







 携程广告纵横平台采用LSTM结合Embedding的深度学习算法进行广告库存预估,解决了样本少、多维度预估、库存变化等问题。通过LSTM的记忆能力和Embedding的特征表示,模型能捕捉节假日等影响因素,提高预估精度。通过数据归一化、聚类优化,确保模型的训练和泛化。模型训练结合离线和在线增量更新,保持模型的实时性。
携程广告纵横平台采用LSTM结合Embedding的深度学习算法进行广告库存预估,解决了样本少、多维度预估、库存变化等问题。通过LSTM的记忆能力和Embedding的特征表示,模型能捕捉节假日等影响因素,提高预估精度。通过数据归一化、聚类优化,确保模型的训练和泛化。模型训练结合离线和在线增量更新,保持模型的实时性。
作者简介
Paul,携程高级研发经理,关注广告投放技术架构、大数据、人工智能等领域;
Xunling,携程资深后端开发工程师,关注广告服务、性能优化,对AI技术有浓厚兴趣。
一、背景
近年来,随着互联网的发展,在线广告营销成为一种非常重要的商业模式。出于广告流量商业化售卖和日常业务投放精细化运营的目的,需要对广告流量进行更精准的预估,从而更精细的进行广告库存管理。
因此,携程广告纵横平台实践了LSTM(Long Short-Term Memory,长短时记忆网络)模型结合Embedding的广告库存预估深度学习算法,在节省训练资源的同时,构建更具泛化性的模型,支持根据不同地域分布、人口学属性标签等进行库存变动预估,并能体现出节假日特征对库存波动的影响,从而对广告库存进行更为精确的预估。
二、问题和挑战
广告库存预估实现有诸多挑战:
现实中对广告库存的影响因素非常多,比如节假日、周末、自然灾害等等;
广告库存样本周期以天为单位,训练样本很少;
需要支持不同维度交叉进行广告预估,例如同时选择地域、年龄、性别、会员等级等定向交叉,预估未来N天的库存情况;
广告库存日新月异,随时间推移,不断有新的库存样本生成,模型更新频率要求较高。
这些因素让广告库存预估工作从资源和效率等角度都带来压力。
三、算法简述
RNN(Recurrent Neural Network,循环神经网络)是一种特殊的神经网络,被广泛应用于序列数据的建模和预测,如自然语言处理、语音识别、时间序列预测等领域。RNN对时间序列的数据有着强大的提取能力,也被称作记忆能力。相对于传统的前馈神经网络,RNN具有循环连接,可以将前一时刻的输出作为当前时刻的输入,从而使得网络可以处理任意长度的序列数据,捕捉序列数据中的长期依赖关系。
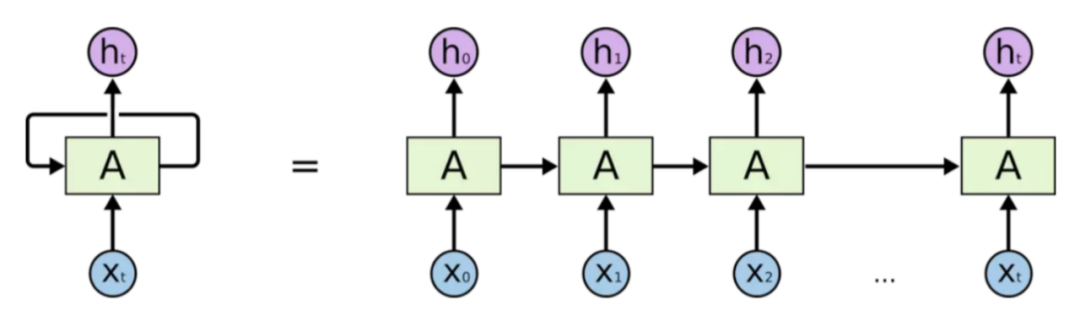
图 3-1
LSTM(Long Short-Term Memory,长短时记忆网络)是一种特殊的 RNN,它通过引入门控机制和记忆单元等结构来增强 RNN 的记忆能力和表达能力。
LSTM 的基本结构包括一个循环单元和三个门控单元:输入门、遗忘门和输出门。循环单元接受当前时刻的输入和前一时刻的输出作为输入,并输出当前时刻的输出和传递到下一时刻的状态。输入门控制当前时刻的输入对状态的影响,遗忘门控制前一时刻的状态对当前状态的影响,输出门控制当前状态对输出的影响。记忆单元则用于存储和传递长期的信息。基于此,使得LSTM具有长期的记忆能力,并且具有防止梯度消失的特点,故我们选择LSTM作为库存预估模型的训练基础。
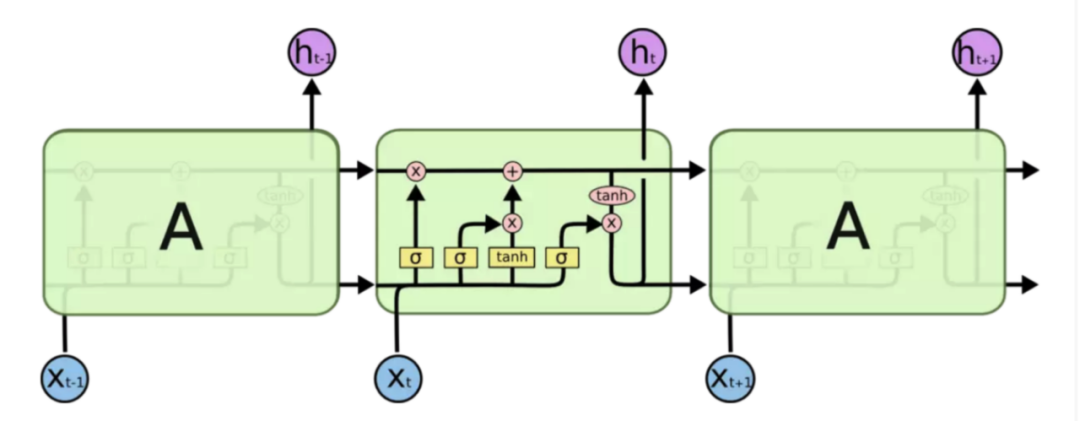
图 3-2
Embedding是一种特征处理方式,它可以将我们的某个特征数据向量化,可以将离散的整数序列映射为连续的实向量,它通常用于自然语言处理中的词嵌入(Word Embedding)任务,用于将每个单词映射为一个实向量,从而使得单词之间的语义关系可以在向量空间中进行计算。
在本文中,我们是使用它进行实体嵌入(Entity Embedding) 任务,也就是将我们的特征实体进行向量化,通过大量的数据训练,得到实体向量之前的细微关系,从而帮助模型更清晰的识别不同实体对广告库存的影响,进而提高模型的泛化能力。
四、数据处理
4.1 特征定义
基础特征为下图所示:
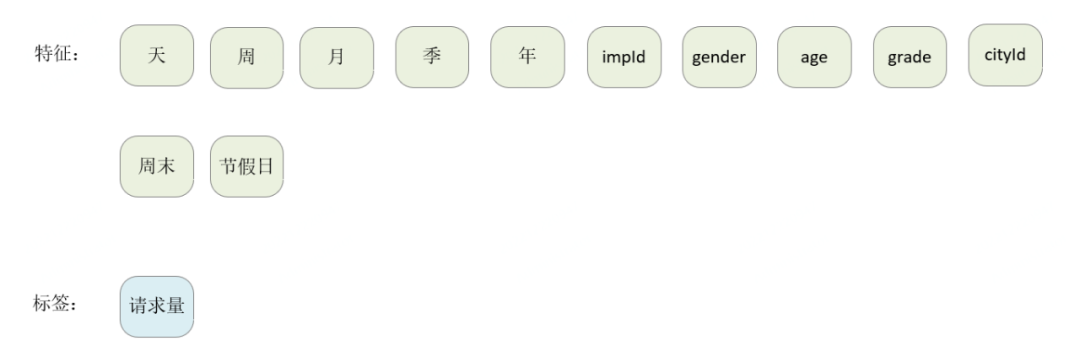
图 4-1
由于节假日的特殊性,我们又将其细分为以下维度,保证模型抓住节前和节后购票效应。

图 4-2
4.2 归一化
在深度学习中,对数据进行归一化主要目的是将数据缩放到一个合适的范围内,便于神经网络的训练和优化。对数据进行归一化可以改善梯度下降、加速收敛、提高模型的泛化能力。
我们选择Z-score标准化方法对数据进行处理,Z-score 标准化(也称为标准差标准化)是一种常见的数据归一化方法,其基本思想是将原始数据转换为标准正态分布,即均值为 0,标准差为 1。公式如下图所示,是一个实测值与平均数的差再除以标准差的过程。
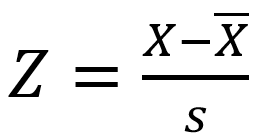
4.3 数据聚类
我们在第二章节问题和挑战中聊到过,广告库存预估需要对多个维度支持预估功能,不同维度交叉组合后,库存量千差万别,导致我们的样本数据中标签值min和max差距非常大。
如图4-3所示,本图Y轴表示某组合维度标签值的库存数据量级,库存数据量较小的组合维度占有很大一部分,而库存数据量较大的组合维度相对较少,仅凭数据归一化手段,数据压缩的效果非常不明显,如果强行一起训练会互相影响,导致模型难以拟合,训练中的损失函数如图4-4所示,训练时模型无法正常拟合,损失值不能够正常下降
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









