







-
在本章节中,我们学习新的字符串拼接方式:标签模板字符串,动态效果与自由使用程度得到进一步提升
-
函数的默认参数更好的解决方案,以及结合解构的进阶使用方式
-
剩余参数的进一步说明,箭头函数的补充,以及展开语法对数据的处理细节是怎么样的,深拷贝还是浅拷贝,都会得到说明
一、字符串模板基本使用
-
在ES6之前,如果我们想要将字符串和一些动态的变量(标识符)拼接到一起,是非常麻烦和丑陋的(ugly)
-
ES6允许我们使用字符串模板来嵌入JS的变量或者表达式来进行拼接:
-
从使用的角度来说是差不多的,最明显的区别在于拼接上,ES6的模板字符串不再采用
加号进行拼接,而是使用${}进行插值,其中的整体割裂感得以削减
-
const name = "小余"
const age = 20
//ES6之前的拼接
const info = "今天来的人是" + name + "他今年" + age + "岁了"
console.log(info)
//ES6之后的拼接(模板字符串)
const info = `今天来的人是${name}他今年${age}岁了`
console.log(info)
-
但拼接方式的改变只是模板字符串的其中一个功能,最主要的在于
${}使用角度是非常自由的-
在
${}内部可以编写表达式也可以进行函数调用,因此非常考验使用者的想象力和基础功底以及实际需求 -
比如在构建动态生成的内容,如动态SQL语句或HTML时,传统的字符串拼接可能容易引入注入攻击的风险。模板字符串可以与库结合使用,如标签模板,以确保字符串是安全处理的,例如自动转义
-
const name = "小余"
const age = 20
//表达式
console.log(`${name}今年${age*2}`);//小余今年40
//函数调用
const foo = function(name){
//例如可以调用对应的翻译API,将中文名转为英文名,实现一定的功能
return name
}
console.log(`${foo(name)}今年${age}`);//小余今年20
-
因此我们可以进行基础的一个对比总结
表21-1 普通字符串与模板字符串对比总结
| 特性 | 普通字符串 | 模板字符串 |
|---|---|---|
| 定义方式 | 使用单引号或双引号 | 使用反引号(`) |
| 插值表达式 | 不支持直接插入变量或表达式 | 支持插入变量或表达式,使用 ${expression} |
| 多行文本 | 需要使用 \n 显示换行 | 直接书写换行,不需额外字符 |
| 嵌套引用 | 需要转义同类型引号 | 可以嵌套不同类型引号无需转义 |
| 复杂表达式 | 不支持 | 支持执行复杂表达式 |
| 性能 | 略优,对于简单的字符串操作更高效 | 略逊,处理插值和表达式需要计算 |
-
在JS引擎的执行流程中,当解析到模板字符串时:
-
会先分析整个模板字符串,确定
文本部分和插值表达式 -
接着计算插值表达式的值
-
然后将表达式的值转换为字符串(如果不是字符串的话)
-
最后将文本部分和表达式的值按顺序拼接成最终的字符串
-
-
步骤相对复杂,所以从性能角度上,普通字符串会更占优势,但模板字符串的功能更加强大。相对于强大的功能,性能上的微小差距可以进行一定程度的忽略
-
要注意的是使用字符串插值的所有插入的值都会使用
toString()强制转型为字符串,也就是步骤3,因此最终预期的结果一定是字符串且不需要我们手动转换类型
1.1 标签模板字符串
标签模板字符串不是直接由反引号(```)定义的字符串,而是将模板字符串通过一个函数(称为标签函数)进行处理的结果。这个函数接收模板字符串中的各个部分作为参数,包括字符串数组和插值表达的表达式值,并可以返回处理后的任何结果
-
相对于模板字符串来说,名字前缀多了一个
标签,这个标签代指标签函数,是模板字符串结合函数的一种调用方式
function foo(name){
return console.log(name);
}
foo('小余')//小余
//另外调用函数的方法:标签模板字符串
foo`coderwhy`//[ 'coderwhy' ]
-
通过模板字符串所返回的结果是一个数组,这就需要说到JS引擎是如何解析
标签函数调用的-
正如前面所说的JS引擎解析模板字符串的四个流程中,首先会先确定
文本部分和插值表达式两个部分 -
而标签函数调用中的模板字符串作为形参,也是分为两个部分(参数1与参数2)
-
-
参数1是一个数组(内含文本部分),参数2的数量则不固定(取决于插值数量)
-
其中参数1之所以会是一个数组,则是由于插值语法
${}在模板字符串中起切割作用 -
参数2和
剩余参数...形式类似,包括了插值语法${}的所有部分内容(按前后顺序获取),使用剩余参数来获取的兼容度会更高,毕竟很难知道具体会分割多少次1
-
function foo(name,...args){
console.log(name,...args);
}
function foo2(name,...args){
console.log(name,args);
}
//内容切割,文本部分在前,插值内容在后
foo`coder${1}why${2}`//[ 'coder', 'why', '' ] 1 2
foo2`coder${1}why${2}`//[ 'coder', 'why', '' ] [ 1, 2 ]
-
且根据JS引擎的解析规则,在进行输出插值语法之前,会先计算插值表达式
foo`coder${1}why${2+3}`//[ 'coder', 'why', '' ] 1 5
-
实际情况下,我们很少这样调用函数,但并不意味这样做没有意义,像React的
CSS in JS就是使用标签模板字符串来操作的-
可以看到CSS属性可以通过
${}插值语法来进行设置 -
这是利用
styled-components第三方库进行实现的,而该第三方库则利用标签模板字符串,通过以下三步骤达成对应目的
-
解析模板字符串:
styled.div接收到的模板字符串被分解成静态字符串部分和动态表达式部分(如果有的话) -
生成样式规则:
styled-components使用这些解析后的字符串和表达式生成完整的 CSS 规则 -
创建 React 组件:这些样式被附加到一个新创建的 React 组件上。此组件在渲染时将自动应用这些样式
-
//CSS in JS代码
import { styled } from "styled-components";
export const ItemWrapper = styled.div`
flex-shrink: 0;//阻止图片被压缩
border-radius: 5px;
width: ${props => props.itemwidth};
padding: 8px;
box-sizing: border-box;
${props => props.theme.mixin.Levitation}
`
二、函数默认参数
-
在开发中,如果函数形参数量和实参数量不一致,会发生什么事情?
-
当形参数量>实参数量时,没有得到实参的形参是默认值undefined,准确的说,在JS当中,没有得到确定赋值的变量,其默认值都是undefined
-
function foo(name,age){
console.log(name,age);//如果我们name跟age没有传值,会默认是undefined,但这个undefined是比较危险的,因为undefined调用的时候会报错
}
foo()//未传值,undefined undefined
-
而错误使用undefined会引发一系列的问题,因此在函数中,我们可以给上对应的默认值
-
在ES5中,我们通常是在函数内的最上层先进行一个判断,有值传递使用该值,无值则使用默认值
-
在ES6中,可以对
形参赋予默认值写法
-
//ES5写法
function foo1(m,n) {
//形参判断
n = n || 'coderwhy'
console.log(m,n);
}
foo1('小余')//小余 coderwhy
//ES6写法
function foo2(m,n='coderwhy') {
console.log(m,n);
}
foo2('小余')//小余 coderwhy
-
ES6之前的写法是有缺陷的:
-
首先写起来比较麻烦,并且代码的阅读性较差。比较致命的是,该写法是有bug漏洞的
-
那就是
逻辑或||的判定规则是怎么样的,在MDN有这样的一行提醒
-

图21-1 MDN文档对假值的说明
-
在这里需要注意,假值是不会被使用的,假如我们传递进去一个0或者空的字符串,我希望这两个内容能够正确的去使用,但使用
逻辑或就无法正确筛选该内容-
一般来说,只有null和undefined会被视为无意义,所以在ES11后,
空值合并运算符??因此产生,和逻辑或的使用方法相似,不同之处在于判断范围只限于null、undefined两种,在React中,常用来判断组件是否挂载使用
-
function foo1(m,n) {
m = m || '小余'
n = n || 'coderwhy'
console.log(m,n);
}
foo1(0,'')//小余 coderwhy
-
什么是假值?在 JavaScript 中,假值(falsy value)指的是在布尔上下文中被自动转换为
false的值。这些值在条件语句或逻辑操作中不表示真实的布尔false,但当它们需要转换为布尔类型来进行判断时,它们的表现等同于false
表21-2 假值的类型与说明
| 假值类型 | 值 | 描述 |
|---|---|---|
| 布尔值 | false | 布尔类型的假值 |
| 空字符串 | "" | 空字符串也被视为假值 |
| 数字 0 | 0 | 数字零被视为假值 |
| 数字 -0 | -0 | 负零也被视为假值 |
null | null | 表示无值 |
undefined | undefined | 变量未定义也被视为假值 |
NaN | NaN | 表示非数字值的特殊数值,也是假值 |
-
因此使用
逻辑或来设置默认值有较为明显的界限判断问题,所以使用默认值的时候,最好采用默认参数写法-
根据Babel的代码转化,能够看出在使用默认值参数写法,会进行更深层的处理校验判断
-
arguments.length > 1检查是否传入了超过一个参数。在这个上下文中,这意味着至少有两个参数被传递给了函数,因为如果只有一个参数则结果为false(假值),将无法继续触发往后的逻辑与&& -
arguments[1] !== undefined确保第二个参数不是undefined。这是为了确保如果提供了第二个参数,即使它的值是null或者是一个假值(比如0或""),都应当使用这个值,而不是默认值 -
? arguments[1] : "coderwhy"中,如果前面的条件(即传入超过一个参数且第二个参数不是undefined)为真,则使用传入的第二个参数arguments[1];如果为假,则使用默认值"coderwhy"
-
//原代码
function foo2(m,n='coderwhy') {
console.log(m,n);
}
foo2('小余')//小余 coderwhy
//babel转化
function foo2(m) {
var n =
arguments.length > 1 && arguments[1] !== undefined
? arguments[1]
: "coderwhy";
console.log(m, n);
}
foo2("小余"); //小余 coderwhy
-
可以看到,函数默认参数写法能够简化非常多的写法,在该基础上,可以继续结合解构等方式,形成更加高效的写法,这种方式在React中将会非常常见
//解构的回顾
const obj = {name:"小余",age:20}
const {age} = obj
console.log(age);//20
//函数的默认值是一个对象,但是用户没有传递一个对象进行,怎么做?
function foo(obj = { name:"小余", age:20}){//通过默认参数的方式传进去一个对象{},还能进行设置默认值
console.log(obj);
//麻烦的写法,还需要从obj中进行一次引用,如果数量多了,就会非常重复
console.log(obj.name,obj.age);
}
foo()
//优化写法
const person = {
name:"coderwhy",
age:35
}
//解构结合默认参数写法
function foo({name,age} = person) {
console.log(name,age);
}
foo()//coderwhy 35
//进阶用法:person2没有对应内容可以解构的话
const person2 = {}
function foo2({name='小余',age='18'} = person2) {
console.log(name,age);
}
foo2()//小余 18
-
在这里需要注意,有默认值的形参最好放在后面,因为需要用到默认值的往往是不一定会用到的,换句话说,该形参不是必填或者必须的
-
在正常决定形参顺序时,必填放前面,选填放后面,以防预料之外的结果产生
-
且默认值只有在形参没有接受到值才会触发,在实参位置如果不传入第一项内容,是无法继续传递第二项内容的
-
所以哪怕参数1有默认值,实参中只传参数2,也会报语法错误
-
这是因为 JS 函数的参数传递设计遵循从左至右的顺序填充,这是基于多数编程语言中的常规函数调用和声明方式
-
且如果允许在没有填充前一个参数的情况下填充后一个参数,将引入调用时的歧义,这会使函数的调用方式和预期的行为之间出现不一致,在设计中必须考虑到所有情况,包括用户可能的非标准用法,从左到右的顺序减少了这种复杂性和潜在的错误
-
正如我们所想,必填在前,选填在后。在缺少必填的内容时,如同空中阁楼,选填部分也就失去意义,函数的诞生早于默认参数,因此默认参数所不需要的操作,未必是以前不需要的,兼容是一种权衡
-
从Babel转化的源码中,也可以看出默认参数是通过arguments进行判断的,因此能够得出相同结论
-
-
同时需要默认参数会导致默认值会改变函数的length个数,默认值及后面的参数都不计算在length之内
-
因为length长度在大部分情况下实际所指的含义是:提供关于
“最小必需参数数量”的直观信息 -
包括在Babel转化源码中,从具备默认值的位置开始,后续的所有参数都会离开形参位置,在函数体中进行额外处理
-
function foo(m='小余',n){
console.log(m,n);
}
//无法正常运行,会报SyntaxError(语法错误)
foo(,'coderwhy')
//长度会受默认参数影响
console.log(foo.length);//0
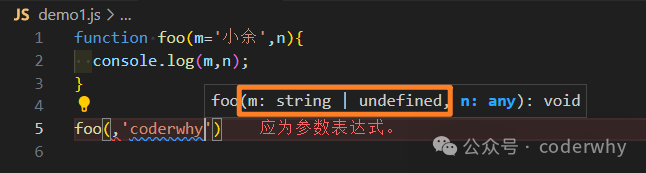
图21-2 参数填写遵守前后顺序
function foo2(m,n='coderwhy',x) {
console.log(m,n);
}
foo2('小余')//小余 coderwhy
//Babel转化 x不具备默认值,但位于默认值之后,也会默认与默认值为一体
function foo2(m) {
var n =
arguments.length > 1 && arguments[1] !== undefined
? arguments[1]
: "coderwhy";
//从具备默认值的位置开始,后续的所有参数都会离开形参位置,在函数体中进行额外处理,x形参就是一种体现,也是length获取不到默认值以及之后的长度原因
var x = arguments.length > 2 ? arguments[2] : undefined;
console.log(m, n);
}
foo2("小余"); //小余 coderwhy
2.1 剩余参数
在JavaScript中,剩余参数语法允许我们将一个不定数量的参数表示为一个数组。这对于处理传递给函数的参数列表非常有用,特别是当我们不知道将会接收多少参数时。剩余参数语法也是在ECMAScript 6(ES6)中被正式引入
-
剩余参数语法使用三个点(
...)作为前缀,后跟一个数组名称,这个数组将包含所有未显式匹配的传入参数
function func(...rest) {
// rest 是一个数组,包含所有未被其他参数捕获的传入参数
}
-
在理解了默认参数的实现方式后,我们可以结合剩余参数,从而实现针对性获取属性和广泛式获取属性相结合的做法
-
针对性获取name、age属性
-
广泛式获取args属性组,从args剩余参数数组中,我们可以获取到我们所不确定有的"选填"部分
-
//自己进一步优化
//但是上面这种方式,能调用的内容就仅限于我们解构出来的内容,不能够obj.xxx的进行调用其他没有解构出来的部分。这个时候就可以使用剩余参数将剩下的没有进行解构的部分给传递进去
function foo({name = "小余",age = 20,...args} = {}){
console.log(name,age);//coderwhy 24
console.log(args.sex);//男,这样就可以解决不知道用户传递什么内容进来,无法使用obj.xxx进行输入的问题了
}
const obj = {name:"coderwhy",age:24,sex:"男"}
foo(obj)
-
包括说剩余参数和解构的结合,在之前有实现的筛选方式
-
除去针对性获取的属性,其余属性都会归属到广泛式部分中,从而通过该特性实现另类的过滤筛选
-
const person = {
name:'小余',
age:18,
address:'福建'
}
const {address,...person2} = person
console.log(person2);//{ name: '小余', age: 18 }
-
那么剩余参数和arguments有什么区别呢?
-
剩余参数只包含那些没有对应形参的实参,而 arguments 对象包含了传给函数的所有实参
-
arguments对象不是一个真正的数组,而rest参数是一个真正的数组,可以进行数组的所有操作
-
arguments是早期的ECMAScript中为了方便去获取所有的参数提供的一个数据结构,而rest参数是ES6中提供并且希望以此来替代arguments的
-
-
注意:剩余参数必须放到最后一个位置,否则会报错
2.2 箭头函数的补充
在前面我们已经学习了箭头函数的用法,这里进行一些补充:
-
箭头函数是没有显式原型prototype的,所以不能作为构造函数,使用new来创建对象
-
箭头函数也不绑定this、arguments、super参数
-
以后要使用类,就不再使用function了,而是使用class

图21-3 箭头函数说明
//function定义的函数是有两个原型的
function foo(){}
console.log(foo.prototy2pe);//浏览器打印:{constructor: ƒ},node打印:{}
console.log(foo.__proto__ === Function.prototype);//true
// 箭头函数是没有显式原型的
const bar = () => {}
//这是个函数,所以会有隐式原型
console.log(bar.__proto__ === Function.prototype);//true
//但是箭头函数却没有显式原型的
console.log(bar.prototype);//undefined
//所以这个证明了一点,那就是使用箭头函数是不能够new出构造函数的,因为构造函数就是产生一个对象,然后将函数身上的显式原型prototype赋值过去,如果连显式原型都没有,那自然无法赋值
const p1 = new bar()//报错:Uncaught TypeError: bar is not a constructor
//以后如果你想要使用的话,就使用class进行替代了构造函数的使用,class里面的配置就已经包括了constructor了
-
箭头函数不创建自己的
this上下文,因此this有别于传统函数的动态作用域绑定-
通过Babel,可以看出在箭头函数内部,所有对
this的引用都被替换为对_this的引用。这样做确保了箭头函数体内的this值与其定义时所在的上下文中的this一致,与运行时的上下文无关 -
通过这种转化方式,Babel 模拟了箭头函数的词法作用域绑定特性。
_this变量的引入是为了解决 JavaScript 运行时中对this上下文动态绑定的行为,也说明了this与箭头函数本身无关 -
所以this的绑定规则和箭头函数无关,是固定位于上层的this,Babel所转化的,也是以前折中的做法,而这也是大多数回调函数、纯函数中所期望的效果
-
const foo = () => {
console.log(this)
}
function foo2 (){
console.log(this)
}
//Babel转化
var _this = this;
var foo = function foo() {
console.log(_this);
};
function foo2() {
console.log(this);
}
三、展开语法
-
展开语法(Spread syntax):
-
可以在函数调用/数组构造时,将数组表达式或者string在语法层面展开;
-
还可以在构造字面量对象时, 将对象表达式按key-value的方式展开;
-
-
在MDN中,主要说明
展开语法的场景有以下三种:-
函数调用:简化多参数的数组传递
-
构建新数组:合并多个数组或添加新元素时无需使用额外的数组方法如
concat -
对象拷贝和合并:方便地进行对象属性的拷贝或合并,无需额外库或复杂逻辑
-
//1.基础使用
const names = ["coderwhy","小余","JS高级","李银河"]
function foo(name1,name2,...args){
console.log(name1,name2,args);
}
foo(...names)
//或者也可以直接展开字符,不过用得很少
const str = "Hello"
foo(...str)
//2.构建新数组
const parts = ['shoulders', 'knees'];
const body = ['head', ...parts, 'toes'];
// body: ['head', 'shoulders', 'knees', 'toes']
//3. 对象合并
const obj1 = { foo: 'bar', x: 42 };
const obj2 = { foo: 'baz', y: 13 };
const mergedObj = { ...obj1, ...obj2 };
// mergedObj: { foo: 'baz', x: 42, y: 13 } // 注意 foo 的值是 obj2 中的,后者覆盖前者
-
展开语法在内部工作时,对数组或可迭代对象进行迭代,将每个项或属性复制到新的对象或数组中。对于函数调用,这意味每个数组元素按顺序传递给函数参数。对于数组和对象字面量,展开操作则是浅拷贝,新构建的数组或对象获得原始元素或属性的引用
-
可以看出,展开语法和剩余参数的写法是一样的,都是
...进行,但其中所扮演的角色是不同的 -
剩余参数是收集剩余的多个参数到一个集合(数组)中
-
展开语法是将一个集合(数组或对象)分散成单独的元素或属性
-
-
对于展开语法的使用,最主要的地方在于,清楚的知道哪些内容是还可以拆分的,哪些是不可以的。像对象数组这种明显的复杂数据类型是能够清楚知道可以拆分,而字符串可以进行拆分就稍微不太明显,这个问题值得去尝试验证一下
-
通过展开进行合并时,如果有相同部分的内容,后者会覆盖前者
-
-
而假如数组和对象同时进行展开合并的话,结果会是怎么样的?
-
可以看到,数组的优先度是更高的,在合并时,对象obj1放前面,数组parts放后面,但合并的结果中可以看到数组依旧在前面,并且是可以成功合并的,key就是数组的索引
-
在之前的学习中,我们已经说明了,数组就是一种特殊的对象,所以在合并时,数组是可以合并进对象形式的内容中的
-
但对象是没办法融入进数组形式内容的,这是一个对象包含数组的并集关系,并且这里还涉及到一个
可迭代的概念,这是我们后续会学习到的
-
const parts = ['shoulders', 'knees'];
const obj1 = { foo: 'bar', x: 42 };
const mergedObj = { ...obj1, ...parts };
console.log(mergedObj);//{ '0': 'shoulders', '1': 'knees', foo: 'bar', x: 42 }
const mergedOArr = [...obj1, ...parts];//TypeError: obj1 is not iterable 无法正常迭代
-
同时需要注意展开运算符(展开语法)对于简单数据类型和复杂数据类型的不同处理情况
-
对于原始数据类型(如数字、字符串、布尔值),展开操作直接在栈中处理。例如,展开字符串会将字符串的每个字符作为独立的元素处理
-
展开对象或数组时,涉及到从栈中读取对象的引用,然后到堆内存中访问实际的对象或数组数据
-
-
展开操作本质上是
浅拷贝,即复制对象或数组的第一层属性到一个新的对象或数组中。这意味着:-
原始类型的属性值直接复制
-
对象或数组类型的属性值复制的是引用(指针),而不是对象本身,而这种内存地址指向同一
堆内容的话,会导致修改一处,处处都跟着修改的结果
-
let arr = [1, { name: 'coderwhy' }, 3];
let spreadArr = [...arr];
spreadArr[1].name = '小余'; // 修改了原始对象,因为是引用
console.log(arr[1].name); // 输出 '小余'
-
对于数组,它会按照索引顺序处理每个元素,对于对象,它会按照属性的枚举顺序(通常是定义顺序,但具体可能因 JavaScript 引擎而异)处理每个属性
-
在技术实现上,JavaScript 引擎内部会对数组或对象执行迭代操作,根据是数组还是对象,使用不同的内部方法来获取所有可枚举的属性或元素
-
而这也是在数组中解构对象会报无法迭代错误的原因,因为数组的处理方式不能完全包括对象
-
3.1 对象的引用赋值-浅拷贝-深拷贝
-
在 JavaScript 中,深拷贝和浅拷贝是处理对象和数组时常见的概念,主要涉及到
如何复制数据以及复制的数据与原数据之间的关系-
浅拷贝只复制对象或数组的第一层元素。如果被复制的元素是原始类型(如数字、字符串、布尔值),则直接复制值。如果元素是对象或数组,则复制引用(即指针),而不是复制对象或数组本身
-
这个浅拷贝的概念在展开语法中已经得以展现,而与浅拷贝所对立的深拷贝,会复制对象的所有层级,创建一个完全独立的副本。不仅第一层的元素被复制,所有更深层的元素也都被递归复制,因此修改新对象不会影响原始对象
-
从内存角度看待复杂数据类型来说,浅拷贝是复制了栈的内容,而深拷贝是复制堆的内容
-
表21-3 深浅拷贝总结
| 特性 | 浅拷贝 | 深拷贝 |
|---|---|---|
| 复制方式 | 只复制第一层的元素 | 复制所有层级的元素 |
| 复制类型 | 原始类型直接复制值,对象和数组复制引用 | 所有类型都创建新的副本,包括对象和数组的嵌套元素 |
| 对嵌套对象的影响 | 修改原对象中的嵌套对象会影响到拷贝对象 | 修改原对象中的嵌套对象不会影响到拷贝对象 |
| 内存影响 | 占用较少内存,因为只复制第一层元素,更深层次仅复制引用 | 占用更多内存,因为复制了所有数据,包括所有嵌套结构 |
| 使用场景 | 当只需要复制顶层属性,且不关心属性中的对象和数组时使用 | 当需要完全独立的副本,确保原始数据的修改不会影响到副本时使用 |
-
假设我们有如下foo对象
-
可以从内存中对比其中的区别,浅拷贝中的对象只是复制了引用地址(存储在栈上),而这些地址指向堆上的同一个对象;因此,修改任何一个浅拷贝的对象都会影响到原对象和其他所有的浅拷贝对象。而深拷贝则是复制堆内存,并且确保最终完全独立的副本
-
let bar = {
address:"福建",
height:1.75
}
const foo = {
name:'小余',
age:18
bar
}
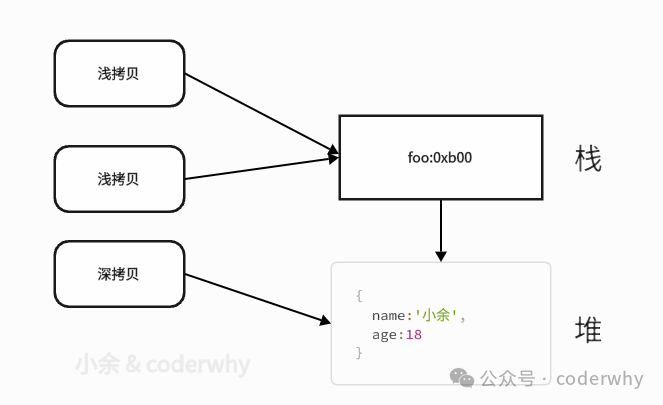
图21-4 深浅拷贝的内存指向情况
-
但依旧要记得深拷贝的核心概念:复制所有层级,创建一个完全独立的副本
-
对于简单数据类型来说,如数值、字符串、布尔值)本身就是不可变的,存储在栈上。对这些数据的复制,本质上就是创建一个新的副本,这本身可以看作是“深拷贝”,因为它们是按值传递的。即使使用深拷贝方法,结果也与普通的赋值相同,因为简单数据类型不包含引用其他对象的能力
-
-
但因此就会引申出来一个令人好奇的问题:假如在对象1内还有对象2,而在对象1中的对象2表达形式是内存地址,也是递归拷贝吗?那此时在对象中的内存地址是否会发生改变
-
深拷贝会
递归地处理每一个嵌套的对象或数组,这一点在一开始的定义中就已经明确。每一层的复杂数据类型都会在堆内存中重新创建,因此内存地址确实会发生改变。这样,每个级别的对象都拥有自己的独立副本,互不影响
-
-
这主要涉及到深拷贝的处理流程:
-
如果元素是简单数据类型,直接复制值到新容器
-
如果元素是复杂数据类型(如另一个对象或数组),递归地调用深拷贝函数,将返回的拷贝结果赋值到新容器的相应位置
-
检查数据类型:首先判断当前数据是否为复杂数据类型(对象或数组)
-
创建新对象/数组:为当前数据创建一个新的容器(对象或数组)
-
递归拷贝:遍历原对象或数组中的每一个元素
-
返回新容器:完成所有元素的拷贝后,返回新创建的对象或数组
-
-
因此深拷贝确保数据结构的整体性和一致性,新的数据结构在逻辑上与原始结构完全相同,但在物理存储上完全独立
-
原生实现深拷贝具备一定的缺陷,例如无法复制函数、undefined在转化过程会被忽略、不能解决循环引用、忽略日期对象、忽略正则表达式,
Map,Set等高级数据结构无法通过这种方式正确复制等等 -
在后续过程中,我们会进行手写实现深拷贝,而在开发中,往往会使用第三方库来协助我们实现对应的效果
-
//利用JS机制间接实现实现 有局限性,但胜在使用简单
const info = JSON.parse(JSON.stringify(obj))//这样先将obj对象转化为字符串,又转化回了对象。但这个转回的对象已经是一个全新的对象了,跟原来的obj已经没有关系了,尽管内容一样
3.2 数值的表示
-
在ES6中规范了二进制和八进制的写法:
-
该目的依旧是为了让使用界限清晰,减少二义性,关于这点,在ES6中的很多地方,我们都能够见到
-
表21-4 数值表示(ES5与ES6对比)
| 特性 | ES5 及之前的版本 | ES6+ |
|---|---|---|
| 二进制表示 | 不支持直接表示二进制 | 使用 0b 或 0B 前缀表示。例如:0b1011 表示十进制的 11 |
| 八进制表示 | 使用 0 前缀,但易混淆且在严格模式下抛出错误 | 使用 0o 或 0O 前缀表示。例如:0o11 表示十进制的 9 |
//正常十进制
const num1 = 100
//b -> binary(二进制)
const num2 = 0b100
//octonary(八进制)
const num3 = 0o100
//hexadecimal(十六进制)
const num4 = 0x100
console.log(num1,num2,num3,num4);//100 4 64 256
-
另外在ES2021新增特性:数字过长时,可以使用_作为连接符,在理解上会更加友好
const num = 100_000_000
console.log(num);














 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









