







 本文介绍了携程酒店推荐系统中如何通过 UnifiedPB 数据协议解决数据迭代问题,以及如何构建填充引擎,提升开发效率、降低成本、保证数据一致性。该填充引擎基于 serverless 理念,实现逻辑与资源隔离,通过配置驱动自动化数据填充,确保需求上线质量和效率,同时实现了全场景数据的统一管理,降低了资源浪费。
本文介绍了携程酒店推荐系统中如何通过 UnifiedPB 数据协议解决数据迭代问题,以及如何构建填充引擎,提升开发效率、降低成本、保证数据一致性。该填充引擎基于 serverless 理念,实现逻辑与资源隔离,通过配置驱动自动化数据填充,确保需求上线质量和效率,同时实现了全场景数据的统一管理,降低了资源浪费。
作者简介
yang,携程资深后端开发工程师,专注推荐系统架构、数据流批一体、系统稳定性、效率提升等领域;
kevin,携程高级研发经理,专注以技术驱动解决推荐系统中产品业务上的共性问题,创新生产模式,重构生产力;
莫秃,携程高级后端开发工程师,负责酒店机器学习平台的研发工作;
一、背景与思考
1.1 背景
携程酒店排序推荐广告工程(以下简称酒店推荐工程)在数据层面引入抽象化的统一数据协议UnifiedPB,解决了过去各场景各自维护,建立各自的数据流,网状开放式数据表,烟囱式迭代的问题,实现了全场景数据的标准化、规范化、统一化。
那么,UnifiedPB具体是什么呢?它是基于protobuf构建的统一工程、策略、数据三方的标准数据模型。从数据时效性上,我们抽象出三类:Online、NearLine、Offline;从数据类型归属上,我们抽象出四类:User、Item、User-Item、Common(公用字典)。
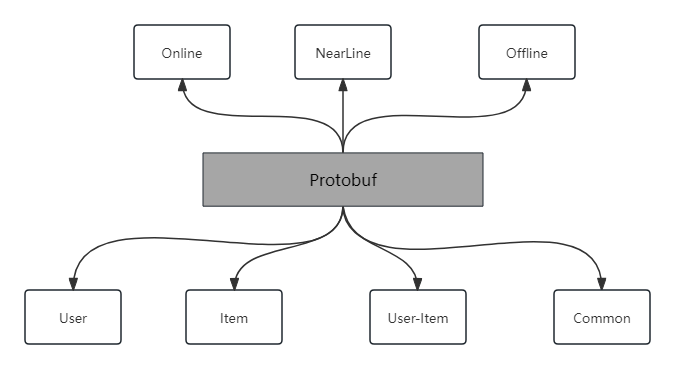
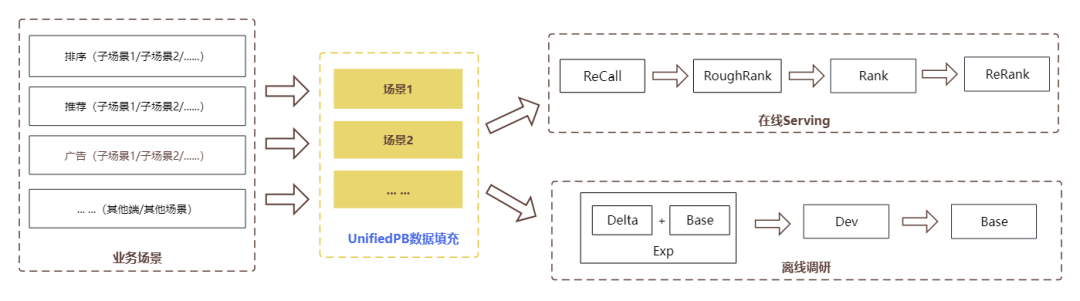
UnifiedPB数据作为酒店推荐工程最核心的底层数据基座,是整个推荐工程的数据入口,无论是在线Serving(召回→ 粗排 → 精排 → 重排),还是离线调研(特征调研 → 小流量 → 全流量),全链路多模块都强依赖UnifiedPB数据,因此UnifiedPB数据填充的上线质量和效率显得尤为重要,将直接影响到系统推荐质量和策略收益效果。
1.2 存在问题
基于上述现状背景,虽然我们引入UnifiedPB统一数据协议解决了网状开放式迭代问题,但是UnifiedPB数据填充在开发效率和成本等方面还存在如下一些问题亟需解决:
迭代效率低:case by case按需、人工hardCode开发、专人运维模式,交付周期长,效率低。例如60个特征从需求提出,到开发测试,最终上线预估需要8天。
复用效率低:三端、跨场景之间无法快速直接复用。一个版本特征在某个小流量场景实现显著后,期望能够在其他场景快速复用生效,需要重新进行重复开发工作,效率低。
逻辑耦合不透明:策略逻辑与数据工程强耦合,且不透明化,排查问题需要人工扒代码,排查效率低。
成本不可控
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









