





web数据传输的几种方式
This article was sponsored by import.io. Thank you for supporting the sponsors who make SitePoint possible!
本文由import.io赞助。 感谢您支持使SitePoint成为可能的赞助商!
The web is full of interesting and useful information. Some of the most successful web applications do nothing more than organize that information in a creative way that’s easy to digest by their users — ever heard of a little company called Google? However, organizing data from the web can be a difficult and time consuming process, and many projects never launch because of this. Now, import.io is solving this problem, meaning web data is finally easy to collect, organize, and use to your advantage.
网络上充满了有趣而有用的信息。 一些最成功的Web应用程序无非就是以一种易于用户吸收的创新方式来组织这些信息-听说过一家叫Google的小公司吗? 但是,从网络组织数据可能是一个困难且耗时的过程,因此许多项目从未启动过。 现在,import.io正在解决此问题,这意味着最终可以轻松收集,组织和使用Web数据,从而为您带来好处。
什么是import.io? (What is import.io?)
import.io allows you to collect data from across the web, and then access and manipulate that data through a simple user interface. As highlighted in their introductory video, the process is very quick, and requires absolutely no coding knowledge to complete. After collecting your data, you can view it and apply edits as needed, integrate it into your application as an API (import.io has great documentation with instructions on how to do this in a wide array of languages), or download it in a variety of formats.
import.io允许您从Web上收集数据,然后通过简单的用户界面访问和处理这些数据。 正如他们的介绍性视频中突出显示的那样,该过程非常快速,并且完全不需要任何编码知识即可完成。 收集数据后,您可以查看数据并根据需要应用编辑,将其作为API集成到您的应用程序中(import.io提供了出色的文档,其中包含有关如何使用多种语言进行操作的说明),或以多种格式。
使用import.io (Using import.io)
Most applications that involve complicated and computation-heavy processes have equally complicated user interfaces. I was surprised to find how easy import.io was to navigate and use.
大多数涉及复杂且计算繁重过程的应用程序都具有同样复杂的用户界面。 我惊讶地发现import.io导航和使用起来多么容易。
After signing up, I downloaded their desktop application (which you will need to collect data).
注册后,我下载了他们的桌面应用程序(需要收集数据)。
For my first data collection project, I decided to create an API from a URL, in the form of a collection of posts from my personal blog.
对于我的第一个数据收集项目,我决定从URL中创建一个API,以我个人博客中帖子集的形式。
I then entered my blog address into the URL bar, and then turned extraction on to begin building my API.
然后,我在URL栏中输入我的博客地址,然后打开提取以开始构建我的API。
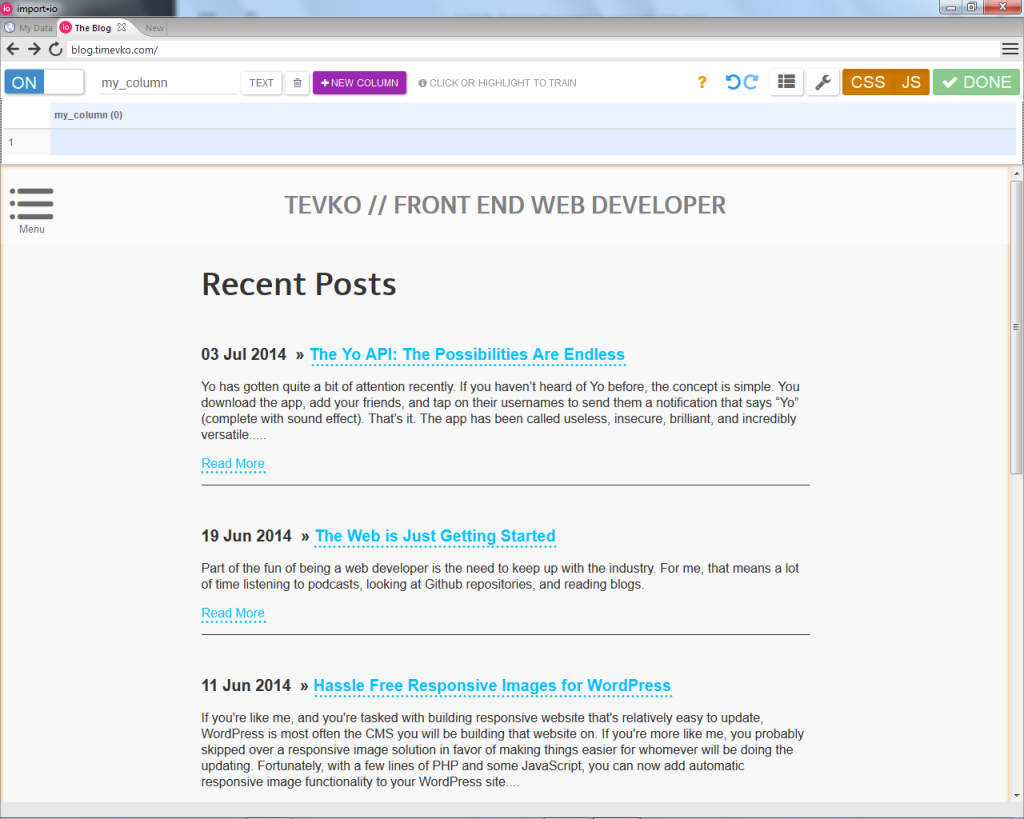
As a side note, another great feature offered by import.io is the ability to toggle JavaScript support on or off, in case you need to collect data from a JavaScript run application. From there, creating the data table was as easy as navigating a simple point-and-click interface, in which I told the application how many rows I expected to be in the table (one row or multiple), and clicked on the desired data as I named the column it was to be placed in. The impressive part was when the application correctly predicted where the rest of the data I needed was located, and I didn’t have to specify where the next post title, date, or description would be. import.io doesn’t just collect data, it also predicts where your data is going to be, and adjusts itself when the location of the data is changed on the page.
附带说明一下,import.io提供的另一个重要功能是,如果您需要从JavaScript运行的应用程序中收集数据,则可以打开或关闭JavaScript支持。 从那里开始,创建数据表就像导航简单的点击界面一样简单,在该界面中,我告诉应用程序我期望表中有多少行(一行或多行),然后单击所需的数据。我将其命名为要放置的列。令人印象深刻的部分是,应用程序正确地预测了我需要的其余数据的位置,而不必指定下一个帖子标题,日期或说明的位置将是。 import.io不仅收集数据,还可以预测数据的位置,并在页面上更改数据位置时进行自我调整。
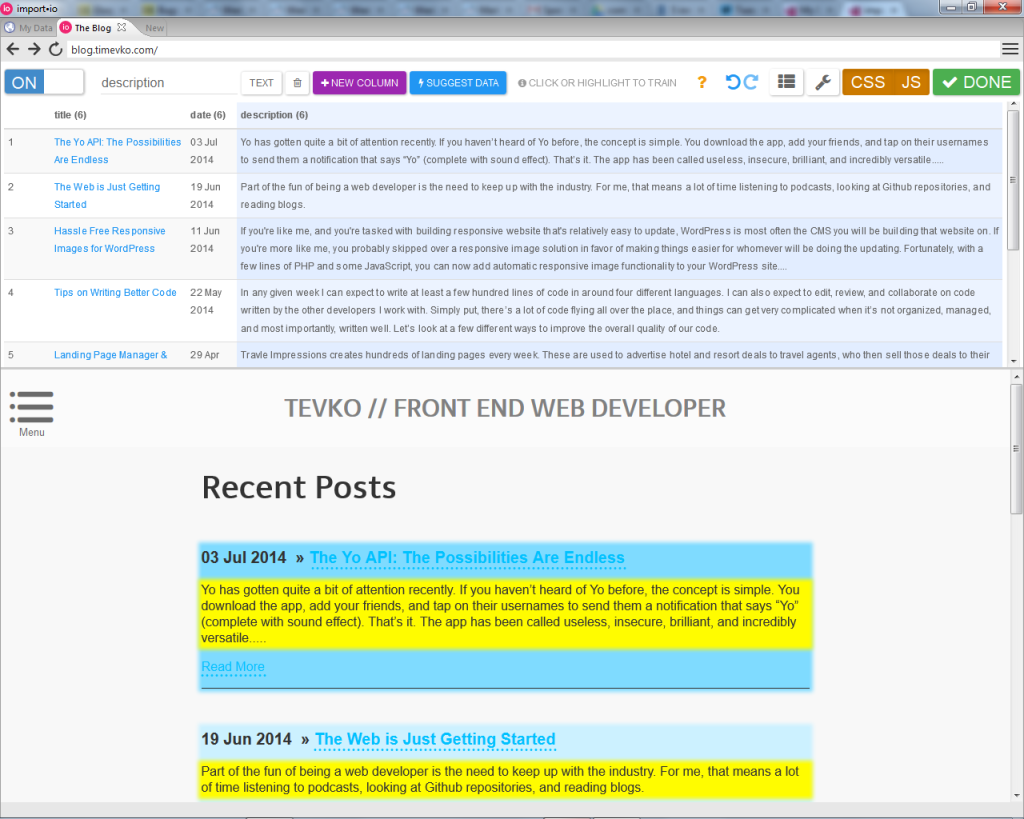
After all of the data was in place, I clicked “Done” and was brought back to the “My Data” section of the application, where I could edit, implement, and export my data as needed. You can export the data in a number of ways, including as JSON, TSV, or using Google Sheets.
放置完所有数据后,我单击“完成”,然后返回到应用程序的“我的数据”部分,可以在其中根据需要编辑,实现和导出数据。 您可以通过多种方式导出数据,包括将其导出为JSON,TSV或使用Google表格。
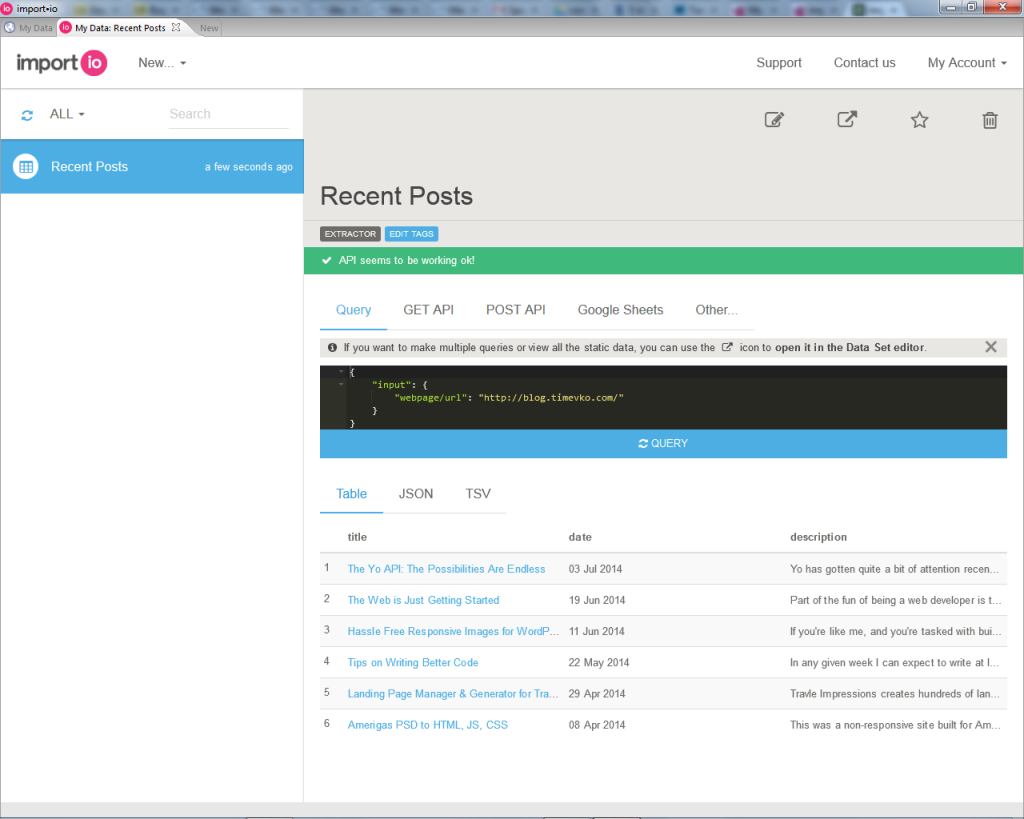
Here’s a sample of the automatically generated JSON code from my Recent Posts data collection:
这是我最近的Posts数据集合中自动生成的JSON代码的示例:
{ "title": "http://blog.timevko.com/2014/07/03/yo-possibilities-endless", "title/_text": "The Yo API: The Possibilities Are Endless", "description": "Yo has gotten quite a bit of attention recently. If you haven’t heard of Yo before, the concept is simple. You download the app, add your friends, and tap on their usernames to send them a notification that says “Yo” (complete with sound effect). That’s it. The app has been called useless, insecure, brilliant, and incredibly versatile.....", "date": "03 Jul 2014", "title/_source": "/2014/07/03/yo-possibilities-endless" }
{ "title": "http://blog.timevko.com/2014/07/03/yo-possibilities-endless", "title/_text": "The Yo API: The Possibilities Are Endless", "description": "Yo has gotten quite a bit of attention recently. If you haven't heard of Yo before, the concept is simple. You download the app, add your friends, and tap on their usernames to send them a notification that says “Yo” (complete with sound effect). That's it. The app has been called useless, insecure, brilliant, and incredibly versatile.....", "date": "03 Jul 2014", "title/_source": "/2014/07/03/yo-possibilities-endless" }
Using import.io to create this quick data collection only tok me about five minutes, and it was perfectly accurate. The best part? I didn’t pay a dime. import.io is free to use for life, and has an option for enterprise solutions as well.
使用import.io创建此快速数据收集仅花费了我大约五分钟的时间,并且非常准确。 最好的部分? 我没有付一角钱。 import.io可以终身免费使用,也可以选择企业解决方案。
So now we know how easy it is to collect and use data from all over the web, what are some other interesting things that we can do with it?
因此,现在我们知道从整个Web收集和使用数据有多么容易,我们可以用它做些其他有趣的事情?
1.构建一个可以在您附近打开餐厅的应用程序 (1. Build an app that finds diners open near you)
Let’s say that it’s a late night, you’re in New York City, you’re hungry, and you really like diners. What do you do if you want to find a few near you that are still open? Using import.io, you could build a web app that does this for you! How would that work?
假设这是一个深夜,您在纽约市,饿了,您真的很喜欢用餐。 如果您想在您附近找到一些仍然开放的空间,该怎么办? 使用import.io,您可以构建一个为您执行此操作的Web应用程序! 那将如何工作?
Well, we’ve already seen how easy it is to get our data in an easy to use JSON format, and Foursquare is really good at finding 24-hour diners in NYC. So we could use import.io to gather all of the information about the diners, and then create a simple interface that lists the diners closest to our current location on a map with the help of the Google Maps API and the geolocation API provided by the browser.
好了,我们已经知道以易于使用的JSON格式获取数据非常容易, Foursquare非常擅长在纽约市寻找24小时用餐者。 因此,我们可以使用import.io来收集有关食客的所有信息,然后创建一个简单的界面,借助Google Maps API和Google提供的geolocation API,该界面列出最接近地图上当前位置的食客。浏览器。
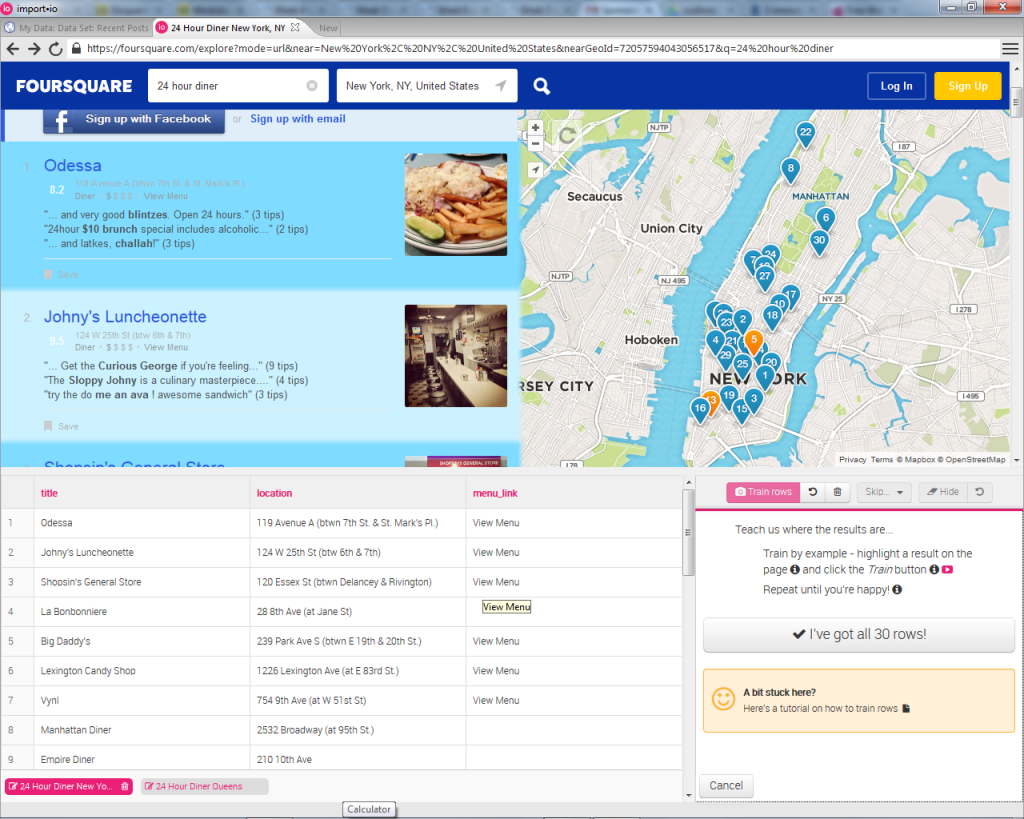
If it sounds to good to be true, fear not! A similar project has already been created with import.io, and it worked so well that they dedicated a whole blog post to it!
如果听起来不错,那就不要担心! 已经使用import.io创建了一个类似的项目,并且效果很好,以至于他们将整个博客文章都献给了它 !
2.在您喜欢的网站上获取统计信息 (2. Get statistics on your favorite website)
SitePoint posts a lot of articles every day. How would we get statistics on those articles, as well as their most common topic, average comment count, and most frequent writers?
SitePoint每天都会发布很多文章。 我们如何获得这些文章的统计数据,以及它们最常见的主题,平均评论数和最常写的作者?
Our first step would be to create a web crawler, the process for which is detailed here. We could then export the data provided by our crawler as JSON, and use javascript to create a set of functions that pushes the URLs, comment count numbers, author names, etc. into arrays and returns either an average of the counts, or the topics and author names that appear most frequently.
我们的第一步是创建一个Web搜寻器, 其过程在此处详细介绍 。 然后,我们可以将抓取工具提供的数据导出为JSON,并使用javascript创建一组函数,将URL,注释计数数字,作者姓名等推入数组,并返回计数的平均值或主题和出现频率最高的作者姓名。
I set up a sample crawler to demonstrate this, and the process was quick and seamless.
我设置了一个样本搜寻器来演示这一点,并且该过程是快速且无缝的。
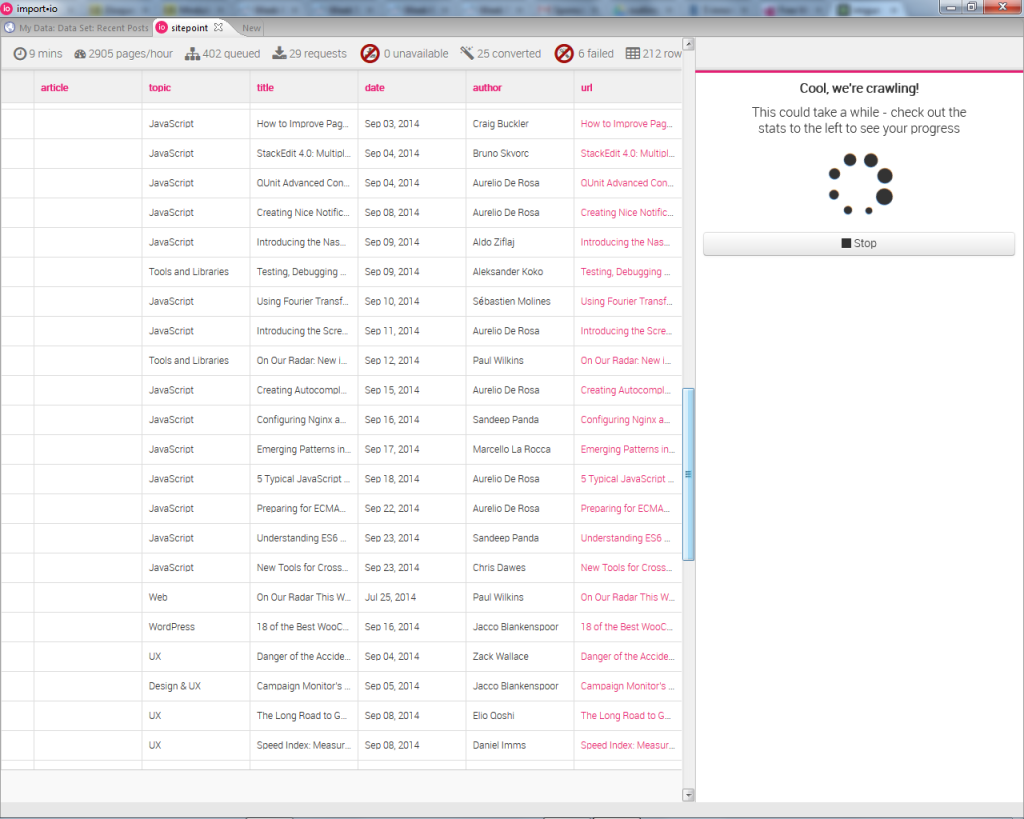
Here’s a sample codepen that uses some of the JSON data from my Sitepoint crawler to list a few of the most recent (at the time) articles on the site.
这是一个示例Codepen,它使用我的Sitepoint搜寻器中的一些JSON数据来列出网站上的一些最新(当时)文章。
See the Pen HGant by Tim (@tevko) on CodePen.
请参阅CodePen上的Tim( @tevko )的Pen HGant 。
Take a look at Product Hunt Statistics, which uses an import.io web crawler to get user data from Product Hunt.
看一下Product Hunt Statistics ,它使用import.io Web搜寻器从Product Hunt获取用户数据。
3.自由职业者,获取潜在客户 (3. Freelancers, get leads)
Are you a freelancer? Are you looking for more business? Of course you are. import.io can crawl websites to find people and companies that are looking for the services that you offer, and store their contact information in a spread sheet. Using that information is as simple as sending an email to each one of the people or companies in the spreadsheet. import.io has a blog post that explains this process. Their best advice: make sure the messages you send are personal. No one likes an automated email!
您是自由职业者吗? 您正在寻找更多业务吗? 当然可以 import.io可以爬网网站来查找正在寻找您提供的服务的人员和公司,并将其联系信息存储在电子表格中。 使用该信息就像向电子表格中的每个人或公司发送电子邮件一样简单。 import.io有一篇博客文章解释了此过程 。 他们的最佳建议:确保您发送的消息是个人消息。 没有人喜欢自动发送电子邮件!
4.制作漂亮的图表和图形 (4. Make cool charts and graphs)
Why make cool charts and graphs you ask? Cool charts and graphs are great to impress visitors to your portfolio, to help you learn new libraries like d3.js, or to show off to your fellow developer friends!
为什么要制作您要求的炫酷图表? 酷炫的图表非常适合吸引您的投资组合访问者,帮助您学习d3.js之类的新库,或向其他开发者朋友炫耀!
The Data Press recently used import.io to do this very thing, and the results are pretty impressive! They used MetaCritic and search result information to collect data on music festivals and the bands performing at them. Once all of the data was collected, they imported the data into Tableau to create a vizualization, embedded below.
数据出版社最近使用import.io做到了这一点,其结果令人印象深刻! 他们使用MetaCritic和搜索结果信息来收集有关音乐节及其乐队表演的数据。 收集完所有数据后,他们将数据导入Tableau中以创建Vizualization(嵌入在下面)。

5.传播病毒并改变世界 (5. Make Viral Content and Change the World)
import.io created a dataset with all the men and women listed on Forbes’ list of The World’s Billionaires. Then they gave that data to Oxfam, who used that data to find deeper relationships between those who are well off, and those less fortunate. The Guardian picked up on this, and used the findings to write an interesting article about poverty in Britain. You can read more about the dataset and Oxfam on the import.io blog.
import.io创建了一个数据集,其中列出了《福布斯》全球“亿万富翁”名单中列出的所有男性和女性。 然后他们将数据提供给乐施会 , 乐施会使用该数据在富裕人士和不幸者之间找到更深层次的关系。 卫报对此有所了解,并利用调查结果撰写了一篇有关英国贫困的有趣文章。 您可以在import.io博客上阅读有关数据集和乐施会的更多信息。
结论 (Conclusion)
Data is everywhere, but difficulties in collection and organization often prevent us from using it to our advantage. With import.io, the headaches of finding and using large datasets are gone. Now making APIs, crawling the web, and using automation to collect data from an authenticated source, is a point and a click away.
数据无处不在,但是收集和组织上的困难常常使我们无法利用数据来获取优势。 有了import.io,查找和使用大型数据集的麻烦就消除了。 现在,创建API,爬网和使用自动化从经过身份验证的源中收集数据是一件容易的事,只需单击即可。
Over to you: What would you build with easily aggregated web data?
交给您:易于聚合的Web数据将为您构建什么?
翻译自: https://www.sitepoint.com/5-innovative-ways-use-web-data/
web数据传输的几种方式















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









