







第一步:建工程
并创建对应的包

第二步:改web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0"
metadata-complete="true">
</web-app>
把版本变为最新
第三步:创建servlet类

public class responseDown extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//1:获取下载文件的路径
// String realPath = this.getServletContext().getRealPath("/女神.jpg");
String realPath = "E:\\IdeaProject\\ServletProject\\ServletStudy\\Response\\src\\main\\resources\\女神.jpg";
System.out.println("下载文件的路径"+realPath);
//2:下载的文件名 思路:获取/后面的那一段
String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);
//3:设置让浏览器能够支持下载我们需要的东西
//如果有中文文件名 需 URLEncoder.encode 编码否则有可能会乱码
// resp.setHeader("Content-Disposition","attachment;filename="+fileName);
resp.setHeader("Content-Disposition","attachment;filename="+ URLEncoder.encode(fileName,"utf-8"));
//4:获取下载文件的输入流
FileInputStream in = new FileInputStream(realPath);
//5:创建缓冲区
int len = 0;
byte[] buffer = new byte[1024];
//6:获取响应的OutputStream对象
ServletOutputStream out = resp.getOutputStream();
//7:将FileOutputStream流写入到buffer缓冲区中,使用OutputStream将缓冲区中的数据输出到客户端
while((len=in.read(buffer))>0){
out.write(buffer,0,len);
}
//8:关闭流对象
in.close();
out.close();
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req, resp);
}
}
第四步:在web.xml中注册此servlet
<!--注册Servlet-->
<servlet>
<servlet-name>down</servlet-name>
<servlet-class>com.csnz.servlet.responseDown</servlet-class>
</servlet>
<!-- 配置servlet对应的映射-->
<servlet-mapping>
<servlet-name>down</servlet-name>
<url-pattern>/down</url-pattern>
</servlet-mapping>
第五步:在resources文件夹中添加要下载的文件

第六步:配置tomcat

第七步:启动服务器
女神照片下载成功!!!
接下来详解 responseDown中的具体实现下载的代码

这里无法直接使用/女神.jsp的方式来找到此文件
因为getServletContext是在当前目录下查找的
如果这样子运行 web端会出错404

思路:因为realPath是字符串 所以我们可以使用字符串的截取方式 获取/后面的内容
这里如果直接/肯定会出错 需要转义

这里setHeader()中的两个参数是固定写法

就是说in 能获取到指定下载文件的内容
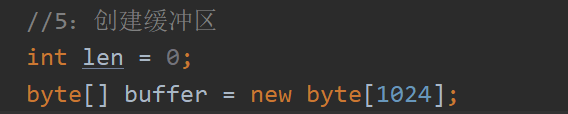
这里建立缓冲区的目的是为了更快速 同时效率更高

out 的意思为 使用out输出数据

每次用in去读取缓冲区容量大小的文件内容,如果他大于0 则证明文件还未全部读取完
out.write(buffer,0,len);
输出缓冲区中有效长度的内容
最后,关闭流对象
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









