





In a previous article I introduced two basic data structures: stack and queue. The article was well received so I’ve decided to share data structures in an intermittent on-going series here at SitePoint. In this entry I’ll introduce you to trees, another data structure used in software design and architecture. More articles and data structures will follow!
在上一篇文章中,我介绍了两个基本数据结构:堆栈和队列。 这篇文章很受好评,因此我决定在SitePoint上进行的一个不间断的连续系列中共享数据结构。 在本条目中,我将向您介绍树木,这是用于软件设计和体系结构的另一种数据结构。 接下来将有更多文章和数据结构!
搜索问题 (A Search Problem)
Data structure management generally involves 3 types of operations:
数据结构管理通常涉及3种类型的操作:
insertion – operations that insert data into the structure.
插入 –将数据插入结构的操作。
deletion – operations that delete data from the structure.
删除 –从结构中删除数据的操作。
traversal – operations that retrieve data from the structure.
遍历 –从结构中检索数据的操作。
In the case of stacks and queues, these operations are position-oriented – that is, they are limited by the position of the item in the structure. But what if we needed to store and retrieve data by its value?
在堆栈和队列的情况下,这些操作是面向位置的,也就是说,它们受项目在结构中的位置的限制。 但是,如果我们需要按值存储和检索数据呢?
Consider the following list (arranged in no particular order):
考虑以下列表(不按特定顺序排列):
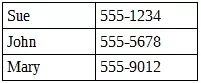
Clearly neither a stack nor queue would be suitable; we would potentially have to traverse the entire structure in order to find a particular entry if the value is either the last in the list or is not in the list at all. Assuming that the required value is in the list, and that each item is equally likely to contain the required value, we would need to visit an average of n/2 items – where n is the length of the list. The longer the list, the longer it will take to find what we’re looking for. What is required in this instance is the ability to arrange the data in a way that facilitates searching, which is where trees come in.
显然,堆栈和队列都不适合; 如果该值是列表中的最后一个或根本不在列表中,则可能必须遍历整个结构才能找到特定的条目。 假设所需值在列表中,并且每个项目都可能包含所需值,那么我们将需要平均访问n / 2个项目-其中n是列表的长度。 列表越长,找到我们要查找的内容所需的时间就越长。 在这种情况下,所需要的是能够以便于搜索的方式排列数据的能力,这就是树木的来源。
We can abstract this data as a “table” with the following basic operations:
我们可以通过以下基本操作将这些数据抽象为“表”:
create – create an empty table.
创建 –创建一个空表。
insert – add an item to the table.
插入 –在表格中添加一个项目。
delete – remove an item from the table.
删除 –从表中删除一个项目。
retrieve – find an item in the table.
检索 –在表中找到一个项目。
If this looks vaguely similar to database Create, Read, Update, Delete (CRUD) operations, that’s because trees are intimately related to databases and and how they represent data records internally.
如果这看起来与数据库的创建,读取,更新,删除(CRUD)操作相似,那是因为树与数据库密切相关,并且树与内部数据记录也是如此。
One way we can represent our “table” is as a linear implementation – such that it mirrors the flat, list-like appearance of a table. Linear implementations can either be sorted or unsorted, and sequential (i.e. fixed-length records or variable-length using record delimiters) or linked (using record pointers). For what it’s worth, early database designs such as IBM’s Indexed Sequential Access Method (ISAM) and legacy file systems such as MS-DOS’s File Allocation Table (FAT) were based on linear implementations.
我们可以表示“表格”的一种方法是线性实现–使其镜像表格的平坦列表形式。 线性实现既可以排序也可以不排序,并且可以是顺序的(即使用记录定界符的固定长度记录或可变长度记录)或链接(使用记录指针)。 值得一提的是,早期的数据库设计(例如IBM的索引顺序访问方法(ISAM))和遗留文件系统(例如MS-DOS的文件分配表(FAT))都是基于线性实现的。
The downside of sequential implementations is that they are more expensive in terms of inserts and deletes, whereas linked implementations allow for dynamic storage allocation. Searching a fixed-length sequential implementation however is considerably more efficient than a linked implementation since it can more easily facilitate a binary search.
顺序实现的缺点是,就插入和删除而言,它们的成本更高,而链接实现则允许动态存储分配。 但是,搜索固定长度的顺序实现比链接实现要有效得多,因为它可以更轻松地促进二进制搜索。
树木 (Trees)
So as we’ve learned, sometimes it may be more efficient to use a non-linear search implementation such as a tree. Trees provide the best features of both sequential and linked table implementations and support all table operations in a very efficient manner. For this reason, many modern databases and file systems now use trees to facilitate indexing. For example, MySQL’s MyISAM storage engine uses Trees for indices, and Apple’s HFS+, Microsoft’s NTFS, and btrfs for Linux all use trees for directory indexing.
因此,正如我们所了解的那样,有时使用非线性搜索实现(例如树)可能会更有效。 树提供顺序表和链接表实现的最佳功能,并以非常有效的方式支持所有表操作。 因此,许多现代数据库和文件系统现在都使用树来促进索引编制。 例如,MySQL的MyISAM存储引擎使用树进行索引,而Apple的HFS +,Microsoft的NTFS和Linux的btrfs都使用树进行目录索引。
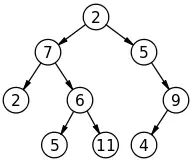
As you can see, trees are typically hierarchical and imply a parent-child relationship between the nodes. A node with no parents is called the root, and a node with no children is called a leaf. Child nodes of the same parent are called siblings. The term edges refers to the connections (indicated by arrows) between nodes.
如您所见,树通常是分层的,并且暗示节点之间的父子关系。 没有父节点的节点称为根 ,没有子节点的节点称为叶 。 同一父级的子节点称为同级 。 术语“ 边缘”是指节点之间的连接(用箭头指示)。
You’ll note that the binary tree in the figure above is a variation of a doubly-linked list. In fact, if we rearranged the nodes to flatten the tree it would look exactly like a doubly-linked list!
您会注意到,上图中的二叉树是双向链接列表的变体。 实际上,如果我们重新排列节点以使树变平,它将看起来完全像一个双向链接列表!
A node with at most two children is the simplest form of a tree, and we can utilize this property to construct a binary tree as a recursive collection of binary nodes:
最多有两个子节点的节点是树的最简单形式,我们可以利用此属性将二叉树构造为二叉节点的递归集合:
<?php
class BinaryNode
{
public $value; // contains the node item
public $left; // the left child BinaryNode
public $right; // the right child BinaryNode
public function __construct($item) {
$this->value = $item;
// new nodes are leaf nodes
$this->left = null;
$this->right = null;
}
}
class BinaryTree
{
protected $root; // the root node of our tree
public function __construct() {
$this->root = null;
}
public function isEmpty() {
return $this->root === null;
}
}插入节点 (Inserting Nodes)
Adding items to a tree is a little more “interesting”. There are several solutions – many of which involve rotating and rebalancing the tree. Indeed, different tree structures, such as AVL, Red-Black, and B-Trees, have evolved to address various performance issues associated with node insertions, deletions, and traversals.
将项目添加到树上更加“有趣”。 有几种解决方案–其中许多解决方案涉及旋转和重新平衡树。 实际上,已经开发了不同的树结构,例如AVL,红黑和B树,以解决与节点插入,删除和遍历相关的各种性能问题。
For simplicity, let’s consider a basic implementation in pseudocode:
为简单起见,让我们考虑一下伪代码的基本实现:
1. If the tree is empty, insert new_node as the root node (obviously!)
2. while (tree is NOT empty):
2a. If (current_node is empty), insert it here and stop;
2b. Else if (new_node > current_node), try inserting to the right
of this node (and repeat Step 2)
2c. Else if (new_node < current_node), try inserting to the left
of this node (and repeat Step 2)
2d. Else value is already in the tree
In this naive implementation, a divide and conquer approach is assumed. Anything less than the current node value goes to the left, anything greater goes right, and duplicates are rejected. Notice how this strategy immediately lends itself to a recursive solution as a tree in this instance can also be a sub-tree.
在这种幼稚的实现中,采用了分而治之的方法。 小于当前节点值的所有内容都将进入左侧,大于当前节点值的所有内容均将进入右侧,并且重复项将被拒绝。 请注意,此策略如何立即使其适用于递归解决方案,因为在这种情况下,树也可以是子树。
<?php
class BinaryTree
{
...
public function insert($item) {
$node = new BinaryNode($item);
if ($this->isEmpty()) {
// special case if tree is empty
$this->root = $node;
}
else {
// insert the node somewhere in the tree starting at the root
$this->insertNode($node, $this->root);
}
}
protected function insertNode($node, &$subtree) {
if ($subtree === null) {
// insert node here if subtree is empty
$subtree = $node;
}
else {
if ($node->value > $subtree->value) {
// keep trying to insert right
$this->insertNode($node, $subtree->right);
}
else if ($node->value < $subtree->value) {
// keep trying to insert left
$this->insertNode($node, $subtree->left);
}
else {
// reject duplicates
}
}
}
}Deleting nodes is a whole other story, which we’ll leave for another time as it will require a more in-depth treatment than this article allows.
删除节点是另外一回事,我们将再讨论一次,因为它将需要比本文所允许的更深入的处理。
走在树上 (Walking the Tree)
Notice how we started at the root node and walked the tree, node-by-node, to find an empty node? There are 4 general strategies used to traverse a tree:
注意我们是如何从根节点开始并逐节点遍历树以查找空节点的? 有四种遍历树的常规策略:
pre-order – process the current node and then traverse the left and right sub-trees.
预订 –处理当前节点,然后遍历左右子树。
in-order (symmetric) – traverse left first, process the current node, and then traverse right.
按顺序 (对称)–首先向左遍历,处理当前节点,然后向右遍历。
post-order – traverse left and right first and then process the current node.
后置命令 –首先左右移动,然后处理当前节点。
level-order (breadth-first) – process the current node, then process all sibling nodes before traversing nodes on the next level.
级别顺序 (广度优先)–处理当前节点,然后处理所有同级节点,然后再遍历下一级别的节点。
The first three strategies are also known as a depth-first or depth-order search – in which one starts at the root (or an arbitrary node designated as the root) and traverses as far down a branch as possible, before backtracking. Each of these strategies are used in different operational contexts and situations, for example, pre-order traversal is suited to node insertions (as in our example) and sub-tree cloning (grafting). In-order traversal is commonly used for searching binary trees, while post-order is better suited for deleting (pruning) nodes.
前三种策略也称为深度优先或深度顺序搜索-其中一种策略从根(或指定为根的任意节点)开始,并在回溯之前遍历尽可能远的分支。 这些策略中的每一种都用于不同的操作上下文和情况中,例如,预遍历适用于节点插入(如我们的示例)和子树克隆(移植)。 有序遍历通常用于搜索二叉树,而后序遍历更适合于删除(修剪)节点。
To illustrate how an in-order traversal works, let’s make a few modifications to our example:
为了说明有序遍历是如何工作的,让我们对示例进行一些修改:
<?php
class BinaryNode
{
...
// perform an in-order traversal of the current node
public function dump() {
if ($this->left !== null) {
$this->left->dump();
}
var_dump($this->value);
if ($this->right !== null) {
$this->right->dump();
}
}
}
class BinaryTree
{
...
public function traverse() {
// dump the tree rooted at "root"
$this->root->dump();
}
}Calling the traverse() method will display the entire tree in ascending order starting from the root node.
调用traverse()方法将从根节点开始以升序显示整个树。
结论 (Conclusion)
Well, here we are at the end already! In this article I introduced you to the tree data structure, and its simplest form – the binary tree. You’ve seen how nodes are inserted into the tree and how to recursively walk the tree in depth-order.
好了,我们到此为止了! 在本文中,我向您介绍了树数据结构及其最简单的形式–二叉树。 您已经了解了如何将节点插入到树中以及如何以深度顺序递归遍历树。
Next time I’ll discuss breadth-first search as well as introduce some new data structures. Stay tuned! Until then, I encourage you to explore other tree types and their respective algorithms for inserting and deleting nodes.
下次,我将讨论广度优先搜索并介绍一些新的数据结构。 敬请关注! 在此之前,我鼓励您探索其他树类型以及它们各自用于插入和删除节点的算法。
Image via Fotolia
图片来自Fotolia















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









