







Clustering by Passing Messages Between Data Points
- 聚类算法是初始化聚类,然后进行迭代,但只有当初始化合适的情况下,才能得到最优解。我们聚类的一般方法:在一组数据中寻找K个中心,使数据点与它们最近中心点之间的平方差的和最小。较常用的K-Centers方法必须人工指定K值。算法在数据集中随机选择K个点作为初始中心点,反复提纯以使平方差之和减小。K-Centers对于初始化时的中心点十分敏感,只有在聚类数较小且幸运的至少有一个初始中心点在最优解的中心点附近。因此,使用K-Centers时要用不同的初始数据进行多次试验,在其中取最好的结果。
- 这篇文章中采用的是一种“亲密度传播”的方法,输入是数据对之间的相似度,这些相似度组成N*N(N为数据对象的数目)的相似矩阵S,利用该矩阵进行自动迭代计算。
- message 更新是建立在最小化能量函数的基础上进行,message表示的是数据与当前聚类中心的亲密度。
注:相似度矩阵应该是一个负值矩阵,即每个元素的值不能大于0,如果用欧式距离,那么取负值即可。
AP算法有两个重要的消息,Responsibility,Availability。
R(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度,表示的是从i到k的消息;
A(i,k)描述了数据对象i选择数据对象k作为其据聚类中心的适合程度,表示从k到i的消息。
R(i,k)与A(i,k)越大,那么数据对象k就越有可能作为聚类的中心。AP算法就是不断迭代更新每一个数据对象的吸引度和归属度,直到迭代一定的次数,产生m个高质量的exemplar,同时将其余数据对象分配到相应的聚类中。
算法实现:
算法输入是点与点之间相似性s(i,k)的集合。相似性s(i,k)反映点s作为点i中心点的适应程度(可能性)。当我们将目标设置为最小化平方差之和时,相似度s(i,k)定义为点i、k之间的负的欧拉距离s(i,k)=-||xi-xk||2
当使用中心点条件概率模型时, s(i,k)可以设为k作为中心点关于点i的log似然函数,当合适时, s(i,k)也可手动设置。
该方法不再需要设置聚类数量,而需要为每个点设置个实数值s(k,k),s(k,k)值较大的点更有可能选为中心点。S(k,k)称为首选项(preference )。中心点在信息传递的过程中浮现,其数量受preference影响。
若已知所有的点被选为中心点的概率相同,则可将所有点的preference设置为相同的值(不同的值可能会导致不同的聚类数量),该值可以为所有相似性的中值或者最小值。
信息传播
算法中有两种信息:响应度和可用性,每种信息都会引起一种竞争。在每个阶段,综合两种信息决定哪些点作为中心点,和所有的点归属于哪个中心点。
响应度(responsibility ) r(i,k)从i向k发送,反映k作为i中心点的累积迹象(cumulated evidence )(可能性)。
可用性( availability ) a(i,k)自候选中心点k向点i发送,反映i将k作为中心点的合适性。
开始时(第一次迭代),a(i,k)=0
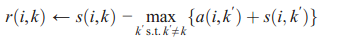
r(i,k)以下述规则更新
r(k,k)反映一个点是否适于作中心点,支持点多,则其值为正。
第一次r(i,k)更新时,完全是数据驱动(data-driven),不考虑每个潜在中心点有多少其他支持者(点)(即a(i,k)都为0)。
根据更新规则,若i与k的近似度比i与其他点的近似度都高,则r(i,k)为正数(k可能为i的中心点或者说i支持k成为中心点)。
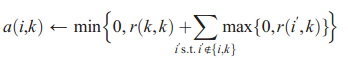
a(i,k)以下述规则更新
a(i,k)的更新中连加只加正的r(i,k),因为只有正的r才会反映点k适于作中心点的程度。
在以后的迭代中,若k点事实上归属于某中心点时(即自身非中心点),其可用性a(i,k)将下降到0以下(当无支持点或者支持点较少时, r(k,k)为负,更新公式中后面的连加较小,小于r(k,k)绝对值,使a变为负数)。其返回的负数可用性a(i,k)将会削弱s(i,k)的影响力,使k不再作为潜在中心点。
当r(k,k)为负(当前判断k不适于作中心点)时,若其收到来自邻居的正数响应度r(i,k),则其可用性a(i,k)会变大。
为了防止过大的正数响应度r的影响,将可用度的和现在在阈值0以下(即公式中的min计算)。
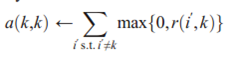
自可用性a(k,k)按以下规则更新
基于来自邻居的正的响应度来评级k是否适于作中心点。
信息只在有连接的点之间传播(即已知相似度的点之间,在具体应用我们可能并不需要使用所有点与其他点的相似信息),利用响应度和可用性综合评价哪个点适于作中心点。对于点i,使a(i,k)+r(i,k)最大的k即i的中心点,若k=i,则i本身即中心点。
一个迭代过称分为三个阶段:1、根据可用性a更新响应度r;2、根据响应度r更新可用性a;3、根据a和r综合判定当前阶段的中心点。
设置迭代次数或者设置信息变化的阈值使迭代一定次数后终止。为防止在迭代中出现数据震荡,在更新信息时需加入一个阻尼系数p(p在区间[0,1]内)。P乘以上次迭代的值加上(1-p)乘以本次迭代变化的值作为数值更新信息。
%%随机产生矩阵后对角线赋-1
S=rand(10)-1;
N=size(S,1);
for i=1:N
S(i,i)=-1;
end
S; %%随机矩阵
%%将生成的矩阵改为对称矩阵
for i=1:N
for j=1:N
if(i<j)
S(i,j)=S(j,i);
end
end
end
S %%对称随机矩阵
%%之前实验
%S=[-1,0.9,0.1,0.3;0.8,-1,0.2,0.2;0.1,0.2,-1,0.9;0.1,0.3,0.8,-1];
%S=[-1,-0.8,-0.1,-0.2;-0.7,-1,-0.1,-0.3;-0.3,-0.1,-1,-0.7;-0.1,-0.2,-0.9,-1]
A=zeros(N,N);
R=zeros(N,N); % Initialize messages
S=S+1e-2*randn(N,N)*(max(S(:))-min(S(:))) % Remove degeneracies %%处理后对称矩阵
lam=0.5; % Set damping factor
for iter=1:100
% Compute responsibilities
Rold=R;
AS=A+S;
[Y,I]=max(AS,[],2);
for i=1:N
AS(i,I(i))=-1000;
end;
[Y2,I2]=max(AS,[],2);
R=S-repmat(Y,[1,N]);
for i=1:N
R(i,I(i))=S(i,I(i))-Y2(i);
end;
R=(1-lam)*R+lam*Rold; % Dampen responsibilities
% Compute availabilities
Aold=A;
Rp=max(R,0);
for k=1:N
Rp(k,k)=R(k,k);
end;
A=repmat(sum(Rp,1),[N,1])-Rp;
dA=diag(A);
A=min(A,0);
for k=1:N
A(k,k)=dA(k);
end;
A=(1-lam)*A+lam*Aold; % Dampen availabilities
end;
E=R+A % Pseudomarginals
I=find(diag(E)>0)
K=length(I);% Indices of exemplars
[tmp c]=max(S(:,I),[],2)
c(I)=1:K %%替换自身所在的位置
idx=I(c) % Assignments %%找出N个样本点所对应的中心点
disp('AP聚类结果如下:\n');
disp('------------------');
fprintf('类数为:%d \n',K);
fprintf('类的中心点和所包含的对应点如下:\n')
disp('-----------------------------------');
for i=1:K
m=I(i); %%第i个中心点对应S中的对角线中的位置
fprintf('第 %d 个中心点: S(%d)=%6.4f \n',i,m,S(m,m));
disp('\n');
for j=1:N
n = idx(j); %%各样本点所对应的中心点位置
if(n == m)
fprintf('S中第 %d 个样本点聚到该中心点下:S(%d)=%6.4f ',j,j,S(j,j)); %%打印此次中心点所包含的样本点
if(mod(j,2) == 0) disp('\n'); %%分行控制输出
end
end
end
end













 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









