







关键要点
- RAG(检索增强生成)技术通过结合外部知识库提升AI语言模型的准确性和相关性,研究表明效果显著。
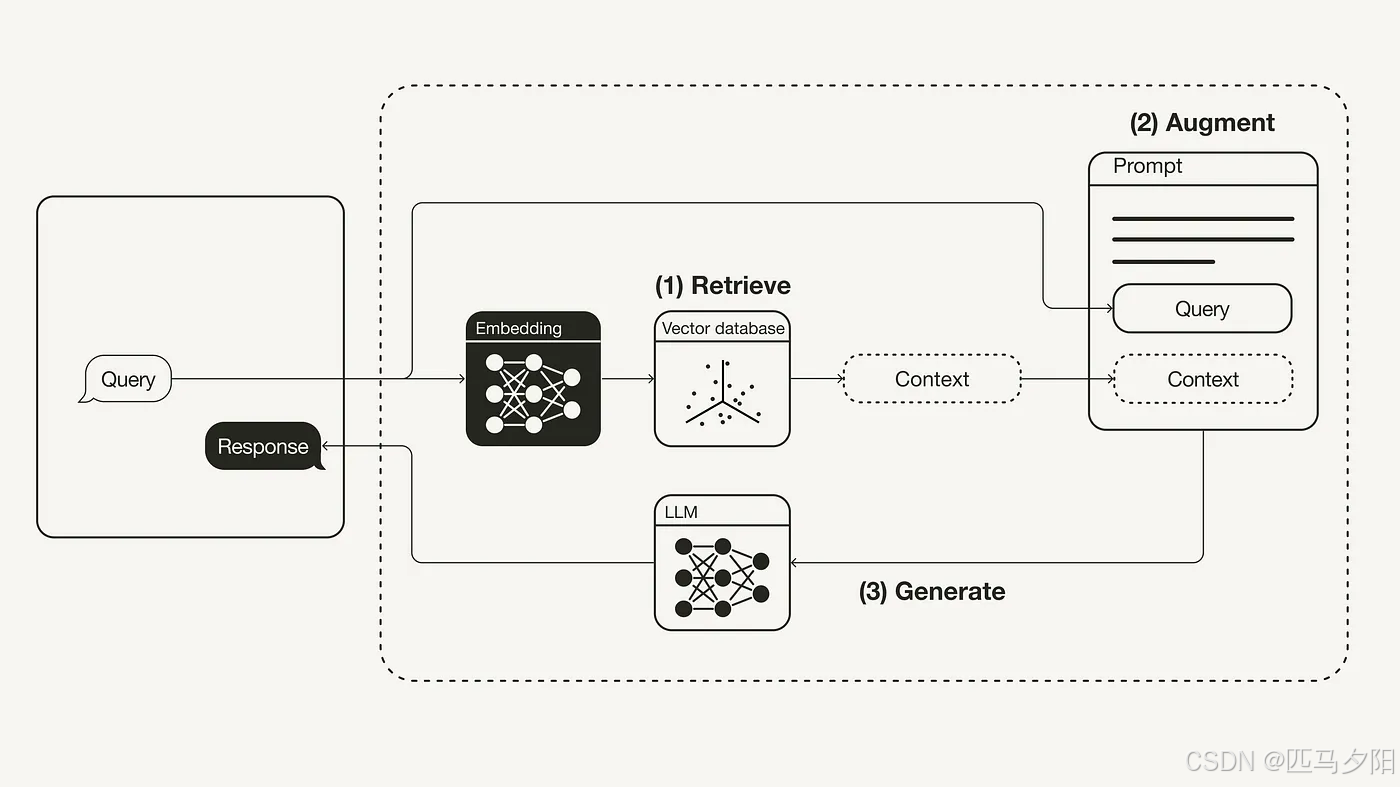
- 其原理包括检索相关信息、增强输入数据,然后由语言模型生成回答。
- 主要作用是提供更准确、及时的回答,无需重新训练模型。
- 应用场景包括客户服务、教育、医疗和法律等领域。
- 未来趋势可能包括改进检索效率和扩展到多模态数据,证据显示发展潜力巨大。
- 代码示例展示了如何使用LangChain实现RAG,涉及数据加载、嵌入生成和响应生成。
RAG技术的全面讲解与代码示例
简介
RAG(Retrieval Augmented Generation,检索增强生成)是AI领域的一种创新技术,特别是在自然语言处理(NLP)中。它通过结合信息检索和文本生成能力,显著提升了大型语言模型(LLM)的表现,使其能提供更准确、相关且实时的回答。本文将从原理、作用、应用场景及未来发展趋势四个方面全面解析RAG技术,并结合代码示例展示其实现方式,适合对AI感兴趣但非技术背景的读者。
原理详解
RAG的工作流程可以分为以下步骤:
- 数据准备与索引:首先,知识库中的数据(如文档、数据库)会被处理并生成嵌入(embeddings),这些嵌入是文本的数值表示,便于后续搜索。常用工具包括向量数据库如Pinecone或FAISS。
- 检索过程:当用户提出问题(如“哪个行星有最多的卫星”),系统会生成问题的嵌入,然后在知识库中查找最相关的文本块。这通常通过语义相似性搜索实现,而非简单关键词匹配。
- 信息增强:检索到的文本块会与用户问题结合,形成增强后的输入。例如,问题“如何做蛋糕”可能与食谱片段合并,变成“基于这些食谱,如何做蛋糕”。
- 生成回答:增强后的输入被送入语言模型,模型基于其训练知识和检索信息生成最终回答,确保内容准确且上下文相关。
研究显示,RAG生成的回答比仅依赖训练数据的LLM准确率高出约43%,特别是在知识密集型任务中。
作用与优势
RAG的主要作用包括:
- 提升准确性:通过访问外部知识库,减少模型“幻觉”(hallucination,即生成错误信息)的风险。例如,在医疗场景中,RAG能确保AI基于最新研究提供建议。
- 保持实时性:无需重新训练模型,就能融入最新数据,适合快速变化的领域如金融市场。
- 成本效益:相比重新训练LLM,RAG只需更新知识库,节省计算资源和时间。一些研究指出,RAG的实现可能只需几行代码,开发成本低。
- 增强可信度:用户能看到模型引用的来源,方便核实信息,特别在法律或学术研究中很重要。
然而,RAG也面临挑战,如检索到的信息可能不准确或相关性不足,需通过优化检索算法解决。此外,处理大规模知识库时,效率可能成为瓶颈。
应用场景分析
RAG的应用场景广泛,涵盖多个行业,以下是几个典型例子:
| 行业 | 应用场景 | 示例 |
|---|---|---|
| 客户服务 | 聊天机器人提供个性化支持 | 查阅订单历史,回答产品问题 |
| 教育 | AI导师辅助学习 | 检索教材内容,解释复杂概念 |
| 医疗 | 医疗AI提供定制化建议 | 查找患者记录或最新研究,辅助诊断 |
| 法律 | 法律研究与文件起草 | 搜索案例法和法规,辅助律师工作 |
| 金融 | 金融分析与咨询 | 检索市场趋势,提供投资建议 |
这些场景中,RAG的灵活性使其能适应不同需求。例如,在客户服务中,RAG能让聊天机器人根据企业内部数据生成回答,提升用户体验。在教育中,它能为学生提供个性化学习资源,增强学习效果。
未来发展趋势
RAG技术的未来发展方向包括:
- 检索效率提升:通过改进嵌入方法和搜索算法,加快信息检索速度,特别在超大规模知识库中。
- 多模态扩展:目前RAG主要处理文本,未来可能扩展到图像、视频等数据,形成多模态RAG系统。
- 与其它AI技术的融合:如结合强化学习或少样本学习,进一步优化生成质量。
- 用户反馈机制:允许用户反馈检索信息或回答的准确性,动态优化系统表现。
- 安全与隐私:确保处理敏感数据时符合隐私法规,防止数据泄露。
研究表明,这些趋势将使RAG在更多复杂场景中发挥作用,例如实时多语言翻译或跨模态内容生成。2025年3月12日,行业报告预测RAG将在企业AI应用中占据重要地位,特别是在需要高准确性的领域。
伦理与挑战
尽管RAG有诸多优势,但也存在伦理和技术挑战:
- 隐私问题:检索外部数据可能涉及用户敏感信息,需建立隐私保护机制。
- 偏见风险:知识库可能包含偏见,需通过监控和修正减少影响。
- 信息误解:RAG系统可能误解检索到的内容,导致错误回答。例如,MIT Technology Review提到,RAG可能从学术书误解信息,生成如“美国曾有一位穆斯林总统”的错误结论。
这些挑战需通过技术优化和伦理指导解决,确保RAG的公平性和可靠性。
代码示例:使用LangChain实现RAG
以下是一个使用LangChain库的简单RAG实现示例,展示如何构建一个问答系统:
# 安装必要的库
# pip install -qU langchain langchain-openai langchain-chroma langchain-community
# 设置OpenAI API密钥
import os
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
# 加载示例数据(这里使用网页数据)
from langchain_community import document_loaders
loader = document_loaders.WebPageLoader("https://example.com/some-data")
documents = loader.load()
# 将文档分割成小块
from langchain_text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 创建嵌入并存储到向量数据库
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
embedding_function = OpenAIEmbeddings()
vector_db = Chroma.from_documents(docs, embedding_function)
# 创建检索器
retriever = vector_db.as_retriever(search_kwargs={"k": 2})
# 设置语言模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 创建结合检索器和语言模型的链
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
template = """助理,你会收到一个问题和一些上下文。请使用上下文回答问题。如果上下文没有答案,就说“我不知道”。
问题:{question}
上下文:{context}"""
prompt = template.format(question=RunnablePassthrough(), context=retriever)
chain = prompt | llm | StrOutputParser()
# 提问
question = "文档的主要主题是什么?"
result = chain.invoke(question)
print(result)
这个示例展示了如何加载数据、预处理、存储到向量数据库、检索相关信息并生成回答。实际应用中,可能需要根据具体需求调整参数,如块大小或检索数量。
结论
RAG技术通过结合检索和生成能力,显著提升了AI语言模型的性能,适用于客户服务、教育、医疗等多个领域。其未来发展潜力巨大,特别是在效率提升和多模态扩展方面。结合代码示例,读者可以更直观地理解RAG的实现方式,相关资源可参考LangChain RAG Tutorial。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











