







踏过千山万水,峰回路转,终于装上了scrapy爬虫构架。接着参照网上写一个demo。
中文demo:http://www.cnblogs.com/txw1958/archive/2012/07/16/scrapy-tutorial.html
英文原创demo:http://doc.scrapy.org/en/0.16/intro/tutorial.html
由于疏忽,在spider目录下的蜘蛛程序中,有那么一段代码:
filename = response.url.split("/")[-2]敲入时少了后面的 [-2],于是
filename = response.url.split("/")然后运行,问题就来了
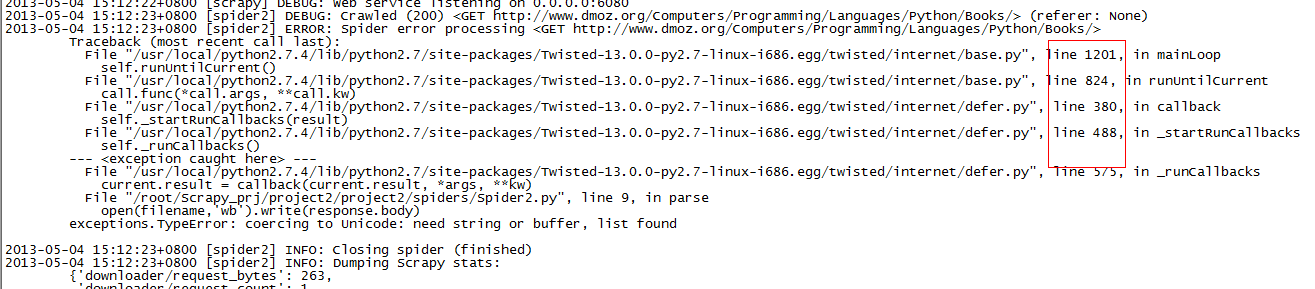
一下子被吓倒了,貌似问题出现在Twisted模块,是不是装Twisted版本不对导致的。Google一下,找到有类似的问题,按网上做,还是没解决。此时已经严重怀疑是Twisted版本问题导致的,不过这时还不想重装Twisted,毕竟太麻烦了。于是到英文scrapy.org网站找scrapy demo例子。照搬下来,居然可以正常运行了!!!此时证明不是Twisted版本问题,发现自己代码少了[-2]的缘故。分析一下,可能是open()这个函数是继承Twisted的open(),从而错误提示指向Twisted模块。这种错误提示没什么价值,反而有很大的误导性。
所以啊,有时候程序的错误提示并不是问题的真正所在。















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









