





官方地址:
http://cs231n.github.io/neural-networks-1/#actfun
翻译:
这三天写上
常用的激活函数
每个激活函数(或者非线性的)输入一个数值然后对其作某个固定的数学处理。你在练习中可能遇到这些激活函数。
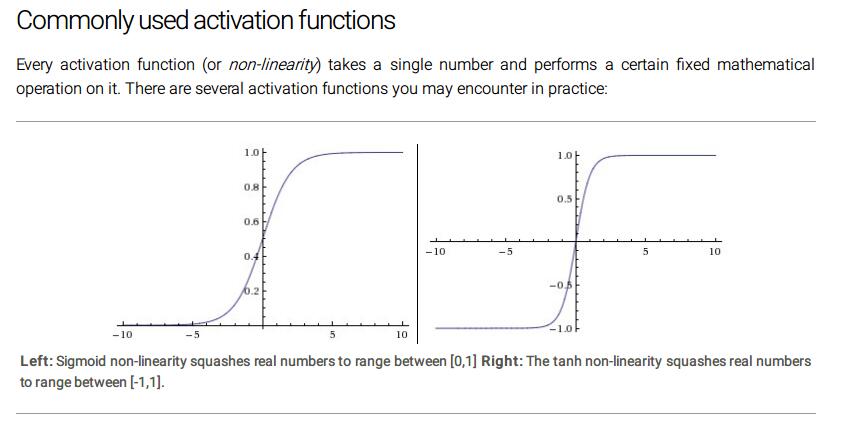
左:Sigmoid 非线性映射实数到[0,1]区间,右:tanh非线性映射实数到[-1,1]区间。
Sigmoid。sigmoid非线性激活函数的公式是,如上上图左。之前的章节提过,它将实数压缩到0 1 区间。而且,大的负数变成0,大的正数变成1。sigmoid函数由于其强大的解释力,在历史上被最经常地用来表示神经元的活跃度:从不活跃(0)到假设上最大的(1)。在实践中,sigmoid函数最近从受欢迎到不受欢迎,很少再被使用。它有两个主要缺点:
1.sigmoid过饱和、丢失了梯度。sigmoid神经元的一个很差的属性就是神经元的活跃度在0和1处饱和,它的梯度在这些地方接近于0。回忆在反向传播中,某处的梯度和其目标输出的梯度相乘,以得到整个目标。因此,如果某处的梯度过小,就会很大程度上干掉梯度,使得几乎没有信号经过这个神经元以及所有间接经过此处的数据。除此之外,人们必须额外注意sigmoid神经元权值的初始化来避免饱和。例如,当初始权值过大,几乎所有的神经元都会饱和以至于网络几乎不能学习。
2.sigmoid的输出不是零中心的。这个特性会导致为在后面神经网络的高层处理中收到不是零中心的数据。这将导致梯度下降时的晃动,因为如果数据到了神经元永远时正数时,反向传播时权值w就会全为正数或者负数。这将导致梯度下降不希望遇到的锯齿形欢动。但是,如果采用这些梯度是由批数据累加起来,最终权值更新时就会更准确。因此,这是一个麻烦一些,但是能比上面饱和的激活问题结果好那么一些。
Tanh.Tanh如上图右。其将实数映射到[-1,1]。就像sigmoid神经元一样,它的激活也会好合,但是不像sigmoid函数,它是零中心的。因此在实际应用中tanh比sigmoid更优先使用。而且注意到tanh其实很简单,是sigmoid缩放版。
左:纠正线性单元激活函数,就是当x<0为0,当x>0时斜率为1。右:从Krizhevsky 等人论文中摘出的图表,表现ReLU单元比tanh单元具有6倍的收敛速度提升。
ReLU。ReLU近几年很流行。它求函数f(x) = max(0,x)。换句话说,这个激活函数简单设0为阈值(见上图左—)。关于用ReLU有这些好处和坏处:
(+)其在梯度下降上比较tanh/sigmoid有更快的收敛速度。这被认为时其线性、非饱和的形式。
(+)比较tanh/sigmoid操作开销大(指数型),ReLU可以简单设计矩阵在0的阈值来实现。
(-)不幸的是,ReLU单元脆弱且可能会在训练中死去。例如,大的梯度流经过ReLU单元时可能导致神经不会在以后任何数据节点再被激活。当这发生时,经过此单元的梯度将永远为零。ReLU单元可能不可逆地在训练中的数据流中关闭。例如,比可能会发现当学习速率过快时你40%的网络都“挂了”(神经元在此后的整个训练中都不激活)。当学习率设定恰当时,这种事情会更少出现。
ReLU渗漏法。这是种解决ReLU挂了的办法。当x<0,用小的负梯度(0.01)来替代0。
截图存留:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









