









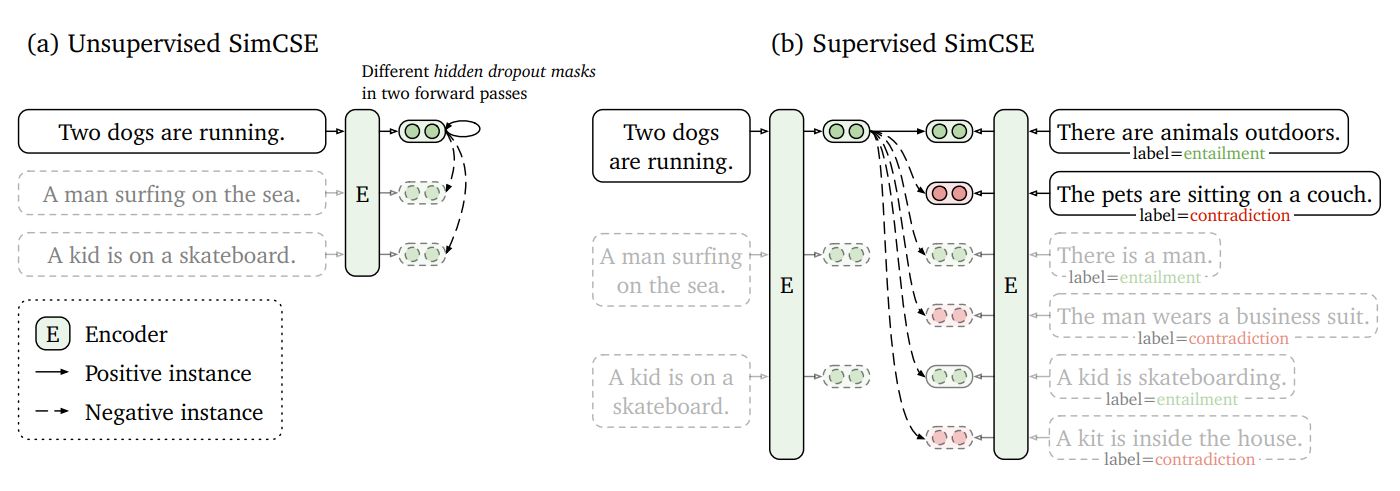
一个对比学习的框架
作者在这里通过将一句话分两次过同一个模型,但使用两种不同的dropout,这样得到的两个sentence embedding就作为模型的正例,而同一个batch中的其他embedding就变为了负例。
第二个代理任务就更加的直接。作者直接采用NLI有监督数据集做对比学习训练。NLI,及自然语言推理,其任务是判断两句话之间的关系。其中可能的关系有entailment (相近), contradiction (矛盾)或neutral (中立)。因此,entailment sentence pair就可以被天然的作为正例,此时如果我们继续把同batch中其他embedding作为负例,SimCSE的第二个代理任务我们就构建好了。此外,作者还尝试了把hard negative(及NLI dataset中的contradiction sentence pair)加到负例中,效果也有一定提升。
目标函数-非标准infoNCE函数
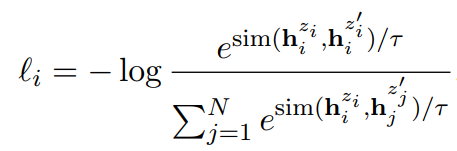















 1728
1728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









