




一个完整的IR系统:
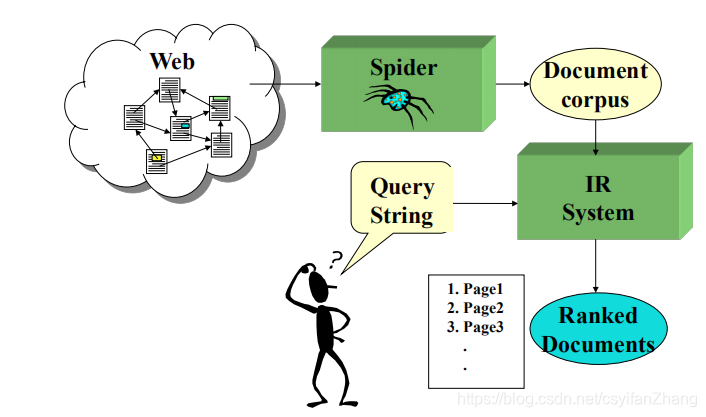
与传统IR模型的差别就在于爬虫+Web的部分,只有通过在Web上不断搜集信息,才能不断的完善我们网络信息检索的能力。
一、Web简介
- Web信息搜集(Web Crawling):指通过Web页面之间的链接关系从Web上自动获取页面信息,并且随着链接不断向所需要的Web页面扩展的过程,信息搜集系统也常常称为Robot, Spider, Crawler等
- 信息搜集是网络信息检索系统获得数据来源的过程,地位相当重要
- 信息搜集的目标:快速获得高质量的网页——快+高质量
1、Web三要素
- 资源(Resources): 超文本的概念表示,如
HTML(HyperText Markup Language - 资源标识(Resource identifiers): 用来定位资源的唯一性命名机制,如
URL - 传输协议(Transfer protocols): 浏览器(Web用户代理)和服务器之间通信的规范,如
HTTP
下面的内容为WEB基础,涉及一些计算机网络知识,有基础的其实可以跳。
(1)HTML的基本结构
一个HTML文档可以分为文档头( head)和文档体(body),前者在<HEAD>和 </HEAD>之间,后者在<BODY> 和</BODY>之间
文档的题目(title )显示在头部
文档的内容( content )显示在文档体内,文档体可以分为段落,用 <P>分割
超链接(Hyperlink) <a href="relations/alumni">alumni</a>。链接是一个Web资源到另一个资源的(有方向的)链接,中间的文字成为锚文本( anchor)。锚文本对信息检索是非常重要的,因为它是对网页的一个高度抽象,可以作为我们对该网页的索引词。
(2)资源标识符
URL(Uniform Resource Locators)语法: <protocol>://<hostname><path>?<query>#<fragment>。?代表后面是一个查询,可以获得一些变量值。#可以对网页进行重定位。
查询(query)从HTML表格中传递变量 <variable>=<value>&<variable>=<value>…
片段( fragment)也称为指向( reference )同一个文
档内的指针 <<A NAME=“<fragment>”>
绝对URL,指明完整的资源定位路径
相对URL,只是相对的资源定位信息
(3)传输协议HTTP/HTTPS

HTTP是Hypertext Transfer Protocol,超文本传输协议的缩写,主要使用了TCP技术(TCP三次握手建立连接),他有如下的一些方法。
(i)常用方法

(ii)HTTP响应状态码
- 1XX: Informational
100 Continue, 101 Switching Protocols
- 2XX: Success
200 OK, 206 Partial Content
- 3XX: Redirection
301 Moved Permanently, 304 N 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3599
3599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









