





Over the years, JavaScript has continued to gain lots of attention as its increasingly vast capabilities continue to expand. It has grown from being just a client-side scripting language for making cool interactive web interfaces to being used extensively on the server-side, for mobile applications, desktop applications, embedded systems, IOT, and so on. Although there are a wide range of frameworks available to enhance the strengths of a JavaScript developer, learning to work with vanilla JavaScript to do things in the most efficient way is a fundamental skill.
多年来,随着JavaScript越来越强大的功能不断扩展,它一直受到越来越多的关注。 它已经从仅用于制作很酷的交互式Web界面的客户端脚本语言发展到在服务器端广泛用于移动应用程序,桌面应用程序,嵌入式系统,IOT等。 尽管可以使用各种各样的框架来增强JavaScript开发人员的实力,但是学习与原始JavaScript一起以最有效的方式工作是一项基本技能。
In this article you’ll implement two different algorithm approaches using vanilla JavaScript. It’s recommended that you try to do it yourself first and only refer to the code to move in the right direction, confirm your solutions, and study other approaches.
在本文中,您将使用香草JavaScript实现两种不同的算法方法。 建议您首先尝试自己做,仅参考代码朝正确的方向前进,确认您的解决方案,并研究其他方法。
Your challenge is to receive a string of text of any length and return the number of vowels found within the text.
您面临的挑战是接收任意长度的文本字符串,并返回在文本中找到的元音数量。
算法思维 (Algorithmic Thinking)
Reading through the challenge statement, you’ll notice the statement receive a string of text. If you’re quite used to programming in general, this should bring the idea of functions to mind. We could write a function that’d have a parameter called “text”. Text would be a string of any length which would be passed to the function as an argument when it is called.
仔细阅读质询声明,您会发现该声明收到了字符串text 。 如果您通常已经习惯了编程,那么应该想到函数的想法。 我们可以编写一个具有名为“文本”的参数的函数。 文本可以是任意长度的字符串,在调用时将作为参数传递给函数。
Next, within the function we have to go through the text and search for occurrences of the English vowels (“a”, “e”, “i”, “o”, “u”). The function then returns the total number of matches (vowels) found. You can stop the execution of a function and return a value from that function with return statements.
接下来,在函数中,我们必须遍历文本并搜索出现的英语元音(“ a”,“ e”,“ i”,“ o”,“ u”)。 然后,该函数返回找到的匹配项(元音)的总数。 您可以停止执行函数,并使用return语句从该函数return值。
代码实施 (Code Implementation)
We’ll explore two ways to implement this. First an iterative approach and then the use of regular expressions.
我们将探索两种实现方法。 首先是一种迭代方法,然后是正则表达式的使用。
迭代方法 (An Iterative Approach)
In the iterative approach, we’ll loop through each letter of the string passed and then check to see if they match any of the vowels. Before running through the text we would have a counter initialized and assigned a value of zero. In a case where there’s a match, we increment the counter.
在迭代方法中,我们将遍历传递的字符串的每个字母,然后检查它们是否与任何元音匹配。 在遍历文本之前,我们将初始化一个计数器并将其分配为零。 如果有比赛,我们增加计数器。
Here’s our implementation:
这是我们的实现:
/_
An iterative approach to counting the number of vowels in a
string of text.
_/
const vowels = ["a", "e", "i", "o", "u"]
function countVowelsIterative(text) {
// Initialize counter
let counter = 0;
// Loop through text to test if each character is a vowel
for (let letter of text.toLowerCase()){
if (vowels.includes(letter)) {
counter++
}
}
// Log formatted response to console
console.log(`The text contains ${counter} vowel(s)`)
// Return number of vowels
return counter
}
/_
============== Test Case ===================
_/
countVowelsIterative('I am a world-class developer using iterations');
// Logs "The text contains 16 vowel(s)" to the console
// returns 16First, we declared a constant
vowelswhich contained an array of the five English vowels.首先,我们声明一个恒定的
vowels,其中包含五个英语元音的数组。Next, we make use of a
for…ofloop to iterate through each letter of the text. If you’re not conversant with this, afor…ofloop creates a loop iterating over iterable objects. Iterable objects could be strings, arrays, maps, sets, and so on.接下来,我们使用
for…of循环遍历文本的每个字母。 如果您对此不满意,则for…of循环会创建一个循环遍历可迭代对象的循环。 可迭代对象可以是字符串,数组,映射,集合等。- Notice how we convert all letters of the text to lowercase within the loop. This is because, we don’t want to miss the cases of uppercase vowels within the passed text (trust me that wasn’t intentional). 注意在循环中我们如何将文本的所有字母都转换为小写。 这是因为,我们不想错过所传递文本中大写元音的情况(相信我不是故意的)。
Next within the loop, we use an
ifstatement to check if the selected letter is included in the array of vowels we defined earlier. Fittingly, we call theincludes()method on the array of vowels to determine whether the array includes the selected letter, returningtrueorfalseas appropriate.接下来,在循环中,我们使用
if语句检查所选字母是否包含在我们前面定义的元音数组中。 适当地,我们在元音数组上调用includes()方法以确定该数组是否包含所选字母,并在适当时返回true或false。If the condition evaluates to
true, we increment the counter.如果条件评估为
true,我们将增加计数器。- After looping through we log a formatted message to the console telling us the number of vowels and then return the counter which is equivalent to the number of vowels found. 遍历之后,我们将一条格式化的消息记录到控制台,告诉我们元音的数量,然后返回等于找到的元音数量的计数器。
Now let’s consider another approach.
现在让我们考虑另一种方法。
常用表达 (Regular Expressions)
Regular expressions help us find patterns or characters/character combinations within strings. This is relevant to us because regular expressions will help us find the desired characters within the text passed. By extension, regular expressions can help us to do more remarkable things such as the implementation of content filters. Regular expressions also stay the same across programming languages. Let’s examine the solution.
正则表达式可帮助我们在字符串中查找模式或字符/字符组合。 这与我们有关,因为正则表达式将帮助我们在传递的文本中找到所需的字符。 通过扩展,正则表达式可以帮助我们做更多出色的事情,例如内容过滤器的实现。 正则表达式在各种编程语言中也保持不变。 让我们研究解决方案。
Here’s our implementation:
这是我们的实现:
/_
Using Regular Expressions to count the number of vowels in a
string of text.
_/
function countVowelsRegex(text) {
// Search text with Regex and store all matching instances
let matchingInstances = text.match(/[aeiou]/gi);
// Check if matching instances exist then calculate length
if(matchingInstances) {
// Log formatted response to console
console.log(`The text contains ${matchingInstances.length} vowel(s)`)
// Return number of vowels
return matchingInstances.length
} else{
return 0
}
}
/_
============== Test Case ===================
_/
countVowelsRegex('I am a world-class developer using Regex');
// Logs "The text contains 13 vowel(s)" to the console
// returns 13The first thing we did within the function was to call
thematch()method on the text which returns an array of the matches found after matching the regular expression passed as an argument against the text.我们在函数中所做的第一件事是在文本上调用
thematch()方法,该方法返回匹配作为参数传递给文本的正则表达式后找到的匹配项的数组。The regular expression specifies the letters to be looked for within the brackets
[]. For simple patterns, regular expressions are usually defined within a pair of slashes. Notice the charactersgitrailing the closing slash?正则表达式在括号
[]指定要查找的字母。 对于简单模式,通常在一对斜杠内定义正则表达式。 请注意,字符gi在斜杠后跟?gstands for a global search which does not return after the first match, restarting the subsequent searches from the end of the previous match.g表示在第一个匹配项之后不返回的全局搜索,从上一个匹配项的结尾重新开始后续搜索。istands for case insensitive search which makes the whole expression case-insensitive (for example /xyz/i would match XyZ).i代表不区分大小写的搜索,这使整个表达式不区分大小写(例如/ xyz / i将匹配XyZ)。Next we use a conditional to check if any matching instances were found. The
.match()method used above returns an array of the matched items if matches were found andnullif they weren’t. Hence in the conditional, ifmatchingInstancesevaluates to a truthy value (that is an array of matches found), we log a formatted message showing the number of vowels which is same as the length of the array. Then we return the number as well. On the other hand if it evaluates to a false value, we return0as it means no matches were found.接下来,我们使用条件检查是否找到任何匹配的实例。 如果找到匹配项,则上面使用的
.match()方法将返回匹配项的数组,如果未找到则返回null。 因此,在条件条件下,如果matchingInstances评估为真实值(即找到的匹配项数组),我们将记录一条格式化的消息,该消息显示与该数组的长度相同的元音数量。 然后我们也返回数字。 另一方面,如果它的计算结果为假值,则返回0因为这意味着未找到匹配项。
评估与总结 (Evaluation & Summary)
We have now successfully implemented an algorithm that counts the number of vowels in a string of text in JavaScript.
现在,我们已经成功实现了一种算法,该算法可以计算JavaScript中文本字符串中元音的数量。
Let’s evaluate both methods used. The iterative approach although not as concise as the other can be a more logical approach, especially for beginners. However as the result shows, the regex method is better optimized.
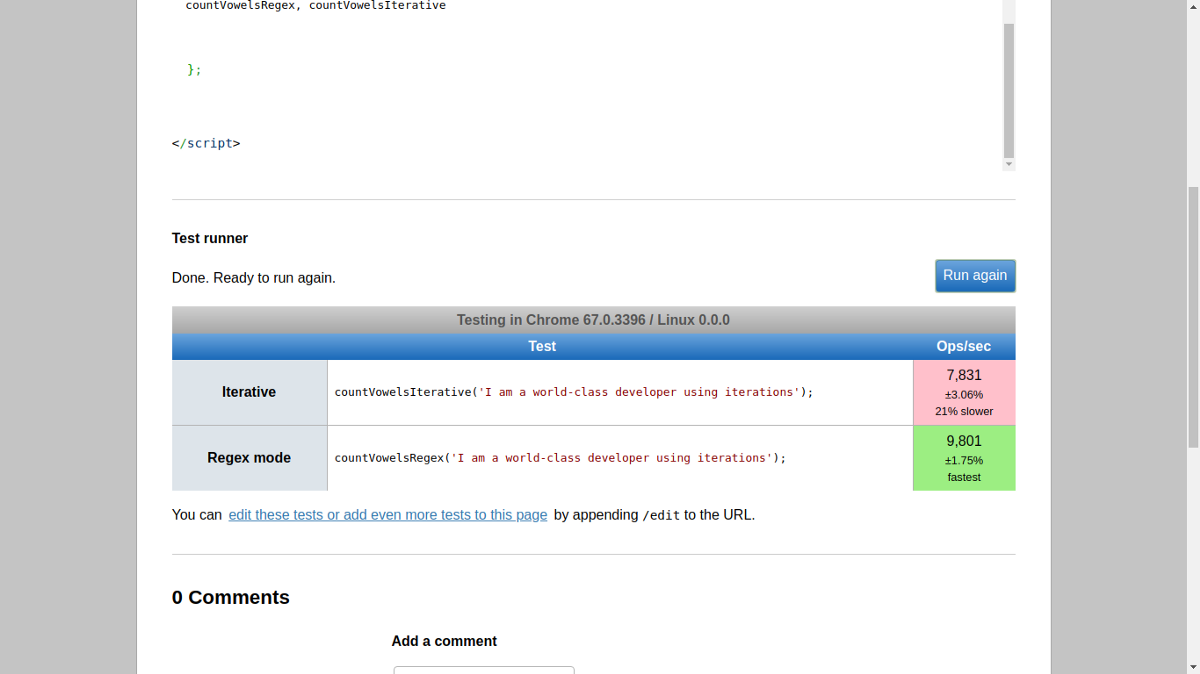
让我们评估使用的两种方法。 迭代方法虽然不像其他方法那么简洁,但它可能是更合乎逻辑的方法,尤其对于初学者而言。 但是,结果表明,正则表达式方法得到了更好的优化。
You can use this test case vowel counter to run the tests yourself.
您可以使用此测试用例的元音计数器自己运行测试。















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









