





Rule engines are funny things. They’re typically complex, and meant to replace simple conditional logic. The problem they solve is one of scale.
规则引擎很有趣。 它们通常很复杂,意在代替简单的条件逻辑。 他们解决的问题是规模问题之一。
When your application becomes so large that the logic to display or enable functionality is over a large area; conditional logic leads to bugs. Edge cases. Instances when your if statements don’t cover every aspect they need to. Or every path through your application.
当您的应用程序变得如此之大以致于显示或启用功能的逻辑范围很大时; 条件逻辑会导致错误。 边缘情况。 实例,当您的if语句不能涵盖它们需要的所有方面时。 或应用程序中的每条路径。
This is when good rules engines shine. Perhaps I’m being a little too abstract here. Let’s look at an example…
这是好的规则引擎大放异彩的时候。 也许我在这里有点太抽象了。 让我们看一个例子……

You can find the example code at https://github.com/assertchris-tutorials/rulerz.
您可以在https://github.com/assertchris-tutorials/rulerz中找到示例代码。
问题 (The Problem)
I listen to music all the time. I prefer iTunes, over other media players, for many reasons. But one of the reasons that stands out is that I can use iTunes to build large, complex playlists for me.
我一直在听音乐。 由于许多原因,与其他媒体播放器相比,我更喜欢iTunes。 但是脱颖而出的原因之一是,我可以使用iTunes为我构建大型,复杂的播放列表。
I can give iTunes a few rules, and it will update the list of playlist tracks based on those rules, without me having to think about how it is doing that.
我可以给iTunes一些规则,它会根据这些规则更新播放列表曲目的列表,而无需考虑它的运行方式。
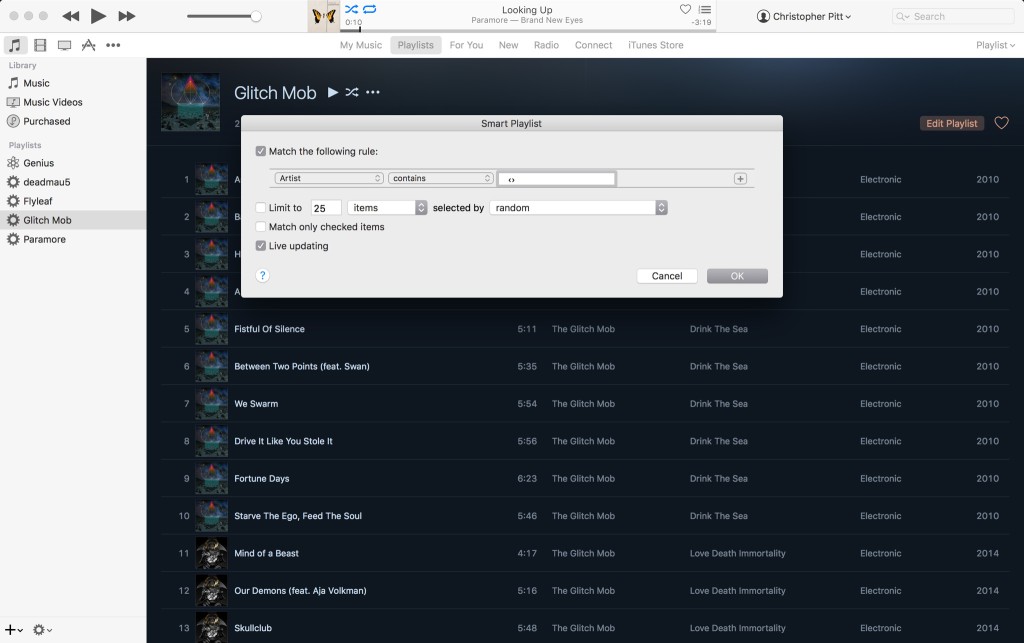
But how does it do this? How does it build my simple rules into a filter for tracks? When I tell it things like; “give me everything from The Glitch Mob, produced before 2014, where plays count is less than 20”, it understands what I mean.
但是它是怎么做到的呢? 如何将我的简单规则构建为轨道过滤器? 当我告诉它的时候 “请给我2014年之前制作的The Glitch Mob中的所有内容,其中戏剧数量少于20个”,它理解了我的意思。
Now, we could make these Smart Playlists with many conditionals. If you’re anything like me though, you just cringed at that thought.
现在,我们可以使用许多条件制作这些智能播放列表 。 如果你像我一样,那你只是畏缩了。
输入RulerZ (Enter RulerZ)
RulerZ is a rule engine. It’s an implementation of the Specification pattern. You know where else you’ve seen the Specification pattern? In database abstraction layers like Eloquent and Doctrine!
RulerZ是一个规则引擎。 这是规范模式的实现。 您知道在其他地方看到过规范模式吗? 在数据库抽象层中,例如口才和学说!
The basic idea is that you start with some sort of list. It could be users in a database, or expenses in a CSV file. Then you read them into memory (or even filter before that) and filter them according to some chain-based logic. You know the kind:
基本思想是从某种列表开始。 可能是数据库中的用户,也可能是CSV文件中的费用。 然后,您将它们读入内存(甚至在此之前进行过滤),并根据一些基于链的逻辑对其进行过滤。 你知道那种:
$list
->whereArtist("The Glitch Mob")
->whereYearLessThan(2015)
->wherePlayCountLessThan(20)
->all();In database abstraction layers this is usually done by generating SQL. We send that SQL to the database server, where the records are brought into memory and then filtered. What we get is the already-filtered list, but the idea is still the same.
在数据库抽象层中,这通常是通过生成SQL来完成的。 我们将该SQL发送到数据库服务器,在该服务器中将记录放入内存中,然后进行过滤。 我们得到的是已经过滤的列表,但是想法仍然相同。
We wouldn’t want to make those filters as conditionals, through PHP. The Specification pattern (and by extension SQL) are great for applying this boolean logic.
我们不想通过PHP将这些过滤器作为条件过滤器。 规范模式(以及扩展SQL)非常适合应用此布尔逻辑。
Let’s take a look at how to use RulerZ:
让我们看一下如何使用RulerZ:
use RulerZ\Compiler;
use RulerZ\Parser;
use RulerZ\RulerZ;
$compiler = new Compiler\EvalCompiler(
$parser = new Parser\HoaParser()
);
$rulerz = new RulerZ(
$compiler, [
$visitor = new Compiler\Target\ArrayVisitor(),
]
);
$tracks = [
[
"title" => "Animus Vox",
"artist" => "The Glitch Mob",
"plays" => 36,
"year" => 2010
],
[
"title" => "Bad Wings",
"artist" => "The Glitch Mob",
"plays" => 12,
"year" => 2010
],
[
"title" => "We Swarm",
"artist" => "The Glitch Mob",
"plays" => 28,
"year" => 2010
]
// ...
];
$filtered = $rulerz->filter(
$tracks,
"artist = :artist and year < :year and plays < :plays",
[
"artist" => "The Glitch Mob",
"year" => 2015,
"plays" => 20
]
);In this example, we have a list of tracks. This could be something we export from iTunes…
在此示例中,我们有一个轨道列表。 这可能是我们从iTunes导出的内容…
We create a rule compiler, and a new RulerZ instance. We can then use the RulerZ instance of filter our track list. We combine the textual rules with the parameter list to create the boolean filter logic.
我们创建一个规则编译器和一个新的RulerZ实例。 然后,我们可以使用RulerZ实例过滤我们的跟踪列表。 我们将文本规则与参数列表结合起来以创建布尔过滤器逻辑。
Like SQL but in PHP, against records stored in memory. It’s simple and elegant!
与SQL类似,但在PHP中,针对存储在内存中的记录。 简单而优雅!
建立智能播放列表 (Building Smart Playlists)
Let’s put this knowledge to use! We’ll begin by extracting an iTunes library:
让我们利用这些知识! 我们将从提取iTunes库开始:
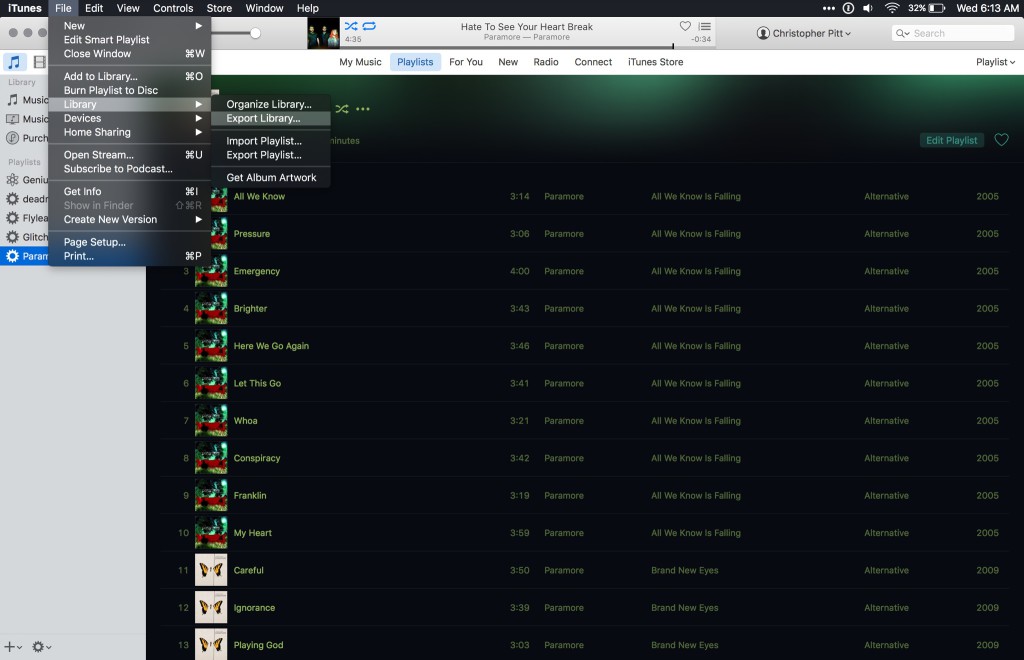
Open iTunes, click “File” → “Library” → “Export Library…”
打开iTunes,单击“文件”→“库”→“导出库…”。
Save the XML file as library.xml, in your working directory.
在工作目录中将XML文件另存为library.xml 。
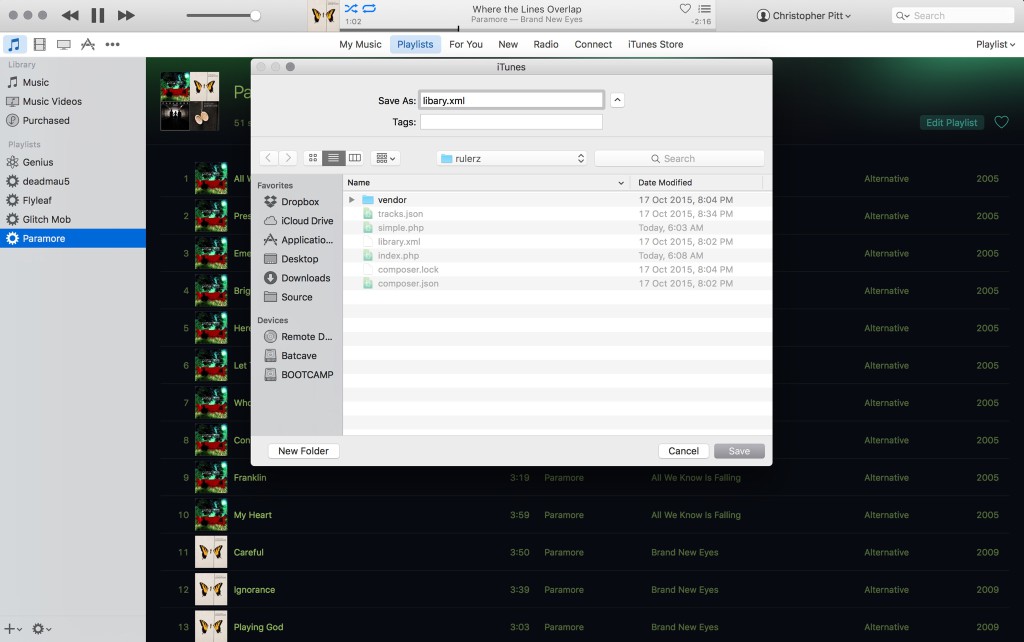
Depending on the size of your library, this file may be large. My library.xml file is about 46k lines long…
根据库的大小,此文件可能很大。 我的library.xml文件长约46k行…
This XML file can be difficult to work with. It’s in an odd key/value format. So we’re going to convert it to a JSON file, containing track data only:
这个XML文件可能很难使用。 它采用奇数键/值格式。 因此,我们将其转换为仅包含跟踪数据的JSON文件:
$document = new DomDocument();
$document->loadHTMLFile("library.xml");
$tracks = $document
->getElementsByTagName("dict")[0] // root node
->getElementsByTagName("dict")[0] // track container
->getElementsByTagName("dict"); // track nodes
$clean = [];
foreach ($tracks as $track) {
$key = null;
$all = [];
foreach ($track->childNodes as $node) {
if ($node->tagName == "key") {
$key = str_replace(" ", "", $node->nodeValue);
} else {
$all[$key] = $node->nodeValue;
$key = null;
}
}
$clean[] = $all;
}
file_put_contents(
"tracks.json", json_encode($clean)
);We create a DomDocument object, to allow us to step through the XML nodes. There are three levels to this file: root dict node → library dict node → track dict nodes.
我们创建一个DomDocument对象,以允许我们逐步遍历XML节点。 该文件分为三个级别:根dict节点→库dict节点→跟踪dict节点。
For each track node, we step through each child node. Half of them are key nodes (with dictionary key strings) and the other half are value nodes. So we store each key until we get a value to go with it. This is a bit of a hack, but it does the job. We only need to run this once to get a nice track list, and RulerZ will use it thereafter!
对于每个跟踪节点,我们逐步浏览每个子节点。 其中一半是key节点(带有字典键字符串),另一半是值节点。 因此,我们存储每个键,直到获得与之匹配的值。 这有点骇人听闻,但确实可以。 我们只需要运行一次就可以得到一个不错的曲目列表,然后RulerZ将使用它!
If you want to debug this code, I suggest you export playlists (as XML files) instead. That way you can have a much smaller library.xml file to work with. You don’t want to repeat this extraction many times, on a large list. Trust me…
如果要调试此代码,建议您改为导出播放列表(作为XML文件)。 这样,您可以使用一个较小的library.xml文件。 您不想在一个很大的列表上多次重复此提取。 相信我…
Then we need to create a form, for the filters:
然后,我们需要为过滤器创建一个表单:
$filterCount = 0;
$filtered = [];
function option($value, $label, $selected = null) {
$parameters = "value={$value}";
if ($value == $selected) {
$parameters .= " selected='selected'";
}
return "<option {$parameters}>{$label}</option>";
}We begin with $filterCount, which is the number of filters applied so far. We’re not persisting any filters yet, so this will always be 0. We also create an array of filtered tracks, though this will also be empty for now.
我们从$filterCount开始,这是到目前为止应用的过滤器数量。 我们尚未保留任何过滤器,因此该值始终为0 。 我们还创建了一个过滤后的轨道数组,尽管目前它还是空的。
Then we define a function for rendering option elements. This cuts down on the work we have to do later. Yay! Next up is the markup:
然后,我们定义一个用于呈现选项元素的函数。 这减少了我们以后要做的工作。 好极了! 接下来是标记:
<form method="post">
<div>
<select name="field[<?= $filterCount ?>]">
<?= option("Name", "Name") ?>
<?= option("Artist", "Artist") ?>
<?= option("Album", "Album") ?>
<?= option("Year", "Year") ?>
</select>
<select name="operator[<?= $filterCount ?>]">
<?= option("contains", "contains") ?>
<?= option("begins", "begins with") ?>
<?= option("ends", "ends with") ?>
<?= option("is", "is") ?>
<?= option("not", "is not") ?>
<?= option("gt", "greater than") ?>
<?= option("lt", "less than") ?>
</select>
<input type="text" name="query[<?= $filterCount ?>]" />
</div>
<input type="submit" value="filter" />
</form>
<?php foreach ($filtered as $track): ?>
<div>
<?= $track["Artist"] ?>,
<?= $track["Album"] ?>,
<?= $track["Name"] ?>
</div>
<?php endforeach; ?>Here we’ve created markup for adding a single filter. The fields are named field[0], operator[0] and query[0], which will make sense the more we work on this.
在这里,我们创建了用于添加单个过滤器的标记。 这些字段分别命名为field[0] , operator[0]和query[0] ,这对我们进行更多的工作将有意义。
We also step through the array of filtered tracks, displaying the artist, album and name of each. This array is empty right now, but we’ll add tracks to it shortly.
我们还将逐步浏览经过筛选的曲目,显示艺术家,专辑和每个曲目的名称。 这个数组现在是空的,但是我们很快就会在其上添加曲目。
We’ve created a small subset of the filter options we could create. Each track has the following kinds of data:
我们已经创建了我们可以创建的过滤器选项的一小部分。 每个轨道具有以下类型的数据:
{
"Track ID": "238",
"Name": "Broken Bones (Bonus Track)",
"Artist": "CHVRCHES",
"Album Artist": "CHVRCHES",
"Composer": "CHVRCHES",
"Album": "The Bones of What You Believe (Special Edition)",
"Genre": "Alternative",
"Kind": "Purchased AAC audio file",
"Size": "7872373",
"Total Time": "224721",
"Disc Number": "1",
"Disc Count": "1",
"Track Number": "14",
"Track Count": "16",
"Year": "2013",
"Date Modified": "2014-05-21T09:45:09Z",
"Date Added": "2013-11-24T22:18:35Z",
"Bit Rate": "256",
"Sample Rate": "44100",
"Play Count": "133",
"Play Date": "3513745347",
"Play Date UTC": "2015-05-05T20:22:27Z",
"Skip Count": "1",
"Skip Date": "2014-01-30T21:44:20Z",
"Release Date": "2013-09-24T07:00:00Z",
"Normalization": "1979",
"Artwork Count": "1",
"Sort Album": "Bones of What You Believe (Special Edition)",
"Persistent ID": "B05B025A46F6F2BB",
"Track Type": "File",
"Purchased": "",
"Location": "file://.../track.m4a",
"File Folder Count": "5",
"Library Folder Count": "1"
}Aside form the textual filters we’ve already added; we can add our own custom functions:
除了已经添加的文本过滤器之外, 我们可以添加自己的自定义函数:
$visitor->setOperator("my_is", function($field, $value) {
return $field == $value;
});
$visitor->setOperator("my_not", function($field, $value) {
return $field != $value;
});
$visitor->setOperator("my_contains", function($field, $value) {
return stristr($field, $value);
});
$visitor->setOperator("my_begins", function($field, $value) {
return preg_match("/^{$value}.*/i", $field) == 1;
});
$visitor->setOperator("my_ends", function($field, $value) {
return preg_match("/.*{$value}$/i", $field) == 1;
});
$visitor->setOperator("my_gt", function($field, $value) {
return $field > $value;
});
$visitor->setOperator("custom_lt", function($field, $value) {
return $field < $value;
});We can use these in other textual queries, like: my_contains(Artist, 'Glitch'). In fact, we can begin to stitch the form filters together, using these:
我们可以在其他文本查询中使用它们,例如: my_contains(Artist, 'Glitch') 。 实际上,我们可以开始使用以下方法将表单过滤器缝合在一起:
if (isset($_POST["field"])) {
$fields = $_POST["field"];
$operators = $_POST["operator"];
$values = $_POST["query"];
$query = "";
foreach ($fields as $i => $field) {
$operator = $operators[$i];
$value = $values[$i];
if (trim($field) && trim($operator) && trim($value)) {
if ($query) {
$query .= " and ";
}
$query .= "my_{$operator}({$field}, '{$value}')";
}
}
$filterCount = count($fields);
}This code checks if there are posted filters. For each posted filter, we get the operator and query value. If these aren’t empty values (which is what we use trim to check) then we build a query string.
此代码检查是否有发布的过滤器。 对于每个发布的过滤器,我们获得operator和query值。 如果这些不是空值(这是我们使用trim检查的值),那么我们将构建查询字符串。
We also adjust the $filterCount so new filter fields are added to the end of the list. Finally, we need to filter the exported track list:
我们还调整了$filterCount以便将新的过滤器字段添加到列表的末尾。 最后,我们需要过滤导出的曲目列表:
$tracks = json_decode(
file_get_contents("tracks.json"), true
);
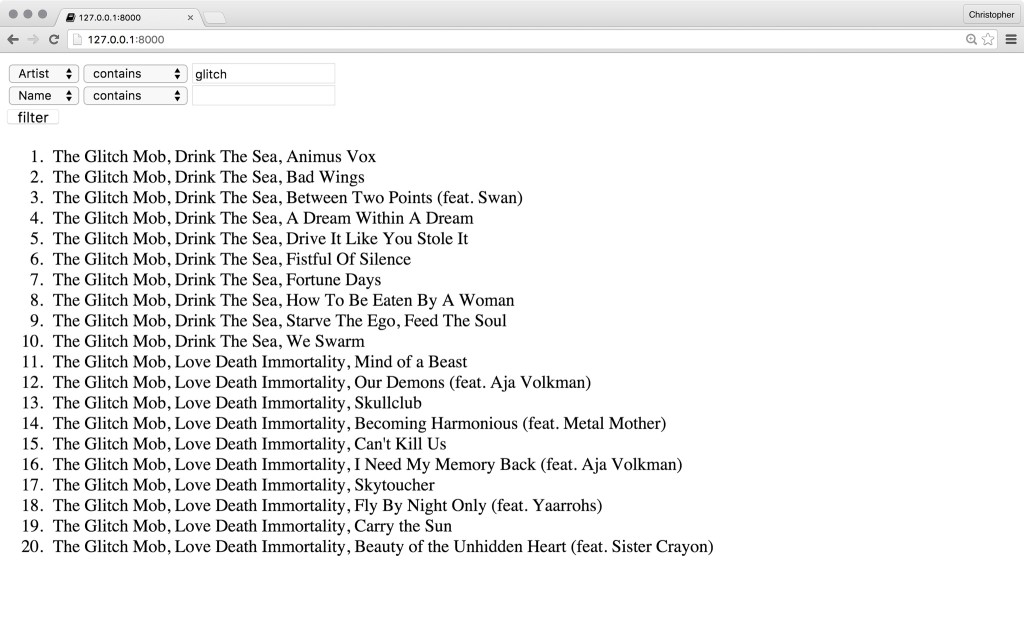
$filtered = $rulerz->filter($tracks, $query);This takes the iTunes export we made earlier and filters it according to the dynamic query we just made.
这将采用我们之前制作的iTunes导出,并根据我们刚进行的动态查询对其进行过滤。
显示发布的过滤器 (Displaying Posted Filters)
Let’s display posted filters in the form, so we can see which filters are being applied to the current result-set:
让我们在表单中显示已发布的过滤器,以便我们可以看到哪些过滤器正在应用于当前结果集:
<form method="post">
<?php if ($fields): ?>
<?php for ($i = 0; $i < $filterCount; $i++): ?>
<div>
<select name="field[<?= $i ?>]">
<?= option("Name", "Name", $fields[$i]) ?>
<?= option("Artist", "Artist", $fields[$i]) ?>
<?= option("Album", "Album", $fields[$i]) ?>
<?= option("Year", "Year", $fields[$i]) ?>
</select>
<select name="operator[<?= $i ?>]">
<?= option("contains", "contains", $operators[$i]) ?>
<?= option("begins", "begins with", $operators[$i]) ?>
<?= option("ends", "ends with", $operators[$i]) ?>
<?= option("is", "is", $operators[$i]) ?>
<?= option("not", "is not", $operators[$i]) ?>
<?= option("gt", "greater than", $operators[$i]) ?>
<?= option("lt", "less than", $operators[$i]) ?>
</select>
<input
type="text"
name="query[<?= $i ?>]"
value="<?= $values[$i] ?>" />
</div>
<?php endfor; ?>
<?php endif; ?>
<div>
<select name="field[<?= $filterCount ?>]">
<?= option("Name", "Name") ?>
<?= option("Artist", "Artist") ?>
<?= option("Album", "Album") ?>
<?= option("Year", "Year") ?>
</select>
<select name="operator[<?= $filterCount ?>]">
<?= option("contains", "contains") ?>
<?= option("begins", "begins with") ?>
<?= option("ends", "ends with") ?>
<?= option("is", "is") ?>
<?= option("not", "is not") ?>
<?= option("gt", "greater than") ?>
<?= option("lt", "less than") ?>
</select>
<input type="text" name="query[<?= $filterCount ?>]" />
</div>
<input type="submit" value="filter" />
</form>This is much like the previous form we had. Now we’re basing option selection on posted values.
这很像我们以前的表格。 现在,我们根据发布的值选择选项。
We’re not removing empty filters. Consider that an exercise left to the reader!
我们不会删除空的过滤器。 考虑一下留给读者的练习!
结论 (Conclusion)
This was an interesting project for me. It’s not often I get to really think about how something was implemented, through code of my own. RulerZ provided me with the tools I needed to do it!
对我来说,这是一个有趣的项目。 通过我自己的代码,我很少经常真正考虑如何实现某些事情。 RulerZ为我提供了所需的工具!
Can you think of other interesting uses for a rule engine? Let me know in the comments!
您能想到规则引擎的其他有趣用途吗? 在评论中让我知道!
翻译自: https://www.sitepoint.com/using-the-rulerz-rule-engine-to-smarten-up-playlist-building/















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









