







 AdrenoGPU是Qualcomm为移动平台设计的集成GPU,支持多种先进的移动API,如OpenGLES和DirectX等。AdrenoGPU采用统一渲染架构,支持早期深度测试、Tiled渲染架构等多种特性,能够为移动设备带来高性能的图形处理能力。
AdrenoGPU是Qualcomm为移动平台设计的集成GPU,支持多种先进的移动API,如OpenGLES和DirectX等。AdrenoGPU采用统一渲染架构,支持早期深度测试、Tiled渲染架构等多种特性,能够为移动设备带来高性能的图形处理能力。
Adreno GPU详细介绍
Adreno GPU是美国Qualcomm为移动平台设计的集成GPU。支持最先进的移动API,同时具有优异的性,应用于对带宽、功耗、散热等方面都有限制的移动芯片。Adreno GPU支持任意复杂的API,比如OpenGL ES(2.0、3.0、3.1等)、OpenCL、RenderScript、DirectX等。目前发布的分别有Adreno 130、Adreno 200、Adreno 203、Adreno 205、Adreno 220、Adreno 225、Adreno 302、Adreno 305、Adreno 306、Adreno 320、Adreno 330、Adreno 420、Adreno 430系列。Qualcomm可以为移动终端带来台式机品质的游戏体验。
Epic Games 高级引擎程序师 Niklas Smedberg 表示: “Epic 现在已经通过 Qualcomm Technologies 的骁龙 805 芯片组将虚幻引擎 4 ( Unreal Engine 4 )引入到了 Android 终端上。最近,我们还与Qualcomm Technologies 合作,通过骁龙 Adreno GPU 硬件将图形体验提升至一个全新的水平 ,为Android 智能手机和平板电脑带来前所未有的高效统一着色功能。 ”
请看下面两张图,第一张是在PC机上渲染的,而第二张是在“骁龙 615”上渲染的,是不是已经完全达到PC的渲染品质了呀!

Adreno GPU 架构特性
1、统一渲染架构(Unified shader architecture)
所有的Adreno GPU都支持统一渲染模型,Adreno GPU的计算单元(ALU)即支持顶点shader又支持像素/片段shader。这样的设计可以充分利用系统的资源避免浪费。
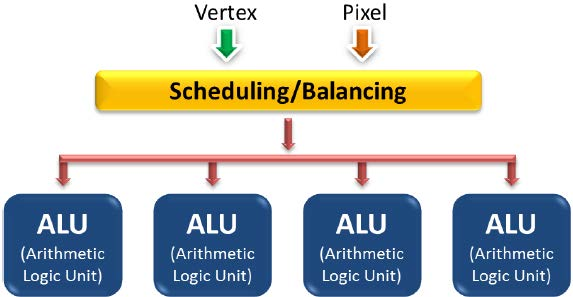
Adreno GPU的统一渲染架构GPU里,顶点着色器和片段着色器之间不存在物理分割,是系统根据当前的运行状况自动分配他们之间的比例。如下图:
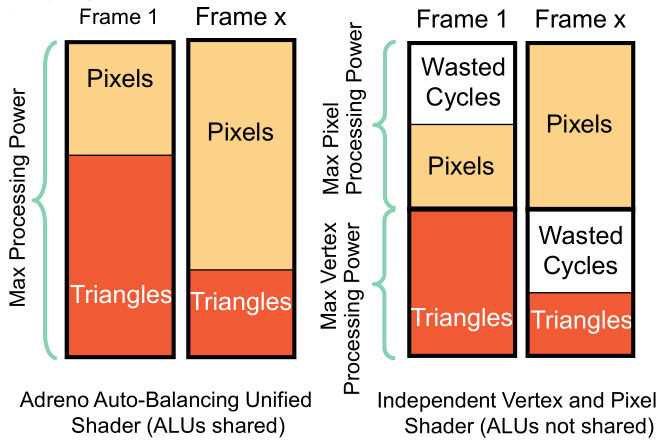
Adreno GPU上,第一帧顶点计算多就分配给顶点着色器多一些ALU,而第X帧像素运算多就分配给像素着色器多一些ALU。而不支持统一渲染架构的GPU是平均分配ALU的,比如第一帧像素处理少用不完自己的ALU,但是却无法共享给顶点着色器,造成巨大浪费。
2、更早进行深度测试(Early Z Reject)
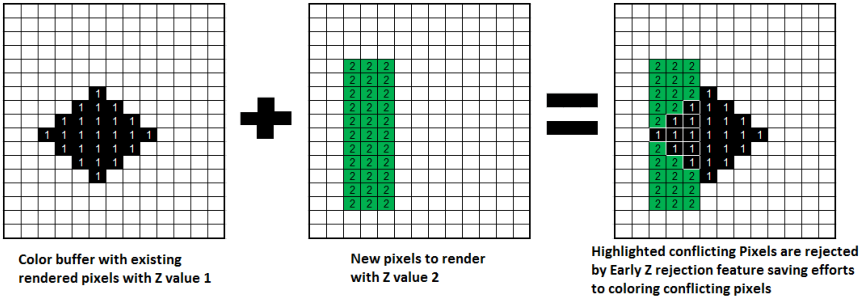
为了避免浪费GPU资源去画那些被挡住的点,提高渲染包含不透明物体的大场景时的性能,更早进行深度测试。尽量早的剔除被挡住的不透明的面,这样被剔除的像素不会被着色器着色,也不会被其他模块处理。并且,剔除非常高效—— 像素剔除的速率是像素绘制速率的2倍。
例如下图,新图元(绿色)中和黑色图元重叠的部门将被剔除,第三张图显示了最终帧缓冲区的内容。
那么,我们如何利用该特性提高你的程序的性能呢?在绘制你场景中的不透明物体时从近到远按顺序渲染(例如,最后画天空),这样远处被遮挡的部分可以通过Early Z Reject机制被剔除掉。
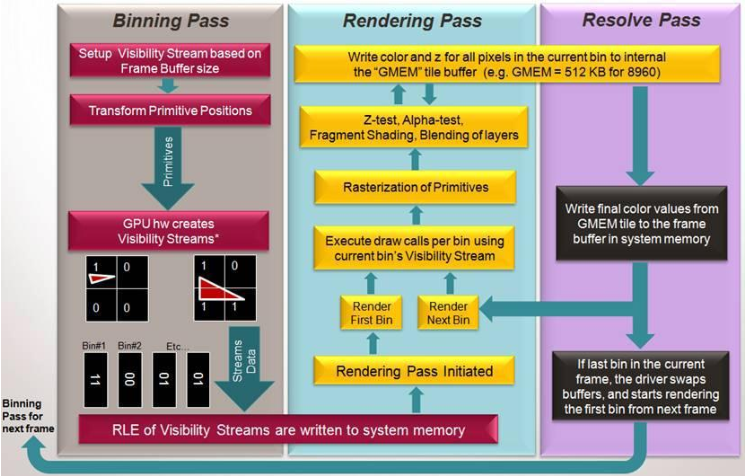
3、Tiled 渲染架构
Adreno GPU包含高速缓存(GMEM)来存储深度、模板和颜色信息,类似PC显卡的显存。GPU可以以很高的速度访问GMEM,访问速度到什么程度呢?到访问时间可以忽略不计,同时耗电量也可以忽略不计。所以,使用GMEM是高效低耗的。同时,还可以降低alpha混合和抗锯齿的成本。
既然GMEM这么好,是不是越大越好呢?回答是肯定的,但是这会导致成本的急剧增加。所以,GMEM一般不会太大,比如1M。GMEM这么小怎么来使用呢?这就需要基于Tile的渲染架构。
Tile渲染不同于一次渲染整个场景,而是分多次渲染。要渲染的面被分割为一些小的“bin”. Bin 的大小由GMEM的大小除以渲染目标的格式(包括深度缓存的格式)和大小来决定。
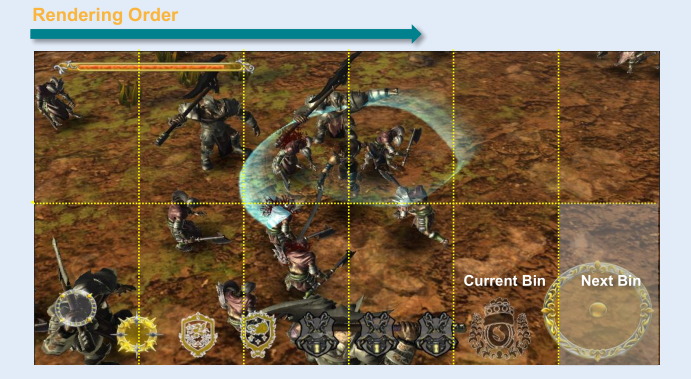
每个bin的所有像素都被画到GMEM里面,GMEM有着非常高的带宽足以匹配GPU的能力。等这个bin绘制完成后,GPU将GMEM中混合好的像素以一个整体的形式高效写回到系统内存的帧缓冲区,这叫做一次“Resolve”。
我们知道GPU对内存的访问是最耗时间、性能和功耗的。而有了Tile架构,我们就可以大大减少对内存的访问。如上图画面,有12个Tile,所以GPU只需要访问12次内存即可。
当然上面说的12次内存访问只是理论值,如果用户的程序写的不规范的话,不但不会提高性能还会降低性能。数据通过系统总线在内部存储和外部帧缓冲区之间的传输是非常耗资源的操作,应该尽量避免。特别是在一个帧的中间调用glTexImage2D, glBufferData, glReadPixels, glCopyTexImage2D等函数, 强迫驱动从外部低速存储加载一个tile到内部高速存储。
4、FlexRender技术
前面我们讲的Tiled渲染架构是一种延迟渲染技术(DeferRender),而与之相反的就是直接渲染技术(DirectRender)。Adreno GPU为了最大的发挥高性能的特性,可以对渲染目标进行分析,自动选择DeferRender还是DirectRender。
5、PCF阴影处理
Percentage Closer Filtered (PCF)阴影处理技术通过过滤深度测试的结果来生成更柔和的阴影边缘可以提供消除锯齿的流畅、逼真的动态阴影。

6、动态硬件曲面细分着色器(Tessellation)
Adreno GPU通过硬件从低分辨模型中创建更多的细节,既节省内存带宽的占用,又可以提供渲染非常平滑和高细节场景的能力。

7、纹理支持
- 多重纹理
- 视频纹理
- 纹理压缩
- 浮点纹理
- 无缝立方体纹理
- 3D纹理
- 大尺寸纹理
- sRGB纹理
8、其他特性
统一的缓冲区
- 优化:为着色程序提供统一的数据
- 切换统一的缓冲区一般比切换单独的缓冲区快
- 统一的缓冲区可以存放更大的数据快,而且可以在不同的程序间共享
变换反馈
- 允许保留图元被顶点着色器变换后的状态
- 状态被写入到一个缓冲器对象,并且可以在后续的GPU处理提交以供使用
- 可用于粒子系统大幅优化
多重渲染目标
- 同时渲染到多个渲染目标纹理上
- 通过将数据写入到不同的目标,减少或消除了执行多次渲染的必要
- 常见的用途是用来实现延迟着色管线
升级的计算能力
- Direct compute, OpenCL 1.2 Full profile,OpenGL ES 3.1 Compute
- 为RenderScript提供更多的硬件加速
半精度双倍速率 (DRHP) 设计
- 使用额外的/复杂的着色器而不会影响性能
- 更低的功耗,更好的性能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









