







回顾
在开始之前,我们需要知道自己在做什么。
之前,我们花了不少时间熟悉如何将RE转化为DFA,那么为什么要将RE转换为DFA?这个问题类似于现在为什么要将CFG(上下文无关文法)转换成Parser。在掌握具体的步骤之前,我们有必要说明一下这样做的目的。
首先看一下编译器的模型图:
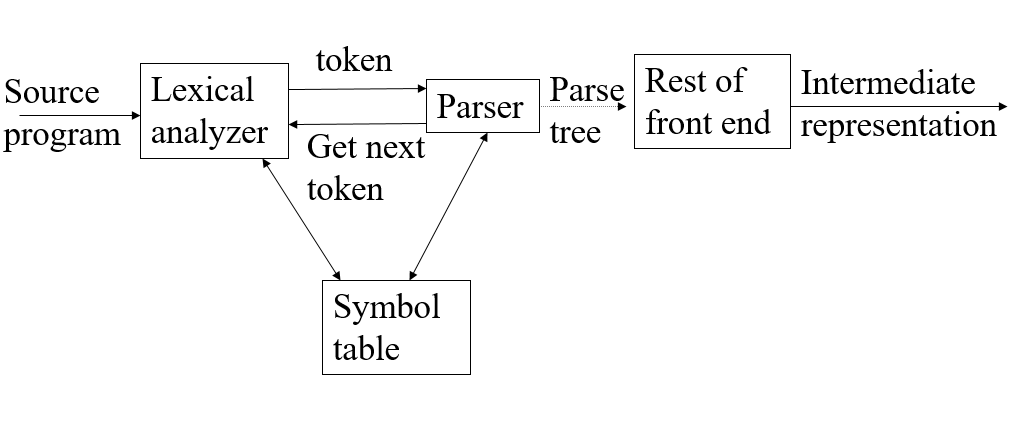
为什么要将RE转换到DFA?
相信看过实验一之后这个问题已经非常清楚。实验一我们需要完成一个词法分析器。我们需要自己用正则表达式定义一个语言的成分,比如单词、数字、注释、引用等,分别写出他们对应的NFA,合并NFA并转换成DFA,在得到DFA之后我们可以知道所有的状态和每个状态遇到不同的输入应该如何跳转处理,从DFA生成词法分析的程序。在上一篇文章的一开始,我们也提到了如何从DFA生成程序。词法分析器最终的输出是一个Token序列,记录了lexeme(词)、catalog(种类,就是自己用RE定义的)以及InnnerCode(内部码)
为什么要将CFG转到Parser?
之前我们所做的是词法分析,现在我们需要考虑语法分析的问题,当我们已经定义出一个语言的上下文无关文法,并且拿到了已经分析好的单词序列,我们怎样解析这些单词序列之间的语法关系呢?这类似于如何从有序的单词序列中分析出主语、谓语、宾语。我们需要知道这个单词对应语法中的那种成分,或者这一系列单词究竟符不符合语法要求。
递归下降分析法
有一种很简单的方法可以用来解决这个问题,它叫做递归下降分析法( Recursive Descent Parsing)。
这个方法利用递归与回搠的方法解决问题,核心在于为每个非终结符构造一个函数。
Example: S=>ABC, A=>aA|ε, B=>bB|ε, C=>cC|ε
首先是main函数:
main() {
i = S();
} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7341
7341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









