





爬网工具
Before web based API's became the prominent way of sharing data between services we had web scraping. Web scraping is a technique in data extraction where you pull information from websites.
在基于Web的API成为在服务之间共享数据的主要方式之前,我们曾进行过Web抓取。 Web抓取是数据提取中的一种技术,您可以从其中提取信息。
There are many ways this can be accomplished. It can be done manually by copy and pasting data from a website, using specialized software, or building your own scripts to scrape data. In this tutorial, we will be showing you how to build a simple web scraper that gets some general movie information from IMDB. The technologies we will be using to accomplish this are:
有许多方法可以实现。 可以通过使用专用软件从网站复制和粘贴数据来手动完成此操作,也可以构建自己的脚本来刮取数据。 在本教程中,我们将向您展示如何构建一个简单的Web抓取工具 ,以从IMDB中获取一些常规电影信息。 我们将用来实现这一目标的技术是:
- NodeJS 节点JS
- ExpressJS: The Node framework that everyone uses and loves. ExpressJS :每个人都使用并喜欢的Node框架。
- Request: Helps us make HTTP calls 请求 :帮助我们进行HTTP调用
- Cheerio: Implementation of core jQuery specifically for the server (helps us traverse the DOM and extract data) Cheerio :专门针对服务器的核心jQuery的实现(帮助我们遍历DOM并提取数据)
建立 (Setup)
Our setup will be pretty simple. If you're already familiar with NodeJS, go ahead and setup your project and include Express, Request and Cheerio as your dependencies.
我们的设置将非常简单。 如果您已经熟悉NodeJS,请继续设置您的项目,并包括Express , Request和Cheerio作为您的依赖项。
Here is our package.json file to get all the dependencies we need for our project.
这是我们的package.json文件,用于获取我们项目所需的所有依赖项。
{
"name" : "node-web-scrape",
"version" : "0.0.1",
"description" : "Scrape le web.",
"main" : "server.js",
"author" : "Scotch",
"dependencies" : {
"express" : "latest",
"request" : "latest",
"cheerio" : "latest"
}
}With your package.json file all ready to go, just install your dependencies with:
准备好package.json文件后,只需使用以下命令安装依赖项:
npm install
npm install
With that setup, let's take a look at what we'll be creating. In this tutorial, we will make a single request to IMDB and get:
通过该设置,让我们看一下将要创建的内容。 在本教程中,我们将向IMDB发出单个请求,并获得:
- name of a movie 电影名称
- release year 发行年份
- IMDB community rating IMDB社区评分
Once we compile this information, we will save it to a JSON file on our computer. Please see the code examples below for our setup. For this tutorial we will not have a front-end user interface and will rely on our command window to guide us.
编译此信息后,我们会将其保存到计算机上的JSON文件中 。 请参阅下面的代码示例以进行设置。 对于本教程,我们将没有前端用户界面,并将依靠我们的命令窗口来指导我们。
我们的应用 (Our Application)
Our web scraper is going to be very minimalistic. The basic flow will be as follows:
我们的网页抓取工具将非常简约。 基本流程如下:
- Launch web server 启动Web服务器
- Visit a URL on our server that activates the web scraper 在我们的服务器上访问一个可激活网络抓取工具的URL
- The scraper will make a request to the website we want to scrape 抓取工具将向我们要抓取的网站发出请求
- The request will capture the HTML of the website and pass it along to our server 该请求将捕获网站HTML并将其传递给我们的服务器
- We will traverse the DOM and extract the information we want 我们将遍历DOM并提取所需的信息
- Next, we will format the extracted data into a format we need 接下来,我们将提取的数据格式化为所需的格式
- Finally, we will save this formatted data into a JSON file on our machine 最后,我们将格式化后的数据保存到计算机上的JSON文件中
If you've been following our other NodeJS tutorials you should be pretty familiar with how to structure of an application works. For this tutorial, we will set the entire logic in our server.js file.
如果您一直在关注其他NodeJS教程,那么您应该非常熟悉如何构建应用程序的结构。 对于本教程,我们将在server.js文件中设置整个逻辑。
var express = require('express');
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var app = express();
app.get('/scrape', function(req, res){
//All the web scraping magic will happen here
})
app.listen('8081')
console.log('Magic happens on port 8081');
exports = module.exports = app;提出要求 (Making the Request)
Now that we have the boilerplate of the application done, let's get into the fun stuff. We are now on Step 3, and that is making the request to the external website we would like to scrape.
现在我们已经完成了应用程序的样板,让我们开始学习有趣的东西。 我们现在进入第3步,即向我们要抓取的外部网站发出请求 。
var express = require('express');
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var app = express();
app.get('/scrape', function(req, res){
// The URL we will scrape from - in our example Anchorman 2.
url = 'http://www.imdb.com/title/tt1229340/';
// The structure of our request call
// The first parameter is our URL
// The callback function takes 3 parameters, an error, response status code and the html
request(url, function(error, response, html){
// First we'll check to make sure no errors occurred when making the request
if(!error){
// Next, we'll utilize the cheerio library on the returned html which will essentially give us jQuery functionality
var $ = cheerio.load(html);
// Finally, we'll define the variables we're going to capture
var title, release, rating;
var json = { title : "", release : "", rating : ""};
}
})
})
app.listen('8081')
console.log('Magic happens on port 8081');
exports = module.exports = app;The request function takes two parameters, the URL and a callback. For the URL parameter we will set the link of the IMDB movie we want to extract information from. In the callback, we will capture 3 parameters: error, response, and html.
request函数带有两个参数,即URL和callback 。 对于URL参数,我们将设置我们要从中提取信息的IMDB电影的链接。 在回调中 ,我们将捕获3个参数: error , response和html 。
遍历DOM (Traversing the DOM)
电影标题 (Movie Title)
Now we are ready to start traversing the DOM and extracting information. First let's get the movie name. We'll head over to IMDB, open up Developer Tools and inspect the movie title element. We will be looking for a unique element that will help us single out the movie title. We notice that the <h1> tag is our best bet for the movie title and that the class header is unique. This seems like good starting spot.
现在,我们准备开始遍历DOM并提取信息。 首先让我们获取电影名称。 我们将前往IMDB,打开“开发人员工具”并检查电影标题元素。 我们将寻找一个独特的元素 ,以帮助我们挑选电影标题。 我们注意到<h1>标签是电影标题的最佳选择,并且类header是唯一的。 这似乎是一个很好的起点。
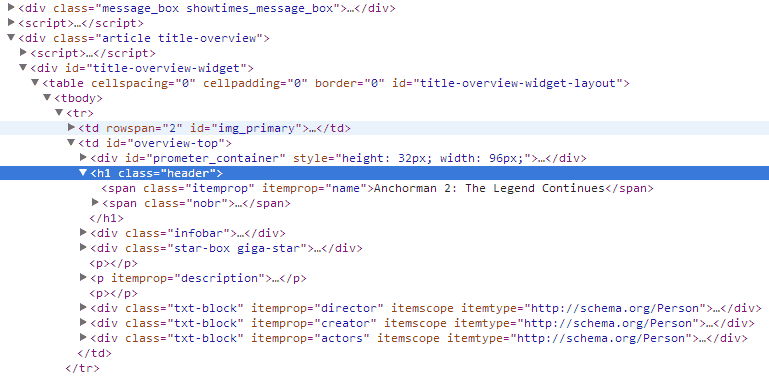
var express = require('express');
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var app = express();
app.get('/scrape', function(req, res){
url = 'http://www.imdb.com/title/tt1229340/';
request(url, function(error, response, html){
if(!error){
var $ = cheerio.load(html);
var title, release, rating;
var json = { title : "", release : "", rating : ""};
// We'll use the unique header class as a starting point.
$('.header').filter(function(){
// Let's store the data we filter into a variable so we can easily see what's going on.
var data = $(this);
// In examining the DOM we notice that the title rests within the first child element of the header tag.
// Utilizing jQuery we can easily navigate and get the text by writing the following code:
title = data.children().first().text();
// Once we have our title, we'll store it to the our json object.
json.title = title;
})
}
})
})
app.listen('8081')
console.log('Magic happens on port 8081');
exports = module.exports = app;发行年份 (Release Year)
Now we are able to get the movie title. Next, we'll repeat the process this time trying to find a unique element in the DOM for the movie release year. We notice that the year is also contained within the <h1> tag and we also notice that the year is contained within the last element of the header. This gives us enough information to extract the year by writing this code:
现在我们可以获取电影标题了 。 接下来,这次我们将重复此过程,以尝试在电影发行年份的DOM中查找唯一元素。 我们注意到年份也包含在<h1>标记内,并且我们还注意到年份包含在标题的最后一个元素内。 通过编写以下代码,这为我们提供了足够的信息来提取年份:
var express = require('express');
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var app = express();
app.get('/scrape', function(req, res){
url = 'http://www.imdb.com/title/tt1229340/';
request(url, function(error, response, html){
if(!error){
var $ = cheerio.load(html);
var title, release, rating;
var json = { title : "", release : "", rating : ""};
$('.header').filter(function(){
var data = $(this);
title = data.children().first().text();
// We will repeat the same process as above. This time we notice that the release is located within the last element.
// Writing this code will move us to the exact location of the release year.
release = data.children().last().children().text();
json.title = title;
// Once again, once we have the data extract it we'll save it to our json object
json.release = release;
})
}
})
})
app.listen('8081')
console.log('Magic happens on port 8081');
exports = module.exports = app;社区评价 (Community Rating)
Finally, to get the community rating, we repeat the above process. This time though, we notice that there is a very unique class name that will help us get the information really easily. The class name is .star-box-giga-star. So let's write some code to extract that information.
最后,要获得社区评级,我们重复上述过程。 但是,这次,我们注意到有一个非常独特的类名,它将帮助我们真正轻松地获取信息。 类名是.star-box-giga-star 。 因此,让我们编写一些代码来提取该信息。
var express = require('express');
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var app = express();
app.get('/scrape', function(req, res){
url = 'http://www.imdb.com/title/tt1229340/';
request(url, function(error, response, html){
if(!error){
var $ = cheerio.load(html);
var title, release, rating;
var json = { title : "", release : "", rating : ""};
$('.header').filter(function(){
var data = $(this);
title = data.children().first().text();
release = data.children().last().children().text();
json.title = title;
json.release = release;
})
// Since the rating is in a different section of the DOM, we'll have to write a new jQuery filter to extract this information.
$('.star-box-giga-star').filter(function(){
var data = $(this);
// The .star-box-giga-star class was exactly where we wanted it to be.
// To get the rating, we can simply just get the .text(), no need to traverse the DOM any further
rating = data.text();
json.rating = rating;
})
}
})
})
app.listen('8081')
console.log('Magic happens on port 8081');
exports = module.exports = app;That's all there is to it. If you wanted to extract more information, you can do so by repeating the steps we did above.
这里的所有都是它的。 如果您想提取更多信息,可以通过重复上面的步骤来完成。
- Find a unique element or attribute on the DOM that will help you single out the data you need 在DOM上找到一个唯一的元素或属性,以帮助您挑选所需的数据
- If no unique element exists on the particular tag, find the closest tag that does and set that as your starting point 如果特定标签上不存在唯一元素,请找到最接近的标签并将其设置为起点
- If needed, traverse the DOM to get to the data you would like to extract 如果需要,遍历DOM以获取要提取的数据
格式化和提取 (Formatting and Extracting)
Now that we have the data extracted, let's format it and save it to our project folder. We have been storing our extracted data to a variable called json. Let's save the data in this variable to our project folder. You'll notice earlier that we required the fs library. If you didn't know what this was for, this library gives us access to our computer's file system. Take a look at the code below to see how we write files to the file system.
现在我们已经提取了数据,让我们对其进行格式化并将其保存到我们的项目文件夹中。 我们已经将提取的数据存储到一个名为json的变量中。 让我们将这个变量中的数据保存到我们的项目文件夹中。 您会在前面注意到我们需要fs库。 如果您不知道这是干什么的,可以使用此库访问我们计算机的文件系统。 看下面的代码,看看我们如何将文件写入文件系统。
var express = require('express');
var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var app = express();
app.get('/scrape', function(req, res){
url = 'http://www.imdb.com/title/tt1229340/';
request(url, function(error, response, html){
if(!error){
var $ = cheerio.load(html);
var title, release, rating;
var json = { title : "", release : "", rating : ""};
$('.header').filter(function(){
var data = $(this);
title = data.children().first().text();
release = data.children().last().children().text();
json.title = title;
json.release = release;
})
$('.star-box-giga-star').filter(function(){
var data = $(this);
rating = data.text();
json.rating = rating;
})
}
// To write to the system we will use the built in 'fs' library.
// In this example we will pass 3 parameters to the writeFile function
// Parameter 1 : output.json - this is what the created filename will be called
// Parameter 2 : JSON.stringify(json, null, 4) - the data to write, here we do an extra step by calling JSON.stringify to make our JSON easier to read
// Parameter 3 : callback function - a callback function to let us know the status of our function
fs.writeFile('output.json', JSON.stringify(json, null, 4), function(err){
console.log('File successfully written! - Check your project directory for the output.json file');
})
// Finally, we'll just send out a message to the browser reminding you that this app does not have a UI.
res.send('Check your console!')
}) ;
})app.listen('8081') console.log('Magic happens on port 8081'); exports = module.exports = app;
app.listen('8081')console.log('魔术发生在端口8081'); 出口=模块。出口=应用;
With this code in place you are set to scrape and save the scraped data. Let's start up our node server, navigate to http://localhost:8081/scrape and see what happens.
使用此代码后,您就可以抓取并保存抓取的数据。 让我们启动节点服务器,导航到http://localhost:8081/scrape ,看看会发生什么。
- If everything went smoothly your browser should display a message telling you to check your command prompt. 如果一切顺利,浏览器将显示一条消息,告诉您检查命令提示符。
- When you check your command prompt you should see a message saying that your file was successfully written and that you should check your project folder. 当您检查命令提示符时,您应该看到一条消息,说明您的文件已成功写入,并且您应检查项目文件夹。
- Once you get to your project folder you should see a new file created called
output.json. 进入项目文件夹后,您应该会看到一个名为output.json的新文件。 - Opening this file, will give you a nicely formatted JSON document that will have the extracted data. 打开此文件,将为您提供格式良好的JSON文档,其中将包含提取的数据。
Congrats! You just wrote your first web scraper!
恭喜! 您刚刚编写了第一个网络刮板!
放在一起 (Putting It All Together)
In this tutorial, we built a simple a web scraper that extracted movie information from an IMBD page. We covered using the Request and Cheerio libraries to make external requests and add jQuery functionality to our NodeJS server. We showed you how to traverse the DOM using jQuery in Node and how to write to the file system. I hope you enjoyed this article. Feel free to ask any questions below.
在本教程中,我们构建了一个简单的网络抓取工具,该抓取工具从IMBD页面提取了电影信息。 我们介绍了使用Request和Cheerio库进行外部请求并将jQuery功能添加到我们的NodeJS服务器。 我们向您展示了如何在Node中使用jQuery遍历DOM以及如何写入文件系统。 希望您喜欢这篇文章。 随时问以下任何问题。
Web爬网注意事项 ( A Note on Web Scraping )
Web scraping falls within a gray area of the law. Scraping data for personal use within limits is generally ok but you should always get permission from the website owner before doing so. Our example here was very minimalistic in a sense (we only made one request to IMDB) so that it does not interfere with IMDB's operations. Please scrape responsibly.
刮网属于法律的灰色区域。 通常,在限制范围内收集供个人使用的数据是可以的,但是在这样做之前,您应该始终获得网站所有者的许可。 在某种意义上,这里的示例非常简单(我们仅向IMDB发出了一个请求),因此它不会干扰IMDB的操作。 请负责任地抓取。
翻译自: https://scotch.io/tutorials/scraping-the-web-with-node-js
爬网工具

















 1662
1662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









