







第一 、 STL中智能指针的缺陷
因为auto_ptr并不是完美无缺的,它的确很方便,但也有缺陷,在使用时要注意避免。首先,不要将auto_ptr对象作为STL容器的元素。C++标准明确禁止这样做,否则可能会碰到不可预见的结果
auto_ptr的另一个缺陷是将数组作为auto_ptr的参数: auto_ptr<char> pstr (new char[12] ); //数组;为定义
然后收集了关于auto_ptr的几种注意事项:
1、auto_ptr不能共享所有权。
2、auto_ptr不能指向数组
3、auto_ptr不能作为容器的成员。
4、不能通过赋值操作来初始化auto_ptr
std::auto_ptr<int> p(new int(42)); //OK
std::auto_ptr<int> p = new int(42); //ERROR
这是因为auto_ptr 的构造函数被定义为了explicit
5、不要把auto_ptr放入容器
第二、宏与内联函数的区别
#define IQUEUE_IS_EMPTY(entry) ((entry) == (entry)->next)
#define iqueue_is_empty IQUEUE_IS_EMPTY
...
if (iqueue_is_empty(&kcp->rcv_queue))
return -1;
(1)什么是内联函数?
内联函数是指那些定义在类体内的成员函数,即该函数的函数体放在类体内。
(2)为什么要引入内联函数?
当然,引入内联函数的主要目的是:解决程序中函数调用的效率问题。但是宏的定义很容易产生二意性。
(3)为什么inline能取代宏?
inline 定义的类的内联函数,函数的代码被放入符号表中,在使用时直接进行替换,(像宏一样展开),没有了调用的开销,效率也很高。
很明显,类的内联函数也是一个真正的函数,编译器在调用一个内联函数时,会首先检查它的参数的类型,保证调用正确。然后进行一系列的相关检查,就像对待任何一个真正的函数一样。这样就消除了它的隐患和局限性。
inline 可以作为某个类的成员函数,当然就可以在其中使用所在类的保护成员及私有成员。
(4)内联函数和宏的区别?
内联函数和宏的区别在于,宏是由预处理器对宏进行替代,而内联函数是通过编译器控制来实现的。而且内联函数是真正的函数,只是在需要用到的时候,内联函数像宏一样的展开,所以取消了函数的参数压栈,减少了调用的开销。你可以象调用函数一样来调用内联函数,而不必担心会产生于处理宏的一些问题。内联函数与带参数的宏定义进行下比较,它们的代码效率是一样,但是内联欢函数要优于宏定义,因为内联函数遵循的类型和作用域规则,它与一般函数更相近,在一些编译器中,一旦关上内联扩展,将与一般函数一样进行调用,比较方便。
(5)什么时候用内联函数?
内联函数在C++类中,应用最广的,应该是用来定义存取函数。我们定义的类中一般会把数据成员定义成私有的或者保护的,这样,外界就不能直接读写我们类成员的数据了。对于私有或者保护成员的读写就必须使用成员接口函数来进行。如果我们把这些读写成
员函数定义成内联函数的话,将会获得比较好的效率。
Class A
{
Private:
int nTest;
Public:
int readtest() { return nTest;}
void settest(int I) { nTest=I; }
}
(6)如何使用内联函数?
我们可以用inline来定义内联函数。
inline int A (int x) { return 2*x; }
不过,任何在类的说明部分定义的函数都会被自动的认为是内联函数。
(7)内联函数的优缺点?
我们可以把它作为一般的函数一样调用,但是由于内联函数在需要的时候,会像宏一样展开,所以执行速度确比一般函数的执行速度要快。当然,内联函数也有一定的局限性。就是函数中的执行代码不能太多了,如果,内联函数的函数体过大,一般的编译器会放弃内联方式,而采用普通的方式调用函数。(换句话说就是,你使用内联函数,只不过是向编译器提出一个申请,编译器可以拒绝你的申请)这样,内联函数就和普通函数执行效率一样了。
(8)如何禁止函数进行内联?
如果使用VC++,可以使用/Ob命令行参数。当然,也可以在程序中使用 #pragma auto_inline达到相同的目的。
(9)注意事项:
1.在内联函数内不允许用循环语句和开关语句。
2.内联函数的定义必须出现在内联函数第一次被调用之前。
第三、指针与引用的区别
指针能够毫无约束地操作内存中的如何东西,功能强大,但是使用不当非常危险。
引用仅是借用对象的别名,使用方便,不会意外的操作其他内存空间。
第四、STL 关于迭代器失效问题
当一个容器变化时,指向该容器中元素的迭代器可能失效。这使得在迭代器变化期间改变容器容易出现问题。在这方面,不同的容器提供不同的保障:
vectors: 引起内存重新分配的插入运算使所有迭代器失效,插入也使得插入位置及其后位置的迭代器失效,删除运算使得删除位置及其后位置的迭代器失效.
vector的push_back操作可能没事,但是一旦引发内存重分配,所有迭代器都会失效;
vector的insert操作插入点之后的所有迭代器失效;但一旦引发内存重分配,所有迭代器都会失效;
vector的erase操作插入点之后的所有迭代器失效;
vector的reserve操作所有迭代器失效(因为它导致内存重分配);
list/map: 插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.
deque的insert操作所有迭代器失效;
deque的erase操作所有迭代器失效;
1. 对于关联容器(如map, set, multimap,multiset),删除当前的iterator,仅仅会使当前的iterator失效,只要在erase时,递增当前iterator即可。这是因为map之类的容器,使用了红黑树来实现,插入、删除一个结点不会对其他结点造成影响。erase只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
for (iter = cont.begin(); it != cont.end();)
{
(*iter)->doSomething();
if (shouldDelete(*iter))
cont.erase(iter++);
else
++iter;
}
2. 对于序列式容器(如vector,deque),删除当前的iterator会使后面所有元素的iterator都失效。这是因为vetor,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。所以不能使用erase(iter++)的方式,还好erase方法可以返回下一个有效的iterator。
for (iter = cont.begin(); iter != cont.end();)
{
(*it)->doSomething();
if (shouldDelete(*iter))
iter = cont.erase(iter);
else
++iter;
}
3. 对于list来说,它使用了不连续分配的内存,并且它的erase方法也会返回下一个有效的iterator,因此上面两种方法都可以使用。
第五、linux中以及有几种信号以及如何加载core文件gdb
当我们的程序崩溃时,内核有可能把该程序当前内存映射到core文件里,方便程序员找到程序出现问题的地方。最常出现的,几乎所有C程序员都出现过的错误就是“段错误”了。也是最难查出问题原因的一个错误。下面我们就针对“段错误”来分析core文件的产生、以及我们如何利用core文件找到出现崩溃的地方。
何谓core文件:当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
当程序接收到以下UNIX信号会产生core文件:
在系统默认动作列,“终止w/core”表示在进程当前工作目录的core文件中复制了该进程的存储图像(该文件名为core,由此可以看出这种功能很久之前就是UNIX功能的一部分)。大多数UNIX调试程序都使用core文件以检查进程在终止时的状态。
core文件的产生不是POSIX.1所属部分,而是很多UNIX版本的实现特征。UNIX第6版没有检查条件(a)和(b),并且其源代码中包含如下说明:“如果你正在找寻保护信号,那么当设置-用户-ID命令执行时,将可能产生大量的这种信号”。4.3 + BSD产生名为core.prog的文件,其中prog是被执行的程序名的前1 6个字符。它对core文件给予了某种标识,所以是一种改进特征。
表中“硬件故障”对应于实现定义的硬件故障。这些名字中有很多取自UNIX早先在DP-11上的实现。请查看你所使用的系统的手册,以确切地确定这些信号对应于哪些错误类型。
下面比较详细地说明这些信号。
SIGABRT 调用abort函数时产生此信号。进程异常终止。
SIGBUS 指示一个实现定义的硬件故障。
SIGEMT 指示一个实现定义的硬件故障。
EMT这一名字来自PDP-11的emulator trap 指令。
SIGFPE 此信号表示一个算术运算异常,例如除以0,浮点溢出等。
SIGILL 此信号指示进程已执行一条非法硬件指令。
4.3BSD由abort函数产生此信号。SIGABRT现在被用于此。
SIGIOT 这指示一个实现定义的硬件故障。
IOT这个名字来自于PDP-11对于输入/输出TRAP(input/output TRAP)指令的缩写。系统V的早期版本,由abort函数产生此信号。SIGABRT现在被用于此。
SIGQUIT 当用户在终端上按退出键(一般采用Ctrl-/)时,产生此信号,并送至前台进
程组中的所有进程。此信号不仅终止前台进程组(如SIGINT所做的那样),同时产生一个core文件。
SIGSEGV 指示进程进行了一次无效的存储访问。
名字SEGV表示“段违例(segmentation violation)”。
SIGSYS 指示一个无效的系统调用。由于某种未知原因,进程执行了一条系统调用指令,
但其指示系统调用类型的参数却是无效的。
SIGTRAP 指示一个实现定义的硬件故障。
此信号名来自于PDP-11的TRAP指令。
SIGXCPU SVR4和4.3+BSD支持资源限制的概念。如果进程超过了其软C P U时间限制,则产生此信号。
SIGXFSZ 如果进程超过了其软文件长度限制,则SVR4和4.3+BSD产生此信号。
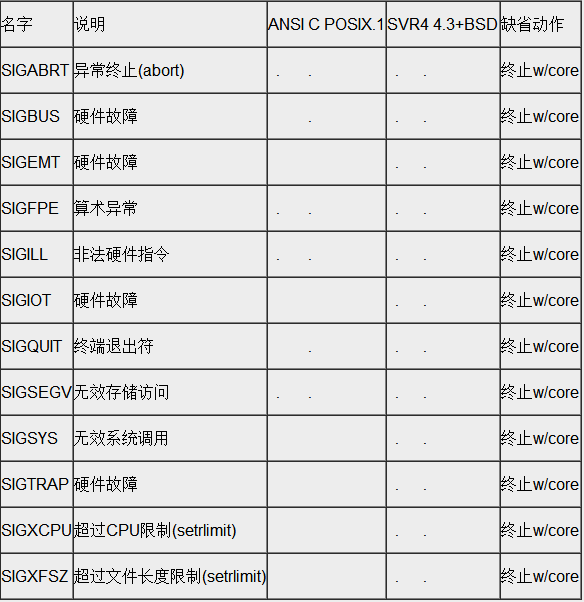
摘自《UNIX环境高级编程》第10章 信号。
例子:
#include <stdio.h>
#include <string.h>
int func(char **a)
{
a[0]="abc"; //有多少次赋值是不确定的,就是说字符串个数不定
a[1]="def";
a[2]="ghi";
}
int main()
{
char** array;
printf("array=%d\n",array);
func(array);
printf("array[0]=%s\n",array[0]);
printf("array[1]=%s\n",array[1]);
}[zhanghua@localhost core_dump]$ gcc –g core_dump_test.c -o core_dump_test
如果需要调试程序的话,使用gcc编译时加上-g选项,这样调试core文件的时候比较容易找到错误的地方。
执行:
[zhanghua@localhost core_dump]$ ./core_dump_test
段错误
运行core_dump_test程序出现了“段错误”,但没有产生core文件。这是因为系统默认core文件的大小为0,所以没有创建。可以用ulimit命令查看和修改core文件的大小。
[zhanghua@localhost core_dump]$ ulimit -c
0
[zhanghua@localhost core_dump]$ ulimit -c 1000
[zhanghua@localhost core_dump]$ ulimit -c
1000
-c 指定修改core文件的大小,1000指定了core文件大小。也可以对core文件的大小不做限制,如:
[zhanghua@localhost daemon]# ulimit -c unlimited
[zhanghua@localhost daemon]# ulimit -c
unlimited
如果想让修改永久生效,则需要修改配置文件,如.bash_profile、/etc/profile或/etc/security/limits.conf。
再次执行:
[zhanghua@localhost core_dump]$ ./core_dump_test
段错误 (core dumped)
[zhanghua@localhost core_dump]$ ls core.*
core.6133
可以看到已经创建了一个core.6133的文件.6133是core_dump_test程序运行的进程ID。
调式core文件
core文件是个二进制文件,需要用相应的工具来分析程序崩溃时的内存映像。
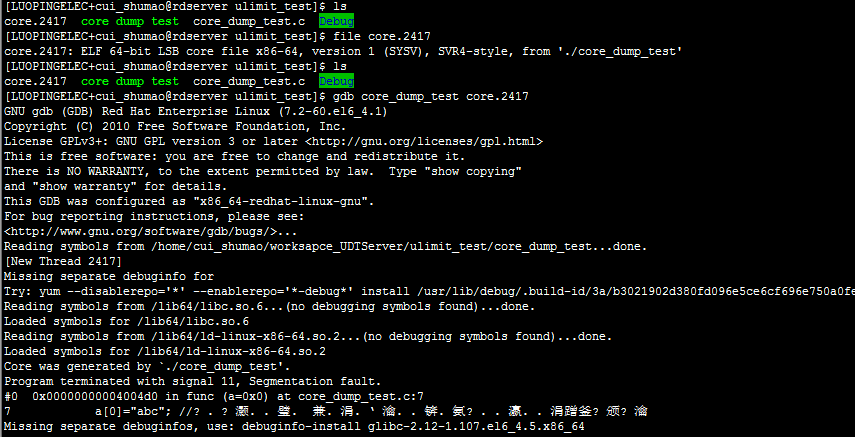
GDB中键入where,就会看到程序崩溃时堆栈信息(当前函数之前的所有已调用函数的列表(包括当前函数),gdb只显示最近几个),我们很容易找到我们的程序在最后崩溃的时候调用了core_dump_test.c 第7行的代码,导致程序崩溃。注意:在编译程序的时候要加入选项-g。您也可以试试其他命令, 如 fram、list等。更详细的用法,请查阅GDB文档。
core文件创建在什么位置
在进程当前工作目录的下创建。通常与程序在相同的路径下。但如果程序中调用了chdir函数,则有可能改变了当前工作目录。这时core文件创建在chdir指定的路径下。有好多程序崩溃了,我们却找不到core文件放在什么位置。和chdir函数就有关系。当然程序崩溃了不一定都产生core文件。
什么时候不产生core文件
在下列条件下不产生core文件:
( a )进程是设置-用户-ID,而且当前用户并非程序文件的所有者;
( b )进程是设置-组-ID,而且当前用户并非该程序文件的组所有者;
( c )用户没有写当前工作目录的许可权;
( d )文件太大。core文件的许可权(假定该文件在此之前并不存在)通常是用户读/写,组读和其他读。
利用GDB调试core文件,当遇到程序崩溃时我们不再束手无策。
第六、C++初始化列表以及顺序
在C++中,构造函数有个特殊的初始化方式叫“初始化表达式表”(简称初始化表)。初始化表位于函数参数表之后,却在函数体 {} 之前。
这说明该表里的初始化工作发生在函数体内的任何代码被执行之前。
构造函数初始化表的使用规则:
1.如果类存在继承关系,派生类必须在其初始化表里调用基类的构造函数。
例如
class A
{…
A(int x); // A 的构造函数
};
class B : public A
{…
B(int x, int y);// B 的构造函数
};
B::B(int x, int y): A(x) // 在初始化表里调用A 的构造函数
{
…
}
2.类的const 常量只能在初始化表里被初始化,因为它不能在函数体内用赋值的方式
来初始化
class Shape
{
const int m_size; //const 常量
float m_width;
float m_height;
public:
Shape(int s,float w,float h):m_size(s) //只能在这初始化
{
//m_size =s; //在初始化将出错
m_width = w;
m_height = h;
}
};
3. 类的数据成员的初始化可以采用初始化表或函数体内赋值两种方式,这两种方式的效率不完全相同。
方式一:在初始化列表中初始化
class Line
{
.........
};
class Shape
{
float m_width;
float m_height;
Line m_line;
public:
Shape(float w,float h,Line line):m_line(line)
{
m_width = w;
m_height = h;
}
};
方式二:在构造函数内部初始化
class Line
{
.........
};
class Shape
{
float m_width;
float m_height;
Line m_line;
public:
Shape(float w,float h,Line line)
{
m_line = line;
m_width = w;
m_height = h;
}
};
二者区别在与:前者效率高于后者,因为前者只调用拷贝构造函数,而后者调用了构造和拷贝构造函数.
简单总结三条:(使用初始化列表)
a.类存在继承关系;
b.类的const常量;
c.类的数据成员的初始化(非内部数据类型的成员对象).
关于顺序是:按照C++类成员的定义顺序来初始化。
例如:
class A
{
int i;
int j;
};
A::A():i(j),j(100)
{
}
这样的初始化i得到未知的数字,不能得到100.
第七、STL容器是不是线程安全的?
第12条:切勿对 STL容器的线程安全性有不切实际的依赖。
STL的实现,是部分线程安全的。就是说,对容器和iostream,如果不同线程同时读同一容器对象线程安全。不同线程同时写同一容器的不同对象,线程安全。但不同线程同时读写同一对象,必须在外面自己做线程互斥和同步。
标准 C++的世界相当狭小和古旧。在这个纯净的世界中,所有的可执行程序都是静态链接的。不存在内存映像文件或共享内存。没有窗口系统,没有网络,没有数据库,也没有其他进程。考虑到这一点,当你得知 C++标准对线程只字未提时,你不应该感到惊讶。于是,你对 STL的线程安全性的第一个期望应该是,它会因不同实现而异。
当然,多线程程序是很普遍的,所以多数 STL提供商会尽量使自己的实现可在多线程环境下工作。然而,即使他们在这一方面做得不错,多数负担仍然在你的肩膀上。理解为什么会这样是很重要的。STL提供商对解决多线程问题只能做很有限的工作,你需要知道这一点。
在 STL容器中支持多线程的标准(这是多数提供商们所希望的)已经为 SGI所确定,并在它们的 STL Web站点[21]上发布。概括来说,它指出,对一个 STL实现你最多只能期望:
多个线程读是安全的。多个线程可以同时读同一个容器的内容,并且保证是正确的。自然地,在读的过程中,不能对容器有任何写入操作。
多个线程对不同的容器做写入操作是安全的。多个线程可以同时对不同的容器做写入操作。
就这些。我必须指明,这是你所能期望的,而不是你所能依赖的。有些实现提供了这些保证,有些则没有。
写多线程的代码并不容易,许多程序员希望 STL的实现能提供完全的线程安全性。如果是这样的话,程序员可以不必再考虑自己做同步控制。这无疑是很方便的,但要做到这一点将会很困难。考虑当一个库试图实现完全的容器线程安全性时可能采取的方式:
对容器成员函数的每次调用,都锁住容器直到调用结束。
在容器所返回的每个迭代器的生存期结束前,都锁住容器(比如通过 begin或 end调用)。
对于作用于容器的每个算法,都锁住该容器,直到算法结束(实际上这样做没有意义。因为,如同将在第 32条中解释的,算法无法知道它们所操作的容器。尽管如此,在这里我们仍要讨论这一选择。因为即便这是可能的,我们也会发现这种做法仍不能实现线程安全性,这对于我们的讨论是有益的)。
现在考虑下面的代码。它在一个 vector<int>中查找值为 5的第一个元素,如果找到了,就把该元素置为 0。
vector<int> v;
...
vector<int>::iterator first5(find(v.begin(), v.end(), 5)); //第 1行
if (first5 != v.end()){ //第 2行
*first5 = 0; //第 3行
}
在一个多线程环境中,可能在第 1行刚刚完成后,另一个不同的线程会更改 v中的数据。如果这种更改真的发生了,那么第 2行对 first5和 v.end是否相等的检查将会变得没有意义,因为 v的值将会与在第 1行结束时不同。事实上,这一检查会产生不确定的行为,因为另外一个线程可能会夹在第 1行和第 2行中间,使 first5变得无效,这第二个线程或许会执行一个插入操作使得 vector重新分配它的内存(这将会使 vector所有的迭代器变得无效。关于重新分配的细节,请参见第 14条)。类似地,第 3行对*first5的赋值也是不安全的,因为另一个线程可能在第 2行和第 3行之间执行,该线程可能会使 first5无效,例如可能会删除它所指向的元素(或者至少是曾经指向过的元素)。
上面所列出的加锁方式都不能防止这类问题的发生。第 1行中对 begin和 end的调用都返回得太快了,所以不会有任何帮助,它们生成的迭代器的生存期直到该行结束, find也在该行结束时返回。
上面的代码要做到线程安全, v必须从第 1行到第 3行始终保持在锁住状态,很难想象一个 STL实现能自动推断出这一点。考虑到同步原语(例如信号量、互斥体等)通常会有较高的开销,这就更难想象,一个 STL实现如何既能够做到这一点,同时又不会对那些在第 1行和第 3行之间本来就不会有另外线程来访问 v的程序(假设程序就是这样设计的)造成显著的效率影响。
这样的考虑说明了为什么你不能指望任何 STL实现来解决你的线程难题。相反,在这种情况下,必须手工做同步控制。在这个例子中,或许可以这样做:
想要使用STL时是线程安全的,需要自己处理而不是依赖STL的实现。可以手工做同步控制,如下面:
vector<int> v;
...
getMutexFor(v);
vector<int>::iterator first5(find(v.begin(),v.end(),5));
if(first5!=v.end())
{
*first5=0;
}
releaseMutexFor(v);
但是这种方法,可能忘了调用releaseMutexFor,这样这个互斥锁就永远也不会被释放。更为面向对象的方法是创建一个Lock类,它在构造函数中获得一个互斥体,在析构函数中释放它,从而尽可能减少getMutexFor调用,没有调用相应的releaseMutexFor调用的可能性。这样的类(实际上是一个类模板)看起来大概是:
template<typename Container>
class Lock{
public:
Lock(const Container& container ):c(container)
{
getMutexFor(c);
}
~Lock()
{
ReleaseMutexFor(c);
}
private:
const Container& c;
};
vector<int>v;
...
{ //创建新的代码块
Lock<vector<int> >lock(v); //创建互斥体
vector<int>::iterator first5(find(v.begin(),v.end(),5));
if (first5!=v.end())
{
*first5=0;
}
} //代码块结束,自动释放互斥体
即使不创建新的代码块,在作用域结束,对象自动析构,只不过可能晚一点,但是如果是忘了调用releaseMutexFor,则永远不会释放互斥体。
因为 Lock对象在其析构函数中释放容器的互斥体,所以很重要的一点是,当互斥体应该被释放时,Lock就要被析构。为了做到这一点,我们创建了一个新的代码块( block),在其中定义了 Lock,当不再需要互斥体时就结束该代码块。看起来好像是我们把“调用 releaseMutexFor”这一任务换成了“结束代码块”,事实上这种说法是不确切的。如果我们忘了为 Lock创建新的代码块,则互斥体仍然会被释放,只不过会晚一些——当控制到达包含 Lock的代码块末尾时。而如果我们忘记了调用 releaseMutexFor,那么我们永远也不会释放互斥体。
而且,基于 Lock的方案在有异常发生时也是强壮的。 C++保证,如果有异常被抛出,局部对象会被析构,所以,即便在我们使用 Lock对象的过程中有异常抛出, Lock仍会释放它所拥有的互斥体 。如果我们依赖于手工调用 getMutexFor和 releaseMutexFor,那么,当在调用 getMutexFor之后而在调用 releaseMutexFor之前有异常被抛出时,我们将永远也无法释放互斥体。
异常和资源管理虽然很重要,但它们不是本条款的主题。本条款是讲述 STL中的线程安全性的。当涉及 STL容器和线程安全性时,你可以指望一个 STL库允许多个线程同时读一个容器,以及多个线程对不同的容器做写入操作。你不能指望 STL库会把你从手工同步控制中解脱出来,而且你不能依赖于任何线程支持。
. 已经证实存在一个漏洞。如果该异常根本没有被捕获到,那么程序将终止。在这种情况下,局部对象(如 lock)可能还没有让它们的析构函数被调用到。有些编译器会调用它们,有些编译器不会。这两种情况都是有效的。
第八、C++泛型编程
c++模板与泛型编程基础
泛型编程就是以独立于任何特定类型的方式编写代码,而模板是泛型编程的基础。
(1)定义函数模板(function template)
函数模板是一个独立于类型的函数,可以产生函数的特定类型版本。
// implement strcmp-like generic compare function
template <typename T>
int compare(const T &v1, const T &v2)
{
if (v1 < v2) return -1;
if (v2 < v1) return 1;
return 0;
}
模板定义以关键字template开始,后接尖括号括住的模板形参表。
模板形参可以是表示类型的类型形参(type parameter),也可以是表示常量表达式的非类型形参(nontype parameter)。上面程序中的T是类型形参。
// compiler instantiates int compare(const int&, const int&)
cout << compare(1, 0) << endl;
// compiler instantiates int compare(const string&, const string&)
string s1 = “hi”, s2 = “world”;
cout << compare(s1, s2) << endl;
使用函数模板时,编译器会将模板实参绑定到模板形参。编译器将确定用什么类型代替每个类型形参,用什么值代替每个非类型形参,然后产生并编译(称为实例化)该版本的函数。
上面的例子中,编译器用int代替T创建第一个版本,用string代替T创建第二个版本。
函数模板也可以声明为inline。
// inline specifier follows template parameter list
template <typename T> inline T min(const T&, const T&);
(2)定义类模板(class template)
在定义的类模板中,使用模板形参作为类型或值的占位符,在使用类时再提供具体的类型或值。
template <typename Type>
class Queue
{
public:
Queue();
Type & front();
const Type & front() const;
void push(const Type &);
void pop();
bool empty() const;
private:
// …
};
与调用函数模板不同,使用类模板时,必须为模板形参显示指定实参。
Queue<int> qi; // Queue that holds ints
Queue<string> qs; // Queue that holds strings
(3)模板类型形参
类型形参由关键字class或typename后接说明符构成。在函数模板形参表中,二者含义相同。typename其实比class更直观,更清楚的指明后面的名字是一个类型名(包括内置类型),而class很容易让人联想到类声明或类定义。
此外,在使用嵌套依赖类型(nested depended name)时,必须用到typename关键字。
在类的内部可以定义类型成员。如果要在函数模板内部使用这样的类型,必须显示告诉编译器这个名字是一个类型,否则编译器无法得知它是一个类型还是一个值。默认情况下,编译器假定这样的名字指定(静态)数据成员,而不是类型。所以下面这段程序,如果去掉typename关键字,将会出现编译错误。
template <typename Parm, typename U>
Parm fcn(Parm *array, U value)
{
typename Parm::size_type * p;
}
(4)非类型模板形参
模板形参也可以是非类型形参,在使用时非类型形参由常量表达式代替。
// initialize elements of an array to zero
template <typename T, size_t N>
void array_init(T (&parm)[N])
{
for (size_t i = 0; i != N; ++i)
parm[i] = 0;
}
…
int x[42];
double y[10];
array_init(x); // instantiates array_init(int (&)[42])
array_init(y); // instantiates array_init(double (&)[10])
(5)编写泛型程序
模板代码需要对使用的类型做一些假设,比如上面的compare()要求类型T重载了“<”操作符。所以函数模板内部完成的操作就限制了可用于实例化该函数的类型。
编写模板代码时,对实参类型的要求应尽可能少。比如compare()函数仅使用了“<”操作符,而没有使用“>”操作符。
第九、引用和指针的区别
1.从现象上看:指针在运行时可以改变其所指向的值,而引用一旦和某个对象绑定后就不再改变
2.从内存分配上看:程序为指针变量分配内存区域,而引用不分配内存区域
3.从编译上看:程序在编译时分别将指针和引用添加到符号表上,符号表上记录的是变量名及变量所对应地址。指针变量在符号表上对应的地址值为指针变量的地址值,而引用在符号表上对应的地址值为引用对象的地址值。符号表生成后就不会再改,因此指针可以改变指向的对象(指针变量中的值可以改),而引用对象不能改。
第十、C中不安全的函数
C里操作字符串很高效,但也很麻烦。
1. char * strcpy ( char * destination, const char * source );
最常用的函数,但是却不安全,原因在于,一是要destination有足够的空间,二是要保证source和destination指向的空间没有overlap。
2. int sprintf ( char * str, const char * format, ... );
也许要问,这个怎么用于字符串拷贝呢?可以这么用 sprintf(dest, "%s", src); 但是要调用者保证dest有足够的内存存放src。
3. char * strncpy ( char * destination, const char * source, size_t num );
比起strcpy,多了个长度的控制。从source拷贝num个字符到destination。如果source里不够num字符怎么办呢?会补充0。
一个典型的用法是:
char buf[MAX];
strncpy(buf, src, MAX-1);
这段代码的本意是,一个长为MAX的buf,最多也就放MAX-1个字符,最后一个位置放‘\0'。因此最多能从src里拷贝MAX-1个字符,如果src里没这么多,剩余的填充0就是了。
但是这样做就安全了么?不是,如果src刚好MAX-1个字符。注意到strncpy只复制了MAX-1个字符,最后一个位置未知,有潜在的隐患。下段代码可以诠释:
#define MAX 4
char buf[MAX];
char* src="123";
// solution 1. memset(buf, 0, MAX);
strncpy(buf, src, MAX-1);
// solution 2. buf[MAX-1] = '\0';
printf("%s\n", buf);
有两个办法可以解决:
1. 调用strncpy之前memset为0,有点浪费。
2. 在strncpy之后对最后一个字符赋值为0。都可以,但不够优雅。
4. int snprintf( char *buffer, int buff_size, const char *format, ... );
用作字符串拷贝的用法:
char buf[MAX];
snprintf(buf, sizeof(buf), "%s", src);
即安全,又简洁。
你可能会关心:如果src的长度大于dest(buf)呢?这个是另外一个问题,这里需要的是安全的字符串拷贝,在C语言里,如果一个字符串指针指向的内存没有结尾字符'\0',是非常危险的。
snprintf会把buf的最后一个位置保留为'\0'。
关于返回值:如果当前buf够用,返回实际写入的字符数;如果不够用,返回将要写入的字符数。换句话说,返回值就是传入的字符数目。
假设当前的buf[4].
待写入 实际写入 返回值
12 12 2 够用
123 123 3 够用
1234 123 4 不够用
12345 123 5 不够用
sprintf/snprintf的另外一个用法:
itoa不是ANSI C或C++的一部分,可以变相的用sprintf来代替:
sprintf(str,"%d",value) 转换为十进制数值。
sprintf(str,"%x",value) 转换为十六进制数值。
sprintf(str,"%o",value) 转换为八进制数值。
总结:
做边界检查,防止溢出;小心的把一个大的数据块传递给一个函数;
C大多数注重的是效率,但是程序员对于安全性问题要保持警惕。
微软函数库对C标准函数库的改进。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









