





I attended a TDWI conference in May 2016 in Chicago. Here I got a hint about the datatype hierarchyid in SQL Server which could optimize and eliminate the good old parent/child hierarchy.
我参加了2016年5月在芝加哥举行的TDWI会议。 在这里,我得到了有关SQL Server中数据类型的hierarchyid的提示,该数据可以优化和消除旧的父/子层次结构。
Until then I (and several other in the class) hadn’t heard about the hierarchyid datatype in SQL Server.
在那之前,我(以及班上的其他几个人)还没有听说过SQL Server中的architectureid数据类型。
So here’s an article covering some of the aspects of the datatype hierarchyid – including:
因此,本文涵盖了数据类型hierarchyid的某些方面,包括:
- Introduction 介绍
- How to use it 如何使用它
- How to optimize data in the table 如何优化表中的数据
- How to work with data in the hierarchy-structure 如何使用层次结构中的数据
- Goodies 好东西
介绍 (Introduction)
The datatype hierarchyid was introduced in SQL Server 2008. It is a variable length system datatype. The datatype can be used to represent a given element’s position in a hierarchy – e.g. an employee’s position within an organization.
数据类型architectureid是在SQL Server 2008中引入的。它是可变长度的系统数据类型。 数据类型可用于表示给定元素在层次结构中的位置-例如,员工在组织中的位置。
The datatype is extremely compact. The storage is dependent in the average fanout (fanout = the number of children in all nodes). For smaller fanouts (0-7) the typical storage is about 6 x Log A * n bits. Where A is the average fanout and n in the total number of nodes in the tree. Given above formula an organization with 100,000 employees and a fanout of 6 levels will take around 38 bits – rounded to 5 bytes of total storage for the hierarchy structure.
数据类型非常紧凑。 存储取决于平均扇出(扇出=所有节点中的子代数)。 对于较小的扇出(0-7),典型存储约为6 x Log A * n位。 其中,A是平均扇出,树中的节点总数为n。 根据上述公式,一个拥有100,000名员工和6级扇出的组织将需要大约38位-对于层次结构,四舍五入为总存储量的5个字节。
Though the limitation of the datatype is 892 bytes there is a lot of room for extremely complex and deep structures.
尽管数据类型的限制是892个字节,但对于极其复杂和深层的结构仍有很大的空间。
When representing the values to and from the hierarchyid datatype the syntax is:
[level id 1]/[level id 2]/..[level id n]
在表示与hierarchyid数据类型之间的值时,语法为:
[级别ID 1] / [级别ID 2] / .. [级别ID n]
Example:
1/7/3
例:
1/7/3
The data between the ‘/ can be of decimal types e.g. 0.1, 2.3 etc.
'/之间的数据可以是十进制类型,例如0.1、2.3等。
Given two specific levels in the hierarchy a and b given that a < b means that b comes after a in a depth first order of comparison traversing the tree structure. Any search and comparison on the tree is done this way by the SQL engine.
给定层次结构a和b中的两个特定级别,假设a <b意味着b以深度比较的第一顺序在a之后遍历树结构。 SQL引擎以这种方式在树上进行任何搜索和比较。
The datatype directly supports deletions and inserts through the GetDescendant method (see later for full list of methods using this feature). This method enables generation of siblings to the right of any given node and to the left of any given node. Even between two siblings. NOTE: when inserting a new node between two siblings will produce values that are slightly less compact.
数据类型直接支持通过GetDescendant方法进行删除和插入(有关使用此功能的方法的完整列表,请参见后面的内容)。 此方法可以在任何给定节点的右侧和任何给定节点的左侧生成同级。 即使在两个兄弟姐妹之间。 注意:在两个同级之间插入新节点时,所产生的值的紧凑性会稍差一些。
如何使用它 (How to use it)
Given an example of data – see compete SQL script at the end of this post to generate the example used in this post.
给定一个数据示例–请参阅本文末尾的竞争SQL脚本以生成本文中使用的示例。
The Num field is a simple ascending counter for each level member in the hierarchy.
Num字段是层次结构中每个级别成员的简单递增计数器。
There are some basic methods to be used in order to build the hierarchy using the hierarchy datatype.
为了使用层次结构数据类型构建层次结构,可以使用一些基本方法。
GetRoot方法 (GetRoot method)
The GetRoot method gives the hierarchyid of the rootnode in the hierarchy. Represented by the EmployeeId 1 in above example.
GetRoot方法提供层次结构中根节点的层次结构ID。 在上面的示例中,以EmployeeId 1表示。
The code and result could look like this:
代码和结果可能如下所示:
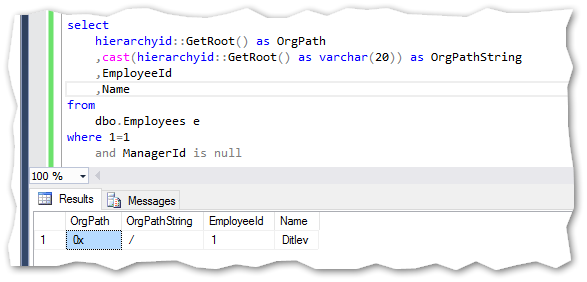
The value ‘0x’ from the OrgPath field is the representation of the string ‘/’ giving the root of the hierarchy. This can be seen using a simple cast to varchar statement:
OrgPath字段中的值“ 0x”是字符串“ /”的表示形式,给出了层次结构的根。 使用简单的强制转换为varchar语句可以看出这一点:
Building the new structure with the hierarchyid dataype using a recursive SQL statement:
使用递归SQL语句使用hierarchicalid数据类型构建新结构:
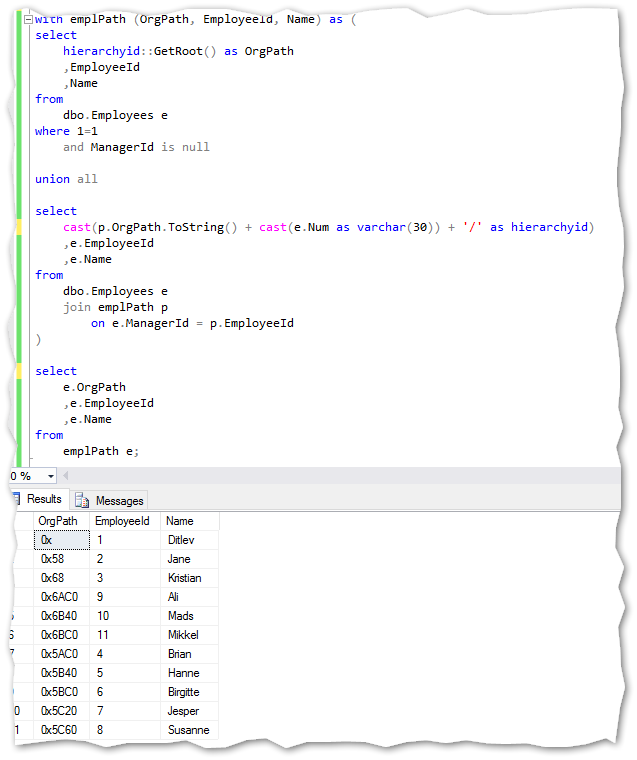
Notice the building of the path after the union all. This complies to the above mentioned syntax for building the hierarchy structure to convert to a hierarchyid datatype.
注意所有并集之后的路径构建。 这符合上述语法的要求,用于构建层次结构以转换为hierarchyid数据类型。
If I was to build the path for the EmployeeId 10 (Name = ‘Mads’) in above example it would look like this: ‘/2/2/’. A select statement converting the hierarchyid field OrgPath for the same record, reveals the same thing:
如果在上面的示例中为EmployeeId 10(名称='Mads')构建路径,它将看起来像这样:'/ 2/2 /'。 一条为同一条记录转换hierarchyid字段OrgPath的select语句揭示了同一件事:
Notice the use of the ToString method here. Another build in method to use for the hierarchyid in SQL Server.
注意此处使用ToString方法。 用于SQL Server中的architectureid的另一种内置方法。
GetLevel方法 (GetLevel method)
The GetLevel method returns the current nodes level with an index of 0 from the top:
GetLevel方法从顶部返回索引为0的当前节点级别:
GetDescendant方法 (GetDescendant method)
This method returns a new hierarchyid based on the two parameters child1 and child2.
此方法基于两个参数child1和child2返回一个新的architectureid。
The use of these parameters is described in the BOL HERE.
在BOL HERE中描述了这些参数的使用。
Below is showed some short examples on the usage.
下面显示了一些简短的用法示例。
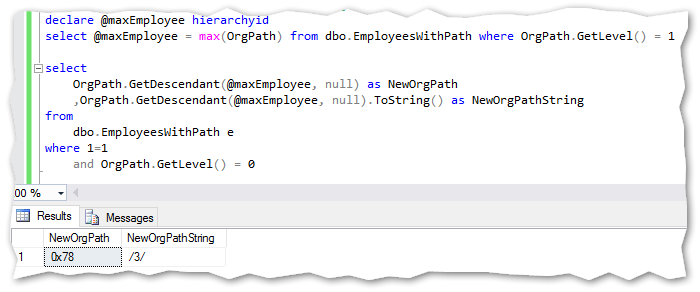
Getting a new hierarchyid when a new employee referring to top manager is hired:
雇用新员工担任高层管理人员时获取新的architectureid:
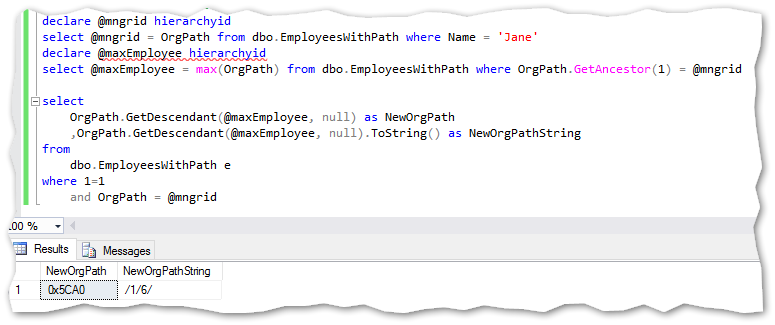
Getting a new hierarchyid when a new hire is referring to Jane on the hierarchy:
当新员工在层次结构上引用Jane时,获取新的architectureid:
Dynamic insert new records in the hierarchy table – this can easily be converted into a stored procedure:
在层次结构表中动态插入新记录–可以轻松地将其转换为存储过程:
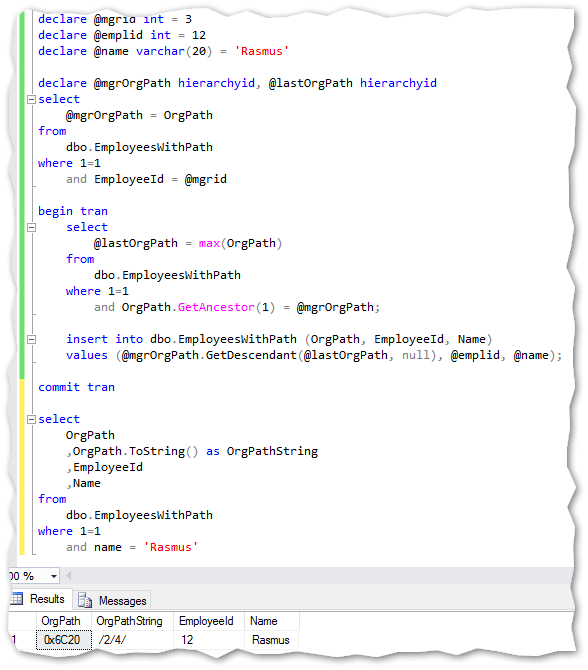
Notice the new GetAncestor method which takes one variable (the number of steps up the hierarchy) and returns that levels Hierarchyid. In this case just 1 step up the hierarchy.
注意新的GetAncestor方法,该方法采用一个变量(层次结构上的步骤数)并返回该层次结构Hierarchyid。 在这种情况下,仅需向上一级即可。
More methods
更多方法
There are several more methods to use when working on a hierarchy table – as found on BOL:
在层次结构表上工作时,还有其他几种方法可以使用-如BOL所示:
GetDescendant – returns a new child node of a given parent. Takes to parameters.
GetDescendant –返回给定父级的新子节点。 带参数。
GetLevel – returns the given level for a node (0 index)
GetLevel –返回节点的给定级别(0索引)
GetRoot – returns a root member
GetRoot –返回根成员
ToString – converts a hierarchyid datatype to readable string
ToString –将architectureid数据类型转换为可读的字符串
IsDescendantOf – returns boolean telling if a given node is a descendant of given parent
IsDescendantOf –返回布尔值,指示给定节点是否为给定父级的后代
Parse – converts a string to a hierarchyid
解析 –将字符串转换为architectureid
Read – is used implicit in the ToString method. Cannot be called by the T-SQL statement
读取 –在ToString方法中隐式使用。 T-SQL语句无法调用
GetParentedValue – returns node from new root in case of moving a given node
GetParentedValue –如果移动给定节点,则从新根目录返回节点
Write – returns a binary representation of the hierarchyid. Cannot be called by the T-SQL statement.
写入 –返回分层结构ID的二进制表示形式。 不能由T-SQL语句调用。
优化 (Optimization)
As in many other scenarios of the SQL Server the usual approach to indexing and optimization can be used.
与在SQL Server的许多其他方案中一样,可以使用索引和优化的常用方法。
To help on the usual and most used queries I would make below two indexes on the example table:
为了帮助进行通常和最常用的查询,我将在示例表上建立以下两个索引:
But with this like with any other indexing strategy – base it on the given scenario and usage.
但是,与任何其他索引策略一样,它基于给定的方案和用法。
好东西 (Goodies)
So why use this feature and all the coding work that comes with it?
那么,为什么要使用此功能及其附带的所有编码工作呢?
Well – from my perspective – it has just become very easy to quickly get all elements either up or down from a given node in the hierarchy.
从我的角度来看,从层次结构中的给定节点快速上移或下移所有元素变得非常容易。
从特定节点获取所有后代 (Get all descendants from a specific node)
If I would like to get all elements below Jane in the hierarchy I just have to run this command:
如果要在层次结构中的Jane下面获取所有元素,则只需运行以下命令:
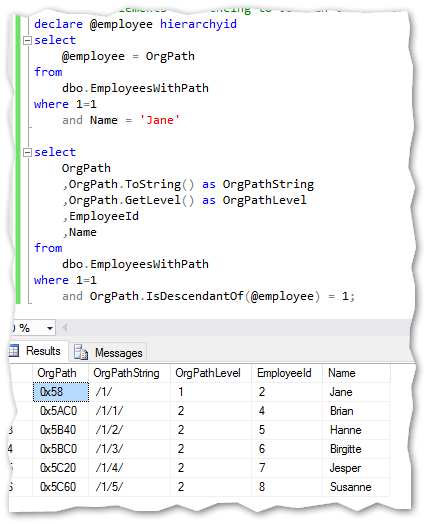
Think of the work you would have to do if this was a non hierarchy structured table using only parent/child and recursive SQL if the structure was very complex and deep.
如果这是一个仅使用父/子和递归SQL的非层次结构表,并且结构非常复杂且很深,则考虑一下您将要做的工作。
I know what I would choose.
我知道我会选择什么。
结论 (Conclusion)
As seen above the datatype hierarchyid can be used to give order to the structure of a hierarchy in a way that is both efficient and fairly easy maintained.
如上所示,数据类型hierarchyid可用于以高效且易于维护的方式对层次结构进行排序。
If one should optimize the structure even further, then the EmployeeId and the ManagerId could be dropped as the EmployeeId is now as distinct as the OrgPath and can be replaced by this. The ManagerId is only used to build the structure – but this is now also given by the OrgPath.
如果要进一步优化结构,则可以删除EmployeeId和ManagerId,因为EmployeeId现在与OrgPath相同,可以用它替换。 ManagerId仅用于构建结构-但现在OrgPath也提供了此名称。
Happy coding…
祝您编程愉快!
You can download the SQL code here
您可以在此处下载SQL代码















 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









