






昨天发了《大学老师称古风歌词“狗屁不通”,遭粉丝围攻:回家葬母吧》帖子之后,发现大家讨论得非常热烈。


而《盗将行》这首歌的曲作者和词作者,在昨晚都分别出面回应:
先是曲作者&演唱者花粥:


我觉得上面这段回应槽点真的很多啊.......

这个意思我没太懂,是花粥老师的大作意义非凡,然后其他很多歌都是跪舔?

不是说歌应该服务听众,而是作为一名歌手,不论是唱片公司的签约艺人,还是小众的独立歌手,既然选择公开发表作品,就必然要面对吃瓜群众的各种评价。你有创作自由,我也有评论自由啊,你觉得我的评论没说到点子上,可以跟我辩论。

好像大家都在说这首歌吧?怎么忽然扯到独立音乐的精神了?
顺便您给讲讲什么是独立音乐的精神?
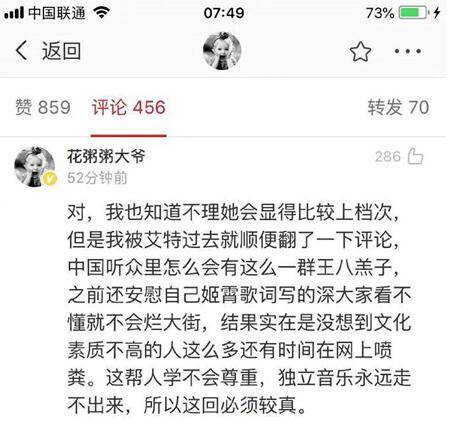

好嘛,“垃圾观众论”又来了......

“真心发自内心创作的音乐人”.......
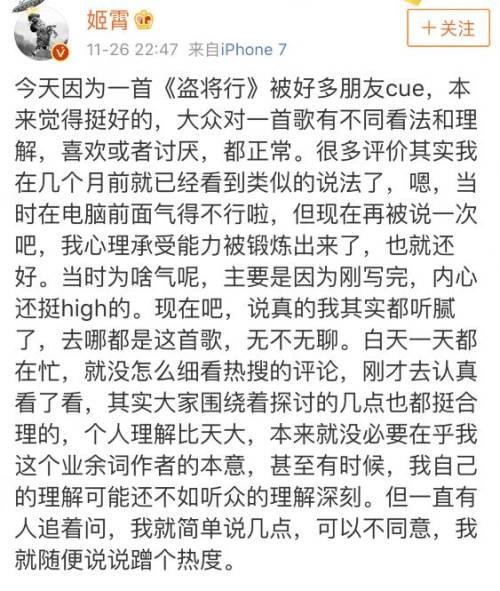
睡觉之前又刷到了词作者的回应,是真的在认认真真地讨论歌词,把包括“恶犬”还有几个有争议的梗都解释了一下:


而在凌晨,花粥又发了一条微博:
正文里没有提及,是因为我觉得此事根本不值得去发一条微博,让我心灰意冷的是如今的网络风气和那些自鸣得意的嘴脸,休息一段时间,希望回来的时候看见的是清醒的人们。

可能大家都需要清醒一下吧。
----------------------------------------------------------------------------------------------
btw 大家讨论的时候请就事论事,拒绝当“垃圾听众”,从你我做起。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









