





A simple search of the Web reveals that there are many programmers who need to work with legacy databases, such as Microsoft Access, but are stumped when confronted with the task of extracting files from Access’s OLE Object field. Part of the problem is the dearth of readily available information about how objects are stored in the OLE field.
对Web的简单搜索显示,有许多程序员需要使用遗留数据库(例如Microsoft Access),但是当面对从Access的OLE Object字段提取文件的任务时,他们陷入了困境。 问题的一部分是缺少有关如何在OLE字段中存储对象的现有信息。
Worse still for the PHP programmer is that every instance of queries posted to forums and support websites are from non-PHP programmers – .Net seems to be the most common, and there are also questions from Java and Delphi programmers.
对于PHP程序员而言,更糟糕的是,发布到论坛和支持网站的查询的每个实例都是非PHP程序员的。.Net似乎是最常见的,还有Java和Delphi程序员的问题。
One thing all of these developers have in common though is the need to extract information from these troublesome OLE fields in order to migrate from a legacy database. But not one article specifically targets for PHP programmers. Nor do any of them address “packages”, only specific data types such as JPEG, PNG, GIF, etc.
所有这些开发人员的共同点是,需要从这些麻烦的OLE字段中提取信息,以便从旧版数据库进行迁移。 但是,没有一篇文章专门针对PHP程序员。 它们中的任何一个也不针对“包”,仅针对诸如JPEG,PNG,GIF等特定数据类型。
In this article we’ll see how PHP can be used to extract objects from two OLE types: packages and Acrobat PDF documents. This is the first part of a two-part series in which we’ll look at OLE packages, which, as we’ll see, can be identified as either “Package” or “Packager Shell Object”. Values expressed in this article are based on an Access 2000 database.
在本文中,我们将了解如何使用PHP从两种OLE类型中提取对象:程序包和Acrobat PDF文档。 这是一个分为两部分的系列文章的第一部分,我们将研究OLE软件包,正如我们将看到的那样,它们可以被标识为“ Package”或“ Packager Shell Object”。 本文中表达的值基于Access 2000数据库。
OLE容器 (OLE Container)
The storage of a blob (binary large object) in a database is never a simple matter, and Microsoft’s Access database is no exception. Let’s summarize some key aspects of the OLE container used when an object is inserted to an OLE field in Access:
在数据库中存储Blob(二进制大对象)绝非易事,Microsoft的Access数据库也不例外。 让我们总结一下将对象插入Access中的OLE字段时使用的OLE容器的一些关键方面:
- No external file would have been inserted to an Access OLE field without first being wrapped in a container. For our purposes, this container can be considered to be a header in front of the object we are interested in and a trailer after it. 如果没有先将外部文件包装在容器中,则不会将任何外部文件插入到Access OLE字段中。 就我们的目的而言,可以将这个容器视为我们感兴趣的对象前面的标头,然后是它后面的预告片。
- The header length is not fixed. Even for the OLE package type the header length can be different depending on the object that is embedded in the container. 标头长度不固定。 即使对于OLE包类型,标头长度也可以不同,具体取决于嵌入在容器中的对象。
- The data is not in a human-readable form, making it harder to visually find crucial items such as the original name of the embedded object, or its name, or the start of the object component. 数据不是人类可读的格式,因此很难从视觉上找到关键项目,例如嵌入对象的原始名称,其名称或对象组件的开头。
- The trailer can be ignored. Our focus here will be on the header and object components. 预告片可以忽略。 我们的重点将放在标题和对象组件上。
One other point: it’s not just the object component that’s encoded, but the header is too. Before we can make any sense of any of the data, the header needs to be decoded first.
另一点:不仅是编码的对象组件,而且标头也是如此。 在我们对任何数据都没有任何意义之前,首先需要对头进行解码。
编码的标题和数据 (Encoded Header and Data)
The test database is defined as simply as possible, with the embedded files contained in the image field of Table1:
测试数据库的定义尽可能简单,其嵌入式文件包含在Table1的image字段中:
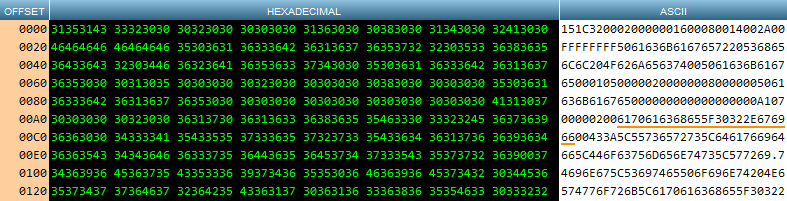
Throughout this worked example, we’ll be using an Apache logo GIF that I stored in the OLE field. Extracting the field contents without decoding, then inspecting the output in a hexadecimal viewer reveals, well, gibberish:
在整个工作示例中,我们将使用存储在OLE字段中的Apache徽标GIF。 提取字段内容而不进行解码,然后在十六进制查看器中检查输出,发现这很乱:
After converting the extracted header from hexadecimal to decimal encoding using PHP’s hex2dec() function we have something more useful:
使用PHP的hex2dec()函数将提取的标头从十六进制编码转换为十进制编码后,我们有一些更有用的功能:
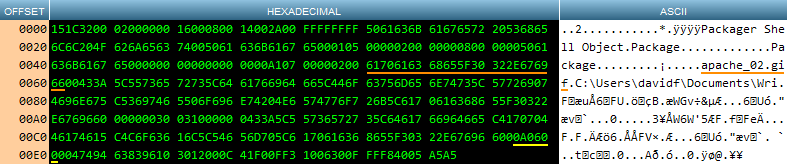
It looks uninviting, but it’s clear that we can now make some sense of the data. To help simplify matters the first 20 bytes can be ignored.
看起来并不诱人,但很显然,我们现在可以对数据有所了解了。 为了简化问题,可以忽略前20个字节。
The next block of characters tells us that the OLE object is of type Packager Shell Object. An OLE package is a general purpose container for those file types not recognized by the database when the files were inserted.
下一个字符块告诉我们OLE对象的类型为Packager Shell Object。 OLE包是用于插入文件时数据库无法识别的那些文件类型的通用容器。
In the words of Professor Farnsworth, “Good news, everyone!” If we look closer at the ASCII column of the hex dump we can see the name of the original file that is embedded in the container – apache_02.gif. This will be useful later when we try to locate the end of the header and the start of the data that we need to extract. Even better, the filename always starts at byte 84 of a Packager Shell Object header and at byte 70 of a Package header.
用范恩斯沃思教授的话说:“大家好!” 如果我们仔细查看十六进制转储的ASCII列,我们可以看到嵌入在容器中的原始文件的名称– apache_02.gif 。 稍后当我们尝试定位标头的末尾和需要提取的数据的开始时,这将很有用。 更好的是,文件名总是从Packager Shell Object标头的字节84和Package标头的字节70开始。
Before moving on to how we extract the GIF from the package, here’s a little teaser: In both of these two hex dumps, there’s the sequence 0A0600 underlined in yellow. For now, accept that 0A0600 is important. We’ll see why in a moment.
在继续介绍如何从包中提取GIF之前,这里有一个小提示:在这两个十六进制转储中,都有用黄色下划线标记的序列0A0600。 目前,接受0A0600很重要。 我们一会儿会明白为什么。
提取对象 (Extracting the Object)
Before we can extract the embedded object, we need to know where it starts and ends in the data. Careful inspection of the hexadecimal representation reveals that the character sequence for the filename occurs three times – once at byte 84 (or 70), then again twice as part of the full path.
在提取嵌入式对象之前,我们需要知道它在数据中的开始和结束位置。 对十六进制表示形式的仔细检查发现,文件名的字符序列出现了三次–一次出现在字节84(或70)处,然后两次出现在完整路径中。
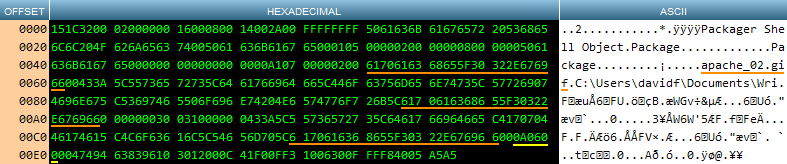
At least, that how it seems in this example. Just to complicate matters, it’s possible that the full path may appear only once. Also, Access may have changed the case of the file path, or changed each level of the file path to old-fashioned 8:3 format (meaning that names longer than 8 character will be truncated, and characters 7 and 8 replaced by ~1).Fortunately there will always be an instance of the full path somewhere around the location of the second full path in this example. “Somewhere around the location?” Just as the header length is not fixed, so too are the locations of the full path. We need to work around these niggles.
至少,在这个例子中看起来是这样。 只是使事情复杂化,完整路径可能只出现一次。 此外,Access可能已更改文件路径的大小写,或将文件路径的每个级别更改为老式的8:3格式(这意味着长度超过8个字符的名称将被截断,而将字符7和8替换为〜1) )。幸运的是,在此示例中,总是在第二条完整路径的位置附近存在完整路径的实例。 “位置附近?” 正如报头长度不是固定的一样,完整路径的位置也是如此。 我们需要解决这些问题。
“More good news, everyone!” The final instance of the filename is the second last important item of interest in the header. It is null-terminated (00), after which is the hexadecimal sequence 0A0600 we saw earlier. This the original size in bytes of the embedded object. It’s stored in little-endian format, so this needs to be reversed to big-endian before we can use it: 0A0600 becomes 00060A, which means 1,546 bytes. This group of three bytes gives a maximum allowable embedded file size of 16 MB.
“更多的好消息,大家!” 文件名的最后一个实例是标题中倒数第二个重要的重要项目。 它以零结尾(00),之后是我们之前看到的十六进制序列0A0600。 这是嵌入式对象的原始大小(以字节为单位)。 它以little-endian格式存储,因此在使用之前必须将其反转为big-endian:0A0600变为00060A,这意味着1,546字节。 这三个字节的组提供的最大允许嵌入文件大小为16 MB。
After this sequence is the object we need. It starts with the character sequence 474946383961. Converting this to ASCII yields “GIF89a”. It doesn’t show in the ASCII column because Access does not store data in the OLE header in consistent two-character blocks. That’s why the first instance of the full path displays nicely up to “DocumentsWri” then goes awry. In this example, the character after “Wri” ought to be “t” as in “Writing” but Access inserted a null character into the sequence. Why? Yeah, Microsoft, why! Note that “ting” (74646E67) immediately follows the null. Another niggle to code around.
此序列之后就是我们需要的对象。 它以字符序列474946383961开头。将其转换为ASCII会产生“ GIF89a”。 它不会显示在ASCII列中,因为Access不会在一致的两个字符块的OLE标头中存储数据。 这就是为什么完整路径的第一个实例很好地显示到“ DocumentsWri”然后出错的原因。 在此示例中,“ Wri”之后的字符应与“ Writing”中的一样为“ t”,但是Access在序列中插入了空字符。 为什么? 是的,微软,为什么! 请注意,“ ting”(74646E67)紧随null之后。 另一个讨厌编码的地方。
So let’s recap. What do we have now? We have the original name of the embedded file, the size in bytes of the original file, and we have the start location of the data we need to extract. We thus have all we need to extract the embedded file from a legacy Access database, and then save it to disc using its original name and extension.
因此,让我们回顾一下。 我们现在有什么? 我们具有嵌入式文件的原始名称,原始文件的大小(以字节为单位),并且具有我们需要提取的数据的起始位置。 因此,我们拥有从旧版Access数据库中提取嵌入文件,然后使用其原始名称和扩展名将其保存到光盘中的所有功能。
将理论付诸实践 (Putting Theory into Practice)
What follows is the PHP I used to extract from my test database the object details we discussed above. It’s no-frills, procedural PHP which should be easy for anyone to understand the steps involved in extracting an object from an OLE package.
接下来是用来从测试数据库中提取上面讨论的对象详细信息PHP。 它是简洁的过程性PHP,任何人都应该可以轻松理解从OLE包提取对象所涉及的步骤。
You’ll notice that some of the logic has multiplied certain numbers by a factor of two. For example, the offset for the embedded file name is defined as 168 rather than the 84 bytes mentioned above. That’s because some parts of the code work on the raw data from the Access database’s OLE field, which is encoded in hexadecimal format. That is, each single byte is stored as two hexadecimal characters.
您会注意到,某些逻辑已将某些数字乘以2。 例如,嵌入式文件名的偏移量定义为168,而不是上面提到的84个字节。 这是因为代码的某些部分适用于Access数据库的OLE字段中的原始数据,该字段以十六进制格式编码。 即,每个单个字节存储为两个十六进制字符。
<?php
if (!function_exists("hex2bin")) {
function hex2bin($hexStr) {
$hexStrLen = strlen($hexStr);
$binStr = "";
$i = 0;
while ($i < $hexStrLen) {
$a = substr($hexStr, $i, 2);
$c = pack("H*", $a);
$binStr .= $c;
$i += 2;
}
return $binStr;
}
}
$dbName = "db1.mdb";
$db = new PDO("odbc:DRIVER={Microsoft Access Driver (*.mdb)}; DBQ=$dbName; Uid=; Pwd=;");
$sql = "SELECT * FROM Table1 WHERE id = 2";
foreach ($db->query($sql) as $row) {
$objName = "";
switch (getOLEType($row["image"])) {
case "Packager Shell Object":
list($objName, $objData) = extractPackagerShellObject($row["image"]);
break;
case "Package":
list($objName, $objData) = extractPackage($row["image"]);
break;
default:
throw new Exception("Unknown OLE type");
}
if ($objName != "") {
file_put_contents($objName, $objData);
}
}
function flipEndian($data, $size) {
$str = "";
for ($i = $size - 2; $i >= 0; $i -= 2) {
$str .= substr($data, $i, 2);
}
return $str;
}
function findNullPos($str) {
// must start on a two-character boundary
return floor((strpos($str, "00") + 1) / 2) * 2;
}
function getOLEType($data) {
// fixed position of OLE type
$offset = 40;
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$tmp = substr($tmp, 0, $nullPos);
$type = hex2bin($tmp);
return $type;
}
function extractPackagerShellObject($data) {
$headerBlock = 500; // usable header size
$offset = 168; // location of name
// find name
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$name = substr($tmp, 0, $nullPos);
$pos = $offset + strlen($name);
// find data
$path1 = strpos($data, $name, $pos); // 1st full path
$pos = $path1 + strlen($name);
$path2 = strpos($data, $name, $pos); // 2nd full path
// check if only one full path
if ($path2 > $pos) {
$pos = $path2 + strlen($name);
}
$oleSizePos = $pos + 2;
$oleObjSize = flipEndian(substr($data, $oleSizePos, 8), 8);
$oleHeaderEnd = $oleSizePos + 8;
$objName = hex2bin(substr($tmp, 0, $nullPos));
// extract object
$data = substr($data, $oleHeaderEnd, hexdec($oleObjSize) * 2);
$objData = hex2bin($data);
return array($objName, $objData);
}
function extractPackage($data) {
$headerBlock = 500; // usable header size
$offset = 140; // location of name
// find name
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$name = substr($tmp, 0, $nullPos);
$pos = $offset + strlen($name);
// find data
$path1 = strpos($data, $name, $pos); // 1st full path
$pos = $path1 + strlen($name);
$path2 = strpos($data, $name, $pos); // 2nd full path
// check if only one full path
if ($path2 > $pos) {
$pos = $path2 + strlen($name);
}
$oleSizePos = $pos + 2;
$oleObjSize = flipEndian(substr($data, $oleSizePos, 8), 8);
$oleHeaderEnd = $oleSizePos + 8;
$objName = hex2bin(substr($tmp, 0, $nullPos));
// extract object
$data = substr($data, $oleHeaderEnd, hexdec($oleObjSize) * 2);
$objData = hex2bin($data);
return array($objName, $objData);
}Note that the bespoke hex2bin() function is only required if your PHP installation does not have its own (it was added in PHP 5.4). Also, the switch statement makes the logic extensible, as we’ll discover in the next part of this article.
请注意,仅当您PHP安装没有它自己的功能(PHP 5.4中添加了该功能)时,才需要定制的hex2bin()函数。 另外, switch语句使逻辑具有可扩展性,正如我们在本文的下一部分中将发现的那样。
The two package functions look very similar. These will be revisited in the next part of this article, when the code will be refactored because of the similar nature of the logic required for these and other object types.
这两个包功能看起来非常相似。 由于这些和其他对象类型所需逻辑的相似性质,在重构代码时,将在本文的下一部分中重新讨论这些内容。
I have tested this PHP with the following file types: BMP, GIF, JPEG, PNG, DOC, XLS, and PPT, all of which were stored as packages. The logic presented above should allow any file stored in an OLE package to be rescued from a legacy database, not just the GIF used in this example.
我已经使用以下文件类型测试了该PHP:BMP,GIF,JPEG,PNG,DOC,XLS和PPT,所有这些文件都存储为包。 上面介绍的逻辑应允许从旧版数据库中恢复OLE包中存储的任何文件,而不仅仅是本示例中使用的GIF。
摘要 (Summary)
In this article we have covered the essential elements of extracting package objects from OLE fields in a Microsoft Access database using PHP. Having learned the basic structure of an OLE object, and how to extract the file contained therein, the method presented above can be applied to other OLE types to ensure that as much data as possible can be retrieved from a legacy Access database.
在本文中,我们介绍了使用PHP从Microsoft Access数据库的OLE字段中提取包对象的基本元素。 在了解了OLE对象的基本结构以及如何提取其中包含的文件之后,以上介绍的方法可以应用于其他OLE类型,以确保可以从旧版Access数据库中检索尽可能多的数据。
In the second part of this series we’ll look at the more complex issue of extracting known object types, focusing in particular on extracting Acrobat PDF documents from a legacy Access database. In the meantime, feel free to clone the GitHub repository with this article’s code to play and explore.
在本系列的第二部分中 ,我们将讨论提取已知对象类型的更为复杂的问题,尤其着重于从旧版Access数据库中提取Acrobat PDF文档。 同时,随时使用本文的代码克隆GitHub存储库以进行播放和探索。
Image via Fotolia
图片来自Fotolia
翻译自: https://www.sitepoint.com/extract-ole-objects-from-an-access-database-using-php-1/















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









