







 本文详细介绍了JVM的内存结构,包括JVM栈、本地方法栈、堆内存以及运行时常量池。重点讲解了虚拟机栈中的局部变量表,包括Slot的使用、动态链接、方法调用的过程以及栈顶缓存技术。此外,还探讨了类加载子系统,包括类加载器的角色、类加载过程(加载、验证、准备、解析、初始化)以及双亲委派模型。最后,讨论了JVM的发展历程,包括不同虚拟机的特性与优化技术。
本文详细介绍了JVM的内存结构,包括JVM栈、本地方法栈、堆内存以及运行时常量池。重点讲解了虚拟机栈中的局部变量表,包括Slot的使用、动态链接、方法调用的过程以及栈顶缓存技术。此外,还探讨了类加载子系统,包括类加载器的角色、类加载过程(加载、验证、准备、解析、初始化)以及双亲委派模型。最后,讨论了JVM的发展历程,包括不同虚拟机的特性与优化技术。
JVM上篇_内存与垃圾回收篇
一 JVM与Java体系结构
1. Java及JVM简介
- java: 跨平台的语言

- JVM: 跨语言的平台

- 随着Java7的正式发布,Java虚拟机的设计者们通过JSR-292规范基本实现在Java虚拟机平台上运行非Java语言编写的程序.
- Java虚拟机根本不关心运行在其内部的程序到底是使用何种编程语言编写的,它只关心"字节码"文件.也就是说java虚拟机拥有语言无关性,并不会单纯地与Java语言"终身绑定",只要其他编程语言的编译结果满足并包含Java虚拟机的内部指令集,符号表以及其他的辅助信息,它就是一个有效的字节码文件,就能够被虚拟机所识别并装载运行.
- 字节码
- 我们平时说的Java字节码,指的是用java语言编译成的字节码.准确的说任何能在jvm平台上执行的字节码格式都是一样的.所以应该统称为:jvm字节码.
- 不同的编译器,可以编译出相同的字节码文件,字节码文件也可以在不同的jvm上运行.
- java虚拟机与java语言并没有必然的联系,它只与特定的二进制文件格式—Class文件格式所关联,Class文件中包含了java虚拟机指令集(或者称为字节码,Bytecodes)和符号表,还有一些其他辅助信息.
- 多语言混合编程
- java平台上的多语言混合编程正成为主流,通过特定领域的语言取解决特定领域的问题是当前软件开发应对日趋复杂的项目需求的一个方向.
- 试想一下,在一个项目之中,并行处理用Clojure语言编写,展示层使用过JRuby/Rails,中间层用过java,每个应用层都将使用不用的编程语言来完成,而且,接口对每一层的开发者都是透明的.各种语言之间的交互不存在任何困难,就像使用自己语言的原生API一样方便,因为它们最终都运行在一个虚拟机上.
- 对这些运行与Java虚拟机上,Java之外的语言,来自系统级的,底层的支持正在迅速增强,以JSR-292为核心的一系列项目和功能改进(如DaVinci Machine项目,Nashorn引擎,InvokeDynamic指令,java.lang.invoke包等),推动Java虚拟机从"Java语言的虚拟机"想"多语言虚拟机"的方向发展.
2. Java发展的重大事件


- Open JDK和Oracle JDK

在JDK11之前,OracleJDK中还会存在一些OpenJDK中没有的,闭源的功能.但在JDK11中,我们可以认为OpenJDK和OracleJDK代码实质上一级完全一致了.
3. 虚拟机与Java虚拟机
- 虚拟机
- 所谓虚拟机(Virtual Machine),就是一台虚拟的计算机,它是一款软件,用来执行一系列虚拟计算机指令.大体上,虚拟机可以分为系统虚拟机和程序虚拟机.
- 大名鼎鼎的Visual Box,VMware就属于系统虚拟机,它们完全是对物理计算机的仿真,提供了一个可运行完整操作系统的软件平台.
- 程序虚拟机的典型代表就是Java虚拟机,它专门为执行单个计算机程序而设计,在java虚拟机中执行的指令我们称为Java字节码指令.
- 无论是系统虚拟机还是程序虚拟机,在上面运行的软件都被限制与虚拟机提供的资源中.
- Java虚拟机
- java虚拟机是一台执行Java字节码的虚拟计算机,它拥有独立的运行机制,其运行的java字节码也未必由Java语言编译而成.
- JVM平台的各种语言可以共享Java虚拟机带来的跨平台型,优秀的垃圾回收器,以及科考的即时编译器.
- JAVA技术的核心就是Java虚拟机(JVM,Java Virtual Machine),因为所有的Java程序都运行在Java虚拟机内部.
- 作用:
- JAVA虚拟机就是二进制字节码的运行环境,负责装载字节码到其内部,解释/编译为对应平台上的机器指令执行.每一条Java指令,Java虚拟机规范都有详细定义,如怎么取操作数,怎么处理操作数,处理结果放在哪里.
- 特点:
- 一次编译,到处运行. 2.自动内存管理. 3. 自动垃圾回收功能
- JVM的位置

JVM是运行在操作系统之上的,它与硬件没有直接的交互.
4. JVM的整体结构
- HotSpot VM是目前市面上高性能虚拟机的代表之一.
- 它采用解释器与即时编译器并存的架构.
- 在今天,Java程序的运行性能早已脱胎换骨,已经达到了可以和C/C++程序一较高下的地步.
谈谈你对JVM整体的理解?
- 类加载子系统
- 运行时数据区(我们核心关注这里的栈,堆,方法区)
- 执行引擎(解释器和JIT编译器共存)
5. Java代码执行流程

6. JVM的架构模型
Java编译器输入的指令流基本上是一种基于栈的指令集架构,另外一种指令集架构则是基于寄存器的指令集架构.
具体来说:这两种架构之间的区别:
- 基于栈式架构的特点:
- 涉及和实现更简单,适用于资源受限的系统.
- 避开了寄存器的分配难题:适用零地址指令方式分配.
- 指令流中的指令大部分是零地址指令,其执行过程依赖于操作栈.指令集更小,编译器容易实现.
- 不需要硬件支持,可移植性更好,更好实现跨平台.
- 基于寄存器架构的特点:
- 典型的应用是x86的二进制指令集,比如传统的PC一级Android的Davlik虚拟机.
- 指令集架构则完全依赖硬件,可移植性差.
- 性能优秀和执行更高效.
- 花费更少的指令取完成一项操作.
- 在大部分情况下,基于寄存器的指令集都以一地址指令,二地址指令和三地址指令,二基于栈式架构的指令集确实以零地址指令为主.
总结:
- 由于跨平台性的设计,Java的指令都是根据栈来设计的,不同平台CPU架构不同,所以不能涉及为基于寄存器的.优点是跨平台,指令集小,编译器容易实现,缺点是性能下降,实现同样的功能需要更多的指令.
- 时至今日,尽管嵌入式平台已经不是Java程序的主流运行平台了(准确来说影视是HotSportVM的宿主环境已经不局限于嵌入式平台了),那么为什么不将架构更换为基于寄存器的架构呢?
7. JVM的生命周期
虚拟机的启动:
- Java虚拟机的启动时通过引导类加载器(bootstrap class loader)创建一个初始类(initial class) 来完成的,这个类是由虚拟机的具体实现指定的.
虚拟机的运行:
- 一个运行的Java虚拟机有着一个清晰的任务:执行Java程序.
- 程序开始执行时它才运行,程序结束时它就停止.
- 执行一个所谓的Java程序的时候,真真正正在执行的是一个叫做Java虚拟机的进程.
虚拟机的退出:
有如下几种情况:
- 程序正常执行结束
- 程序在执行过程中遇到了异常或者错误而异常终止.
- 由于操作系统出现错误而导致Java虚拟机进程终止.
- 某线程调用Runtime类或者System类的exit方法,或Runtime类的halt方法,并且Java安全管理器也运行这次exit或halt操作.
- 除此之外,JNI(Java Native InterFace)规范描述了用JNI Invocation API来加载或者卸载Java虚拟机,Java虚拟机的退出情况.
8. JVM发展历程
- Sun Classic VM
- 早在1996年Java1.0版本的时候,Sun公司发不了一款名为Sun Classic VM的Java虚拟机,它同时也是世界上第一款商用Java虚拟机,JDK1.4时完全被淘汰.
- 这块虚拟机内部只提供解释器.
- 如果使用JIT编译器,就需要进行外挂.但是一旦使用了JIT编译器,JIT就会接管虚拟机的执行系统.解释器就不再工作.解释器和编译器不能配合工作.
- 现在hotspot内置了此虚拟机.
- Exact VM
- 为了解决上一个虚拟机问题,jdk1.2时,sun提供了此虚拟机.
- Exact Memory Management:准确式内存管理.
- 也可以叫Non-Conservative/Accurate Memory Management
- 虚拟机可以知道内存中某个位置的数据具体是什么类型.
- 具体现代高性能逊尼基的雏形
- 热点探测
- 编译器与解释器混合工作模式
- 只在Solaris平台短暂使用,其他平台上还是classic VM
- 英雄气短,终被Hotspot虚拟机替换.
- Sun公司的HotSpot VM
- HotSpot 历史
- 最初有一家名为"Longview Technologies"的小公司涉及.
- 1997年,此公司被Sun公司收购,2009年,Sun公司被甲骨文收购.
- JDK1.3时,HotSpot VM成为默认虚拟机.
- 目前HotSpot 占有绝对的市场地位,称霸武林
- 不管是现在仍在广泛是用的JDK6,还是使用比较多的JDK8中,默认的虚拟机都HotSpot.
- Sun/Oracle JDK和OpenJDK的默认虚拟机.
- 因此本课程默认介绍的虚拟机都是HotSpot .
- 从服务器,桌面到移动端,嵌入式都有应用.
- 通过计数器找到最具编译价值的代码,触发即时编译或者栈上替换.
- 通过编译器与解释器协同工作,在最优化的程序响应时间与最佳执行性能中取得平衡.
- BEA的JRockit
- 专注于服务器端应用
- 它可以不太关注程序启动速度,因此JRockit内部不包含解释器实现,全部代码都是靠即时编译器编译后执行.
- 大量的行业基准测试显示,JRockit JVM是世界上最快的JVM
- 使用JRockit产品,可以已经体验到了显著的西能你提高(一般超过了70%)和硬件成本的减少(50%).
- 优势:全面的Java运行时解决方案组合
- JRockit面向延迟敏感型应用的解决方案JRockit Real Time提供以毫秒或者微秒级的JVM响应时间,适合财务,军事指挥,电信网络的需要.
- MissionControl服务套件,它是一组以极低的开销来监控,管理和分析生产环境中的应用程序的工具.
- 2008年,BEA被Oracle收购.
- Oracle表达了整合两大优势虚拟机的工资,大致在JDK 8中完成.整合的方式是在HotSpot的基础上,一致JRockit的优秀特性.
- IBM的J9
- 全称: IBM Technology for Java Virtual Machine,简称IT4J,内部代号:J9.
- 市场点位与HotSpot接近,服务器端,桌面应用,嵌入式等多用途VM.
- 广泛用于IBM的各种Java产品中
- 目前,有影响力的三大商用服务器之一,也号称世界上最快的Java虚拟机.
- 2017年左右,IBM发布了开源J9 VM,命名为Open J9,交给Ecllipse基金会管理,也成为了Eclipse OpenJ9.
- KVM和CDC/CLDC Hotspot
- Oracle在Java ME产品线上的两款虚拟机为:CDC/CLDC HotSpot Implementation VM>
- KVM(Kilobyte)是CLDC-HT早起产品.
- 目前移动领域地位尴尬,只能手机被安卓和IOS二分天下.
- KVM简单,轻量,高度可移植,面向更低端的设备上还维持自己的一片市场
- 智能控制器,传感器
- 老人手机,经济欠发达地区的功能手机
- 所有的虚拟机的原则:一次编译,到处运行.
- Azul VM
- 前面三大"高性能Java虚拟机"使用在通用硬件平台上.
- 这里Azul VM和BEA Liquid VM是特定硬件平台绑定,软硬件配合的专有虚拟机
- 高性能Java虚拟机中的战斗机.
- Azul VM是Azul Systems公司在Hotspot基础上进行大量改进,运行于Azul Systems公司的专有Vega系统上的Java虚拟机.
- 每个Azul VM实例都可以管理至少数十个CPU和数百GB内存的硬件资源,并提供在巨大内存范围内实现可控的GC时间的垃圾收集器,专有硬件优化的线程调度等有优秀特性.
- 2010年,Azul Systems公司开始从硬件转向软件,发布了自己的Zing JVM,可以在通用X86平台提供接近与Vega系统的特性.
- Liquid VM
- 高性能Java虚拟机中的战斗机.
- BEA公司开发的,直接运行在自家Hypervisor系统上.
- Liquid VM即使现在的JRockit VE,Liquid VM不需要操作系统的支持,或者说它自己本身实现了一个专有的操作系统的必要功能,如线程调度,文件系统,网络支持等.
- 随着JRockit虚拟机终止开发,Liquid VM项目也停止了.
- Apache Harmony
- Apache 也曾经推出过与JDK1.5和JDK1.6兼容的Java运行平台Apache Harmony.
- 它是IBM和Intel联合开发的开源JVM,收到同样开源的OpenJDK的压制,Sun坚决不让Harmony获得JCP认证,最终于2011年退役,IBM转而参加OpenJDK
- 虽然目前并没有Apache Harmony被大规模商用的案例,但是它的Java类库代码吸纳进了Android SDK.
- Microsoft JVM
- 微软为了在IE3浏览器中支持Java Applets,开发了Microsoft JVM.
- 只能在window平台运行.但确实是当时Windows下性能最好的Java VM.
- 1997年,Sun以侵权商标,不正当竞争罪名质控微软成功,陪了sun很多钱,微软在WinowsXP SP3中抹掉了其VM.现在windows上安装的JDK都是HotSpot.
- TaobaoJVM
- 由AliJVM团队发布.阿里,国内使用Java最强大的公司,覆盖了云计算,金融,物流,电商等众多领域,需要解决高并发,高可用,分布式的复合问题.有大量的开源产品.
- 基于OpenJDK开发了自己的定制版本AlibabaJDK,简称AJDK.是整个阿里Java体系的基时.
- 基于OpenJDK HotSpot VM发布的国内第一个优化,深度定制且开源的高性能服务器版Java虚拟机.
- 创新的GCIH(GC invisible heap)技术实现了off-heap,即将全生命周期较长的Java对象从heap中移到heap之外,并且GC不能管理GCIH内部的Java对象,一次达到降低GC的回收频率和提升GC的回收效率的母的.
- GCIH中的对象还能够在多个java虚拟机进程中实现共享.
- 使用crc32指令实现JVM intrinsic降低JNI的调用开销.
- PMU hardware的Java profiling tool和诊断协助工功能.
- 针对大数据场景的ZenGC.
- taobao VM应用在阿里产品上性能高,硬件严重依赖intel的cpu,损失了兼容性,但提高了性能.
- 目前一级在淘宝,天猫上线,把Oracle官方JVM版本全部替换了.
二 类加载子系统

1. 类加载器子系统的作用

- 类加载器子系统负责从文件系统或者忘了中心加载Class文件,class文件在文件开头有特定的文件标识。
- ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定。
加载的类信息存放于一块称为方法区的内存空间。除了类的信息外,方法区中还会存放运行时常量池信息,可能还包括字符串字面量和数字常量(这部分常量信息是Class文件中常量池部分的内存映射)
2. 类加载ClassLoader角色

- class file存在于本地硬盘上,可以理解为设计师画在纸上的模板,而最终这个模板在执行的时候是要加载到JVM当中来根据这个文件实例化n个一模一样的实例。
- class file加载到JVM,被称为DNA元数据模板,放在方法区。
- 在.class文件 -->JVM -->最终成为元数据模板,此过程就要有一个运输工具(类加载器Class Loader)扮演一个快递员的角色。
3. 类加载过程


3.1 加载阶段
- 通过一个类的全限定名获取定义此类的二进制字节流。
- 将这个字节流所代表的的静态存储结果转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
- 类将.class文件加载至元空间后,会在堆中创建一个java.lang.Class对象,用来封装类位于方法区内的数据结构。该Class对象是在加载类的过程中创建的,每个类都对应有一个Class类型的对象。
补充:加载.class文件的方式
- 从本地系统中直接加载
- 通过网络获取,典型场景:Web Applet
- 从zip压缩包中读取,成为日后jar,war格式的基础
- 运行时计算生成,使用最多的是:动态代理技术
- 由其他文件生成,典型场景:JSP应用
- 从专有数据库中提取.class文件,比较少见
- 从加密文件中获取,典型的防Class文件被反编译的保护措施
3.2 链接(Linking)
3.2.1 验证(Verify)
- 目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,保证被加载类的正确性,不会危害虚拟机自身的安全。
- 主要包括四种验证:文件格式验证,元数据验证,字节码验证,符号引用验证。
- 格式检查:是否以魔术oxCAFEBABE开头,主版本和副版本是否在当前Java虚拟机的支持范围内,数据中每一项是否都拥有正确的长度等等。

3.2.2 准备(Prepare)
- 为类变量分配内存并且设置该变量的默认初始值,即零值。
这里不包含用final修饰的static,因为final在编译的时候就会分配了,准备阶段会显示初始化。
这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量会随着对象一起分配到Java堆中。- 注意:Java并不支持boolean类型,对于boolean类型,内部实现是int,由于int的默认值是0,故对应的,boolean的默认值就是false

3.2.3 解析(Resolve)
- 将常量池内的符号引用转换为直接引用的过程。
- 事实上,解析操作往往会伴随着JVM在执行完初始化之后在执行。
- 符号引用就是一组符号来描述所引用的目标。符号引用的字面量形式明确定义在《java虚拟机规范》的Class文件格式中。直接引用就是直接指向目标的指针,相对偏移量或一个间接定位到目标的句柄。
- 解析动作主要针对类或者接口,字段,类方法,接口方法,方法类型等。对应常量池中的CONSTANT_Class_info,CONSTANT_Fieldref_info、CONSTANT_Methodref_info等。
- 符号引号有:类和接口的权限定名、字段的名称和描述符、方法的名称和描述符
解释什么是符号引号和直接引用?
- 教室里有个空的位子没坐人,座位上边牌子写着小明的座位(符号引用),后来小明进来坐下去掉牌子(符号引用换成直接引用)
- 我们去做菜,看菜谱,步骤都是什么样的(这是符号引号),当我们实际上去做,这个过程是直接引用
- 举例:输出操作System.out.println()对应的字节码:
invokevirtual #24 <java/io/PrintStream.println>

以方法为例,Java虚拟机为每个类都准备了一张方法表,将其所有的方法都列在表中,当需要调用一个类的方法的时候,只要知道这个方法在方法表中的偏移量就可以直接调用该方法。通过解析操作,符号引用就可以转变为目标方法在类中方法表中的位置,从而使得方法被成功调用
3.3 初始化(Initialization)
- 为类变量赋予正确的初始化值。
- 初始化阶段就是执行类构造器clinit()的过程。
public class ClassInitTest {
private static int num=1; //类变量的赋值动作
//静态代码快中的语句
static{
num=2;
number=20;
System.out.println(num);
//System.out.println(number); 报错:非法的前向引用
}
//Linking之prepare: number=0 -->initial:20-->10
private static int number=10;
public static void main(String[] args) {
System.out.println(ClassInitTest.num);
System.out.println(ClassInitTest.number);
}
}

- 此方法不需要定义,是javac编译器自动收集类中的所有类变量的赋值动作和静态代码块中的语句合并而来。
- 构造器方法中指令按语句在源文件中出现的顺序执行。
- clinit()不同于类的构造器。(关联:构造器是虚拟机视角下的init())
- 若该类具有父类,JVM会保证子类的clinit()执行前,父类的clinit()依据执行完毕。clinit 不同于类的构造方法(init) (由父及子,静态先行)
public class ClinitTest1 {
static class Father{
public static int A=1;
static{
A=2;
}
}
static class Son extends Father{
public static int B=A;
}
public static void main(String[] args) {
//这个输出2,则说明父类已经全部加载完毕
System.out.println(Son.B);
}
}
- 虚拟机必须保证一个类的clinit()方法在多线程下被同步加锁。
- Java编译器并不会为所有的类都产生clinit()初始化方法。哪些类在编译为字节码后,字节码文件中将不会包含clinit()方法?
- 一个类中并没有声明任何的类变量,也没有静态代码块时
- 一个类中声明类变量,但是没有明确使用类变量的初始化语句以及静态代码块来执行初始化操作时
- 一个类中包含static final修饰的基本数据类型的字段,这些类字段初始化语句采用编译时常量表达式 (如果这个static final 不是通过方法或者构造器,则在链接阶段)
/**
* @author TANGZHI
* @create 2021-01-01 18:49
* 哪些场景下,java编译器就不会生成<clinit>()方法
*/
public class InitializationTest1 {
//场景1:对应非静态的字段,不管是否进行了显式赋值,都不会生成<clinit>()方法
public int num = 1;
//场景2:静态的字段,没有显式的赋值,不会生成<clinit>()方法
public static int num1;
//场景3:比如对于声明为static final的基本数据类型的字段,不管是否进行了显式赋值,都不会生成<clinit>()方法
public static final int num2 = 1;
}
- static与final的搭配问题(使用static + final修饰,且显示赋值中不涉及到方法或构造器调用的基本数据类型或String类型的显式赋值,是在链接阶段的准备环节进行)
/**
* @author TANGZHI
* @create 2021-01-01
*
* 说明:使用static + final修饰的字段的显式赋值的操作,到底是在哪个阶段进行的赋值?
* 情况1:在链接阶段的准备环节赋值
* 情况2:在初始化阶段<clinit>()中赋值
* 结论:
* 在链接阶段的准备环节赋值的情况:
* 1. 对于基本数据类型的字段来说,如果使用static final修饰,则显式赋值(直接赋值常量,而非调用方法)通常是在链接阶段的准备环节进行
* 2. 对于String来说,如果使用字面量的方式赋值,使用static final修饰的话,则显式赋值通常是在链接阶段的准备环节进行
*
* 在初始化阶段<clinit>()中赋值的情况:
* 排除上述的在准备环节赋值的情况之外的情况。
* 最终结论:使用static + final修饰,且显示赋值中不涉及到方法或构造器调用的基本数据类型或String类型的显式赋值,是在链接阶段的准备环节进行。
*/
public class InitializationTest2 {
public static int a = 1;//在初始化阶段<clinit>()中赋值
public static final int INT_CONSTANT = 10;//在链接阶段的准备环节赋值
public static final Integer INTEGER_CONSTANT1 = Integer.valueOf(100);//在初始化阶段<clinit>()中赋值
public static Integer INTEGER_CONSTANT2 = Integer.valueOf(1000);//在初始化阶段<clinit>()中赋值
public static final String s0 = "helloworld0";//在链接阶段的准备环节赋值
public static final String s1 = new String("helloworld1");//在初始化阶段<clinit>()中赋值
public static String s2 = "helloworld2";
public static final int NUM1 = new Random().nextInt(10);//在初始化阶段<clinit>()中赋值
}
- clinit()的调用会死锁吗?
- 虚拟机会保证一个类的()方法在多线程环境中被正确地加锁、同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的()方法,其他线程都需要阻塞等待,直到活动线程执行()方法完毕
- 正是因为函数()带锁线程安全的,因此,如果在一个类的()方法中有耗时很长的操作,就可能造成多个线程阻塞,引发死锁。并且这种死锁是很难发现的,因为看起来它们并没有可用的锁信息
4. 类加载器分类
- JVM支持两种类型的类加载器 。分别为引导类加载器(Bootstrap ClassLoader)和自定义类加载器(User-Defined ClassLoader)。
- 从概念上来讲,自定义类加载器一般指的是程序中由开发人员自定义的一类类加载器,但是Java虚拟机规范却没有这么定义,而是将所有派生于抽象类ClassLoader的类加载器都划分为自定义类加载器。
- 无论类加载器的类型如何划分,在程序中我们最常见的类加载器始终只有3个,如下所示:

这里的四者之间的关系是包含关系。不是上层下层,也不是子父类的继承关系。
4.1 虚拟机自带的加载器
启动类加载器(引导类加载器,Bootstrap ClassLoader)
- 这个类加载使用C/C++语言实现的,嵌套在JVM内部。
- 它用来加载Java的核心库(JAVA_HOME/jre/lib/rt.jar、resources.jar或sun.boot.class.path路径下的内容),用于提供JVM自身需要的类
- 并不继承自ava.lang.ClassLoader,没有父加载器。
- 加载扩展类和应用程序类加载器,并指定为他们的父类加载器。
- 出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类
扩展类加载器(Extension ClassLoader)
- Java语言编写,由sun.misc.Launcher$ExtClassLoader实现。
- 派生于ClassLoader类
- 父类加载器为启动类加载器
- 从java.ext.dirs系统属性所指定的目录中加载类库,或从JDK的安装目录的jre/1ib/ext子目录(扩展目录)下加载类库。如果用户创建的JAR放在此目录下,也会自动由扩展类加载器加载。
4.2 用户自定义类加载器
- 在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,来定制类的加载方式。 为什么要自定义类加载器?
- 隔离加载类
- 修改类加载的方式
- 扩展加载源
- 防止源码泄漏
用户自定义类加载器实现步骤:
- 开发人员可以通过继承抽象类ava.lang.ClassLoader类的方式,实现自己的类加载器,以满足一些特殊的需求
- 在JDK1.2之前,在自定义类加载器时,总会去继承ClassLoader类并重写loadClass() 方法,从而实现自定义的类加载类,但是在JDK1.2之后已不再建议用户去覆盖loadclass() 方法,而是建议把自定义的类加载逻辑写在findClass()方法中
- 在编写自定义类加载器时,如果没有太过于复杂的需求,可以直接继承URLClassLoader类,这样就可以避免自己去编写findClass() 方法及其获取字节码流的方式,使自定义类加载器编写更加简洁。
public class ClassLoaderDemo {
public static void main(String[] args) {
ClassLoader classloader1 = ClassLoader.getSystemClassLoader();
//sun.misc.Launcher$AppClassLoader@18b4aac2
System.out.println(classloader1);
//获取到扩展类加载器
//sun.misc.Launcher$ExtClassLoader@424c0bc4
System.out.println(classloader1.getParent());
//获取到引导类加载器 null
System.out.println(classloader1.getParent().getParent());
//获取系统的ClassLoader
ClassLoader classloader2 = Thread.currentThread().getContextClassLoader();
//sun.misc.Launcher$AppClassLoader@18b4aac2
System.out.println(classloader2);
String[]strArr=new String[10];
ClassLoader classLoader3 = strArr.getClass().getClassLoader();
//null,表示使用的是引导类加载器
System.out.println(classLoader3);
ClassLoaderDemo[]refArr=new ClassLoaderDemo[10];
//sun.misc.Launcher$AppClassLoader@18b4aac2
System.out.println(refArr.getClass().getClassLoader());
int[]intArr=new int[10];
//null,如果数组的元素类型是基本数据类型,数组类是没有类加载器的
System.out.println(intArr.getClass().getClassLoader());
}
}
4.3 ClassLoader的使用说明
- ClassLoader类是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器)


获取ClassLoader的途径
方式一:获取当前ClassLoader
clazz.getClassLoader()
方式二:获取当前线程上下文的ClassLoader
Thread.currentThread().getContextClassLoader()
方式三:获取系统的ClassLoader
ClassLoader.getSystemClassLoader()
方式四:获取调用者的ClassLoader
DriverManager.getCallerClassLoader()
4.3 双亲委派机制
Java虚拟机对class文件采用的是按需加载的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成class对象。而且加载某个类的class文件时,Java虚拟机采用的是双亲委派模式,即把请求交由父类处理,它是一种任务委派模式。
工作原理
- 如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行;
- 如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器;
- 如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。


举例
- 当我们加载jdbc.jar 用于实现数据库连接的时候,首先我们需要知道的是 jdbc.jar是基于SPI接口进行实现的,所以在加载的时候,会进行双亲委派,最终从根加载器中加载 SPI核心类,然后在加载SPI接口类,接着在进行反向委派,通过线程上下文类加载器进行实现类jdbc.jar的加载。

优势
- 避免类的重复加载
- 保护程序安全,防止核心API被随意篡改
- 自定义类:java.lang.String
- 自定义类:java.lang.ShkStart(报错:阻止创建 java.lang开头的类)
沙箱安全机制
- 自定义String类,但是在加载自定义String类的时候会率先使用引导类加载器加载,而引导类加载器在加载的过程中会先加载jdk自带的文件(rt.jar包中java\lang\String.class),报错信息说没有main方法,就是因为加载的是rt.jar包中的string类。这样可以保证对java核心源代码的保护,这就是沙箱安全机制。
- 如图,虽然我们自定义了一个java.lang包下的String尝试覆盖核心类库中的String,但是由于双亲委派机制,启动加载器会加载java核心类库的String类(BootStrap启动类加载器只加载包名为java、javax、sun等开头的类),而核心类库中的String并没有main方法

5. 其他
如何判断两个class对象是否相同
在JVM中表示两个class对象是否为同一个类存在两个必要条件:
- 类的完整类名必须一致,包括包名。
- 加载这个类的ClassLoader(指ClassLoader实例对象)必须相同。
换句话说,在JVM中,即使这两个类对象(class对象)来源同一个Class文件,被同一个虚拟机所加载,但只要加载它们的ClassLoader实例对象不同,那么这两个类对象也是不相等的。
对类加载器的引用
JVM必须知道一个类型是由启动加载器加载的还是由用户类加载器加载的。如果一个类型是由用户类加载器加载的,那么JVM会将这个类加载器的一个引用作为类型信息的一部分保存在方法区中。当解析一个类型到另一个类型的引用的时候,JVM需要保证这两个类型的类加载器是相同的。
类的主动使用和被动使用
Java程序对类的使用方式分为:主动使用和被动使用。
主动使用,又分为七种情况:
- 创建类的实例
- 访问某个类或接口的静态变量,或者对该静态变量赋值
- 调用类的静态方法
- 反射(比如:Class.forName(“com.atguigu.Test”))
- 初始化一个类的子类
- Java虚拟机启动时被标明为启动类的类
- JDK 7 开始提供的动态语言支持:
java.lang.invoke.MethodHandle实例的解析结果
REF_getStatic、REF_putStatic、REF_invokeStatic句柄对应的类没有初始化,则初始化
除了以上七种情况,其他使用Java类的方式都被看作是对类的被动使用,都不会导致类的初始化。
三 运行时数据区
1. 运行时数据区
1.1 概述
本节主要讲的是运行时数据区,也就是下图这部分,它是在类加载完成后的阶段

当我们通过前面的:类的加载-> 验证 -> 准备 -> 解析 -> 初始化 这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时执行引擎将会使用到我们运行时数据区

内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行JVM内存布局规定了Java在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。不同的JVM对于内存的划分方式和管理机制存在着部分差异。结合JVM虚拟机规范,来探讨一下经典的JVM内存布局。

我们通过磁盘或者网络IO得到的数据,都需要先加载到内存中,然后CPU从内存中获取数据进行读取,也就是说内存充当了CPU和磁盘之间的桥梁

Java虚拟机定义了若干种程序运行期间会使用到的运行时数据区,其中有一些会随着虚拟机启动而创建,随着虚拟机退出而销毁。另外一些则是与线程一一对应的,这些与线程对应的数据区域会随着线程开始和结束而创建和销毁。
灰色的为单独线程私有的,红色的为多个线程共享的。即:
- 每个线程:独立包括程序计数器、栈、本地栈。
- 线程间共享:堆、堆外内存(永久代或元空间、代码缓存)

每个JVM只有一个Runtime实例。即为运行时环境,相当于内存结构的中间的那个框框:运行时环境。

1.2 线程
- 线程是一个程序里的运行单元。JVM允许一个应用有多个线程并行的执行。 在Hotspot JVM里,每个线程都与操作系统的本地线程直接映射。
- 当一个Java线程准备好执行以后,此时一个操作系统的本地线程也同时创建。Java线程执行终止后,本地线程也会回收。
- 操作系统负责所有线程的安排调度到任何一个可用的CPU上。一旦本地线程初始化成功,它就会调用Java线程中的run()方法。
1.3 JVM系统线程
- 如果你使用console或者是任何一个调试工具,都能看到在后台有许多线程在运行。这些后台线程不包括调用public static void main(String[] args)的main线程以及所有这个main线程自己创建的线程。
- 这些主要的后台系统线程在Hotspot JVM里主要是以下几个:
- 虚拟机线程:这种线程的操作是需要JVM达到安全点才会出现。这些操作必须在不同的线程中发生的原因是他们都需要JVM达到安全点,这样堆才不会变化。这种线程的执行类型包括"stop-the-world"的垃圾收集,线程栈收集,线程挂起以及偏向锁撤销。
- 周期任务线程:这种线程是时间周期事件的体现(比如中断),他们一般用于周期性操作的调度执行。
- GC线程:这种线程对在JVM里不同种类的垃圾收集行为提供了支持。
- 编译线程:这种线程在运行时会将字节码编译成到本地代码。
- 信号调度线程:这种线程接收信号并发送给JVM,在它内部通过调用适当的方法进行处理。
2. 程序计数器(PC寄存器)
JVM中的程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,寄存器存储指令相关的现场信息。CPU只有把数据装载到寄存器才能够运行。这里,并非是广义上所指的物理寄存器,或许将其翻译为PC计数器(或指令计数器)会更加贴切(也称为程序钩子),并且也不容易引起一些不必要的误会。JVM中的PC寄存器是对物理PC寄存器的一种抽象模拟。

作用
- PC寄存器用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令。
- 特点(是线程私有的 、不会存在内存溢出)
- 意:在物理上实现程序计数器是在寄存器实现的,整个cpu中最快的一个执行单元
- 是唯一一个在java虚拟机规范中没有OOM的区域

- 它是一块很小的内存空间,几乎可以忽略不记。也是运行速度最快的存储区域。
- 在JVM规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程的生命周期保持一致。
- 任何时间一个线程都只有一个方法在执行,也就是==所谓的当前方法。==程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;或者,如果是在执行native方法,则是未指定值(undefined)。
- 它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
- 字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
- 它是唯一一个在Java虚拟机规范中没有规定任何OutofMemoryError情况的区域。
使用PC寄存器存储字节码指令地址有什么用呢?为什么使用PC寄存器记录当前线程的执行地址呢?
- 因为CPU需要不停的切换各个线程,这时候切换回来以后,就得知道接着从哪开始继续执行。
- JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令。

PC寄存器为什么被设定为私有的?
- 我们都知道所谓的多线程在一个特定的时间段内只会执行其中某一个线程的方法,CPU会不停地做任务切换,这样必然导致经常中断或恢复,如何保证分毫无差呢?为了能够准确地记录各个线程正在执行的当前字节码指令地址,最好的办法自然是为每一个线程都分配一个PC寄存器,这样一来各个线程之间便可以进行独立计算,从而不会出现相互干扰的情况。
- 由于CPU时间片轮限制,众多线程在并发执行过程中,任何一个确定的时刻,一个处理器或者多核处理器中的一个内核,只会执行某个线程中的一条指令。
- 这样必然导致经常中断或恢复,如何保证分毫无差呢?每个线程在创建后,都会产生自己的程序计数器和栈帧,程序计数器在各个线程之间互不影响。
CPU时间片
- CPU时间片即CPU分配给各个程序的时间,每个线程被分配一个时间段,称作它的时间片。
- 在宏观上:俄们可以同时打开多个应用程序,每个程序并行不悖,同时运行。
- 但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,每个程序轮流执行。
四 虚拟机栈
4.1. 虚拟机栈概述
4.1.1 背景
- 由于跨平台性的设计,Java的指令都是根据栈来设计的。不同平台CPU架构不同,所以不能设计为基于寄存器的。
- 优点是跨平台,指令集小,编译器容易实现,缺点是性能下降,实现同样的功能需要更多的指令。
4.1.2 内存中的栈与堆
- 栈是运行时的单位,而堆是存储的单位
- 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据。
- 堆解决的是数据存储的问题,即数据怎么放,放哪里
4.1.3 虚拟机栈基本内容
Java虚拟机栈是什么?
Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的Java方法调用,是线程私有的。
生命周期
生命周期和线程一致
作用
主管Java程序的运行,它保存方法的局部变量、部分结果,并参与方法的调用和返回。
栈的特点
- 栈是一种快速有效的分配存储方式,访问速度仅次于罹序计数器。
- JVM直接对Java栈的操作只有两个:
- 每个方法执行,伴随着进栈(入栈、压栈)
- 执行结束后的出栈工作
- 对于栈来说不存在垃圾回收问题(栈存在溢出的情况)

栈中可能出现的异常
- Java 虚拟机规范允许Java栈的大小是动态的或者是固定不变的。
- 如果采用固定大小的Java虚拟机栈,那每一个线程的Java虚拟机栈容量可以在线程创建的时候独立选定。如果线程请求分配的栈容量超过Java虚拟机栈允许的最大容量,Java虚拟机将会抛出一个StackOverflowError 异常。
- 如果Java虚拟机栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的虚拟机栈,那Java虚拟机将会抛出一个 ==OutOfMemoryError ==异常。
public static void main(String[] args) {
test();
}
public static void test() {
test();
}
//抛出异常:Exception in thread"main"java.lang.StackoverflowError
//程序不断的进行递归调用,而且没有退出条件,就会导致不断地进行压栈。
设置栈内存大小
- 我们可以使用参数 -Xss选项来设置线程的最大栈空间,栈的大小直接决定了函数调用的最大可达深度
- 如何设置栈内存的大小? -Xss size (即:-XX:ThreadStackSize)
- 一般默认为512k-1024k,取决于操作系统(jdk5之前,默认栈大小是256k;jdk5之后,默认栈大小是1024k)
栈的大小直接决定了函数调用的最大可达深度
public class StackDeepTest{
private static int count=0;
public static void recursion(){
count++;
recursion();
}
public static void main(String args[]){
try{
recursion();
} catch (Throwable e){
System.out.println("deep of calling="+count);
e.printstackTrace();
}
}
}
4.2 栈的存储单位
4.2.1 栈中存储什么?
- 每个线程都有自己的栈,栈中的数据都是以栈帧(Stack Frame)的格式存在。
- 在这个线程上正在执行的每个方法都各自对应一个栈帧(Stack Frame)。
- 栈帧是一个内存区块,是一个数据集,维系着方法执行过程中的各种数据信息。
4.2.2 栈运行原理
- JVM直接对Java栈的操作只有两个,就是对栈帧的压栈和出栈,遵循“先进后出”/“后进先出”原则。
- 在一条活动线程中,一个时间点上,只会有一个活动的栈帧。即只有当前正在执行的方法的栈帧(栈顶栈帧)是有效的,这个栈帧被称为当前栈帧(Current Frame),与当前栈帧相对应的方法就是当前方法(Current Method),定义这个方法的类就是当前类(Current Class)。
- 执行引擎运行的所有字节码指令只针对当前栈帧进行操作。
- 如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,放在栈的顶端,成为新的当前帧。

- 不同线程中所包含的栈帧是不允许存在相互引用的,即不可能在一个栈帧之中引用另外一个线程的栈帧。
- 如果当前方法调用了其他方法,方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着,虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧。
- Java方法有两种返回函数的方式,一种是正常的函数返回,使用return指令;另外一种是抛出异常。不管使用哪种方式,都会导致栈帧被弹出。
public class CurrentFrameTest{
public void methodA(){
system.out.println("当前栈帧对应的方法->methodA");
methodB();
system.out.println("当前栈帧对应的方法->methodA");
}
public void methodB(){
System.out.println("当前栈帧对应的方法->methodB");
}
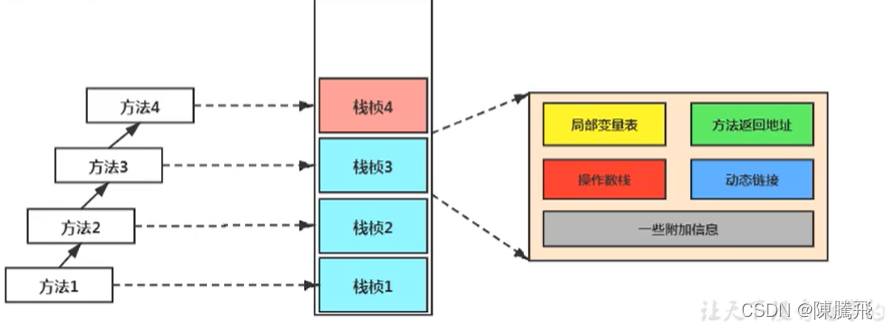
4.2.3 栈帧的内部结构
每个栈帧中存储着:
- 局部变量表(Local Variables)
- 操作数栈(operand Stack)(或表达式栈)
- 动态链接(DynamicLinking)(或指向运行时常量池的方法引用)
- 方法返回地址(Return Address)(或方法正常退出或者异常退出的定义)
- 一些附加信息
- 不同线程中所包含的栈帧是不允许存在相互引用的,即不可能在一个栈帧之中引用另外一个线程的栈帧。
- 如果当前方法调用了其他方法,方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着,虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧。
- Java方法有两种返回函数的方式,一种是正常的函数返回,使用return指令;另外一种是抛出异常。不管使用哪种方式,都会导致栈帧被弹出。
public class CurrentFrameTest{
public void methodA(){
system.out.println("当前栈帧对应的方法->methodA");
methodB();
system.out.println("当前栈帧对应的方法->methodA");
}
public void methodB(){
System.out.println("当前栈帧对应的方法->methodB");
}
4.2.4 栈帧的内部结构
每个栈帧中存储着:
- 局部变量表(Local Variables)
- 动态链接(DynamicLinking)(或指向运行时常量池的方法引用)
- 动态链接(DynamicLinking)(或指向运行时常量池的方法引用)
- 方法返回地址(Return Address)(或方法正常退出或者异常退出的定义)
- 一些附加信息

并行每个线程下的栈都是私有的,因此每个线程都有自己各自的栈,并且每个栈里面都有很多栈帧,栈帧的大小主要由局部变量表 和 操作数栈决定的

4.3 局部变量表(Local Variables)
- 局部变量表也被称之为局部变量数组或本地变量表
- 定义为一个数字数组,主要用于存储方法参数和定义在方法体内的局部变量,这些数据类型包括各类基本数据类型、对象引用(reference),以及returnAddress类型。
- 由于局部变量表是建立在线程的栈上,是线程的私有数据,==因此不存在数据安全问题 ==
- ==局部变量表所需的容量大小是在编译期确定下来的,==并保存在方法的Code属性的maximum local variables数据项中。在方法运行期间是不会改变局部变量表的大小的。
- 方法嵌套调用的次数由栈的大小决定。一般来说,==栈越大,方法嵌套调用次数越多。==对一个函数而言,它的参数和局部变量越多,使得局部变量表膨胀,它的栈帧就越大,以满足方法调用所需传递的信息增大的需求。进而函数调用就会占用更多的栈空间,导致其嵌套调用次数就会减少。
- ==局部变量表中的变量只在当前方法调用中有效。==在方法执行时,虚拟机通过使用局部变量表完成参数值到参数变量列表的传递过程。当方法调用结束后,随着方法栈帧的销毁,局部变量表也会随之销毁。
//使用javap -v 类.class 或者使用jclasslib
public class LocalVariableTest {
public static void main(String[] args) {
LocalVariableTest test=new LocalVariableTest();
int num=10;
test.test1();
}
public static void test1(){
Date date=new Date();
String name="xiaozhi";
}
}
jclasslib截图说明如下:



4.3.1 关于Slot的理解
- 局部变量表,最基本的存储单元是Slot(变量槽)
- 参数值的存放总是在局部变量数组的index0开始,到数组长度-1的索引结束。
- 局部变量表中存放编译期可知的各种基本数据类型(8种),引用类型(reference),returnAddress类型的变量。
- 在局部变量表里,32位以内的类型只占用一个slot(包括returnAddress类型),64位的类型(long和double)占用两个slot。
- byte、short、char 在存储前被转换为int,boolean也被转换为int,0表示false,非0表示true。
- JVM会为局部变量表中的每一个Slot都分配一个访问索引,通过这个索引即可成功访问到局部变量表中指定的局部变量值
- 当一个实例方法被调用的时候,它的方法参数和方法体内部定义的局部变量将会按照顺序被复制到局部变量表中的每一个slot上
- 如果需要访问局部变量表中一个64bit的局部变量值时,只需要使用前一个索引即可。(比如:访问long或doub1e类型变量)
- 如果当前帧是由构造方法或者实例方法创建的,那么该对象引用this将会存放在index为0的slot处,其余的参数按照参数表顺序继续排列。


4.3.2 Slot的重复利用
栈帧中的局部变量表中的槽位是可以重用的,如果一个局部变量过了其作用域,那么在其作用域之后申明的新的局部变就很有可能会复用过期局部变量的槽位,从而达到节省资源的目的。
public class SlotTest {
public void localVarl() {
int a = 0;
System.out.println(a);
int b = 0;
}
public void localVar2() {
{
int a = 0;
System.out.println(a);
}
//此时的就会复用a的槽位
int b = 0;
}
}
4.3.3. 静态变量与局部变量的对比
- 参数表分配完毕之后,再根据方法体内定义的变量的顺序和作用域分配。
- 我们知道类变量表有两次初始化的机会,第一次是在==“准备阶段”,执行系统初始化,对类变量设置零值,另一次则是在“初始化”==阶段,赋予程序员在代码中定义的初始值。
- 和类变量初始化不同的是,局部变量表不存在系统初始化的过程,这意味着一旦定义了局部变量则必须人为的初始化,否则无法使用。
//这样的代码是错误的,没有赋值不能够使用。
public void test(){
int i;
System. out. println(i);
}
补充说明
- 在栈帧中,与性能调优关系最为密切的部分就是前面提到的局部变量表。在方法执行时,虚拟机使用局部变量表完成方法的传递。
- 局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或间接引用的对象都不会被回收。
4.4. 操作数栈(Operand Stack)
- 每一个独立的栈帧除了包含局部变量表以外,还包含一个后进先出(Last-In-First-Out)的 操作数栈,也可以称之为表达式栈(Expression Stack)
- 操作数栈,在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈(push)和 出栈(pop)
- 某些字节码指令将值压入操作数栈,其余的字节码指令将操作数取出栈。使用它们后再把结果压入栈
- 比如:执行复制、交换、求和等操作

public void testAddOperation(){
byte i = 15;
int j = 8;
int k = i + j;
}
public void testAddOperation();
Code:
0: bipush 15
2: istore_1
3: bipush 8
5: istore_2
6:iload_1
7:iload_2
8:iadd
9:istore_3
10:return
- 操作数栈,主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间。
- 操作数栈就是JVM执行引擎的一个工作区,当一个方法刚开始执行的时候,一个新的栈帧也会随之被创建出来,这个方法的操作数栈是空的。
- 每一个操作数栈都会拥有一个明确的栈深度用于存储数值,其所需的最大深度在编译期就定义好了,保存在方法的Code属性中,为max_stack的值。
- 栈中的任何一个元素都是可以任意的Java数据类型
- 32bit的类型占用一个栈单位深度
- 64bit的类型占用两个栈单位深度
- 操作数栈并非采用访问索引的方式来进行数据访问的,而是只能通过标准的入栈和出栈操作来完成一次数据访问
- 如果被调用的方法带有返回值的话,其返回值将会被压入当前栈帧的操作数栈中,并更新PC寄存器中下一条需要执行的字节码指令。
- 操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,这由编译器在编译器期间进行验证,同时在类加载过程中的类检验阶段的数据流分析阶段要再次验证。
- 另外,我们说Java虚拟机的解释引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。
4.5. 代码追踪
public void testAddOperation() {
byte i = 15;
int j = 8;
int k = i + j;
}
使用javap 命令反编译class文件:javap -v 类名.class
public void testAddoperation();
Code:
0: bipush 15
2: istore_1
3: bipush 8
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: return








4.6. 栈顶缓存技术(Top Of Stack Cashing)技术
- 前面提过,基于栈式架构的虚拟机所使用的零地址指令更加紧凑,但完成一项操作的时候必然需要使用更多的入栈和出栈指令,这同时也就意味着将需要更多的指令分派(instruction dispatch)次数和内存读/写次数。
- 由于操作数是存储在内存中的,因此频繁地执行内存读/写操作必然会影响执行速度。为了解决这个问题,HotSpot JVM的设计者们提出了栈顶缓存(Tos,Top-of-Stack Cashing)技术,将栈顶元素全部缓存在物理CPU的寄存器中,以此降低对内存的读/写次数,提升执行引擎的执行效率。
4.7. 动态链接(Dynamic Linking)
- 动态链接、方法返回地址、附加信息 : 有些地方被称为帧数据区
- 每一个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用。包含这个引用的目的就是为了支持当前方法的代码能够实现动态链接(Dynamic Linking)。比如:invokedynamic指令
- 在Java源文件被编译到字节码文件中时,所有的变量和方法引用都作为符号引用(Symbolic Reference)保存在class文件的常量池里。比如:描述一个方法调用了另外的其他方法时,就是通过常量池中指向方法的符号引用来表示的,那么动态链接的作用就是为了将这些符号引用转换为调用方法的直接引用。

为什么需要运行时常量池呢?
常量池的作用:就是为了提供一些符号和常量,便于指令的识别.


4.8. 方法的调用
在JVM中,将符号引用转换为调用方法的直接引用与方法的绑定机制相关.
静态链接:
当一个字节码文件被装载进JVM内部时,如果被调用的目标方法在编译期可知,且运行期保持不变时,这种情况下降调用方法的符号引用转换为直接引用的过程称之为静态链接
动态链接:
如果被调用的方法在编译期无法被确定下来,只能够在程序运行期将调用的方法的符号转换为直接引用,由于这种引用转换过程具备动态性,因此也被称之为动态链接。
静态链接和动态链接不是名词,而是动词,这是理解的关键。
对应的方法的绑定机制为:早期绑定(Early Binding)和晚期绑定(Late Binding)。绑定是一个字段、方法或者类在符号引用被替换为直接引用的过程,这仅仅发生一次。
早期绑定:
早期绑定就是指被调用的目标方法如果在编译期可知,且运行期保持不变时,即可将这个方法与所属的类型进行绑定,这样一来,由于明确了被调用的目标方法究竟是哪一个,因此也就可以使用静态链接的方式将符号引用转换为直接引用。
晚期绑定
如果被调用的方法在编译期无法被确定下来,只能够在程序运行期根据实际的类型绑定相关的方法,这种绑定方式也就被称之为晚期绑定。
随着高级语言的横空出世,类似于Java一样的基于面向对象的编程语言如今越来越多,尽管这类编程语言在语法风格上存在一定的差别,但是它们彼此之间始终保持着一个共性,那就是都支持封装、继承和多态等面向对象特性,既然这一类的编程语言具备多态特悄,那么自然也就具备早期绑定和晚期绑定两种绑定方式。
Java中任何一个普通的方法其实都具备虚函数的特征,它们相当于C语言中的虚函数(C中则需要使用关键字virtual来显式定义)。如果在Java程序中不希望某个方法拥有虚函数的特征时,则可以使用关键字final来标记这个方法。
4.8.1 虚方法和非虚方法
非虚方法:
- 如果方法在编译期就确定了具体的调用版本,这个版本在运行时是不可变的。这样的方法称为非虚方法。
- 静态方法、私有方法、final方法、实例构造器、父类方法都是非虚方法。其他方法称为虚方法。
在类加载的解析阶段就可以进行解析,如下是非虚方法举例
class Father{
public static void print(String str){
System. out. println("father "+str);
}
private void show(String str){
System. out. println("father"+str);
}
}
class Son extends Father{
public class VirtualMethodTest{
public static void main(String[] args){
Son.print("coder");
//Father fa=new Father();
//fa.show("atguigu.com");
}
}
虚拟机中提供了以下几条方法调用指令:
普通调用指令:
- invokestatic:调用静态方法,解析阶段确定唯一方法版本
- invokespecial:调用方法、私有及父类方法,解析阶段确定唯一方法版本
- invokevirtual:调用所有虚方法
- invokeinterface:调用接口方法
动态调用指令:
- invokedynamic:动态解析出需要调用的方法,然后执行
前四条指令固化在虚拟机内部,方法的调用执行不可人为干预,而invokedynamic指令则支持由用户确定方法版本。其中invokestatic指令和invokespecial指令调用的方法称为非虚方法,其余的(fina1修饰的除外)称为虚方法。
/**
* 解析调用中非虚方法、虚方法的测试
*/
class Father {
public Father(){
System.out.println("Father默认构造器");
}
public static void showStatic(String s){
System.out.println("Father show static"+s);
}
public final void showFinal(){
System.out.println("Father show final");
}
public void showCommon(){
System.out.println("Father show common");
}
}
public class Son extends Father{
public Son(){
super();
}
public Son(int age){
this();
}
public static void main(String[] args) {
Son son = new Son();
son.show();
}
//不是重写的父类方法,因为静态方法不能被重写
public static void showStatic(String s){
System.out.println("Son show static"+s);
}
private void showPrivate(String s){
System.out.println("Son show private"+s);
}
public void show(){
//invokestatic
showStatic(" 大头儿子");
//invokestatic
super.showStatic(" 大头儿子");
//invokespecial
showPrivate(" hello!");
//invokespecial
super.showCommon();
//invokevirtual 因为此方法声明有final 不能被子类重写,所以也认为该方法是非虚方法
showFinal();
//虚方法如下
//invokevirtual
showCommon();//没有显式加super,被认为是虚方法,因为子类可能重写showCommon
info();
MethodInterface in = null;
//invokeinterface 不确定接口实现类是哪一个 需要重写
in.methodA();
}
public void info(){
}
}
interface MethodInterface {
void methodA();
}
关于invokednamic指令
- JVM字节码指令集一直比较稳定,一直到Java7中才增加了一个invokedynamic指令,这是Java为了实现「动态类型语言」支持而做的一种改进。
- 但是在Java7中并没有提供直接生成invokedynamic指令的方法,需要借助ASM这种底层字节码工具来产生invokedynamic指令。直到Java8的Lambda表达式的出现,invokedynamic指令的生成,在Java中才有了直接的生成方式。
- Java7中增加的动态语言类型支持的本质是对Java虚拟机规范的修改,而不是对Java语言规则的修改,这一块相对来讲比较复杂,增加了虚拟机中的方法调用,最直接的受益者就是运行在Java平台的动态语言的编译器。
动态类型语言和静态类型语言
- 动态类型语言和静态类型语言两者的区别就在于对类型的检查是在编译期还是在运行期,满足前者就是静态类型语言,反之是动态类型语言。
- 说的再直白一点就是,静态类型语言是判断变量自身的类型信息;动态类型语言是判断变量值的类型信息,变量没有类型信息,变量值才有类型信息,这是动态语言的一个重要特征。
- Java是静态类型语言(尽管lambda表达式为其增加了动态特性),js,python是动态类型语言
Java:String info = "小智";//静态语言
JS:var name = "小智“;var name = 10;//动态语言
Pythom: info = 130;//更加彻底的动态语言
Java 语言中方法重写的本质:
- pc寄存器每执行一条指令都会被改变,而返回地址在调用call之前一直是上一条call后面的地址,不改变
- 找到操作数栈顶的第一个元素所执行的对象的实际类型,记作C。
- 如果在类型C中找到与常量中的描述符合简单名称都相符的方法,则进行访问权限校验,如果通过则返回这个方法的直接引用,查找过程结束;如果不通过,则返回java.lang.IllegalAccessError 异常。
- 否则,按照继承关系从下往上依次对C的各个父类进行第2步的搜索和验证过程。
- 如果始终没有找到合适的方法,则抛出java.1ang.AbstractMethodsrror异常。
IllegalAccessError介绍
- 程序试图访问或修改一个属性或调用一个方法,这个属性或方法,你没有权限访问。一般的,这个会引起编译器异常。这个错误如果发生在运行时,就说明一个类发生了不兼容的改变。
4.8.2 方法的调用:虚方法表
- 在面向对象的编程中,会很频繁的使用到动态分派,如果在每次动态分派的过程中都要重新在类的方法元数据中搜索合适的目标的话就可能影响到执行效率。因此,为了提高性能,JVM采用在类的方法区建立一个虚方法表 (virtual method table)(非虚方法不会出现在表中)来实现。使用索引表来代替查找。
- 每个类中都有一个虚方法表,表中存放着各个方法的实际入口。
- 虚方法表是什么时候被创建的呢?
- 虚方法表会在类加载的链接阶段被创建并开始初始化,类的变量初始值准备完成之后,JVM会把该类的方法表也初始化完毕。

interface Friendly{
void sayHello();
void sayGoodbye();
}
class Dog{
public void sayHello(){
}
public String tostring(){
return "Dog";
}
}
class Cat implements Friendly {
public void eat() {
}
public void sayHello() {
}
public void sayGoodbye() {
}
protected void finalize() {
}
}
class CockerSpaniel extends Dog implements Friendly{
public void sayHello() {
super.sayHello();
}
public void sayGoodbye() {
}
}

4.9. 方法返回地址(return address)
- 存放调用该方法的pc寄存器的值。一个方法的结束,有两种方式:
- 正常执行完成
- 出现未处理的异常,非正常退出
- 无论通过哪种方式退出,在方法退出后都返回到该方法被调用的位置。方法正常退出时,调用者的pc计数器的值作为返回地址,即调用该方法的指令的下一条指令的地址。而通过异常退出的,返回地址是要通过异常表来确定,栈帧中一般不会保存这部分信息。
- 本质上,方法的退出就是当前栈帧出栈的过程.此时,需要恢复上层方法的局部变量表,操作数栈,将返回值压入调用者栈帧的操作数栈,设置PC寄存器值等,让调用方法继续执行下去.
- 正常完成出口和异常完成出口的区别在于:通过异常完成出口退出的不会给他的上层调用者产生任何的返回值.
当一个方法开始执行后,只有两种方式可以退出这个方法:
- 执行引擎遇到任意一个方法返回的字节码指令(return),会有返回值传递给上层的方法调用者,简称正常完成出口;
- 一个方法在正常调用完成之后,究竟需要使用哪一个返回指令,还需要根据方法返回值的实际数据类型而定。
- 在字节码指令中,返回指令包含ireturn(当返回值是boolean,byte,char,short和int类型时使用),lreturn(Long类型),freturn(Float类型),dreturn(Double类型),areturn。另外还有一个return指令声明为void的方法,实例初始化方法,类和接口的初始化方法使用。
- 在方法执行过程中遇到异常(Exception),并且这个异常没有在方法内进行处理,也就是只要在本方法的异常表中没有搜索到匹配的异常处理器,就会导致方法退出,简称异常完成出口。

方法执行过程中,抛出异常时的异常处理,存储在一个异常处理表,方便在发生异常的时候找到处理异常的代码

本质上,方法的退出就是当前栈帧出栈的过程。此时,需要恢复上层方法的局部变量表、操作数栈、将返回值压入调用者栈帧的操作数栈、设置PC寄存器值等,让调用者方法继续执行下去。
正常完成出口和异常完成出口的区别在于:通过异常完成出口退出的不会给他的上层调用者产生任何的返回值。
4.10 一些附加信息
栈帧中还允许携带与Java虚拟机实现相关的一些附加信息。例如:对程序调试提供支持的信息。

栈的相关面试题
- 栈溢出的情况?栈溢出:StackOverflowError
- 栈中是不存在GC的,存在OOM和StackOverflowError
- 举个简单的例子:在main方法中调用main方法,就会不断压栈执行,直到栈溢出;
- 栈的大小可以是固定大小的,也可以是动态变化(动态扩展)的
- 如果是固定的,那么会抛出StackOverflowError
- 如果是动态扩展的,那么会抛出OOM异常(java.lang.OutOfMemoryError)
- 举例栈溢出的情况?(StackOverflowError)
- 通过 -Xss设置栈的大小
- 调整栈大小,就能保证不出现溢出么?
- 不能。因为调整栈大小,只会减少出现溢出的可能,栈大小不是可以无限扩大的,所以不能保证不出现溢出
- 分配的栈内存越大越好么?
- 不是,一定时间内降低了OOM概率,但是会挤占其它的线程空间,因为整个空间是有限的。
- 垃圾回收是否涉及到虚拟机栈?
- 不会;垃圾回收只会涉及到方法区和堆中,方法区和堆也会存在溢出的可能
- 程序计数器,只记录运行下一行的地址,不存在溢出和垃圾回收
- 虚拟机栈和本地方法栈,都是只涉及压栈和出栈,可能存在栈溢出,不存在垃圾回收
- 方法中定义的局部变量是否线程安全?
- 具体问题具体分析。如果对象是在内部产生,并在内部消亡,没有返回到外部,那么它就是线程安全的,反之则是线程不安全的。
/**方法中定义的局部变量是否线程安全? 具体问题具体分析
* @author shkstart
* @create 15:53
*/
public class LocalVariableThreadSafe {
//s1的声明方式是线程安全的,因为线程私有,在线程内创建的s1 ,不会被其它线程调用
public static void method1() {
//StringBuilder:线程不安全
StringBuilder s1 = new StringBuilder();
s1.append("a");
s1.append("b");
//...
}
//stringBuilder的操作过程:是线程不安全的,
// 因为stringBuilder是外面传进来的,有可能被多个线程调用
public static void method2(StringBuilder stringBuilder) {
stringBuilder.append("a");
stringBuilder.append("b");
//...
}
//stringBuilder的操作:是线程不安全的;因为返回了一个stringBuilder,
// stringBuilder有可能被其他线程共享
public static StringBuilder method3() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("a");
stringBuilder.append("b");
return stringBuilder;
}
//stringBuilder的操作:是线程安全的;因为返回了一个stringBuilder.toString()相当于new了一个String,
// 所以stringBuilder没有被其他线程共享的可能
public static String method4() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("a");
stringBuilder.append("b");
return stringBuilder.toString();
/**
* 结论:如果局部变量在内部产生并在内部消亡的,那就是线程安全的
*/
}
}
| 运行时数据区 | 是否存在Error | 是否存在GC |
|---|---|---|
| 程序计数器 | 否 | 否 |
| 虚拟机栈 | 是(SOE) | 否 |
| 本地方法栈 | 是 | 否 |
| 方法区 | 是(OOM) | 是 |
| 堆 | 是 | 是 |
五 本地方法接口和本地方法栈
5.1. 本地方法接口

什么是本地方法?
简单地讲,一个Native Method是一个Java调用非Java代码的接囗。一个Native Method是这样一个Java方法:该方法的实现由非Java语言实现,比如C。这个特征并非Java所特有,很多其它的编程语言都有这一机制,比如在C中,你可以用extern “c” 告知c编译器去调用一个c的函数。
在定义一个native method时,并不提供实现体(有些像定义一个Java interface),因为其实现体是由非java语言在外面实现的。
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序。
//标识符native可以与其它java标识符连用,但是abstract除外
public class IHaveNatives{
public native void methodNative1(int x);
public native static long methodNative2();
private native synchronized float methodNative3(Object o);
native void methodNative4(int[] ary) throws Exception;
}
为什么使用Native Method?
Java使用起来非常方便,然而有些层次的任务用Java实现起来不容易,或者我们对程序的效率很在意时,问题就来了。
与Java环境的交互
有时Java应用需要与Java外面的环境交互,这是本地方法存在的主要原因。你可以想想Java需要与一些底层系统,如操作系统或某些硬件交换信息时的情况。本地方法正是这样一种交流机制:它为我们提供了一个非常简洁的接口,而且我们无需去了解Java应用之外的繁琐的细节。
与操作系统的交互
JVM支持着Java语言本身和运行时库,它是Java程序赖以生存的平台,它由一个解释器(解释字节码)和一些连接到本地代码的库组成。然而不管怎样,它毕竟不是一个完整的系统,它经常依赖于一底层系统的支持。这些底层系统常常是强大的操作系统。通过使用本地方法,我们得以用Java实现了jre的与底层系统的交互,甚至JVM的一些部分就是用c写的。还有,如果我们要使用一些Java语言本身没有提供封装的操作系统的特性时,我们也需要使用本地方法。
Sun’s Java
Sun的解释器是用C实现的,这使得它能像一些普通的C一样与外部交互。jre大部分是用Java实现的,它也通过一些本地方法与外界交互。例如:类java.lang.Thread的setPriority()方法是用Java实现的,但是它实现调用的是该类里的本地方法setPriority()。这个本地方法是用C实现的,并被植入JVM内部,在Windows 95的平台上,这个本地方法最终将调用Win32 setPriority() ApI。这是一个本地方法的具体实现由JVM直接提供,更多的情况是本地方法由外部的动态链接库(external dynamic link library)提供,然后被JVw调用。
现状
目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间的通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍。
5.2. 本地方法栈
- Java虚拟机栈于管理Java方法的调用,而本地方法栈用于管理本地方法的调用。
- 本地方法栈,也是线程私有的。
- 允许被实现成固定或者是可动态扩展的内存大小。(在内存溢出方面是相同的)
- 如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java虚拟机将会抛出一个StackOverflowError 异常。
- 如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么Java虚拟机将会抛出一个OutOfMemoryError异常。
- 本地方法是使用C语言实现的。
- 它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。

- 当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。
- 本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区。
- 它甚至可以直接使用本地处理器中的寄存器
- 直接从本地内存的堆中分配任意数量的内存。
- 并不是所有的JVM都支持本地方法。因为Java虚拟机规范并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等。如果JVM产品不打算支持native方法,也可以无需实现本地方法栈。
- 在Hotspot JVM中,直接将本地方法栈和虚拟机栈合二为一。
6. 堆
6.1. 堆(Heap)的核心概述
堆针对一个JVM进程来说是唯一的,也就是一个进程只有一个JVM,但是进程包含多个线程,他们是共享同一堆空间的。

- 一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域。
- Java堆区在JVM启动的时候即被创建,其空间大小也就确定了。是JVM管理的最大一块内存空间。
- 堆内存的大小是可以调节的。
- 《Java虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。
- 所有的线程共享Java堆,在这里还可以划分线程私有的缓冲区(Thread Local Allocation Buffer,TLAB)。
- 《Java虚拟机规范》中对Java堆的描述是:所有的对象实例以及数组都应当在运行时分配在堆上。(The heap is the run-time data area from which memory for all class instances and arrays is allocated)
- 数组和对象可能永远不会存储在栈上,因为栈帧中保存引用,这个引用指向对象或者数组在堆中的位置。
- 在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除。
- 堆,是GC(Garbage Collection,垃圾收集器)执行垃圾回收的重点区域。

6.1.1. 堆内存细分
- Java 7及之前堆内存逻辑上分为三部分:新生区+养老区+永久区
- Young Generation Space 新生区 Young/New 又被划分为Eden区和Survivor区
- Tenure generation space 养老区 Old/Tenure
- Permanent Space 永久区 Perm


















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











