






/***************************************/
目录:
第一部分:Teradata架构
第二部分:常见问题,及解决方法
第三部分:Teradata工具实用小技巧
第四部分:JOIN的实现机制
第五部分:JOIN的优化
/***************************************/
第一部分:Teradata架构
1.相关概念
SMP (Symmetrical Multi-Processing)对称多处理
MPP (Massively Parallel Processing)大规模并行处理系统
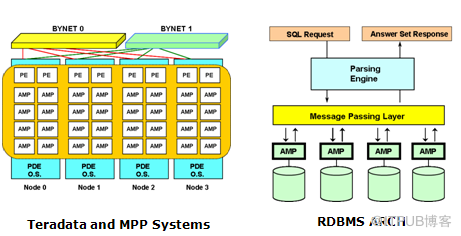
PE
MPL
AMP
VDISK
PI
UPI
NUPI
PPI
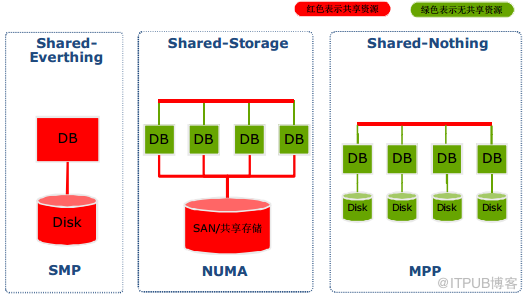
2.Teradata 体系架构
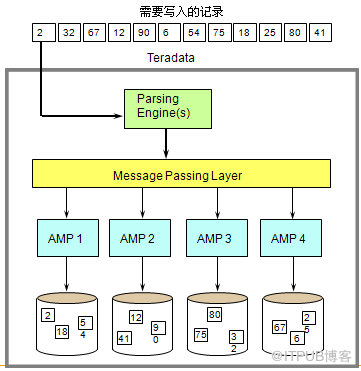
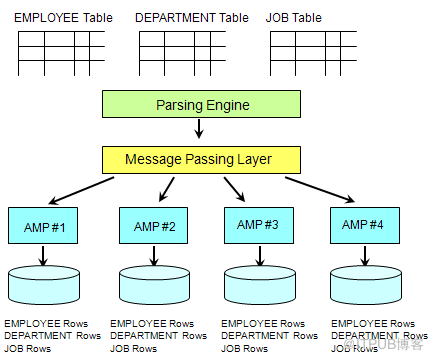
(1)数据存取架构图-数据存储
步骤:
Parsing Engine分发需要写入的记录.
Message Passing Layer确定应管理记录的AMP
AMP将记录写入磁盘一个AMP管理一个逻辑存储单元
virtual disk (它对应多个物理的存储单元)
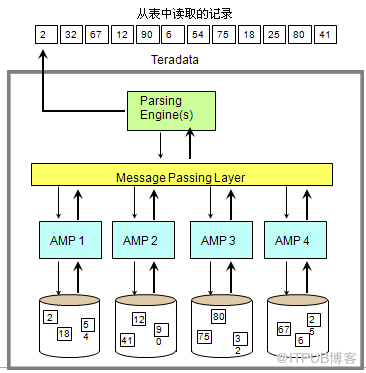
(2)Teradata数据存取架构图-数据读取
步骤:
Parsing Engine将数据读取请求发送到处理单元
Message Passing Layer确定要读取的记录属于哪个AMP管理
AMP(s)定位要读取的记录的存储位置并读取.
Message Passing Layer将结果记录反馈到PE
PE将结果记录反馈到请求端.
(3)均匀的数据分布
Notes:
每个表中的记录都会比较均匀地分布到各个AMP中.
每个AMP中的都会存储系统中几乎所有表的数据.
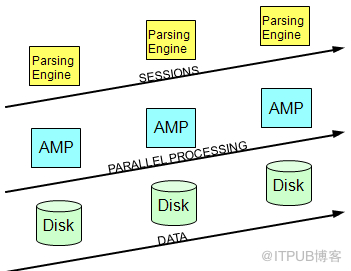
(4)完全线性扩展性
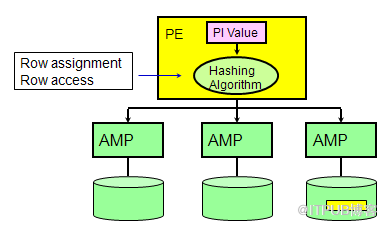
(5)Primary Index 主索引
利用PI访问数据的特点:
总是使用一个AMP
高效率的记录访问方式
(6)Primary Index 主索引数据访问
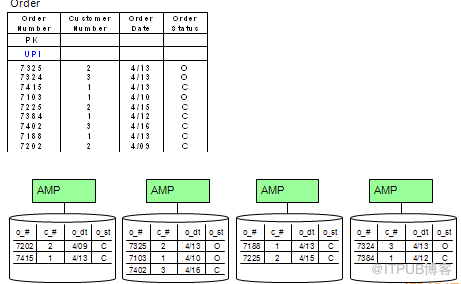
UPI 访问一个AMP,读取一条记录

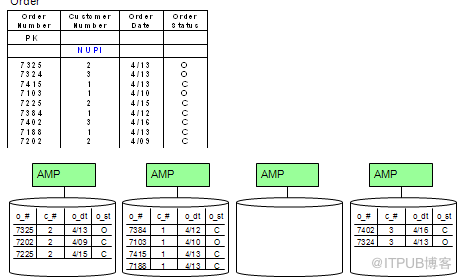
NUPI 访问一个AMP,读取多条记录
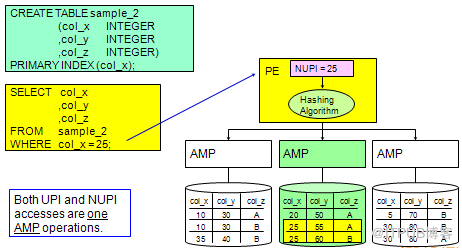
(7)数据分布 1(UPI)
数据分布 2(NUPI)
(8)PI的选取
重复值越少越好
个数越少越好
越经常使用越好
少更新
建表时要指定
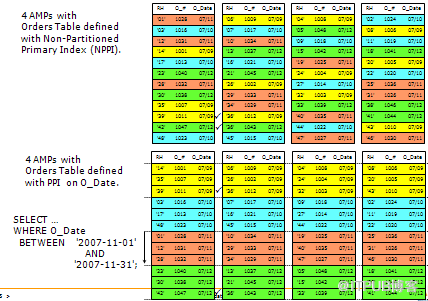
(9)PPI 例子
第二部分:常见问题,及解决方法
1.常见问题分类:
表属性不对: Set / Multiset
问题:INSERT操作慢
主索引(PI)设置不合理
问题1:数据倾斜度大,空间爆满。
问题2:JOIN操作,数据需要重分布。
分区索引(PPI)设置不合理
问题:全表扫描
连接条件过于复杂
问题:系统无法优化执行计划
缺乏统计信息
问题:系统无法找到最优化的执行计划
2.表属性:Set & MultiSet
Set Table不允许记录重复
MultiSet Table允许记录重复
默认值:Set Table
Create Table... AS ... 生成的目标表属性默认为Set Table
对SET Table进行INSERT操作,需要检查是否存在重复记录
相当的耗资源
若真要限定唯一性,可以通过UPI或USI实现
3.PI(Primary Index 主索引)的选择
PI影响数据的存储与访问,其选择标准:
不同值尽量多的字段(More Unique Values)
使用频繁的字段:包括值访问和连接访问
少更新
PI字段不宜太多
最好是手动指定PI
4.PPI的使用
PPI(Partition Primary Index,分区索引),把具有相同分区值的数据聚簇存放在一起;
类似于SQL Server的聚簇索引(Cluster Index),Oracle的聚簇表(Cluster Table)。
利用PPI,可以快速插入/访问同一个Partition(分区)的数据。
5.创建可变临时表
它仅存活于同一个Session之内
注意指定可变临时表为multiset(通常也要指定PI)
可变临时表不能带有PPI
6.固化临时表
固化临时表,就是把查询结果存放到一张物理表。
共下次分析或他人使用
Session断开之后,仍然可以使用。
7.数据类型
注意非日期字段与日期字段char & date的转换与关联:
如果数据类型一致可以直接使用;
在CASE WHEN or COALESCE一定要使用显式的类型转换(CAST)
CASE WHEN A = B THEN DATE1 ELSE ‘20061031’ END
应写成CASE WHEN A = B THEN DATE1 ELSE CAST(‘20061031’ AS DATE) END
数值运算时,确保运算过程中不丢失计算精度。
CAST(100/3 AS DEC(5,2))应该写成CAST(100/3.00 AS DEC(5,2))
8.字符(串)与数字相比较
比较规则:
1) 比较两个值(字段),它们的类型必须一样!
2) 当字符(串)与数字相比较时,先把字符(串)转换成数字,再进行比较。
9.目标列的选择
减少目标列,可以少消耗SPOOL空间,从而提高SQL的效率
当系统任务繁忙,系统内存少的时候,效果尤为明显。
10.Where条件的限定
根据Where条件先进行过滤数据集,再进行连接(JOIN)等操作
这样,可以减少参与连接操作的数据集大小,从而提高效率
好的查询引擎,可以自动优化;但有些复杂SQL,查询引擎优化得并不好。
注意:系统的SQL优化,只是避免最差的,选择相对优的,未必能够得到最好的优化结果。
11.用Case When替代UNION
两个子查询的表连接部分完全一样
两个子查询除了取数据条件,其它都一样。
Union all是多余的,它需要重复扫描数据,进行重复的JOIN
可以用Case when替代union
12.用OR替代UNION
两个子查询的表连接部分完全一样
两个子查询除了取数据条件,其它都一样。
Union all是多余的,它需要重复扫描数据,进行重复的JOIN
可以用OR替代union
此类的问题,在脚本中经常见到。
13.Union和Union all
Union与Union all的作用是将多个SQL的结果进行合并。
Union将自动剔除集合操作中的重复记录;需要耗更多资源。
Union all则保留重复记录,一般建议使用Union all。
第一个SELECT语句,决定输出的字段名称,标题,格式等
要求所有的SELECT语句:
1) 必须要有同样多的表达式数目;
2) 相关表达式的域必须兼容
14.先Group by再join
记录数情况:t: 580万,b: 9400万, c:8, d:8
主要问题:假如连接顺序为:( (b join c) join d) join t)
则是( (9400万 join 8) join 8) join 580万)
数据分布时间长(IO多),连接次数多
解决方法:先执行(t join b),然后groupby,再join c,d
结果:
(1) VTDUR_MON join VTNEW_SUBS_THISYEAR
PI相同,merge join,只需10秒
(2)经过group by,b表只有332记录
(3)b join c join d, 就是:
332 × 8 × 8
(4)最终结果:5记录,共40秒
先汇总再连接,可以减少参与连接的数据集大小,减少比较次数,从而提高效率。
以下面SQL为例,假设历史表( History )有1亿条记录
左边的SQL,需要进行 1亿 × 90次比较
右边的SQL,则只需要 1亿 × 1 次比较
15.SQL书写不当可能会引起笛卡儿积
以下面两个SQL为例,它们将进行笛卡儿积操作。
例子1:
Select
employee.emp_no
, employee.emp_name
From employee A
表Employee与表A进行笛卡儿积
例子2:
SELECT A.EMP_Name, B.Dept_Name
FROM employee A, Department B
Where a.dept_no = b.dept_no;
表A与表B进行笛卡儿积
表A与表B进行Inner Join
16.修改表定义
常见的表定义修改操作:
增加字段
修改字段长度
建议的操作流程
Rename table db.tablex as db.tabley;
通过Show table语句获得原表db.tablex的定义
定义新表: db.tablex
Insert into db.tablex(。。。)
select 。。。 From db.tabley;
Drop table db.tabley;
Teradata提供ALTER TABLE语句,可进行修改表定义
但,不建议采用ALTER TABLE方式。
17.插入/更新/删除记录时,尽量不要Abort
当目标表有数据时,插入和更新操作,以及部分删除,都产生TJ
如果此时abort该操作,系统将会回滚
对于大表进行Update/DELETE操作,将耗费相当多的资源与相当长的时间。
Update/Delete操作,需要事务日志TJ(Transient Journal)
以防意外中断导致数据受到破坏
在Update/Delete操作中途被Cancel,系统则需回滚,这将耗更多的资源与时间!
第三部分:Teradata工具实用小技巧
1.SQL变量
SELECT DATABASE; 显示当前数据库
PVIEW
SELECT USER; 显示当前Session登陆的用户名
lusc
SELECT DATE, CURRENT_DATE ; 显示当前日期
20070806 , 20070806
定义格式: SELECT CAST(DATE AS DATE FORMAT 'YYYYMMDD')
Select TIME, CURRENT_TIMESTAMP(0);显示当前时间
18:46:35, 2007-08-06 18:46:34+00:00
转换: SELECT CAST(CURRENT_TIMESTAMP(0) AS CHAR(19));
2007-08-06 18:47:59
2.日期(DATE)的操作
取当前天:
select cast( current_date as DATE FORMAT 'YYYYMMDD')
取当前天的前一天,后一天
select cast( current_date -1 as DATE FORMAT 'YYYYMMDD')
select cast( current_date + 1 as DATE FORMAT 'YYYYMMDD')
取前(后)一个月的同一天
Select add_months(current_date , -1)
Select add_months(current_date , 1)
若current_date为20070331,结果是什么?
取当前天所在月的第一天
select substr(cast(current_date as date format 'YYYYMMDD'),1,6) || '01';
取当前天所在月的最后一天
select cast( substr(cast( add_months(current_date,1) as date format 'YYYYMMDD'),1,6) || '01‘ as date format 'YYYYMMDD') -1
日期相减
SELECT ( DATE '2007-03-01' - DATE '2004-01-01') day(4);
SELECT (DATE'2007-03-01'- DATE'2004-01-01') month(4) ;
3.日历表:Sys_calendar.Calendar
用于进行复杂的日期计算
判断日期是否合法,例如20070229
SELECT * FROM Sys_calendar.Calendar
WHERE calendar_date = cast('2007-02-29' as date format ‘yyyy-mm-dd’);
返回空值,则说明该日期是非法的。
判断某日归属当月(当年)的第几周,当年的第几季度等
Select week_of_month, Week_of_year, quarter_of_year
From Sys_calendar.Calendar
WHERE calendar_date = cast('2006-10-15' as date format 'yyyy-mm-dd');
取当前月的天数
Select max(day_of_month)
From Sys_calendar.Calendar
WHERE cast( cast(calendar_date as date format 'yyyymmdd') as char(8)) like '200708%‘
或 where month_of_calendar in (
select month_of_calendar
From Sys_calendar.Calendar
where calendar_date = cast('2007-08-01' as date format 'yyyy-mm-dd')
)
第四部分:JOIN的实现机制
1.LEFT Outer Join 举例
SELECT E.Last_name
,E.Department_Number
,D.Department_Name
FROM Employee E LEFT OUTER JOIN
Department D
ON E.Department_Number = D.Department_Number
Last_Name Department_Number Department_Name
Crane 402 software support
James 111 ?
Runyon 501 marketing and sales
Stein 301 research and develop
Green ? ?
Trainer 100 executive
Kanieski 301 research and develop
内连接相比,这个查询的结果集会增加下面的一些记录:
部门号为空的员工。
部门号不在部门代码表里面的员工。
2.Join之前的重分布
Join 的列都是两个表的PI 不需要数据重分布.
SELECT . . .
FROM Table1 T1
INNER JOIN Table2 T2
ON T1.A = T2.A;
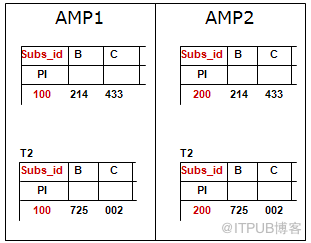
Join 的列都是在一个表上是PI,另外一个表上不是PI 是PI的表不需要重分布.
SELECT . . .
FROM Table1 T1
INNER JOIN Table2
ON T1.A = T2.A;

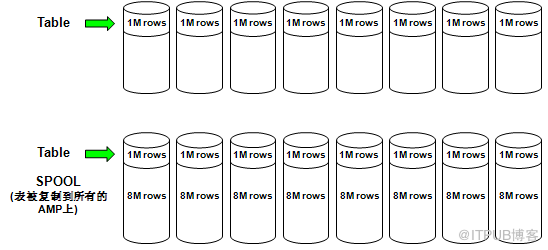
3.复制小表到Spool空间
4.关联策略 Merge Join
适用情况:
两个表的数据量都比较大时
例如 100万 × 30万
用来Join的记录必须位于相同的AMP上
Merge Join 仅仅读取每个表一次.
对于等值条件的Join,优化器经常会选用Merge Join.
通常情况下比product join的效率更高.
Merge join 处理流程:
找到一个小表.
如果需要:
将一个或者两个表要用到的数据都放在Spool空间里.
基于Join列的hash值将记录重分布到相应的AMP.
根据Join列的hash顺序对spool里面的记录进行排序.
对于Join列的Hash值相同的记录进行比较.
与Product Join相比,比较次数大大降低.
5.关联策略 Product Join
适用情况:
大表非PI字段对小表
例如 30万 × 50
不对记录做排序
如果内存里面放不下的时候需要多次读取某张表.
Table1 的每条记录要与 Table2 的每条记录进行比对.
满足条件的记录会被放到 spool空间中.
之所以会被称作Product Join 是因为:
总共的比较次数 = Table 1 的记录条数 * Table 2的记录条数
当内存里面不能存放某一个表的所有数据的时候,这种比较会变得非常的消耗资源,因为总是需要内外存的交换。
如果没有where条件,Product Join通常会产生无意义的结果.
Product Join 处理步骤:
找到小表并在Spool空间中复制到所有AMP上.
在每个AMP上,Spool空间里的小表的每一行和大表在该AMP上的每一行做Join
6.关联策略 Hash Join
适用情况:
大表非PI字段对中等小的表
例如 700万 × 1万
优化器技术有效的将小表放在Cache内存中,并且与未排序的大表进行关联.
Row Hash Join的处理流程:
找到小表.
重分布小表或者复制小表到各个AMP的内存中.
将小表在Cache内存中按照join字段的 row hash顺序排序.
将记录放在内存中.
用大表的join字段的row hash在内存中进行折半查找.
这种join将减少大表的排序、重分布或者拷贝.
EXPLAIN 将会看见类似于“Single Partition Hash Join”的术语.
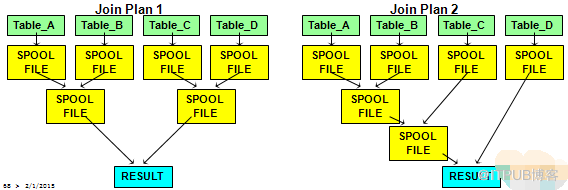
7.多表连接
多表连接可以分解为两两连接.
对下面的SQL,查询引擎可以选择较优的执行计划:例如,Plan1或者Plan2。
SELECT …. FROM Table_A, Table_B, Table_C, Table_D WHERE . . . ;
对下面的SQL,查询引擎只能选择Plan2,否则结果有可能不对。
SELECT ….
FROM Table_A left join Table_B on A.c1 = B.c2
INNER JOIN Table_C ON B.c2 = c.c3
LEFT JOIN Table_D ON D.C4 = A.C1
WHERE . . . ;
第五部分:JOIN的优化
1.改变查询计划的手段
修改PI
收集统计信息
关联字段上的统计信息
Partition上的统计信息
Where条件上的统计信息
Group by 字段上的统计信息
查看某个表的统计信息情况:help stat DBName.TableName
查看详尽的统计情况:select * from pview.vw_statistic_info
通过Explain查看,尚需统计哪些信息?
diagnostic helpstats on for session;
2.JOIN问题的经验分析
运行速度慢的SQL,绝大多数都是JOIN
例外1:INSERT操作慢,可能是因为目标表为set类型,或者PI不对
例外2:数据读取慢,可能用like操作,或者数据本身就很大
JOIN的问题,主要在于:
数据分布方式不对:把大表进行duplicate,或者redistribute
大表Redistribute有可能导致数据分布不均衡
JOIN算法不对:
例如,大表join小表,用merge join导致大表需要重新hash与sort
例如,大表join大表不用merge join
JOIN问题的解决办法:
对参与join的字段进行统计信息
必要的时候,固化临时表,并统计信息
一般情况下,不需要调整SQL的业务逻辑
目录:
第一部分:Teradata架构
第二部分:常见问题,及解决方法
第三部分:Teradata工具实用小技巧
第四部分:JOIN的实现机制
第五部分:JOIN的优化
/***************************************/
第一部分:Teradata架构
1.相关概念
SMP (Symmetrical Multi-Processing)对称多处理
MPP (Massively Parallel Processing)大规模并行处理系统
PE
MPL
AMP
VDISK
PI
UPI
NUPI
PPI

2.Teradata 体系架构

(1)数据存取架构图-数据存储
步骤:
Parsing Engine分发需要写入的记录.
Message Passing Layer确定应管理记录的AMP
AMP将记录写入磁盘一个AMP管理一个逻辑存储单元
virtual disk (它对应多个物理的存储单元)

(2)Teradata数据存取架构图-数据读取
步骤:
Parsing Engine将数据读取请求发送到处理单元
Message Passing Layer确定要读取的记录属于哪个AMP管理
AMP(s)定位要读取的记录的存储位置并读取.
Message Passing Layer将结果记录反馈到PE
PE将结果记录反馈到请求端.

(3)均匀的数据分布
Notes:
每个表中的记录都会比较均匀地分布到各个AMP中.
每个AMP中的都会存储系统中几乎所有表的数据.

(4)完全线性扩展性

(5)Primary Index 主索引
利用PI访问数据的特点:
总是使用一个AMP
高效率的记录访问方式

(6)Primary Index 主索引数据访问
UPI 访问一个AMP,读取一条记录

NUPI 访问一个AMP,读取多条记录

(7)数据分布 1(UPI)

数据分布 2(NUPI)

(8)PI的选取
重复值越少越好
个数越少越好
越经常使用越好
少更新
建表时要指定
(9)PPI 例子

第二部分:常见问题,及解决方法
1.常见问题分类:
表属性不对: Set / Multiset
问题:INSERT操作慢
主索引(PI)设置不合理
问题1:数据倾斜度大,空间爆满。
问题2:JOIN操作,数据需要重分布。
分区索引(PPI)设置不合理
问题:全表扫描
连接条件过于复杂
问题:系统无法优化执行计划
缺乏统计信息
问题:系统无法找到最优化的执行计划
2.表属性:Set & MultiSet
Set Table不允许记录重复
MultiSet Table允许记录重复
默认值:Set Table
Create Table... AS ... 生成的目标表属性默认为Set Table
对SET Table进行INSERT操作,需要检查是否存在重复记录
相当的耗资源
若真要限定唯一性,可以通过UPI或USI实现
3.PI(Primary Index 主索引)的选择
PI影响数据的存储与访问,其选择标准:
不同值尽量多的字段(More Unique Values)
使用频繁的字段:包括值访问和连接访问
少更新
PI字段不宜太多
最好是手动指定PI
4.PPI的使用
PPI(Partition Primary Index,分区索引),把具有相同分区值的数据聚簇存放在一起;
类似于SQL Server的聚簇索引(Cluster Index),Oracle的聚簇表(Cluster Table)。
利用PPI,可以快速插入/访问同一个Partition(分区)的数据。
5.创建可变临时表
它仅存活于同一个Session之内
注意指定可变临时表为multiset(通常也要指定PI)
可变临时表不能带有PPI
6.固化临时表
固化临时表,就是把查询结果存放到一张物理表。
共下次分析或他人使用
Session断开之后,仍然可以使用。
7.数据类型
注意非日期字段与日期字段char & date的转换与关联:
如果数据类型一致可以直接使用;
在CASE WHEN or COALESCE一定要使用显式的类型转换(CAST)
CASE WHEN A = B THEN DATE1 ELSE ‘20061031’ END
应写成CASE WHEN A = B THEN DATE1 ELSE CAST(‘20061031’ AS DATE) END
数值运算时,确保运算过程中不丢失计算精度。
CAST(100/3 AS DEC(5,2))应该写成CAST(100/3.00 AS DEC(5,2))
8.字符(串)与数字相比较
比较规则:
1) 比较两个值(字段),它们的类型必须一样!
2) 当字符(串)与数字相比较时,先把字符(串)转换成数字,再进行比较。
9.目标列的选择
减少目标列,可以少消耗SPOOL空间,从而提高SQL的效率
当系统任务繁忙,系统内存少的时候,效果尤为明显。
10.Where条件的限定
根据Where条件先进行过滤数据集,再进行连接(JOIN)等操作
这样,可以减少参与连接操作的数据集大小,从而提高效率
好的查询引擎,可以自动优化;但有些复杂SQL,查询引擎优化得并不好。
注意:系统的SQL优化,只是避免最差的,选择相对优的,未必能够得到最好的优化结果。
11.用Case When替代UNION
两个子查询的表连接部分完全一样
两个子查询除了取数据条件,其它都一样。
Union all是多余的,它需要重复扫描数据,进行重复的JOIN
可以用Case when替代union
12.用OR替代UNION
两个子查询的表连接部分完全一样
两个子查询除了取数据条件,其它都一样。
Union all是多余的,它需要重复扫描数据,进行重复的JOIN
可以用OR替代union
此类的问题,在脚本中经常见到。
13.Union和Union all
Union与Union all的作用是将多个SQL的结果进行合并。
Union将自动剔除集合操作中的重复记录;需要耗更多资源。
Union all则保留重复记录,一般建议使用Union all。
第一个SELECT语句,决定输出的字段名称,标题,格式等
要求所有的SELECT语句:
1) 必须要有同样多的表达式数目;
2) 相关表达式的域必须兼容
14.先Group by再join
记录数情况:t: 580万,b: 9400万, c:8, d:8
主要问题:假如连接顺序为:( (b join c) join d) join t)
则是( (9400万 join 8) join 8) join 580万)
数据分布时间长(IO多),连接次数多
解决方法:先执行(t join b),然后groupby,再join c,d
结果:
(1) VTDUR_MON join VTNEW_SUBS_THISYEAR
PI相同,merge join,只需10秒
(2)经过group by,b表只有332记录
(3)b join c join d, 就是:
332 × 8 × 8
(4)最终结果:5记录,共40秒
先汇总再连接,可以减少参与连接的数据集大小,减少比较次数,从而提高效率。
以下面SQL为例,假设历史表( History )有1亿条记录
左边的SQL,需要进行 1亿 × 90次比较
右边的SQL,则只需要 1亿 × 1 次比较
15.SQL书写不当可能会引起笛卡儿积
以下面两个SQL为例,它们将进行笛卡儿积操作。
例子1:
Select
employee.emp_no
, employee.emp_name
From employee A
表Employee与表A进行笛卡儿积
例子2:
SELECT A.EMP_Name, B.Dept_Name
FROM employee A, Department B
Where a.dept_no = b.dept_no;
表A与表B进行笛卡儿积
表A与表B进行Inner Join
16.修改表定义
常见的表定义修改操作:
增加字段
修改字段长度
建议的操作流程
Rename table db.tablex as db.tabley;
通过Show table语句获得原表db.tablex的定义
定义新表: db.tablex
Insert into db.tablex(。。。)
select 。。。 From db.tabley;
Drop table db.tabley;
Teradata提供ALTER TABLE语句,可进行修改表定义
但,不建议采用ALTER TABLE方式。
17.插入/更新/删除记录时,尽量不要Abort
当目标表有数据时,插入和更新操作,以及部分删除,都产生TJ
如果此时abort该操作,系统将会回滚
对于大表进行Update/DELETE操作,将耗费相当多的资源与相当长的时间。
Update/Delete操作,需要事务日志TJ(Transient Journal)
以防意外中断导致数据受到破坏
在Update/Delete操作中途被Cancel,系统则需回滚,这将耗更多的资源与时间!
第三部分:Teradata工具实用小技巧
1.SQL变量
SELECT DATABASE; 显示当前数据库
PVIEW
SELECT USER; 显示当前Session登陆的用户名
lusc
SELECT DATE, CURRENT_DATE ; 显示当前日期
20070806 , 20070806
定义格式: SELECT CAST(DATE AS DATE FORMAT 'YYYYMMDD')
Select TIME, CURRENT_TIMESTAMP(0);显示当前时间
18:46:35, 2007-08-06 18:46:34+00:00
转换: SELECT CAST(CURRENT_TIMESTAMP(0) AS CHAR(19));
2007-08-06 18:47:59
2.日期(DATE)的操作
取当前天:
select cast( current_date as DATE FORMAT 'YYYYMMDD')
取当前天的前一天,后一天
select cast( current_date -1 as DATE FORMAT 'YYYYMMDD')
select cast( current_date + 1 as DATE FORMAT 'YYYYMMDD')
取前(后)一个月的同一天
Select add_months(current_date , -1)
Select add_months(current_date , 1)
若current_date为20070331,结果是什么?
取当前天所在月的第一天
select substr(cast(current_date as date format 'YYYYMMDD'),1,6) || '01';
取当前天所在月的最后一天
select cast( substr(cast( add_months(current_date,1) as date format 'YYYYMMDD'),1,6) || '01‘ as date format 'YYYYMMDD') -1
日期相减
SELECT ( DATE '2007-03-01' - DATE '2004-01-01') day(4);
SELECT (DATE'2007-03-01'- DATE'2004-01-01') month(4) ;
3.日历表:Sys_calendar.Calendar
用于进行复杂的日期计算
判断日期是否合法,例如20070229
SELECT * FROM Sys_calendar.Calendar
WHERE calendar_date = cast('2007-02-29' as date format ‘yyyy-mm-dd’);
返回空值,则说明该日期是非法的。
判断某日归属当月(当年)的第几周,当年的第几季度等
Select week_of_month, Week_of_year, quarter_of_year
From Sys_calendar.Calendar
WHERE calendar_date = cast('2006-10-15' as date format 'yyyy-mm-dd');
取当前月的天数
Select max(day_of_month)
From Sys_calendar.Calendar
WHERE cast( cast(calendar_date as date format 'yyyymmdd') as char(8)) like '200708%‘
或 where month_of_calendar in (
select month_of_calendar
From Sys_calendar.Calendar
where calendar_date = cast('2007-08-01' as date format 'yyyy-mm-dd')
)
第四部分:JOIN的实现机制
1.LEFT Outer Join 举例
SELECT E.Last_name
,E.Department_Number
,D.Department_Name
FROM Employee E LEFT OUTER JOIN
Department D
ON E.Department_Number = D.Department_Number
Last_Name Department_Number Department_Name
Crane 402 software support
James 111 ?
Runyon 501 marketing and sales
Stein 301 research and develop
Green ? ?
Trainer 100 executive
Kanieski 301 research and develop
内连接相比,这个查询的结果集会增加下面的一些记录:
部门号为空的员工。
部门号不在部门代码表里面的员工。
2.Join之前的重分布
Join 的列都是两个表的PI 不需要数据重分布.
SELECT . . .
FROM Table1 T1
INNER JOIN Table2 T2
ON T1.A = T2.A;

Join 的列都是在一个表上是PI,另外一个表上不是PI 是PI的表不需要重分布.
SELECT . . .
FROM Table1 T1
INNER JOIN Table2
ON T1.A = T2.A;

3.复制小表到Spool空间

4.关联策略 Merge Join
适用情况:
两个表的数据量都比较大时
例如 100万 × 30万
用来Join的记录必须位于相同的AMP上
Merge Join 仅仅读取每个表一次.
对于等值条件的Join,优化器经常会选用Merge Join.
通常情况下比product join的效率更高.
Merge join 处理流程:
找到一个小表.
如果需要:
将一个或者两个表要用到的数据都放在Spool空间里.
基于Join列的hash值将记录重分布到相应的AMP.
根据Join列的hash顺序对spool里面的记录进行排序.
对于Join列的Hash值相同的记录进行比较.
与Product Join相比,比较次数大大降低.
5.关联策略 Product Join
适用情况:
大表非PI字段对小表
例如 30万 × 50
不对记录做排序
如果内存里面放不下的时候需要多次读取某张表.
Table1 的每条记录要与 Table2 的每条记录进行比对.
满足条件的记录会被放到 spool空间中.
之所以会被称作Product Join 是因为:
总共的比较次数 = Table 1 的记录条数 * Table 2的记录条数
当内存里面不能存放某一个表的所有数据的时候,这种比较会变得非常的消耗资源,因为总是需要内外存的交换。
如果没有where条件,Product Join通常会产生无意义的结果.
Product Join 处理步骤:
找到小表并在Spool空间中复制到所有AMP上.
在每个AMP上,Spool空间里的小表的每一行和大表在该AMP上的每一行做Join
6.关联策略 Hash Join
适用情况:
大表非PI字段对中等小的表
例如 700万 × 1万
优化器技术有效的将小表放在Cache内存中,并且与未排序的大表进行关联.
Row Hash Join的处理流程:
找到小表.
重分布小表或者复制小表到各个AMP的内存中.
将小表在Cache内存中按照join字段的 row hash顺序排序.
将记录放在内存中.
用大表的join字段的row hash在内存中进行折半查找.
这种join将减少大表的排序、重分布或者拷贝.
EXPLAIN 将会看见类似于“Single Partition Hash Join”的术语.
7.多表连接
多表连接可以分解为两两连接.
对下面的SQL,查询引擎可以选择较优的执行计划:例如,Plan1或者Plan2。
SELECT …. FROM Table_A, Table_B, Table_C, Table_D WHERE . . . ;
对下面的SQL,查询引擎只能选择Plan2,否则结果有可能不对。
SELECT ….
FROM Table_A left join Table_B on A.c1 = B.c2
INNER JOIN Table_C ON B.c2 = c.c3
LEFT JOIN Table_D ON D.C4 = A.C1
WHERE . . . ;

第五部分:JOIN的优化
1.改变查询计划的手段
修改PI
收集统计信息
关联字段上的统计信息
Partition上的统计信息
Where条件上的统计信息
Group by 字段上的统计信息
查看某个表的统计信息情况:help stat DBName.TableName
查看详尽的统计情况:select * from pview.vw_statistic_info
通过Explain查看,尚需统计哪些信息?
diagnostic helpstats on for session;
2.JOIN问题的经验分析
运行速度慢的SQL,绝大多数都是JOIN
例外1:INSERT操作慢,可能是因为目标表为set类型,或者PI不对
例外2:数据读取慢,可能用like操作,或者数据本身就很大
JOIN的问题,主要在于:
数据分布方式不对:把大表进行duplicate,或者redistribute
大表Redistribute有可能导致数据分布不均衡
JOIN算法不对:
例如,大表join小表,用merge join导致大表需要重新hash与sort
例如,大表join大表不用merge join
JOIN问题的解决办法:
对参与join的字段进行统计信息
必要的时候,固化临时表,并统计信息
一般情况下,不需要调整SQL的业务逻辑
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/30088512/viewspace-1423022/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/30088512/viewspace-1423022/














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









