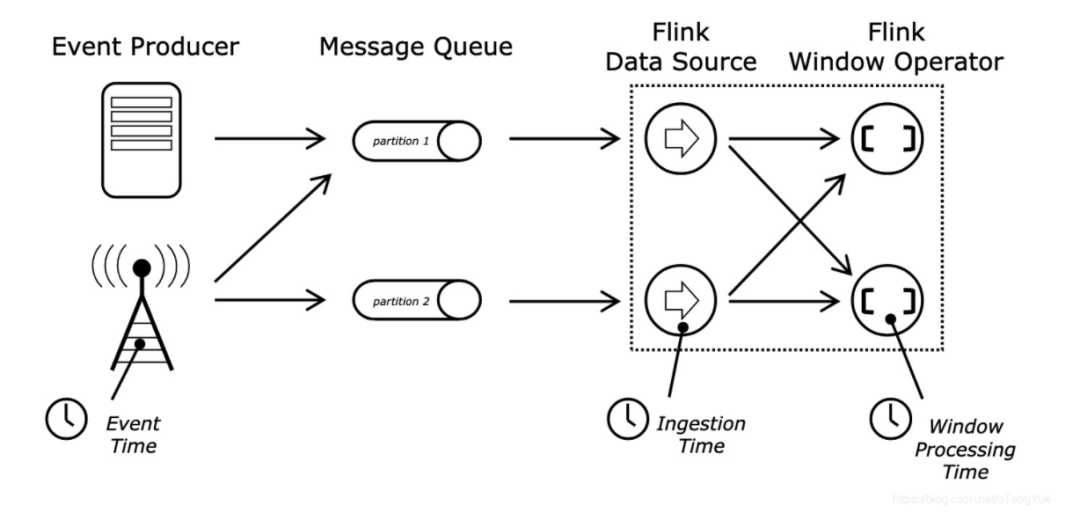
Time 的分类
-
Event-Time :事件时间是每个事件在其生产设备上发生的时间。此时间通常在进入 Flink 之前嵌入记录中,并且可以从每个记录中提取该事件时间戳。
-
Ingestion-Time :摄取时间是事件进入 Flink 的时间。在源算子处,每个记录将源的当前时间作为时间戳,并且基于时间的 算子操作(如时间窗口)引用该时间戳。
-
Processing-Time :处理时间是指执行相应算子操作的机器的系统时间。
Window
Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在 Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window)。
基于时间的窗口操作,在每个相同的时间间隔对 Stream 中的记录进行处理,通常各个时间间隔内的窗口操作处理的记录数不固定;
而基于数据驱动的窗口操作,可以在 Stream 中选择固定数量的记录作为一个窗口,对该窗口中的记录进行处理。
窗口类型:
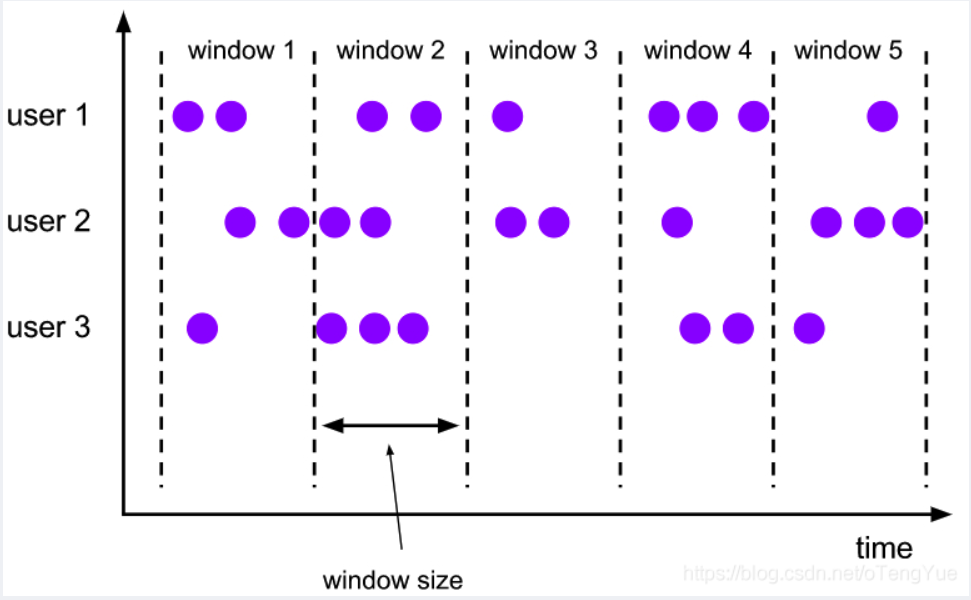
・ tumbling window(滚动窗口)
一个滚动窗口分配器的每个数据元分配给指定的窗口的窗口大小。滚动窗具有固定的尺寸,不重叠。例如,如果指定大小为 5 分钟的滚动窗口,则将评估当前窗口,并且每五分钟将启动一个新窗口。
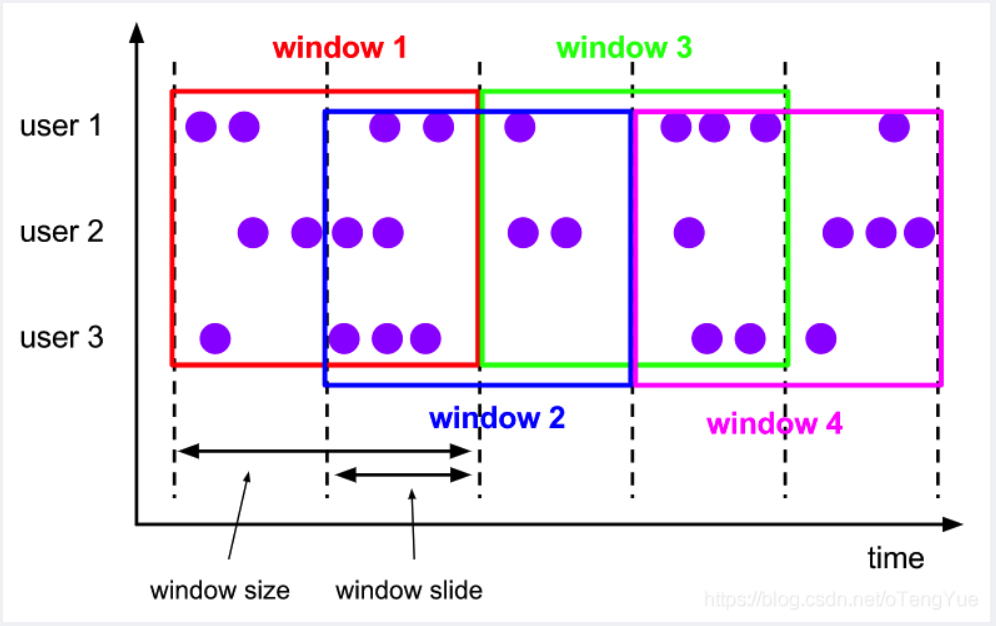
・ sliding window (滑动窗口): 窗口间的元素可能重复
该滑动窗口分配器分配元件以固定长度的窗口。与滚动窗口分配器类似,窗口大小由窗口大小参数配置。附加的窗口滑动参数控制滑动窗口的启动频率。因此,如果幻灯片小于窗口大小,则滑动窗口可以重叠。在这种情况下,数据元被分配给多个窗口。
例如,您可以将大小为 10 分钟的窗口滑动 5 分钟。有了这个,你每隔 5 分钟就会得到一个窗口,其中包含过去 10 分钟内到达的事件。
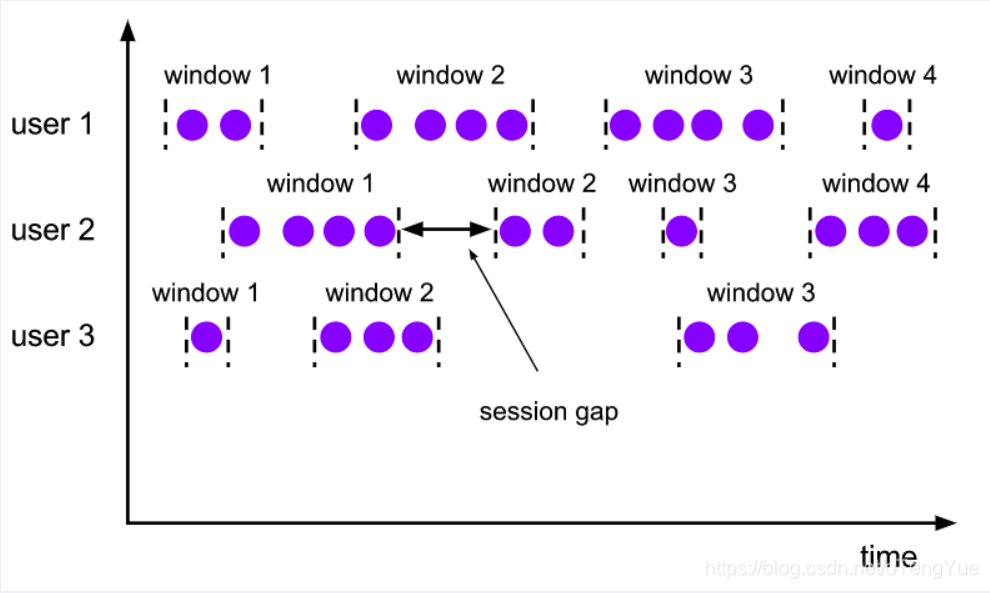
・ session window(会话窗口)
在会话窗口中按活动会话分配器组中的数据元。与滚动窗口和滑动窗口相比,会话窗口不重叠并且没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到数据元时,即当发生不活动的间隙时,会关闭会话窗口。会话窗口分配器可以配置静态会话间隙或会话间隙提取器函数,该函数定义不活动时间段的长度。当此期限到期时,当前会话将关闭,后续数据元将分配给新的会话窗口。
・global window(全局窗口)
一个全局性的窗口分配器分配使用相同的 Keys 相同的单个的所有数据元全局窗口。此窗口方案仅在您还指定自定义触发器时才有用。否则,将不执行任何计算,因为全局窗口没有我们可以处理聚合数据元的自然结束。

State 状态管理
State 是指流计算过程中计算节点的中间计算结果或元数据属性,比如在 aggregation 过程中要在 state 中记录中间聚合结果,比如 Apache Kafka 作为数据源时候,我们也要记录已经读取记录的 offset,这些 State 数据在计算过程中会进行持久化 (插入或更新)。所以 Apache Flink 中的 State 就是与时间相关的,Apache Flink 任务的内部数据(计算数据和元数据属性)的快照。
Checkpoint 容错机制
Checkpoint 是 Flink 实现容错机制最核心的功能,它能够根据配置周期性地基于 Stream 中各个 Operator/task 的状态来生成一个轻量级的分布式快照,从而将这些状态数据定期持久化存储下来,当 Flink 程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
总结
Flink 是一款优秀的批流一体的分布式计算引擎,本文通过对它的背景,优势,架构以及核心的概念进行了介绍,帮助大家对 Flink 的有一个初步认识。















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









