






网上查了一下彩虹表攻击相关资料,发现大部分文章说得都不太清楚,于是扒了Philippe Oechslin最初的paper《Making a Faster Cryptanalytic Time-Memory Trade-Of》,再结合开源项目RainbowCrack-NG(https://github.com/inAudible-NG/RainbowCrack-NG/tree/master),把整个彩虹表攻击原理及其实现方法做了梳理,方便大家理解。
背景知识
哈希加密算法应用范围广泛,包括但不限于:Unix风格的用户密码(Linux、*BSD、Solaris、AIX、QNX等)、macOS、Windows、Web应用程序(如WordPress)、办公软件(如Notes、Domino)、数据库(如MySQL)、文件系统和磁盘(macOS.dmg、Windows BitLocker)、压缩软件(ZIP、RAR、7Z)、文档文件(PDF、Microsoft Office)等。
常见的哈希加密算法有MD5、SHA1、SHA256、SHA3等,他们都有一个特点,就是算法不可逆,要想通过密文倒推加密前的明文,最可靠的办法是暴力穷举,但其耗时往往是无法接受的。
以14位字母和数字的组合密码为例,共有种可能,即使电脑每纳秒计算一个hash值,也需要4亿年才能穷举,其耗时是不可接受的。
另一种办法是查表法,提前将穷举的结果的原文/密文对保存下来,拿到密文后通过查表找到对应的原文,也就是用空间换时间,但是这种空间代价也是无法接受的,还是以14位字母和数字的组合密码为例,假设密文长度为32字节,那么需要存储
假设1TB硬盘价格1RMB,硬盘费用在8百万亿元人民币,是无法承受的。
为此,有人提出了一种碰撞算法来实现暴力破解哈希加密,并命名为彩虹表密码攻击法,该方法是查表法和暴力穷举法的折中优化,在可接受的存储容量基础上,大大减少计算量。
彩虹攻击技术原理
彩虹攻击本质上是一种暴力破解方法,同时采用了空间换时间的思路,即预先针对某种哈希加密算法生成彩虹表,然后使用彩虹表里面相对少量的值表征了整个超大密码空间值。要弄懂彩虹攻击原理,我们先要弄懂Hash函数工作原理,然后设计一个将哈希值散列到明文空间的Reduction函数,然后再理解彩虹链和彩虹表,最后理解碰撞检测原理。不着急,一个一个来
Hash函数
以最常用的MD5函数为例,我们借助node.js里面的md5模块
var crypto = require('crypto');
var md5 = crypto.createHash('md5');
var result = md5.update('MyPasswad').digest('hex');
// 输出:5342972619fca82e494ff2fb688f5da2
console.log(result);
// 输出:32
console.log(result.length)其功能是将输入的 MyPasswad 字符串通过哈希计算,散列对应到一个长度为128bit的大数空间中的某个数,最后通过16进制打印出来。其中有几个重点:
1.均匀性:尽量确保不同的字符串经过哈希计算后会对应到不同的大数,很难找到两个不同的字符串具有相同的哈希值,即实现哈希散列的均匀化,具备高抗碰撞性;
2.单向性:无法从哈希加密结果反向计算加密前的明文字符串,即该计算是单向的,不可逆;
3.唯一性:同一个字符串经过某种哈希计算后得到唯一的大数值。
Reduction函数
Reduction函数的功能是将Hash计算结果的大数转换为一个字符串,即实现大数空间到密码明文空间的映射。
同时Reduction函数必须实现大数空间到字符串空间的均匀映射,与Hash函数将字符串映射到大数类似,实现大数到字符串的反向均匀映射,这个均匀性非常重要,是彩虹攻击有效性的关键。
其实要做到这一点也简单,可以利用哈希函数均匀性,简单取模即可。解释一下,具体做法是将所有明文看成一个集合P,P集合包含的元素个数为N,哈希计算结果的大数集合记为C,Reduction函数记为R,即,其中
为
在P集合中的索引值。因为哈希函数具备均匀性,那么用其取模即可实现均匀散列到从0到N-1的集合索引空间,也就相当于均匀散列到P集合空间。
当然,Reduction函数在彩虹攻击中实际实现会略有不同,具体后面会说到。
彩虹链
介绍完前面的Hash函数和Reduction函数后,我们就可以来说说彩虹链了,因为彩虹链的建立就是基于这两个函数。
先说彩虹链机制:记Hash函数为H,Reduction函数为R,对一个明文做Hash计算,得到一个密文
,即
,对
做一次Reduction计算得到一个新的明文
,即
,在对
进行一次Hash计算,以此往复进行
次计算,最终得到
,如下
如此,便形成了一个长度为的链条,称为彩虹链。彩虹链具有可复现性,即
经过
次H和R函数计算后能重复得到从
到
,以及
到
等一系列值。基于复现性,我们可以用
和
表征一整条彩虹链上的
组值,达到无损数据压缩效果。如果我们使用n条彩虹链使其
个
值能覆盖全部的P集合空间,即覆盖所有明文的可能性,便可以达到和穷举一样的效果。但其存储空间只需要n组
和
值,将近
的压缩率。当t值较大时,比如
,能够大大节省存储空间。
彩虹表
基于彩虹链上述可复现特性,建立一张数据表,取彩虹链首位值存入该表,称之为彩虹表。因此彩虹表只有两列,第一列存的是彩虹链首值,第二列存的是彩虹链的尾值,如果存储的彩虹链条数为n,彩虹表便有n行数据。
基于Hash函数和Reduction函数的均匀性,一条哈希链能覆盖个
值,n条哈希链便能覆盖
个P集合空间值,假如
便能覆盖整个P集合。当然这是理想情况,实际情况下会有很多重复值出现,按照paper的的表述覆盖率p和n的取值之间满足如下关系:
碰撞检测(密码破译)
假如我们拿到一个密文,经过检索彩虹表第二列,如果命中了第k行数据,即
,那么说明用于计算
的
即为
的明文;
假如彩虹表中没能检索到密文值,那么,我们可以对
执行以下操作
,然后用X1检索彩虹表第二列,如果命中了第j行数据,即
,那么说明
为
的明文,因为
,相当于
等于
,而
的明文即为
;
类似地,X的明文还有可能等于(其中0<
<=t,0<=y<n),即X执行
次RH变换后的值能够在彩虹表第二列中检索到,说明X的明文可能处于该条数据对应的彩虹链中的某个环节。
在基于彩虹链的可复现性,我们只需要使用该条数据的第一列值,即值,执行t次RH计算,复现该条彩虹链中的所有
和
值,找到与X值相同的
值,那么对应的
值即为
密文对应的明文。
需要注意的是,即便找到了,任无法确保该条彩虹链中必然包含
值,毕竟Hash函数和Reduction函数无法做大绝对的唯一性和均匀性,所以误检是存在的,而且n值越大,误检率越高。
这一基于尝试性的检测过程,被称为碰撞检测,也是彩虹攻击破译密码的基本原理。
彩虹攻击技术实现
至此,彩虹攻击基本原理阐述完毕。同时也面临几个问题:
1.彩虹表中n条彩虹链的n个值该如何选取?
2.如果单条彩虹链中出现循环,势必降低了覆盖率,该如何处理?
3.如果两条,或多条彩虹链中段出现重复值,后续便完全相同,也会降低覆盖率,该如何处理?
4.哈希表中存储链首的明文值和链尾的哈希值
值真的合适吗?有没有更优选择?
第一个问题相对简单,基于Hash函数的均匀性,以及t值往往比较大,通常在2000以上,初值显得不是特别重要,只需要确保n个值不重复即可。最简单的做法就是从P集合中取前n个值即可,往往这也是比较可取的方案,因为P集合前n个值通常是简单的弱密码,无形中将弱密码覆盖到了。
彩虹表存储优化
先来看第4个问题,以MD5为加密算法的10字符密码为例,如果存储明文和MD5值,第一列明文字符串需要10Byte,数据类型为string,第二列MD5密文需要16Byte,数据类型为byte,合计单个哈希链需要的存储空间为26Byte。假如需要存储10万亿条哈希链,需要的存储空间约为260TB。
请注意Reduction函数,其计算结果是一个Index,其数据类型为Int64。假如我们哈希表第一列存储明文对应的Index值,只需要8Byte,第二列存储密文
经过Duduction计算后的Index值,也只需要8Byte。如此,单个哈希链需要的存储空间缩小到16Byte,10万亿条哈希链所需存储空间约为160TB,相较之前的方案缩减了100TB存储空间,将近40%。
同时需要注意,由于选用的Index只有64bit,因此P集合大小不得超过,约
个。以大小写字母+数字为例,当密码长度为11时,其P集合大小为
因此Index选用Int64时,最多能用于破解长度不超过10的大小写字母+数字的密码。如果需要破解更复杂的密码,如长度为14的全字符密码
因此Index需要选用Int128数据类型。Int128可以最多容纳全字符长度19的密码空间。
Reduction函数优化
要解决上述第2、3个问题,重点在于Reduction函数的设计。假如长度为的彩虹链使用
个不同的Reduction函数,即:
第2个问题便迎刃而解,因为经过不同的Reduction函数便得到不同的值,不会形成循环;对于第3个问题,即便彩虹链中出现了相同值,只要不在同一个位置,后续值也不会重复。
要实现彩虹链不同环节的R函数也很简单,开源项目RainbowCrack-NG中是这样实现的
即:在取模的基础上,加上彩虹链位置偏移量。
需要注意的是,优化后的Reduction函数为碰撞检测环节增加了复杂性。在使用统一R函数的情况下,只需要执行t次H/R函数,就可以得到t个可用于碰撞检测的C值。当改进用不同R函数时,做彩虹链第i个位置的检测时,需要执行t-i次H/R函数
假如彩虹表中第j行的第二列,那么用
计算得到
值,然后判断
是否等于X,如果相等,那么
便是X的明文。
在做碰撞检测过程中,肯定是从最简单的假设开始,即假设彩虹表中包含了X值,这时候不需要对X做H/R计算,直接检索即可。然后假设X位于彩虹链末端倒数第二的位置,这时候只需要对X做一次H/R计算。最坏的情况,即X的明文为时,需要对X执行t次H/R函数,才能得到可用于碰撞检测的
值。从概率来说,大约都需要计算到彩虹链的中间处才能碰撞成功,因此需要对X执行H/R计算的次数如下:
相较于之前固定R函数只需要执行次H/R计算,改进后的R函数需要
次H/R计算,当t值较大时,会大大增加计算量。
结束语
整个彩虹攻击可分为两个环节,第一个环节是彩虹表构建,第二个环节是密码碰撞检测破译过程。
重点在于第一个环节,而在彩虹表构建环节需要注意的是t值和n值的选取,即彩虹链的长度t和彩虹表中彩虹链的条数n。这两个值的选取由以下因素决定:
密码字符集
密码长度
期待成功率
有一个在线工具可以用来计算t值和n值,工具地址:Advanced Rainbow Table Calculator - TobTu
需要说明以下这个工具里面的Tables字段,用于多个彩虹表的情况下,前面我们讨论的都仅限于单一彩虹表,实际使用过程中,通常会分多个彩虹表,这一点在Philippe Oechslin的paper中也有提到,在分多张彩虹表的情况下,密码破译成功率计算公式为:
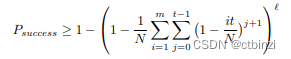
其中为分表个数。
同时在Reduction函数设计时,每个分表都会有各自不同的Reduction函数。在RainbowCrack-NG开源项目中,Reduction函数是这么设计的
其中j为当前彩虹表在个彩虹表中的序号,i为当前所处彩虹链计算步骤。
至此,彩虹攻击原理及其实现解释完毕。


















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











