





cms基于nodejs
This case study explains how I added the capability of working offline to a website, based on Grav, a great PHP-based CMS for developers, by introducing a set of technologies grouped under the name of Progressive Web Apps (in particular Service Workers and the Cache API).
本案例研究说明了我如何通过引入以渐进式Web应用程序(特别是Service Workers和Windows Server 2003)命名的一组技术,基于Grav(一种基于PHP的出色CMS开发人员)为网站添加了脱机工作功能。 缓存API )。
When we’re finished, we’ll be able to use our site on a mobile device or on a desktop, even if offline, like shown here below (notice the “Offline” option in the network throttling settings)
完成后,即使离线,我们也可以在移动设备或台式机上使用我们的网站,如下所示(请注意网络限制设置中的“离线”选项)

第一种方法:缓存优先 (First approach: cache-first)
I first approached the task by using a cache-first approach. In short, when we intercept a fetch request in the Service Worker, we first check if we have it cached already. If not, we fetch it from the network. This has the advantage of making the site blazing fast when loading pages already cached, even when online - in particular with slow networks and lie-fi - but also introduces some complexity in managing updating the cache when I ship new content.
我首先使用缓存优先的方法来完成任务。 简而言之,当我们在Service Worker中拦截获取请求时,我们首先检查是否已经缓存了该请求。 如果没有,我们将从网络上获取它。 这样做的优点是,即使在联机时(尤其是网络速度较慢和lie-fi速度较慢的情况下),即使加载了已缓存的页面,该网站也能使网站快速运行,而且当我发布新内容时,也会在管理更新缓存方面带来一些麻烦。
This will not be the final solution I adopt, but it’s worth going through it for demonstration purposes.
这不是我采用的最终解决方案,但值得进行演示。
I’ll go through a couple phases:
我将经历几个阶段:
- I introduce a service worker and load it as part of the website JS scripts 我介绍了一个服务工作者,并将其作为网站JS脚本的一部分进行加载
when installing the service worker, I cache the site skeleton
安装服务工作者时,我缓存了站点框架
- I intercept requests going to additional links, caching it 我拦截去其他链接的请求,将其缓存
介绍服务人员 (Introducing a service worker)
I add the service worker in a sw.js file in the site root. This allows it to work on all the site subfolders, and on the site home as well. The SW at the moment is pretty basic, it just logs any network request:
我将服务工作者添加到站点根目录的sw.js文件中。 这使它可以在所有站点子文件夹以及站点主页上工作。 目前,SW非常简单,它仅记录任何网络请求:
self.addEventListener('fetch', (event) => {
console.log(event.request)
})I need to register the service worker, and I do this from a script that I include in every page:
我需要注册服务工作者,而这是通过每个页面中包含的脚本来完成的:
window.addEventListener('load', () => {
if (!navigator.serviceWorker) {
return
}
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
//...ok
}).catch((err) => {
console.log('registration failed', err)
})
})If service workers are available, we register the sw.js file and the next time I refresh the page it should be working fine:
如果有服务人员可用,我们将注册sw.js文件,下次我刷新页面时,它将正常工作:
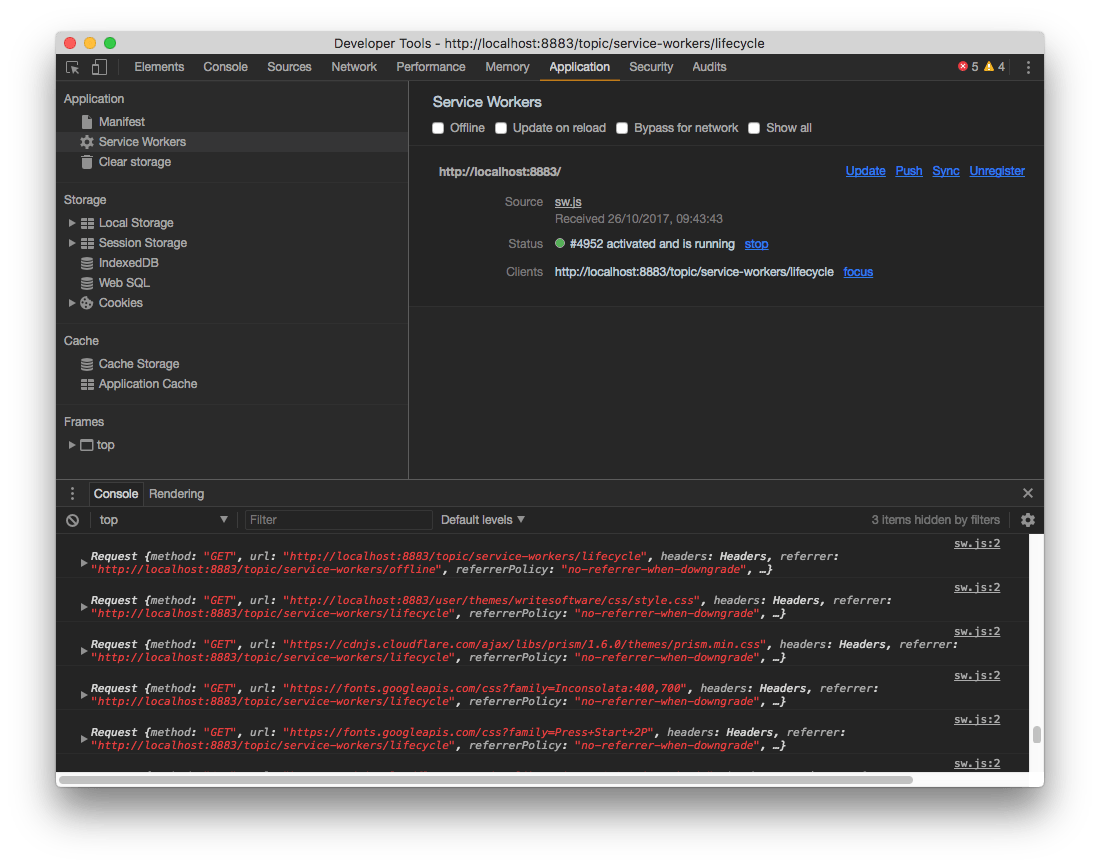
At this point I need to do some heavy lifting on the site. First of all, I need to come up with a way to serve only the App Shell: a basic set of HTML + CSS and JS that will be always available and shown to the users, even when offline.
此时,我需要在现场进行一些繁重的工作。 首先,我需要提出一种仅服务于App Shell的方法 :一套基本HTML + CSS和JS,即使离线也可以始终显示并显示给用户。
It’s basically a stripped down version of the website, with a <div class="wrapper row" id="content-wrapper"></div> empty element, which we’ll fill with content later, available under the /shell route:
它基本上是网站的精简版,带有<div class="wrapper row" id="content-wrapper"></div>空元素,稍后我们将在/shell路径下填充内容。 :

So the first time the user loads the site, the normal version will be shown (full-HTML version), and the service worker is installed.
因此,当用户第一次加载网站时,将显示普通版本(完整HTML版本),并安装了服务工作程序。
Now any other page that is clicked is intercepted by our Service Worker. Whenever a page is loaded, we load the shell first, and then we load a stripped-down version of the page, without the shell: just the content.
现在,单击的任何其他页面都会被我们的服务人员拦截。 每当加载页面时,我们都会先加载外壳,然后再加载页面的精简版本,而无需外壳:仅包含内容。
How?
怎么样?
We listen for the install event, which fires when the Service Worker is installed or updated, and when this happens we initialize the cache with the content of our shell: the basic HTML layout, plus some CSS, JS and some external assets:
我们监听install事件,该事件在安装或更新Service Worker时触发,并在发生这种情况时,使用外壳程序的内容(基本HTML布局以及一些CSS,JS和一些外部资源)初始化缓存。
const cacheName = 'writesoftware-v1'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(cacheName).then(cache => cache.addAll([
'/shell',
'user/themes/writesoftware/favicon.ico',
'user/themes/writesoftware/css/style.css',
'user/themes/writesoftware/js/script.js',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})Then when we perform a fetch, we intercept requests to our pages, and fetch the shell from the Cache instead of going to the network.
然后,当我们执行获取操作时,我们将拦截对页面的请求,然后从缓存获取外壳程序,而不是去网络。
If the URL belongs to Google Analytics or ConvertKit I avoid using the local cache, and I fetch them without using CORS, since they deny accessing them through this method.
如果该网址属于Google Analytics(分析)或ConvertKit,则避免使用本地缓存,并且不使用CORS来获取它们,因为它们拒绝通过此方法访问它们。
Then, if I’m requesting a local partial (just the content of a page, not the full page) I just issue a fetch request to get it.
然后,如果我要本地局部请求(只是页面的内容,而不是整个页面的内容),我只是发出获取请求来获取它。
If it’s not a partial, we return the shell, which is already cached when the Service Worker is first installed.
如果不是局部的,则返回外壳,该外壳在首次安装Service Worker时已经被缓存。
Once the fetch is done, I cache it.
提取完成后,我将其缓存。
self.addEventListener('fetch', (event) => {
const requestUrl = new URL(event.request.url)
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// don't cache, and no cors
event.respondWith(fetch(event.request.url, { mode: 'no-cors' }))
return
}
event.respondWith(caches.match(event.request)
.then((response) => {
if (response) { return response }
if (requestUrl.origin === location.origin) {
if (requestUrl.pathname.endsWith('?partial=true')) {
return fetch(requestUrl.pathname)
} else {
return caches.match('/shell')
}
return fetch(`${event.request.url}?partial=true`)
}
return fetch(event.request.url)
})
.then(response => caches.open(cacheName).then((cache) => {
cache.put(event.request.url, response.clone())
return response
}))
.catch((error) => {
console.error(error)
}))
})Now, I edit the script.js file to introduce an important feature: whenever a link is clicked on my pages, I intercept it and I issue a message to a Broadcast Channel.
现在,我编辑script.js文件以引入一个重要功能:每当单击页面上的链接时,我都会拦截它,并向广播频道发出消息。
Since Service Workers are currently only supported in Chrome, Firefox and Opera, I can safely rely on the BroadcastChannel API for this.
由于目前仅在Chrome,Firefox和Opera中支持Service Worker,因此我可以安全地依靠BroadcastChannel API 。

First, I connect to the ws_navigation channel and I attach a onmessage event handler on it. Whenever I receive an event, it’s a communication from the Service Worker with new content to show inside the App Shell, so I just lookup the element with id content-wrapper and I put the partial page content into it, effectively changing the page the user is seeing.
首先,我连接到ws_navigation通道,并在其上附加onmessage事件处理程序。 每当我收到事件时,它都是来自Service Worker的通信,其中包含要显示在App Shell中的新内容,因此我只需查找具有id content-wrapper的元素,然后将部分页面内容放入其中,从而有效地更改了用户的页面正在看到。
As soon as the Service Worker is registered I issue a message to this channel, with a fetchPartial task and a partial page URL to fetch. This is the content of the initial page load.
注册Service Worker之后,我会立即向此频道发出一条消息,其中包含fetchPartial任务和要提取的部分页面URL。 这是初始页面加载的内容。
The shell is loaded immediately, since it’s always cached and soon after, the actual content is looked up, which might be cached as well.
立即加载该外壳程序,因为它始终被缓存,并且此后不久,便会查找实际内容,该内容也可能会被缓存。
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
}
}
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
channel.postMessage({
task: 'fetchPartial',
url: `${window.location.pathname}?partial=true`
})
}).catch((err) => {
console.log('SW registration failed', err)
})
})The missing bit is handing a click on the page. When a link is clicked, I intercept the event, halt it and I send a message to the Service Worker to fetch the partial with that URL.
缺少的一点是在页面上的点击。 单击链接后,我将拦截该事件,将其暂停,然后将一条消息发送给Service Worker,以获取该URL的部分信息。
When fetching a partial, I attach a ?partial=true query to tell my backend to only serve the content, not the shell.
当获取局部数据时,我附加一个?partial=true查询以告诉后端仅提供内容,而不提供外壳程序。
window.addEventListener('load', () => {
//...
window.onclick = (e) => {
let node = e.target
while (node !== undefined && node !== null && node.localName !== 'a') {
node = node.parentNode
}
if (node !== undefined && node !== null) {
channel.postMessage({
task: 'fetchPartial',
url: `${node.href}?partial=true`
})
return false
}
return true
}
})Now we just miss to handle this event. On the Service Worker side, I connect to the ws_navigation channel and listen for an event. I listen for the fetchPartial message task name, although I could avoid this condition check as this is the only event that’s being sent here (messages in the Broadcast Channel API are not dispatched to the same page that’s originating them - only between a page and a web worker).
现在,我们只是错过了处理此事件的机会。 在Service Worker端,我连接到ws_navigation通道并监听事件。 我监听了fetchPartial消息任务名称,尽管我可以避免进行这种条件检查,因为这是在此处发送的唯一事件(广播频道API中的消息不会分派到发起它们的同一页面上-仅在页面和网络工作者)。
I check if the url is cached. If so, I just send it as a response message on the channel, and return.
我检查网址是否已缓存。 如果是这样,我只是将其作为响应消息发送到频道,然后返回。
If it’s not cached, I fetch it, send it back as a message to the page, and then cache it for the next time it might be visited.
如果未缓存,则将其提取,作为消息发送回该页面,然后缓存以备下次访问时使用。
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (event.data.task === 'fetchPartial') {
caches
.match(event.data.url)
.then((response) => {
if (response) {
response.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
return
}
fetch(event.data.url).then((fetchResponse) => {
const fetchResponseClone = fetchResponse.clone()
fetchResponse.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
caches.open(cacheName).then((cache) => {
cache.put(event.data.url, fetchResponseClone)
})
})
})
.catch((error) => {
console.error(error)
})
}
}We’re almost done.
我们快完成了。
Now the Service Worker is installed on the site as soon as a user visits, and subsequent page loads are handled dynamically through the Fetch API, not requiring a full page load. After the first visit, pages are cached and load incredibly fast, and - more importantly - then even load when offline!
现在,一旦用户访问,就会在站点上安装Service Worker,并且随后的页面加载是通过Fetch API动态处理的,不需要整个页面加载。 首次访问后,页面的缓存和加载速度非常快,而且-更重要的是-离线时甚至可以加载!
And - all this is a progressive enhancement. Older browsers, and browsers that don’t support service workers, work as normal.
而且-所有这些都是逐步的增强。 较旧的浏览器以及不支持服务人员的浏览器都可以正常工作。
Now, hijacking the browser navigation poses us a few problems:
现在,劫持浏览器导航给我们带来了一些问题:
- the URL must change when a new page is shown. The back button should work normally, and the browser history as well 显示新页面时,URL必须更改。 后退按钮应正常工作,浏览器历史记录也应正常工作
- the page title must change to reflect the new page title 页面标题必须更改以反映新的页面标题
- we need to notify the Google Analytics API that a new page has been loaded, to avoid missing an important metric such as the page views per visitor. 我们需要通知Google Analytics(分析)API已经加载了新页面,以避免丢失重要指标,例如每个访问者的页面浏览量。
- the code snippets are not highlighted any more when loading new content dynamically 动态加载新内容时,代码片段不再突出显示
Let’s solve those challenges.
让我们解决这些挑战。
使用History API修复URL,标题和后退按钮 (Fix URL, title and back button with the History API)
In the message handler in script.js in addition to injecting the HTML of the partial, we trigger the history.pushState() method of the History API:
在script.js的消息处理程序中,除了注入部分HTML之外,我们还触发了History API的history.pushState()方法:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
history.pushState(null, null, url)
}
}This is working but the page title does not change in the browser UI. We need to fetch it somehow from the page. I decided to put in the page content partial a hidden span that keeps the page title, so we can fetch it from the page using the DOM API, and set the document.title property:
这是可行的,但是页面标题在浏览器用户界面中没有更改。 我们需要以某种方式从页面中获取它。 我决定在页面内容中放入一部分隐藏的跨度,以保留页面标题,因此我们可以使用DOM API从页面获取它,并设置document.title属性:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
}
}修复Google Analytics(分析) (Fix Google Analytics)
Google Analytics works fine out of the box, but when loading a page dynamically, it can’t do miracles. We must use the API it provides to inform it of a new page load. Since I’m using the Global Site Tag (gtag.js) tracking, I need to call:
Google Analytics(分析)开箱即用,但是当动态加载页面时,它无法创造奇迹。 我们必须使用它提供的API来通知它新的页面加载。 由于我使用的是全球站点标签( gtag.js )跟踪,因此我需要致电:
gtag('config', 'UA-XXXXXX-XX', {'page_path': '/the-url'})into the code above that handles changing page:
到上面用于处理页面更改的代码中:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-XXXXXX-XX', {'page_path': url})
}
}The last thing I need to fix on my page is the code snippets login their highlighing. I use the Prism syntax highlighter and they make it very easy, I just need to add a call Prism.highlightAll() in my onmessage handler:
我需要在页面上修复的最后一件事是代码片段登录其高亮显示。 我使用Prism语法荧光笔,它们使它非常容易,我只需要在我的onmessage处理程序中添加一个调用Prism.highlightAll() :
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-XXXXXX-XX', {'page_path': url})
Prism.highlightAll()
}
}The full code of script.js is:
script.js的完整代码为:
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-1739509-49', {'page_path': url})
Prism.highlightAll()
}
}
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
channel.postMessage({
task: 'fetchPartial',
url: `${window.location.pathname}?partial=true`
})
}).catch((err) => {
console.log('SW registration failed', err)
})
window.onclick = (e) => {
let node = e.target
while (node !== undefined && node !== null && node.localName !== 'a') {
node = node.parentNode
}
if (node !== undefined && node !== null) {
channel.postMessage({
task: 'fetchPartial',
url: `${node.href}?partial=true`
})
return false
}
return true
}
})and sw.js:
和sw.js :
const cacheName = 'writesoftware-v1'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(cacheName).then(cache => cache.addAll([
'/shell',
'user/themes/writesoftware/favicon.ico',
'user/themes/writesoftware/css/style.css',
'user/themes/writesoftware/js/script.js',
'user/themes/writesoftware/img/offline.gif',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
self.addEventListener('fetch', (event) => {
const requestUrl = new URL(event.request.url)
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// don't cache, and no cors
event.respondWith(fetch(event.request.url, { mode: 'no-cors' }))
return
}
event.respondWith(caches.match(event.request)
.then((response) => {
if (response) { return response }
if (requestUrl.origin === location.origin) {
if (requestUrl.pathname.endsWith('?partial=true')) {
return fetch(requestUrl.pathname)
} else {
return caches.match('/shell')
}
return fetch(`${event.request.url}?partial=true`)
}
return fetch(event.request.url)
})
.then(response => caches.open(cacheName).then((cache) => {
if (response) {
cache.put(event.request.url, response.clone())
}
return response
}))
.catch((error) => {
console.error(error)
}))
})
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (event.data.task === 'fetchPartial') {
caches
.match(event.data.url)
.then((response) => {
if (response) {
response.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
return
}
fetch(event.data.url).then((fetchResponse) => {
const fetchResponseClone = fetchResponse.clone()
fetchResponse.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
caches.open(cacheName).then((cache) => {
cache.put(event.data.url, fetchResponseClone)
})
})
})
.catch((error) => {
console.error(error)
})
}
}第二种方法:网络优先,删除应用程序外壳 (Second approach: network-first, drop the app shell)
While the first approach gave us a fully working app, I was a bit skeptical and worried about having a copy of a page cached for too long on the client, so I decided for a network-first approach: when a user loads a page it is fetched from the network first. If the network call fails for some reason, I lookup the page in the cache to see if we got it cached, otherwise I show the user a GIF if it’s totally offline, or another GIF if the page does not exist (I can reach it but I got a 404 error).
虽然第一种方法为我们提供了一个可以正常运行的应用程序,但我有点怀疑,担心在客户端上缓存页面副本的时间太长,因此我决定采用网络优先的方法:当用户加载页面时,首先从网络中获取。 如果网络呼叫由于某种原因失败,我将在缓存中查找该页面以查看是否将其缓存,否则,如果该用户完全脱机,则向用户显示一个GIF;如果该页面不存在,则向用户显示另一个GIF(可以访问该页面)但出现404错误)。
As soon as we get a page we cache it (not checking if we cached it previously or not, we just store the latest version).
一旦获得页面,我们将对其进行缓存(不检查是否先前已缓存它,我们仅存储最新版本)。
As an experiment I also got rid of the app shell altogether, because in my case I had no intentions of creating an installable app yet, as without an up-to-date Android device I could not really test-drive it and I preferred to avoid throwing out stuff without proper testing.
作为实验,我也完全摆脱了应用程序外壳,因为就我而言,我还没有创建可安装应用程序的意图,因为如果没有最新的Android设备,我将无法真正对其进行测试驱动,因此我倾向于避免在没有适当测试的情况下扔掉东西。
To do this I just stripped the app shell from the install Service Worker event and I relied on Service Workers and the Cache API to just deliver the plain pages of the site, without managing partial updates. I also dropped the /shell fetch hijacking when loading a full page, so on the first page load there is no delay, but we still load partials when navigating to other pages later.
为此,我只是从install Service Worker事件中删除了应用程序外壳,然后依靠Service Workers和Cache API来仅提供网站的纯页面,而不管理部分更新。 加载整个页面时,我还删除了/shell fetch劫持,因此在第一页加载时没有延迟,但是稍后导航到其他页面时,我们仍然加载部分内容。
I still use script.js and sw.js to host the code, with script.js being the file that initializes the Service Worker, and also intercepts click on the client-side.
我仍然使用script.js和sw.js托管代码,而script.js是初始化Service Worker的文件,并且还拦截客户端上的单击。
Here’s script.js:
这是script.js :
const OFFLINE_GIF = '/user/themes/writesoftware/img/offline.gif'
const fetchPartial = (url) => {
fetch(`${url}?partial=true`)
.then((response) => {
response.text().then((body) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = body
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-XXXXXX-XX', { page_path: url })
Prism.highlightAll()
}
})
})
.catch(() => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = `<center><h2>Offline</h2><img src="${OFFLINE_GIF}" /></center>`
}
})
}
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
fetchPartial(window.location.pathname)
}).catch((err) => {
console.log('SW registration failed', err)
})
window.onclick = (e) => {
let node = e.target
while (node !== undefined && node !== null && node.localName !== 'a') {
node = node.parentNode
}
if (node !== undefined && node !== null) {
fetchPartial(node.href)
return false
}
return true
}
})and here’s sw.js:
这是sw.js :
const CACHE_NAME = 'writesoftware-v1'
const OFFLINE_GIF = '/user/themes/writesoftware/img/offline.gif'
const PAGENOTFOUND_GIF = '/user/themes/writesoftware/img/pagenotfound.gif'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(CACHE_NAME).then(cache => cache.addAll([
'/user/themes/writesoftware/favicon.ico',
'/user/themes/writesoftware/css/style.css',
'/user/themes/writesoftware/js/script.js',
'/user/themes/writesoftware/img/offline.gif',
'/user/themes/writesoftware/img/pagenotfound.gif',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
self.addEventListener('fetch', (event) => {
if (event.request.method !== 'GET') return
if (event.request.headers.get('accept').indexOf('text/html') === -1) return
const requestUrl = new URL(event.request.url)
let options = {}
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// no cors
options = { mode: 'no-cors' }
}
event.respondWith(fetch(event.request, options)
.then((response) => {
if (response.status === 404) {
return fetch(PAGENOTFOUND_GIF)
}
const resClone = response.clone()
return caches.open(CACHE_NAME).then((cache) => {
cache.put(event.request.url, response)
return resClone
})
})
.catch(() => caches.open(CACHE_NAME).then(cache => cache.match(event.request.url)
.then((response) => {
if (response) {
return response
}
return fetch(OFFLINE_GIF)
})
.catch(() => fetch(OFFLINE_GIF)))))
})更简单:无局部 (Going simpler: no partials)
As an experiment I dropped the click interceptor that fetches partials, and I relied on Service Workers and the Cache API to just deliver the plain pages of the site, without managing partial updates:
作为一个实验,我删除了获取部分内容的点击拦截器,然后依靠Service Workers和Cache API来仅提供网站的普通页面,而不管理部分更新:
script.js:
script.js :
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).catch((err) => {
console.log('SW registration failed', err)
})
})sw.js:
sw.js :
const CACHE_NAME = 'writesoftware-v1'
const OFFLINE_GIF = '/user/themes/writesoftware/img/offline.gif'
const PAGENOTFOUND_GIF = '/user/themes/writesoftware/img/pagenotfound.gif'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(CACHE_NAME).then(cache => cache.addAll([
'/user/themes/writesoftware/favicon.ico',
'/user/themes/writesoftware/css/style.css',
'/user/themes/writesoftware/js/script.js',
'/user/themes/writesoftware/img/offline.gif',
'/user/themes/writesoftware/img/pagenotfound.gif',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
self.addEventListener('fetch', (event) => {
if (event.request.method !== 'GET') return
if (event.request.headers.get('accept').indexOf('text/html') === -1) return
const requestUrl = new URL(event.request.url)
let options = {}
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// no cors
options = { mode: 'no-cors' }
}
event.respondWith(fetch(event.request, options)
.then((response) => {
if (response.status === 404) {
return fetch(PAGENOTFOUND_GIF)
}
const resClone = response.clone()
return caches.open(CACHE_NAME).then((cache) => {
cache.put(event.request.url, response)
return resClone
})
})
.catch(() => caches.open(CACHE_NAME).then(cache => cache.match(event.request.url)
.then((response) => {
return response || fetch(OFFLINE_GIF)
})
.catch(() => fetch(OFFLINE_GIF)))))
})I think this is the bare bones example of adding offline capabilities to a website, still keeping things simple. Any kind of website can add such Service Worker without too much complexity.
我认为这是向网站添加脱机功能并保持简单的基本示例。 任何类型的网站都可以添加这样的Service Worker,而不会太复杂。
In the end for me this approach was not enough to be viable, and I ended up implementing the version with fetch partial updates.
最后,对我而言,这种方法还不够可行,最终我通过获取部分更新来实现该版本。
cms基于nodejs















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









