





 本文详细介绍了SQL数据类型,包括内置数据类型、用户定义的别名数据类型和CLR数据类型。文章强调了选择正确数据类型的重要性,讨论了转换、空值、稀疏列的注意事项,并提供了SQL数据类型转换和稀疏列处理的示例。同时,还讲解了如何创建自定义SQL数据类型。
本文详细介绍了SQL数据类型,包括内置数据类型、用户定义的别名数据类型和CLR数据类型。文章强调了选择正确数据类型的重要性,讨论了转换、空值、稀疏列的注意事项,并提供了SQL数据类型转换和稀疏列处理的示例。同时,还讲解了如何创建自定义SQL数据类型。
This article is about many different SQL data types that we use when working with SQL Server. We will start with a quick overview and go through some stuff like categories of data types, what objects we can work with, and how to create our own custom data types.
本文介绍了在使用SQL Server时我们使用的许多不同SQL数据类型。 我们将从快速概述开始,并介绍诸如数据类型类别,可以使用的对象以及如何创建我们自己的自定义数据类型之类的内容。
SQL数据类型概述 (SQL data types overview)
To kick things off, let’s talk about what is a data type. If I had to define it, I’d say that data type determines the kind, size, and range of data that can be stored in an object. So, this brings us to a question of objects that have data types:
首先,让我们谈谈什么是数据类型。 如果必须定义它,我会说数据类型确定可以存储在对象中的数据的类型,大小和范围。 因此,这使我们想到了具有数据类型的对象的问题:
- Columns 列
- Variables 变数
- Expressions 表达方式
- Parameters 参量
These four SQL data types of objects are of the highest importance. Columns are obviously for tables. Every time we create a variable, we also need to assign a data type to it. In addition to those, we have expressions and parameters to conclude the list of objects that are going to hold data and therefore we need to specify what kind of data they will contain.
这四种SQL数据类型的对象具有最高的重要性。 列显然用于表。 每次创建变量时,我们还需要为其分配数据类型。 除此之外,我们还有表达式和参数来总结要保存数据的对象列表,因此我们需要指定它们将包含哪种数据。
Moving on, let’s see the three categories of data types:
继续,让我们看一下数据类型的三类:
- Built-in data types 内置数据类型
- User-defined alias data types 用户定义的别名数据类型
- User-defined common language runtime (CLR) data types 用户定义的公共语言运行时(CLR)数据类型
There is not much to say about the first category. These are data types that we’re all used to. Below is a chart that lists well known built-in data types and their ranges:
关于第一类没有太多要说的。 这些是我们都习惯的数据类型。 下面的图表列出了众所周知的内置数据类型及其范围:
Data category | SQL data type | Size | Value range |
Exact numeric | Bit | 1 | 1, 0, or NULL |
Tinyint | 1 | 0 to 255 | |
Smallint | 2 | -2^15 (-32,768) to 2^15-1 (32,767) | |
Int | 4 | -2^31 (-2,147,483,648) to 2^31-1 (2,147,483,647) | |
Bigint | 8 | -2^63 (-9,223,372,036,854,775,808) to 2^63-1 (9,223,372,036,854,775,807) | |
Smallmoney | 4 | – 214,748.3648 to 214,748.3647 | |
Money | 8 | -922,337,203,685,477.5808 to 922,337,203,685,477.5807 | |
numeric[ (p[ ,s] )] | 5-17 | ||
decimal [ (p[ ,s] )] | 5-17 | ||
Approximate numeric | Float | 4-8 | – 1.79E+308 to -2.23E-308, 0 and 2.23E-308 to 1.79E+308 |
Real/float(24) | 4 | – 3.40E + 38 to -1.18E – 38, 0 and 1.18E – 38 to 3.40E + 38 | |
Character strings | char [ ( N ) ] | N | N = 1 to 8000 non-Unicode characters bytes |
nvarchar [ ( N | max ) ] | N or 2^31-1 | N = 1 to 8000 non-Unicode characters bytes Max = 2^31-1 bytes (2 GB) non-Unicode characters bytes | |
Text | 2^31-1 | 1 to 2^31-1 (2,147,483,647) non-Unicode characters bytes | |
Unicode character strings | nchar [ ( N ) ] | N | N = 1 to 4000 UNICODE UCS-2 bytes |
nvarchar [ ( N | max ) ] | N or 2^31-1 | N = 1 to 4000 UNICODE UCS-2 bytes 1 to 2^31-1 (2,147,483,647) UNICODE UCS-2 bytes | |
Ntext | 2^30-1 | Maximum size 2^30 – 1 (1,073,741,823) bytes | |
Binary strings | binary [ ( N ) ] | N | N = 1 to 8000 bytes |
varbinary [ ( N | max) ] | N or 2^31-1 | N = 1 to 8000 bytes Max = 0 to 2^31-1 bytes | |
Image | 2^31-1 | 0 to 2^31-1 (2,147,483,647) bytes | |
Other data types | Uniqueidentifier | 16 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (hex decimal) |
Timestamp | 8 | binary(8) or varbinary(8) | |
rowversion | 8 | binary(8) or varbinary(8) | |
xml | 2^31-1 | xml( [ CONTENT | DOCUMENT ] xml_schema_collection ) | |
sql_variant | 8016 | data type that stores values of various SQL Server-supported data types | |
Hierarchyid | 892 | 6*logAn bits where n is child node | |
Cursor | |||
Table | |||
Sysname | 256 | ||
Date and time | Date | 3 | 0001-01-01 through 9999-12-31 |
time [ (fractional second precision) ] | 3 to 5 | 00:00:00.0000000 through 23:59:59.9999999 | |
Smalldatetime | 4 | Date: 1900-01-01 through 2079-06-06 Time: 00:00:00 through 23:59:59 | |
Datetime | 8 | Date: January 1, 1753, through December 31, 9999 Time: 00:00:00 through 23:59:59.997 | |
datetime2 [ (fractional seconds precision) ] | 6 to 8 | Date: 0001-01-01 through 9999-12-31 Time: 00:00:00 through 23:59:59.9999999 | |
datetimeoffset [ (fractional seconds precision) ] | 8 to 10 | Date: 0001-01-01 through 9999-12-31 Time: 00:00:00 through 23:59:59.9999999 Time zone offset: -14:00 through +14:00 | |
Spatial | Geography | 2^31-1 | |
Geometry | 2^31-1 |
资料类别 | SQL数据类型 | 尺寸 | 取值范围 |
精确数值 | 位 | 1个 | 1、0或NULL |
Tinyint | 1个 | 0至255 | |
Smallint | 2 | -2 ^ 15(-32,768)至2 ^ 15-1(32,767) | |
整数 | 4 | -2 ^ 31(-2,147,483,648)至2 ^ 31-1(2,147,483,647) | |
比金特 | 8 | -2 ^ 63(-9,223,372,036,854,775,808)至2 ^ 63-1(9,223,372,036,854,775,807) | |
小钱 | 4 | – 214,748.3648至214,748.3647 | |
钱 | 8 | -922,337,203,685,477.5808至922,337,203,685,477.5807 | |
数字[(p [,s])] | 5-17 | ||
十进制[(p [,s])] | 5-17 | ||
近似数值 | 浮动 | 4-8 | – 1.79E + 308至-2.23E-308、0和2.23E-308至1.79E + 308 |
实数/浮动(24) | 4 | – 3.40E + 38至-1.18E – 38、0和1.18E – 38至3.40E + 38 | |
字符串 | 字符[(N)] | ñ | N = 1至8000个非Unicode字符字节 |
nvarchar [(N | max)] | N或 2 ^ 31-1 | N = 1至8000个非Unicode字符字节 最大= 2 ^ 31-1字节(2 GB)非Unicode字符字节 | |
文本 | 2 ^ 31-1 | 1至2 ^ 31-1(2,147,483,647)非Unicode字符字节 | |
Unicode字符串 | nchar [(N)] | ñ | N = 1至4000 UNICODE UCS-2字节 |
nvarchar [(N | max)] | N或 2 ^ 31-1 | N = 1至4000 UNICODE UCS-2字节 1至2 ^ 31-1(2,147,483,647)UNICODE UCS-2字节 | |
文字 | 2 ^ 30-1 | 最大大小2 ^ 30 – 1(1,073,741,823)字节 | |
二进制字符串 | 二进制[(N)] | ñ | N = 1至8000字节 |
varbinary [(N | max)] | N或 2 ^ 31-1 | N = 1至8000字节 最大值= 0至2 ^ 31-1字节 | |
图片 | 2 ^ 31-1 | 0至2 ^ 31-1(2,147,483,647)字节 | |
其他数据类型 | 唯一标识符 | 16 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx(十六进制) |
时间戳记 | 8 | 二进制(8)或varbinary(8) | |
行版本 | 8 | 二进制(8)或varbinary(8) | |
XML文件 | 2 ^ 31-1 | xml([内容|文档] xml_schema_collection) | |
sql_variant | 8016 | 数据类型,用于存储各种SQL Server支持的数据类型的值 | |
等级制 | 892 | 6 * logAn位,其中n是子节点 | |
光标 | |||
表 | |||
系统名称 | 256 | ||
日期和时间 | 日期 | 3 | 0001-01-01至9999-12-31 |
时间[(分数秒精度)] | 3到5 | 00:00:00.0000000到23:59:59.9999999 | |
小日期时间 | 4 | 日期:1900年1月1日至2079年6月6日 时间:00:00:00至23:59:59 | |
约会时间 | 8 | 日期:1753年1月1日至9999年12月31日 时间:00:00:00至23:59:59.997 | |
| datetime2 [(小数 秒精度)] | 6至8 | 日期:0001-01-01至9999-12-31 时间:00:00:00至23:59:59.9999999 | |
datetimeoffset [(小数秒精度)] | 8至10 | 日期:0001-01-01至9999-12-31 时间:00:00:00至23:59:59.9999999 时区偏移量:-14:00至+14:00 | |
空间的 | 地理 | 2 ^ 31-1 | |
几何 | 2 ^ 31-1 |
- Note: Text, Ntext, and Image SQL data type will be removed in a future version of SQL Server. It is advisable to avoid using these data types in new development work. Use varchar(max), nvarchar(max), and varbinary(max) data types instead.
- 注意:在将来SQL Server版本中,将删除Text,Ntext和Image SQL数据类型。 建议避免在新的开发工作中使用这些数据类型。 请改用varchar(max),nvarchar(max)和varbinary(max)数据类型。
Next, we have what we mentioned at the beginning, and those are user-defined alias data types that allow us to create our own data types based on the built-in list above.
接下来,我们有开头提到的内容,这些是用户定义的别名数据类型,使我们可以根据上面的内置列表创建自己的数据类型。
The last category is user-defined common language runtime (CLR) data types that allow us to create our own data types using the .NET Framework. This is a bit more complicated than the above and requires programming skills to build an assembly, register that assembly inside the SQL Server, create a new SQL data type based on that assembly and then we can start using the newly created data type in SQL Server.
最后一类是用户定义的公共语言运行时(CLR)数据类型,它使我们可以使用.NET Framework创建自己的数据类型。 这比上面的操作要复杂一些,并且需要具备一定的编程技能才能构建程序集,在SQL Server中注册该程序集,基于该程序集创建新SQL数据类型,然后才能开始在SQL Server中使用新创建的数据类型。 。
SQL数据类型注意事项 (SQL data types considerations)
Let’s move on to the next section which is basically just theory, but definitely something that you should think about when storing data either permanently or temporarily.
让我们继续进行下一部分,这基本上只是理论上的问题,但绝对是永久性或临时性存储数据时应考虑的事项。
转换次数 (Conversion)
As a database developer, one of the most common routines when writing code is converting. Conversion takes place when data from an object is moved, compared or combined with data from another object. These conversions may happen automatically, what we call Implicit conversion in SQL Server or manually that is known as Explicit conversion which basically means writing code specifically to do something. A useful rule of thumb is that explicit conversion is always better than implicit conversion because it makes code more readable. Now that we’re talking about conversions, also worth mentioning is the stuff that can help us out with the explicit conversion like CAST and CONVERT functions used to convert an expression of one SQL data type to another.
作为数据库开发人员,编写代码时最常见的例程之一就是转换。 当来自一个对象的数据与另一个对象的数据进行移动,比较或组合时,就会进行转换。 这些转换可能是自动发生的, 在SQL Server中我们称为隐式转换,也可能是手动进行的,即所谓的“显式转换”,这基本上是指专门编写代码来执行某些操作。 一个有用的经验法则是,显式转换总是比隐式转换更好,因为它使代码更具可读性。 现在我们正在讨论转换,还值得一提的是可以帮助我们进行显式转换的东西,例如用于将一种SQL数据类型的表达式转换为另一种SQL数据类型的CAST和CONVERT函数。
图形用户界面 (GUID)
GUID is an acronym for Globally Unique Identifier. It is a way to guarantee uniqueness and it’s one of the biggest SQL data types. The only downside of GUID is the 16 bytes in size. Therefore, avoid indexes on GUIDs as much as possible.
GUID是“全局唯一标识符”的缩写。 这是保证唯一性的一种方法,它是最大SQL数据类型之一。 GUID的唯一缺点是16个字节。 因此,请尽可能避免在GUID上建立索引。
空与非空 (NULL vs. NOT NULL)
If you stick with SQL Server defaults, that could lead to some data integrity issues. You should always try to specify the nullability property whenever you’re defining columns in tables. Back to the basics, null means unknown or missing which basically means it’s not 0 or an empty string, and we cannot do the null comparison. We cannot say null = null. This is a no can do. There’s a property called ANSI_NULLS that we can set and control this comparison with null values.
如果坚持使用SQL Server默认值,则可能导致某些数据完整性问题。 在表中定义列时,应始终尝试指定可为空性。 回到基础,null表示未知或丢失,这基本上意味着它不是0或空字符串,并且我们不能进行null比较。 我们不能说null = null。 这是不能做的。 有一个名为ANSI_NULLS的属性,我们可以使用空值设置和控制此比较。
稀疏列 (Sparse columns)
This type of column is just a regular column in SQL Server except for a property that is set to on and it tells SQL Server to optimize that column for null storage.
除了设置为on的属性外,这种类型的列只是SQL Server中的常规列,它告诉SQL Server为空存储优化该列。
SQL数据类型准则 (SQL data type guidelines)
First of all, always use the right data type for the job. This is a lot bigger than most people think. It can have a significant impact on efficiency, performance, storage and further database development.
首先,始终为作业使用正确的数据类型。 这比大多数人想的要大得多。 它会对效率,性能,存储和进一步的数据库开发产生重大影响。
If we take the first two, the query optimizer is going to generate an execution plan depending on what data types are used. A very simple example could be if we’re using the bigint data type where we could be using the smallint – well then, we are most likely just slowing down the query. Choosing the right SQL data type will ultimately result in query optimizer working more efficiently.
如果我们采用前两个,则查询优化器将根据所使用的数据类型生成执行计划。 一个非常简单的例子是,如果我们使用bigint数据类型,而我们可能使用smallint,那么,很可能只是减慢了查询速度。 选择正确SQL数据类型最终将导致查询优化器更有效地工作。
It a good idea to provide documentation for yourself and others using the database on data types going into the objects. It goes without saying, but avoid deprecated data types, always check Microsoft’s latest documentation for the news and updates. If there’s a slight chance that you’re going to work with non-English data, always use Unicode data types. Furthermore, use the sysname data types for the administrative scripts over the nvarchar.
最好为自己和其他人使用进入对象的数据类型的数据库提供文档。 不用说,但是要避免使用不赞成使用的数据类型,请始终检查Microsoft最新文档中的新闻和更新。 如果您不太可能使用非英语数据,请始终使用Unicode数据类型。 此外,在nvarchar上将sysname数据类型用于管理脚本。
SQL数据类型示例 (SQL data type examples)
Let’s jump over to SSMS and see how we can work with some of the data types mentioned in the previous sections. We’ll go through conversions, sparse columns, and alias data types.
让我们跳到SSMS,看看我们如何使用上一节中提到的某些数据类型。 我们将介绍转换,稀疏列和别名数据类型。
转换次数 (Conversion)
Cast, Convert and Parse functions convert an expression of one SQL data type to another. Below is an example query that can be used on a sample “AdventureWorks” database against the “TransactionHistory” table. It’s grabbing “ProductID” and “TransactionDate” from which we can use that date of the transaction to see how conversion works:
Cast,Convert和Parse函数将一种SQL数据类型的表达式转换为另一种。 下面是一个示例查询,可对“ TransactionHistory”表在示例“ AdventureWorks”数据库上使用。 它抓住了“ ProductID”和“ TransactionDate”,我们可以从中使用交易的日期来查看转换的工作方式:
SELECT th.ProductID,
th.TransactionDate,
CAST(th.TransactionDate AS NVARCHAR(30)) AS CastDate, --CAST: ANSI SQL std
CONVERT(VARCHAR(10), th.TransactionDate, 110) AS ConvertDate, --CONVERT T-SQL specific
PARSE('20 October 2019' AS DATETIME USING 'en-US') AS ParseDate -- Convert string to int/datetime
FROM Production.TransactionHistory th;
Here is the result set of various SQL data types:
这是各种SQL数据类型的结果集:
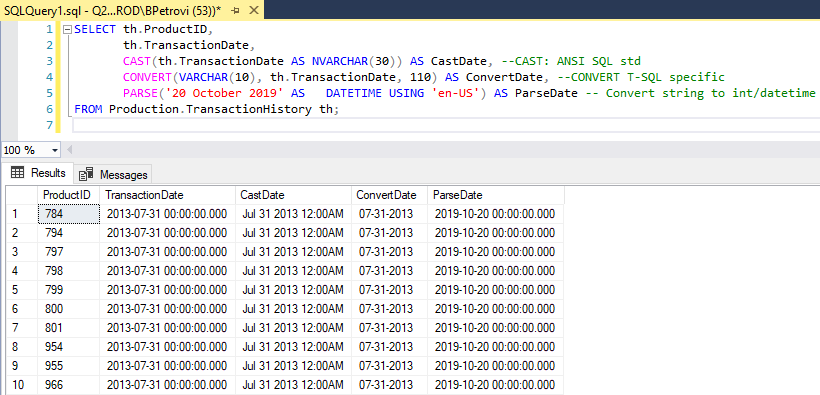
We used the Cast function against TransactionDate to convert values to a nvarchar to a length of 30. Next, we used Convert to do the same thing but then we also specified the format 110 which gives us a specific date style. Last, we used Parse which essentially works the same, but we can apply culture to it.
我们使用针对TransactionDate的Cast函数将值转换为长度为30的nvarchar。接下来,我们使用Convert进行相同的操作,但是随后我们还指定了110格式,该格式提供了一种特定的日期样式。 最后,我们使用了本质上相同的Parse,但是我们可以对其应用文化。
Let’s take a closer look at the result set and see what we got:
让我们仔细看看结果集,看看我们得到了什么:
- Here we have the date and time of the transaction as it sits within the database (datetime data type) 在这里,我们具有事务在数据库中的日期和时间(datetime数据类型)
- Here is what it looks like when we cast it as a text representation 这是当我们将其转换为文本表示形式时的样子
- Converting does the same thing but in this case, we’re specifying how the Convert function will translate expression (110 = mm-dd-yyyy) 转换做同样的事情,但是在这种情况下,我们指定转换函数如何转换表达式(110 = mm-dd-yyyy)
- Parsing in this case, just translates requested data using specific culture (en-US) 在这种情况下,仅使用特定区域性(美国)翻译请求的数据
Next, let’s see some extra stuff that we can do with the Parse function. Parse is great with converting strings to dates and integers. For example, if we execute the Select statement below, it will grab the string 100.000 and turn it into an integer:
接下来,让我们看看我们可以使用Parse函数执行的一些其他操作。 解析非常适合将字符串转换为日期和整数。 例如,如果我们执行下面的Select语句,它将获取字符串100.000并将其转换为整数:
SELECT PARSE('100.000' AS INT) AS StringToInt;
Here is the result set:
这是结果集:
Now, let’s say that we want to do the same thing again but for some reason, the integer has a character in it that SQL Server cannot convert to an integer:
现在,让我们说我们想再次做同样的事情,但是由于某种原因,整数中包含一个字符,SQL Server无法将其转换为整数:
SELECT PARSE('10O.000' AS INT) AS StringToIntError;
Here is the error message that it throws:
这是它引发的错误消息:
Msg 9819, Level 16, State 1, Line 2
Error converting string value ’10O.000′ into data type int using culture ”.
消息9819,第16层,状态1,第2行
使用文化“将字符串值'10O.000'转换为数据类型int时出错。
So, what we can do in this case is to use Try_Parse instead of regular Parse because if we try the same thing from above, it will return a null value rather than the error:
因此,在这种情况下,我们可以使用Try_Parse而不是常规Parse,因为如果我们从上面尝试相同的操作,它将返回空值而不是错误:
SELECT TRY_PARSE('10O.000' AS INT) AS StringToIntNull;
Here is what it looks like:
看起来是这样的:
This method can be used as an identifier if something would error out ahead of time AKA defensive coding. Tries can be applied for the other two SQL data types as well.
如果在AKA防御性编码之前会出错,则可以将该方法用作标识符。 尝试也可以应用于其他两种SQL数据类型。
稀疏列 (Sparse columns)
As I mentioned at the beginning, sparse columns reduce null space requirements. So, let’s jump to Object Explorer in our sample database, locate and query BillOfMaterials table to see how this works:
正如我在开头提到的那样,稀疏列减少了空空间需求。 因此,让我们跳到示例数据库中的“对象资源管理器”,找到并查询BillOfMaterials表以了解其工作原理:
SELECT *
FROM Production.BillOfMaterials bom;
Notice that there are a lot of null values within the ProductAssemblyID and EndDate columns:
请注意,ProductAssemblyID和EndDate列中有很多空值:
Therefore, we can say that these two are good candidates for sparse columns. So, one way to change this is to simply change the property in the designer or we can do it using the T-SQL code from below:
因此,可以说这两个都是稀疏列的良好候选者。 因此,一种更改方法是简单地更改设计器中的属性,或者我们可以使用下面的T-SQL代码进行更改:
ALTER TABLE Production.BillOfMaterials ALTER COLUMN ProductAssemblyID ADD SPARSE;
GO
ALTER TABLE Production.BillOfMaterials ALTER COLUMN EndDate ADD SPARSE;
GO
Commands did not complete successfully the first time, so I had to lose the clustered index (line 7) and then everything went smooth:
命令第一次没有成功完成,因此我不得不丢失聚簇索引(第7行),然后一切顺利:
If we go back to Object Explorer, refresh the BillOfMaterials table, we can see that those two are now marked as sparse columns:
如果回到对象资源管理器,刷新BillOfMaterials表,可以看到这两个现在被标记为稀疏列:
Nice, right. One more neat thing about sparse columns is called column sets. This is useful in a situation when we have a table that contains a bunch of special-purpose columns that are rarely used like in our example ProductAssemblyID and EndDate columns or AddressLine2, MiddleName, etc. So, the idea with the column set is that SQL Server will take all those columns and give us a generated XML column that is updateable. This can lead to a performance boost of the application because SQL Server can work with the column set rather than with each sparse column individually.
很好,对。 关于稀疏列的另一项巧妙的事情称为列集。 这在以下情况下很有用:当我们的表包含一堆很少使用的特殊用途的列时,例如在我们的示例ProductAssemblyID和EndDate列或AddressLine2,MiddleName等中。因此,使用列集的想法是SQL服务器将使用所有这些列,并为我们提供一个可更新的生成XML列。 这可以提高应用程序的性能,因为SQL Server可以使用列集,而不是单独使用每个稀疏列。
So, let’s add a column set using those two examples from above using the following command:
因此,让我们使用以下命令从上面的两个示例添加一个列集:
ALTER TABLE Production.BillOfMaterials
ADD SparseColumns XML COLUMN_SET FOR ALL_SPARSE_COLUMNS;
GO
So, if we try to add a column set but our table already has sparse columns, it will error out:
因此,如果我们尝试添加列集,但我们的表已经具有稀疏列,则会出错:
Msg 1734, Level 16, State 1, Line 9
Cannot create the sparse column set ‘SparseColumns’ in the table ‘BillOfMaterials’ because the table already contains one or more sparse columns. A sparse column set cannot be added to a table if the table contains a sparse column.
讯息1734,第16级,州1,第9行
无法在表“ BillOfMaterials”中创建稀疏列集“ SparseColumns”,因为该表已包含一个或多个稀疏列。 如果表中包含稀疏列,则不能将稀疏列集添加到表中。
If you ever come across this, the easiest workaround is to undo sparse columns. This can be easily done in the designer. Just open it up from Object Explorer, select the column that you need, and within the column properties change the Is Parse property to No as shown below:
如果遇到这种情况,最简单的解决方法是撤消稀疏列。 这可以在设计器中轻松完成。 只需从Object Explorer中打开它,选择所需的列,然后在列属性中将Is Parse属性更改为No ,如下所示:
Now, if we execute the command one more time, it will be successful:
现在,如果我们再次执行该命令,它将成功:
The bottom line here, don’t add sparse columns first – add column sets first and then sparse columns. That way you won’t have to do it the hard way. What’s really neat about this, our DML statements such as Select, Insert and Update can still work the old way by referencing the columns individually or we can do it using the column sets.
最重要的是,不要先添加稀疏列-首先添加列集,然后再添加稀疏列。 这样,您就不必艰难地做到这一点。 真正有趣的是,我们的DML语句(例如Select,Insert和Update)仍然可以通过单独引用列或使用列集进行操作而以旧方式工作。
用户定义SQL数据类型 (User-defined SQL data types)
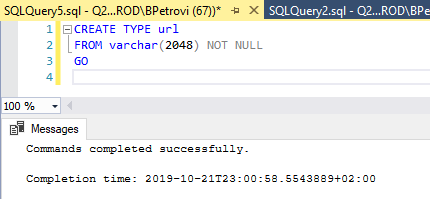
Let’s wrap things up with creating a custom data type. We’re going to create an alias data type which is based on another data type. Let’s just say that we have a need for storing URLs in our table and we want to create an actual URL data type. All we need to do is execute the code from below:
让我们来总结一下创建自定义数据类型的过程。 我们将创建一个基于另一种数据类型的别名数据类型。 只是说我们需要在表中存储URL,并且我们想创建一个实际的URL数据类型。 我们需要做的就是从下面执行代码:
CREATE TYPE url
FROM varchar(2048) NOT NULL
GO
URLs are just characters, so the varchar data type is perfect for this. I’ve set the max value to 2048 because of this thread that I’ve found online which states that you should keep your URLs under 2048 characters:
URL只是字符,因此varchar数据类型非常适合此功能。 由于已在网上找到该线程,因此我将最大值设置为2048, 该线程指出您应将网址保持在2048个字符以下:
We can see this new SQL data type if we head over Object Explorer, under Programmability, Types, User-Defined Data Types folder:
如果我们转到Object Explorer,则可以在Programmability,Types,User-Defined Data Types文件夹下看到此新SQL数据类型:
From here, we can start using the newly created data type. Just an example:
从这里开始,我们可以开始使用新创建的数据类型。 只是一个例子:
ALTER TABLE Purchasing.Vendor
ADD PurchasingWebServiceURL2 url NULL
GO
结论 (Conclusion)
In this article, we learned how to implement SQL data types. We kicked off with an overview just to get familiar with some of the built-in data types. Then we talked about some stuff to consider when working with data types and conversion using Cast, Convert and Parse functions. We also jumped into SSMS where we showed how to convert an expression of one data type to another. We went through how to work with sparse columns, and then we also saw how to create our own custom data types.
在本文中,我们学习了如何实现SQL数据类型。 我们从概述开始,只是为了熟悉一些内置数据类型。 然后,我们讨论了使用Cast,Convert和Parse函数处理数据类型和进行转换时要考虑的一些事项。 我们还跳入了SSMS,在其中展示了如何将一种数据类型的表达式转换为另一种数据类型。 我们介绍了如何处理稀疏列,然后还介绍了如何创建自己的自定义数据类型。
I hope this article on SQL data types has been informative for you and I thank you for reading it.
希望有关SQL数据类型的这篇文章对您有所帮助,也感谢您阅读它。















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









