





cte sql
介绍 (Introduction)
Have you ever written up a complex query using Common Table Expressions (CTEs) only to be disappointed by the performance? Have you been blaming the CTE? This article looks at that problem to show that it is a little deeper than a particular syntax choice and offers some tips on how to improve performance.
您是否曾经使用通用表表达式(CTE)编写了一个复杂的查询,只是对性能感到失望? 您一直在指责CTE吗? 本文着眼于该问题,表明它比特定的语法选择要深一些,并提供了一些有关如何提高性能的提示。
再访CTE (CTEs Revisited)
Common Table Expressions first appeared in SQL Server 2005. Combined with the WITH statement, they provide a way to reorganize a complicated hierarchy of sub queries into an easy-to-read linear form. CTEs also allow for recursive behavior, though that is beyond the scope of this article. Quoting from Books Online, a CTE:
Common Table Expressions最早出现在SQL Server 2005中。与WITH语句结合使用,它们提供了一种将子查询的复杂层次结构重组为易于阅读的线性形式的方法。 CTE还允许进行递归行为,尽管这不在本文的讨论范围之内。 引用CTE在线丛书:
Specifies a temporary named result set, known as a common table expression (CTE). This is derived from a simple query and defined within the execution scope of a single SELECT, INSERT, UPDATE, or DELETE statement. This clause can also be used in a CREATE VIEW statement as part of its defining SELECT statement. A common table expression can include references to itself. This is referred to as a recursive common table expression.
指定一个临时的命名结果集,称为公用表表达式(CTE)。 这是从一个简单的查询派生的,并在单个SELECT,INSERT,UPDATE或DELETE语句的执行范围内定义。 此子句也可以在CREATE VIEW语句中用作其定义的SELECT语句的一部分。 公用表表达式可以包含对其自身的引用。 这称为递归公用表表达式。
Generally, you set up a query using CTEs like this:
通常,您可以使用如下CTE设置查询:
WITH
cte1 AS (
SELECT …
),
Cte2 AS (
SELECT …
),
…
SELECT …
FROM cte1
JOIN cte2
ON cte1.<join column> = cte2.<join column>
You can have any number of CTEs and the final statement (which can be any valid DML) can use all, some or none of them. Assuming there are just two, as above, this can be rewritten using subqueries:
您可以具有任意数量的CTE,最终语句(可以是任何有效的DML)可以使用全部,部分或不使用它们。 假设只有两个,如上所述,可以使用子查询将其重写:
SELECT …
FROM (
SELECT …
) cte1
JOIN (
SELECT …
) cte2
ON cte1.<join column> = cte2.<join column>
There is no difference between the first query and the second as far as how it is parsed, compiled and executed. The execution plans will be identical. The difference is in readability. When subqueries are complex, it can be easier to pull them out and put them into CTEs then combine them in a WITH statement.
就如何解析,编译和执行而言,第一个查询和第二个查询之间没有区别。 执行计划将是相同的。 区别在于可读性。 当子查询很复杂时,将它们拉出并放入CTE中,然后将它们组合在WITH语句中会更容易。
性能? (Performance?)
Maybe you have written or debugged a CTE that seems to run slowly. Or, perhaps you’ve seen postings in some SQL Server forum complaining that some CTE runs slowly. What the complainant is really suggesting is that somehow when SQL Server compiles a query built from CTEs it does it differently than the same query using sub-queries and somehow does a worse job of it. That is simply not the case. In fact, if the forum poster had reformatted the query into (possibly nested) subqueries and not use the WITH…CTE structure, the same performance characteristics would no doubt have been observed.
也许您编写或调试了运行缓慢的CTE。 或者,也许您在某些SQL Server论坛中看到过一些帖子,抱怨某些CTE运行缓慢。 投诉人真正暗示的是,当SQL Server编译通过CTE构建的查询时,它与使用子查询的同一查询的执行方式有所不同,并且在某种程度上做得更差。 事实并非如此。 实际上,如果论坛发布者已将查询重新格式化为(可能是嵌套的)子查询,而不使用WITH…CTE结构,则无疑会观察到相同的性能特征。
So, why does it run so slowly! Good question. To try to understand why, let’s look at a simple example:
所以, 为什么它运行这么慢! 好问题。 为了理解原因,让我们看一个简单的例子:
DECLARE @t TABLE (id INT, name SYSNAME);
INSERT INTO @t (id, name)
SELECT TOP(1000000) a.object_id, a.name
FROM sys.all_columns a, sys.all_columns b;
WITH cte
AS (
SELECT id, name
FROM @t
)
SELECT c.id, c.name
FROM cte c
JOIN sys.all_columns s ON c.name = s.name
What does this do? After the table variable declaration, it populates the table with the first one million rows from the Cartesian product of the sys.all_columns view. Depending on how big the database is that you run this against there may be thousands, tens of thousands and maybe many more rows in that table. A million rows in the result is enough for our purposes. After populating the table variable, the script continues in a WITH statement using a CTE that just pulls rows from the table variable. Doesn’t look that bad, right? Before you run it on some handy production system, though, read on.
这是做什么的? 在表变量声明之后,它将使用sys.all_columns视图的笛卡尔积的前一百万行填充表。 根据您针对数据库运行的规模,该表中可能有成千上万,数万甚至更多的行。 结果达到一百万行就足以满足我们的目的。 填充表变量后,脚本使用仅从表变量中提取行的CTE在WITH语句中继续。 看起来还不错吧? 但是,在一些方便的生产系统上运行它之前,请继续阅读。
A little math will help you see what’s at stake. If I just run:
进行一些数学运算将帮助您了解问题所在。 如果我只是跑步:
SELECT COUNT(*)FROM sys.all_columns;
I get a result of 7364 on my system – and that’s just LocalDB! Since that is being joined with the Cartesian product of the same view, that could result in 7.364 billion rows. I let it run on my own (non-production!) system. I had to stop it before it could complete. I admit to being a little impatient!
我在系统上得到7364的结果–就是LocalDB! 由于将其与相同视图的笛卡尔乘积相结合,因此可能导致73.64 亿行。 我让它在我自己的(非生产!)系统上运行。 我不得不停止它才能完成。 我承认有点不耐烦!
Curious to see what’s going on behind the curtain, I displayed the execution plan. It looks like this:
好奇地想知道幕后是怎么回事,我展示了执行计划。 看起来像这样:
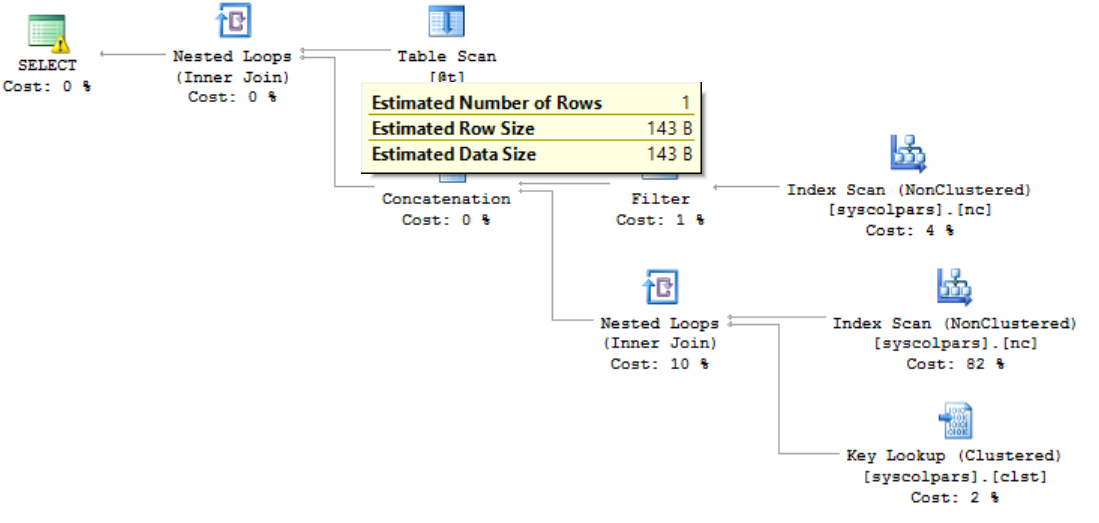
Note that a Nested Loops operator was selected and that the estimated number of rows coming from my table variable is 1! Even though I just loaded it with 1 million rows! How can this be? The sad truth is that SQL Server does not maintain statistics for table variables, so at the time the query is compiled, it does not know how may rows are really there. If I had just one row, a nested loop would be fine! Here’s how that’s defined in BOL:
请注意,已选择一个嵌套循环运算符,并且来自我的表变量的估计行数为1! 即使我刚刚加载了100万行! 怎么会这样? 可悲的事实是,SQL Server不会维护表变量的统计信息,因此在编译查询时,它不知道行的实际位置。 如果我只有一行,那么嵌套循环就可以了! 这是在BOL中的定义方式:
The nested loops join, also called nested iteration, uses one join input as the outer input table (shown as the top input in the graphical execution plan) and one as the inner (bottom) input table. The outer loop consumes the outer input table row by row. The inner loop, executed for each outer row, searches for matching rows in the inner input table.
嵌套循环联接,也称为嵌套迭代,使用一个联接输入作为外部输入表(在图形执行计划中显示为顶部输入),使用一个联接输入作为内部(底部)输入表。 外循环逐行消耗外输入表。 对每个外部行执行的内部循环在内部输入表中搜索匹配的行。
So, for every one of the million rows in my table variable, SQL will do a scan of the object catalog view. Not! Good!
因此,对于表变量中的每一百万行,SQL都会扫描对象目录视图。 不! 好!
My second attempt replaces the table variable with a temp table. The script is identical except that it starts off with:
我的第二次尝试用临时表替换了表变量。 该脚本是相同的,除了它的开头是:
CREATE TABLE #t (id INT, name SYSNAME);
And replaces @t with #t in the rest of the script. This time the execution plan looks like this:
并在脚本的其余部分中将@t替换为#t。 这次执行计划如下所示:

This looks better! For one thing, the estimated number of rows coming from the temporary table is correct. For another, the complier chose a hash match – a much better choice for this join than the table scans we had before.
这看起来更好! 一方面,来自临时表的估计行数是正确的。 另一个原因是,编译器选择了散列匹配-这种连接的选择比我们以前进行的表扫描要好得多。
I let this query run to completion. It ran for just over 3 minutes on my (admittedly old and slow!) laptop and produced 16.7 billion rows before hitting an out of memory error (that’s a lot of rows!) Reducing the number of rows in the temporary table to 100,000 allowed it to finish in a comfortable nine seconds.
我让这个查询运行完毕。 它在我的笔记本电脑上运行了仅3分钟多(老旧的,速度很慢!),产生了167亿行,然后遇到内存不足错误(很多行!),将临时表中的行数减少到100,000可允许它在舒适的9秒内完成。
All of this means that there is nothing wrong with the CTE construct; something else must be going on. That something else is statistics. The SQL Server compiler uses statistics (e.g. row counts) to inform the optimizer. However, statistics are not created or updated for table variables. This is the “Aha!” moment! Changing the script to use a temporary table instead of a table variable meant that statistics were available to choose a better execution plan.
所有这些意味着CTE构造没有任何问题。 其他事情一定要继续下去。 那是统计。 SQL Server编译器使用统计信息(例如行数)来通知优化器。 但是,不会为表变量创建或更新统计信息。 这就是“啊哈!” 时刻! 更改脚本以使用临时表代替表变量意味着可以使用统计信息来选择更好的执行计划。
深层发掘 (Digging Deeper)
That something else is in the little phrase near at the beginning of the quotation from BOL:
BOL报价单开头附近的一句话中还有其他内容:
Specifies a temporary named result set
指定一个临时的命名结果集
Why is that significant? Can you think of another type of temporary named result set? How about a table variable! We already found out that table variables, which have no statistics, can wreak havoc with execution plans because of incorrect row counts. However, a CTE holds something similar in a temporary result set. When compiling a complex CTE, it may not have enough information available to derive an optimal plan. When I think that is happening, here’s what I do:
为什么这么重要? 您能想到另一种类型的临时命名结果集吗? 一个表变量呢! 我们已经发现,没有统计信息的表变量会由于行计数错误而严重破坏执行计划。 但是,CTE在临时结果集中拥有类似的内容。 编译复杂的CTE时,可能没有足够的信息来推导最佳计划。 当我认为发生这种情况时,请执行以下操作:
SELECT * FROM <CTE name>Just before the main query that pulls the CTEs together and highlighting and running the script down to that point.
就在将CTE聚集在一起并突出显示并运行脚本的主要查询之前。
- Verify that the culprit is correctly written with proper predicates. 验证是否使用正确的谓词正确书写了罪魁祸首。
- Ensure that the predicates are indexed, if possible (more on that later). 如果可能的话,请确保对谓词进行索引(稍后再介绍)。
- Resume testing from that CTE onward until the end. 从该CTE开始继续测试,直到结束。
There is at least one problem that cannot be fixed with this process. It is not always possible to ensure that all predicates are indexed, especially for derived results. In that case, there is another option to break the bottleneck:
此过程无法解决至少一个问题。 并非总是能够确保所有谓词都被索引,特别是对于派生结果。 在这种情况下,还有另一种方法可以打破瓶颈:
This will mean restructuring your query. Basically, you will take the top half of the query and write the results to a temporary table, then index the table, then resume the query, starting with the temporary table. For example, suppose I have:
这将意味着重组查询。 基本上,您将使用查询的上半部分并将结果写入临时表,然后对该表建立索引,然后从临时表开始继续查询。 例如,假设我有:
WITH CTE1 AS (
SELECT …
),
CTE2 AS (
SELECT …
), …
CTEn AS (
SELECT …
)
/* Main Query */
SELECT …
FROM CTE1
JOIN CTE2 …
Assume further that the problem is at CTE10. This will become:
进一步假设问题出在CTE10。 这将成为:
WITH CTE1 AS (
SELECT …
),
CTE2 AS (
SELECT …
), …
CTE9 AS (
SELECT …
)
SELECT …
INTO #CTE9
FROM CTE1
JOIN CTE2 …
Now that we have the results so far in a temporary table, index it:
到目前为止,我们已经将结果保存在临时表中,将其编入索引:
CREATE INDEX IX_#CTE9 ON #CTE9(col1, col2, …)
Now, let’s finish the query:
现在,让我们完成查询:
WITH CTE9 AS (
SELECT …
FROM #CTE9
),
CTE10 AS (
SELECT …
), …
CTEn AS (
SELECT …
)
/* Main Query */
SELECT …
FROM CTE9,
JOIN CTE10, …
Note that you may still have to continue the process outlined above until you reach your performance goals.
请注意,在达到性能目标之前,您可能仍必须继续上述过程。
还有另一件事 (And Another Thing)
Whatever you do, get used to reading Execution plans. There is a wealth of information there and hundreds if not thousands of great resources on understanding them. As a final sanity check, though, right-click on the left-most entry in the graphical execution plan. That will likely be a SELECT, UPDATE, INSERT or DELETE. Now in the context menu, choose Properties. Make sure that you see this, about half-way down:
无论您做什么,都要习惯阅读执行计划。 那里有大量的信息,还有成百上千个(如果不是成千上万的)理解这些资源。 不过,作为最终的检查,请右键单击图形执行计划中最左侧的条目。 这可能是SELECT,UPDATE,INSERT或DELETE。 现在,在上下文菜单中,选择“属性”。 确保您看到了大约一半的内容:
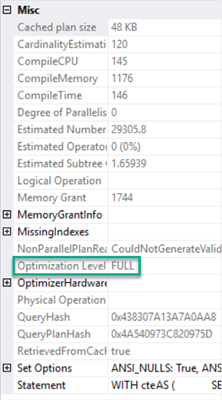
If you don’t see Optimization Level FULL, it is an indicator that your query is too complex. Consider breaking it up some more, using the temporary table technique outlined above.
如果您没有看到“优化级别已满”,则表明您的查询过于复杂。 考虑使用上面概述的临时表技术对其进行分解。
结论 (Conclusion)
Common Table Expressions are just another way to write subqueries. They are not magic, nor does SQL Server treat them any differently from normal, nested subqueries, except for their recursive cousins. CTEs can make code easier to read and maintain, since, when used properly, you can separate concerns by CTE. (Notice how I snuck in an Object-Oriented programming principle?)
公用表表达式只是编写子查询的另一种方法。 它们不是魔术,除了递归表亲之外,SQL Server对待它们与常规嵌套子查询也没有任何区别。 CTE可以使代码更易于阅读和维护,因为如果使用得当,您可以按CTE分离关注点。 (请注意,我是如何遵循面向对象编程原理的?)
When they perform badly, though, don’t blame the CTE. Dig deeper to understand what is going on beneath the covers. The execution plan is the perfect way to do that.
但是,当它们表现不佳时,不要怪CTE。 深入挖掘以了解幕后情况。 执行计划是实现此目标的理想方法。
cte sql
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









