





SQL Server temp tables are a special type of tables that are written to the TempDB database and act like regular tables, providing a suitable workplace for intermediate data processing before saving the result to a regular table, as it can live only for the age of the database connection.
SQL Server临时表是一种特殊类型的表,它们被写入TempDB数据库,并且像常规表一样工作,为将结果保存到常规表之前提供了合适的工作场所,以进行中间数据处理,因为它只能存在一定的使用期限。数据库连接。
SQL temp tables can be used to enhance stored procedures performance by shortening the transaction time, allowing you to prepare records that you will modify in the SQL Server temp table, then open a transaction and perform the changes.
SQL临时表可通过缩短事务时间来增强存储过程的性能,允许您准备要在SQL Server临时表中修改的记录,然后打开一个事务并执行更改。
There are four main types for the SQL temp tables:
SQL临时表有四种主要类型:
a Local SQL Server temp table, which is named starting with a # symbol (e.g. #TempShipments), that can be referenced only by the current database session and discarded by its disconnection,
一个本地SQL Server临时表 ,该表以一个#符号(例如,#TempShipments)开头,只能由当前数据库会话引用,并可以通过断开连接而丢弃,
a Global SQL temp table, which is named starting with ## (e.g. ##TempShipments), that can be referenced by any process in the current database and discarded when the original database session that created that temp table disconnected or until the last statement that was referencing the temp table has stopped using it, as anyone who has access to the system TempDB database when that global SQL temp table is created will be able to use that table,
一个全局SQL临时表 ,该表以##开头(例如## TempShipments),可以由当前数据库中的任何进程引用,并在创建该临时表的原始数据库会话断开连接时或直到最后一个语句断开时被丢弃引用临时表已停止使用它,因为在创建全局SQL临时表时有权访问系统TempDB数据库的任何人都可以使用该表,
a Persistent SQL Server temp table which is named starting with a TempDB prefix such as TempDB.DBO.TempShipments
一个持久性SQL Server临时表 ,该表以TempDB前缀(例如TempDB.DBO.TempShipments)开头
and a Table Variable that starts with an @ prefix (e.g. @TempShipments)
和一个以@前缀开头的表变量 (例如@TempShipments)
The SQL Server Database Engine can distinguish between the same SQL temporary tables created while executing the same stored procedure many times simultaneously by appending a system-generated numeric suffix to the SQL Server temp table name. This is why the local SQL temp table name can’t exceed 116 characters.
通过将系统生成的数字后缀附加到SQL Server临时表名称,SQL Server数据库引擎可以区分在同时执行相同存储过程多次时创建的相同SQL临时表。 这就是为什么本地SQL临时表名称不能超过116个字符的原因。
Although both SQL Server temp tables and table variables are stored in the TempDB database, there are many differences between them such as:
尽管SQL Server临时表和表变量都存储在TempDB数据库中,但是它们之间有很多区别,例如:
SQL temp tables are created using CREATE TABLE T-SQL statement, but table variables are created using DECLARE @name Table T-SQL statement.
使用CREATE TABLE T-SQL语句创建SQL临时表,但是使用DECLARE @name表T-SQL语句创建表变量。
You can ALTER the SQL Server temp tables after creating it, but table variables don’t support any DDL statement like ALTER statement.
您可以在创建SQL Server临时表后对其进行更改,但是表变量不支持任何ALTER语句之类的DDL语句。
SQL temp tables can’t be used in User Defined Functions, but table variables can be.
SQL临时表不能在用户定义函数中使用,但可以使用表变量。
SQL Server temporary tables honor explicit transactions defined by the user, but table variables can’t participate in such transactions.
SQL Server临时表支持用户定义的显式事务,但是表变量不能参与此类事务。
SQL temp tables support adding clustered and non-clustered indexes after the SQL Server temp table creation and implicitly by defining Primary key constraint or Unique Key constraint during the tables creation, but table variables support only adding such indexes implicitly by defining Primary key constraint or Unique key constraint during tables creation.
SQL临时表支持在SQL Server临时表创建之后以及通过在表创建期间定义主键约束或唯一键约束来隐式添加聚簇和非聚集索引,但是表变量仅通过定义主键约束或唯一性来隐式添加此类索引。表创建期间的关键约束。
SQL temp tables can be dropped explicitly, but table variables can’t be dropped explicitly, taking into consideration that both types are dropped automatically when the session in which they are created is disconnected.
可以显式删除SQL临时表,但不能显式地删除表变量,要考虑到在创建它们的会话断开连接时会自动删除这两种类型。
SQL Server temp tables can be local temporal tables at the level of the batch or stored procedure in which the table declared or global temporal tables where it can be called outside the batch or stored procedure scope, but table variables can be called only within the batch or stored procedure in which it is declared.
SQL Server临时表可以是批处理或存储过程级别的局部时态表,其中声明的表或全局临时表可以在批处理或存储过程范围之外调用,但表变量只能在批处理中调用或在其中声明它的存储过程。
In addition to that, SQL Server column level statistics are generated automatically against SQL temp tables, helping the SQL Server Query Optimizer to generate the best execution plan, gaining the best performance when querying that SQL Server temp table. But you should take into consideration that modifying SQL temp tables many times in your code may lead to statistics getting out of date. This would require manually updating for these statistics, or enabling Trace Flag 2371. In this article, we will see how we can benefit from the ability to add clustered and non-clustered indexes in the SQL Server temp tables.
除此之外,还会针对SQL临时表自动生成SQL Server列级统计信息,从而帮助SQL Server查询优化器生成最佳执行计划,并在查询该SQL Server临时表时获得最佳性能。 但是您应该考虑到,在代码中多次修改SQL临时表可能会导致统计信息过时。 这将需要手动更新这些统计信息,或启用跟踪标志2371 。 在本文中,我们将看到如何从SQL Server临时表中添加群集索引和非群集索引的功能中受益。
Defining PRIMARY KEY and UNIQUE KEY constraints during SQL temp table creation will enable SQL Server Query Optimizer to always be able to use these indexes. Even so, these indexes prevent inserting non-unique values to these columns, which is not the best case in all scenarios, that may require non-unique values. In this case, it is better to explicitly define a clustered or non-clustered index that could be configured as a non-unique index. Adding indexes to the SQL temp tables will enhance its performance if the index is chosen correctly, otherwise, it can cause performance degradation. Also, not every SQL Server temp table needs adding indexes, as it depends on many things such as the way that this SQL temp table will be called, joined with other huge tables or if it will be part of a complex stored procedure.
在创建SQL临时表的过程中定义PRIMARY KEY和UNIQUE KEY约束将使SQL Server Query Optimizer始终能够使用这些索引。 即使这样,这些索引仍可以防止将非唯一值插入这些列,这并不是在所有情况下的最佳情况,因为这可能需要非唯一值。 在这种情况下,最好显式定义可以配置为非唯一索引的聚集索引或非聚集索引。 如果正确选择索引,则将索引添加到SQL临时表将提高其性能,否则会导致性能下降。 同样,并不是每个SQL Server临时表都需要添加索引,因为它取决于许多事情,例如该SQL临时表的调用方式,与其他巨大表的联接方式,或者它是否将成为复杂存储过程的一部分。
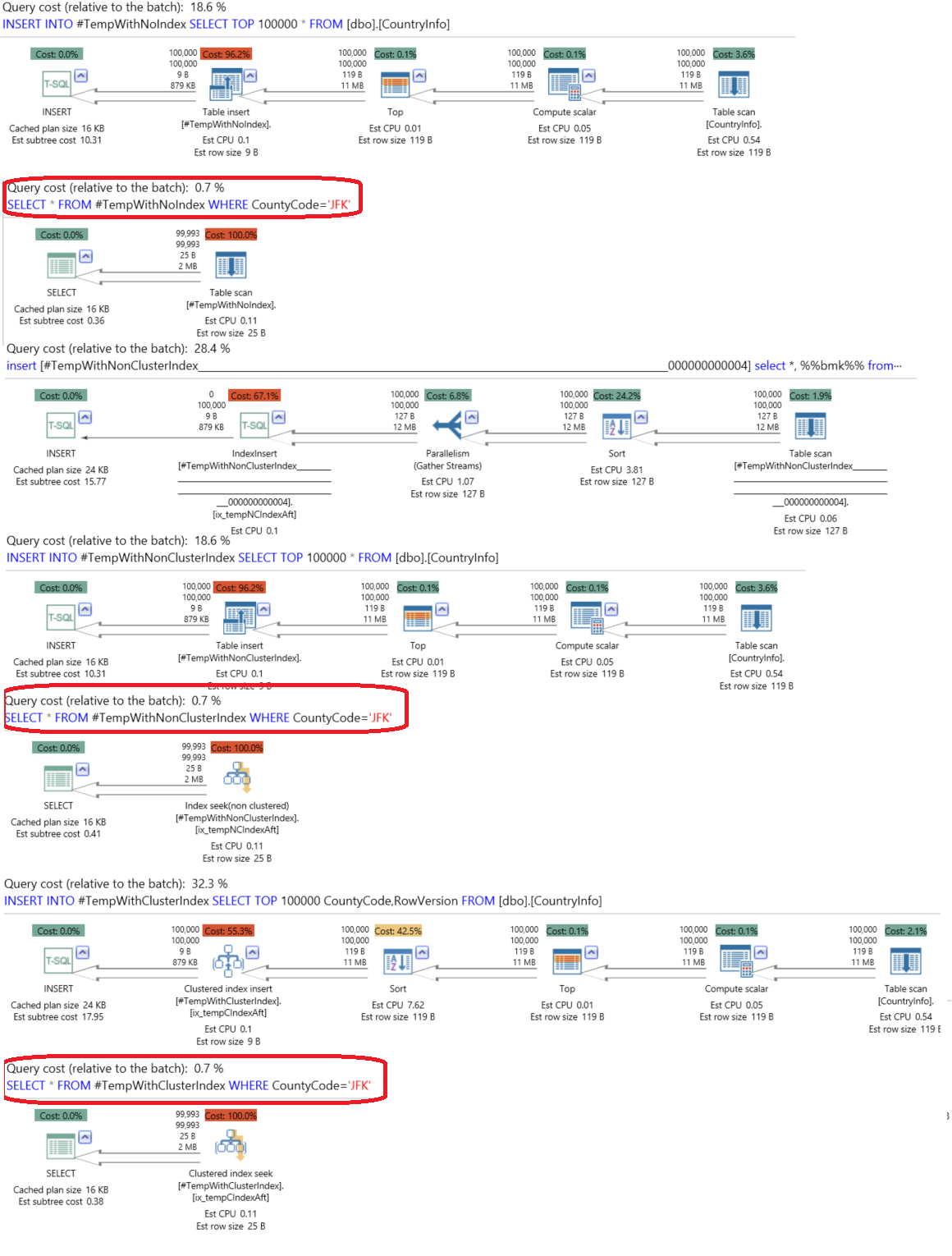
Let’s start our demo, in which we will test the performance of filling and retrieving data from SQL Server temp tables that contain 100k records, without any index, with a non-clustered index, and with a clustered index. We will concentrate in checking the time consumed by each case and the generated execution plan. To evaluate the consumed time, we will declare @StartTime variable before each execution, set its value to GETDATE () and at the end of each execution, we will print the date difference (in ms) between the current time and the start time.
让我们开始演示,其中我们将测试从包含10万条记录SQL Server临时表填充和检索数据的性能,该临时表没有任何索引,具有非聚集索引,并且具有聚集索引。 我们将专注于检查每种情况所花费的时间以及生成的执行计划。 要评估消耗的时间,我们将在每次执行之前声明@StartTime变量,将其值设置为GETDATE(),然后在每次执行结束时,我们将打印当前时间与开始时间之间的日期差(以毫秒为单位)。
The below script will create the previously mentioned three SQL temp tables; temp table without an index, temp table with a non-clustered index and temp table with clustered index and fill it with 100k records from the CountryInfo test table then retrieve these records from the tables:
下面的脚本将创建前面提到的三个SQL临时表。 没有索引的临时表,具有非聚集索引的临时表和具有聚集索引的临时表,并用CountryInfo测试表中的100k条记录填充它,然后从表中检索以下记录:
USE SQLShackDemo
GO
set nocount on
go
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithNoIndex
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
INSERT INTO #TempWithNoIndex
SELECT TOP 100000 * FROM [dbo].[CountryInfo]
SELECT * FROM #TempWithNoIndex WHERE CountyCode='JFK'
PRINT '#TempWithNoIndex'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithNoIndex
GO
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithNonClusterIndex
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
INSERT INTO #TempWithNonClusterIndex
SELECT TOP 100000 * FROM [dbo].[CountryInfo]
CREATE NONCLUSTERED INDEX ix_tempNCIndexAft ON #TempWithNonClusterIndex ([CountyCode],[RowVersion]);
SELECT * FROM #TempWithNonClusterIndex WHERE CountyCode='JFK'
PRINT '#TempWithNonClusterIndex'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithNonClusterIndex
GO
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithClusterIndex
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
CREATE CLUSTERED INDEX ix_tempCIndexAft ON #TempWithClusterIndex ([CountyCode],[RowVersion]);
INSERT INTO #TempWithClusterIndex
SELECT TOP 100000 CountyCode,RowVersion FROM [dbo].[CountryInfo]
SELECT * FROM #TempWithClusterIndex WHERE CountyCode='JFK'
PRINT '#TempWithClusterIndex'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithClusterIndex
GO
Executing the previous script, the result will show us that in our case, adding a non-clustered index is worse than having the table without index by 1.2 times in our case, but adding a clustered index will enhance the overall performance by one time in our case as in the below timing comparison in ms:
执行前一个脚本,结果将向我们表明,在我们的示例中,添加非聚集索引比在不使用索引的情况下使没有索引的表差1.2倍,但是在不使用索引的情况下添加聚集索引将使整体性能提高一倍。我们的情况如下所示,以毫秒为单位的时间比较:
Checking the generated execution plan using the ApexSQL Plan application after the execution, we will see that, as we don’t have joins with huge tables or complex queries, the data retrieval from the three tables consume the same resources (1%) and differ in the operator that is used to retrieve the data; Table Scan in the case of the temp table without index, Index Seek in the case of temp table with non-clustered index and Clustered Index Seek in the case of temp table with clustered index.
执行后使用ApexSQL Plan应用程序检查生成的执行计划,我们将看到,由于我们没有大型表或复杂查询的联接,因此从这三个表中检索数据会消耗相同的资源(1%),并且会有所不同在用于检索数据的运算符中; 对于没有索引的临时表,表扫描;对于具有非聚集索引的临时表,索引搜索;对于具有聚集索引的临时表,聚集索引。
Also you can derive from the execution plan, that the table with non-clustered index took the largest time (1063 ms) and resources (47% of the overall execution) during the table insertion process opposite to the table with clustered index insertion that took less time (827 ms) and resources (32 % of the overall execution):
您还可以从执行计划中得出,与插入索引索引的表相反,在表插入过程中,具有非聚集索引的表花费了最大的时间(1063 ms)和资源(占总执行的47%)。更少的时间(827毫秒)和资源(占总执行量的32%):
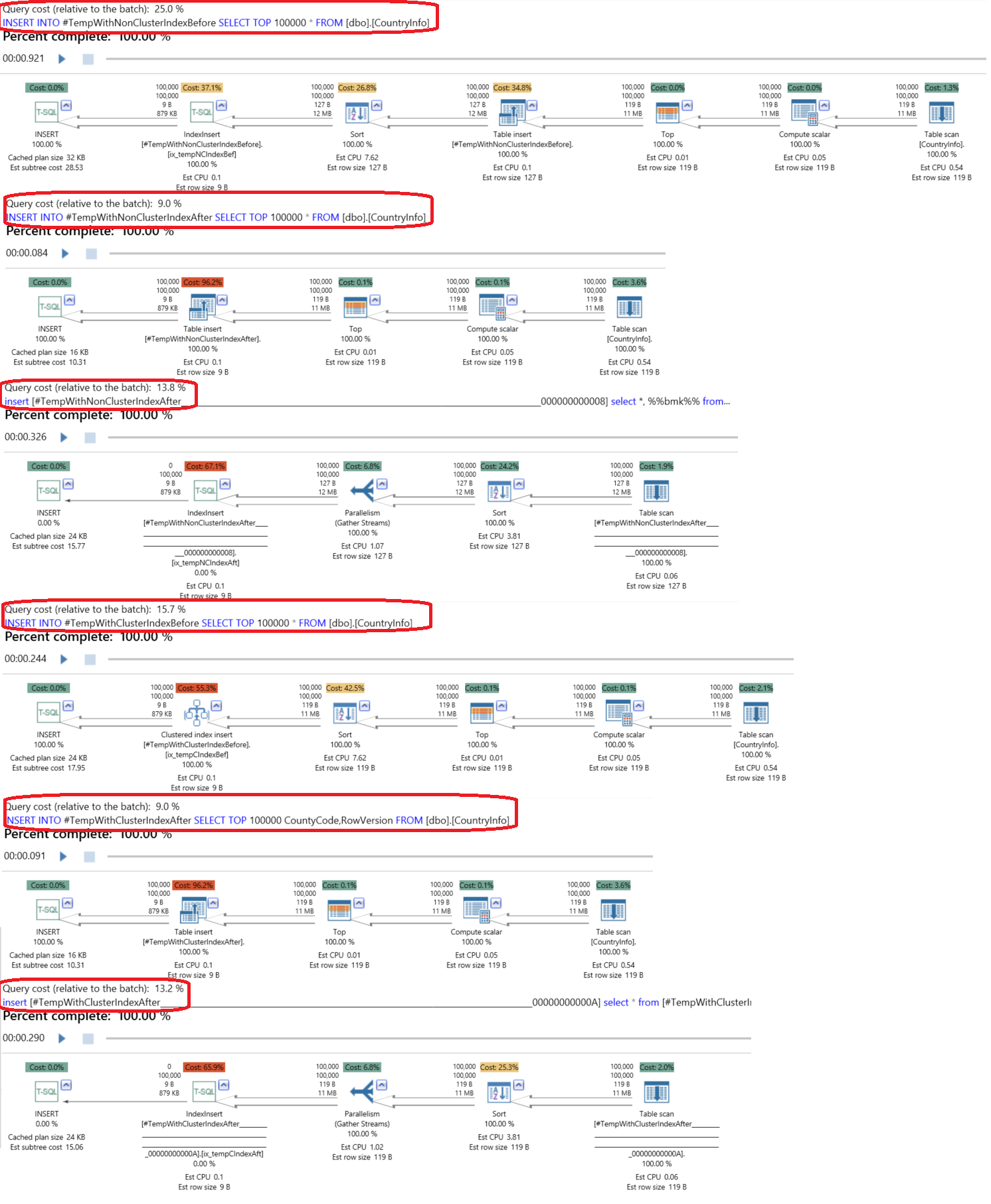
In the previous script we created a non-clustered index after filling the temp table and the clustered index before filling the temp table. But is it different when we create the index before or after filling the temp table? To answer this question let’s perform the following test in which we will check the consumed time in all cases; adding a non-clustered index before filling the temp table, adding a non-clustered index after filling the temp table, adding a clustered index before filling the temp table and adding a clustered index after filling the temp table:
在上一个脚本中,我们在填充临时表之后创建了非聚集索引,而在填充临时表之前创建了聚集索引。 但是,在填充临时表之前或之后创建索引时,会有所不同吗? 为了回答这个问题,让我们执行以下测试,我们将检查所有情况下的消耗时间。 在填充临时表之前添加一个非聚集索引,在填充临时表之后添加一个非聚集索引,在填充临时表之前添加一个聚集索引,以及在填充临时表之后添加一个聚集索引:
USE SQLShackDemo
GO
set nocount on
GO
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithNonClusterIndexBefore
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
CREATE NONCLUSTERED INDEX ix_tempNCIndexBef ON #TempWithNonClusterIndexBefore ([CountyCode],[RowVersion]);
INSERT INTO #TempWithNonClusterIndexBefore
SELECT TOP 100000 * FROM [dbo].[CountryInfo]
PRINT '#TempWithNonClusterIndexBefore'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithNonClusterIndexBefore
GO
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithNonClusterIndexAfter
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
INSERT INTO #TempWithNonClusterIndexAfter
SELECT TOP 100000 * FROM [dbo].[CountryInfo]
CREATE NONCLUSTERED INDEX ix_tempNCIndexAft ON #TempWithNonClusterIndexAfter ([CountyCode],[RowVersion]);
PRINT '#TempWithNonClusterIndexAfter'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithNonClusterIndexAfter
GO
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithClusterIndexBefore
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
CREATE CLUSTERED INDEX ix_tempCIndexBef ON #TempWithClusterIndexBefore ([CountyCode],[RowVersion]);
INSERT INTO #TempWithClusterIndexBefore
SELECT TOP 100000 * FROM [dbo].[CountryInfo]
PRINT '#TempWithClusterIndexBefore'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithClusterIndexBefore
GO
DECLARE @StartTime AS DATETIME = GETDATE()
CREATE TABLE #TempWithClusterIndexAfter
([CountyCode] NVARCHAR(100),[RowVersion] DateTime)
INSERT INTO #TempWithClusterIndexAfter
SELECT TOP 100000 CountyCode,RowVersion FROM [dbo].[CountryInfo]
CREATE CLUSTERED INDEX ix_tempCIndexAft ON #TempWithClusterIndexAfter ([CountyCode],[RowVersion]);
PRINT '#TempWithClusterIndexAfter'
PRINT DATEDIFF(ms,@StartTime,GETDATE())
DROP TABLE #TempWithClusterIndexAfter
GO
It is clear from the result generated from executing the previous script that it is better to create the non-clustered index after filling the table, as that is 1.2% faster, and create the clustered index before filling the table, as that is 2.5% faster, due to the mechanism that is used to fill the tables and create the indexes:
从执行上一个脚本所产生的结果可以明显看出,最好在填充表之后创建非聚集索引,因为速度快了1.2%,而在填充表之前创建了聚集索引,因为速度为2.5%由于用于填充表和创建索引的机制,速度更快:
Checking the execution plan, the result will show us that creating the clustered index before the insertion consumes 15.7% of the overall execution, where creating it after the insertion will consume 22% of the overall execution. On the other hand, creating the non-clustered indexes after the insertion consumes 23% of the resources compared with the 25% percent that is consumed by creating it before the insertion process:
检查执行计划,结果将向我们表明,在插入之前创建聚簇索引会消耗整体执行的15.7%,而在插入之后创建聚簇索引会消耗整体执行的22%。 另一方面,在插入之后创建非聚集索引会消耗23%的资源,而在插入过程之前创建非聚集索引会消耗25%的资源:
结论 (Conclusion)
In SQL Server, SQL temp tables, that are stored in the TempDB database, are widely used to provide a suitable place for the intermediate data processing before saving the result to a base table. It also used to shorten the duration of long running transactions with minimum base table locking by taking the data, processing it and finally opening a transaction to perform the change on the base table. This approach is applicable to add non-clustered and clustered indexes to the SQL Server temp tables, which both can enhance the performance of retrieving data from these tables if the indexes are chosen correctly.
在SQL Server中,存储在TempDB数据库中SQL临时表被广泛用于在将结果保存到基表之前为中间数据处理提供合适的位置。 它还通过获取数据,处理数据并最终打开一个事务以对基表执行更改,从而以最少的基表锁定来缩短长时间运行的事务的持续时间。 此方法适用于将非群集索引和群集索引添加到SQL Server临时表,如果正确选择了索引,两者都可以提高从这些表检索数据的性能。
翻译自: https://www.sqlshack.com/indexing-sql-server-temporary-tables/















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









