





sql server 跟踪
描述 (Description)
Keeping track of our SQL Server Agent jobs is a very effective way to control scheduling, failures, and understand when undesired conditions may be manifesting themselves. This is a brief journey towards a solution that provides us far greater insight into our jobs, schedules, and executions than we can glean from SQL Server by default.
跟踪我们SQL Server Agent作业是一种控制计划,失败以及了解何时可能出现不希望的情况的非常有效的方法。 这是一个简短的解决方案之旅,它为我们提供了比默认情况下从SQL Server收集的更多信息,使我们对作业,计划和执行有了更深入的了解。
介绍 (Introduction)
When we consider SQL Server performance metrics for use by database professionals, a long list comes to mind:
当我们考虑数据库专业人员使用SQL Server性能指标时,会想到一长串:
- Waits 等待
- CPU 中央处理器
- Memory utilization (buffer cache, plan cache, server memory) 内存利用率(缓冲区高速缓存,计划高速缓存,服务器内存)
- Contention (locks, deadlocks, blocking) 争用(锁,死锁,阻止)
- I/O (reads, writes by database/file/object) I / O(读取,写入按数据库/文件/对象)
- Many, many more… 很多很多…
A metric often overlooked is job performance. The alert we most often respond to is a failed job. When a backup, warehouse load, or maintenance task fails, we are alerted and know that some response is needed to ensure we understand why and how it failed.
一个经常被忽视的指标是工作绩效。 我们最常响应的警报是一项失败的工作。 当备份,仓库装载或维护任务失败时,我们会收到警报并知道需要一些响应以确保我们了解失败原因和失败方式。
Job failures are not always avoidable, but our goal is to prevent systemic or catastrophic failures. If we discover that an important ETL process is taking 23 hours to complete per day, then it is obvious we need to revisit the job, the work it performs, and rearchitect it to be more efficient. At that time, though, it is too late. We need to keep our important data flowing, but at the same time ensure that the long-running process doesn’t slow to the point of being ineffective, or fail.
作业失败并非总是可以避免的,但是我们的目标是防止系统性或灾难性的失败。 如果我们发现一个重要的ETL流程每天需要花费23个小时才能完成,那么很明显,我们需要重新审视该工作,执行的工作,并重新构建以提高效率。 但是,当时为时已晚。 我们需要保持重要数据的流动,但同时要确保长时间运行的过程不会减慢到无效或失败的地步。
Our goal is to take job-related metadata and run statistics from MSDB and compile them into a simple but useful store of reporting data that can be trended, monitored, and reported on as needed.
我们的目标是获取与作业相关的元数据,并从MSDB运行统计数据,并将其编译为简单但有用的报告数据存储,可以根据需要对趋势数据进行监视,监视和报告。
工作绩效跟踪有什么好处? (What Are the Benefits of Job Performance Tracking?)
The immediate benefits of tracking this sort of data are obvious in that we can keep an eye out for very long-running jobs and (hopefully) catch a problematic situation before it becomes a 2 am wake-up call!
跟踪此类数据的直接好处是显而易见的,因为我们可以密切注意运行时间很长的作业,并(希望)在有问题的情况下将其唤醒,将其设为凌晨2点!
There are additional insights we can glean from this data that can make it even more useful, such as:
我们可以从这些数据中收集到更多的见解,这些见解可以使它变得更加有用,例如:
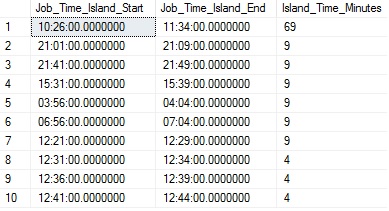
- Trend job runtime and predict how long jobs will take in the future. This allows us to predict when we may need to evaluate the efficiency of current processes before they become problematic. 趋势作业运行时间,并预测将来需要多长时间。 这使我们能够预测何时可能需要评估当前流程的效率,以免出现问题。
- Track individual job steps to focus on larger jobs and which parts might need attention. 跟踪各个工作步骤以专注于较大的工作以及可能需要注意的部分。
- Aggregate job performance across a sharded or multi-server environment to determine overall efficiency. 汇总分片或多服务器环境中的作业性能,以确定整体效率。
- Improve our ability to schedule new jobs, by being able to easily view job scheduling data on a server. 通过能够轻松查看服务器上的作业调度数据,提高了调度新作业的能力。
- Allow us to better plan server downtime by reviewing job scheduling and runtime data. This provides us with information on what jobs could be missed (or need to be run later) in the event that a server is brought down. This could also be useful after an unexpected outage, allowing us to review any missed or failed jobs en masse. 通过查看作业计划和运行时数据,使我们能够更好地计划服务器停机时间。 这为我们提供了有关在服务器关闭的情况下可能错过(或需要稍后运行)哪些作业的信息。 这在意外中断后也很有用,这使我们能够全面审查任何丢失或失败的工作。
With some creativity, other uses can be concocted for this data, including tracking SSIS package execution, replication performance, backups, index maintenance, ETL processes, warehouse data loads, and more!
凭借一些创造力,可以将这些数据用于其他用途,包括跟踪SSIS包的执行,复制性能,备份,索引维护,ETL流程,仓库数据加载等等!
为什么不是每个人都这样做? (Why Doesn’t Everyone Do This?)
As with many alerting, monitoring, or trending processes, we often don’t see a need for them until something breaks and a need arises. Until a job or related process fails, the need to pay attention to runtimes may not be realized.
与许多警报,监视或趋势处理一样,我们常常在出现问题并产生需求之前才发现对它们的需求。 直到作业或相关过程失败,才可能意识到需要注意运行时。
To make matters more difficult, SQL Server does not provide a spectacular way to monitor and trend job progress and results over time. SQL Server Agent contains a GUI that can show us details on recent job outcomes, as well as the ability to monitor jobs in progress:
使事情变得更加困难的是,SQL Server没有提供一种出色的方法来监视和跟踪工作进度和结果的趋势。 SQL Server代理包含一个GUI,可以向我们显示有关最近作业结果的详细信息,以及监视正在进行的作业的能力:
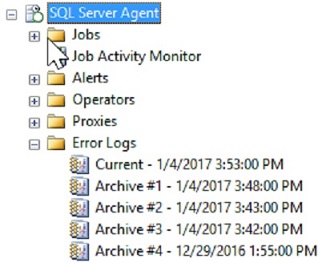
From the SQL Server Agent menu, we can click on Job Activity Monitor in order to view the up-to-the-minute status of each job. From the jobs menu, the history for all or any subset of jobs can be viewed, as well as for any single job:
从SQL Server代理菜单中,我们可以单击“作业活动监视器”,以查看每个作业的最新状态。 从作业菜单中,可以查看所有或任何作业子集以及任何单个作业的历史记录:
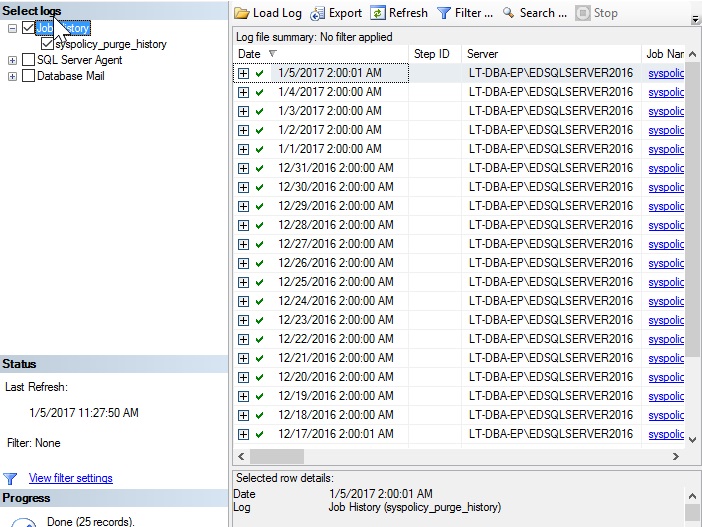
This information is useful, but its utility is limited in a number of ways:
该信息很有用,但是其实用性受到多种方式的限制:
- Job history is stored in MSDB for a limited amount of time, based on a server’s configuration. Metrics about previous job runs may be removed once past a set retention period. 根据服务器的配置,作业历史记录在MSDB中存储的时间有限。 超过设定的保留期限后,可能会删除有关先前作业运行的指标。
- There are few ways to trend or view any metrics over a period of time. 在一段时间内,很少有趋势或查看任何指标的方法。
- Viewing the combined job history for multiple servers is not intuitive. 查看多个服务器的合并作业历史记录并不直观。
- We have little ability to customize how this data is presented to us. 我们几乎无法定制如何将这些数据呈现给我们。
An alternative to navigating job history data via the GUI is to use a handful of views within MSDB, each of which provides data on job configuration, job schedules, and job history:
通过GUI导航作业历史记录数据的另一种方法是使用MSDB中的少数视图,每个视图都提供有关作业配置,作业计划和作业历史记录的数据:
- MSDB.dbo.sysjobs: Provides a list of all jobs on the local SQL Server, along with relevant metadata. MSDB.dbo.sysjobs :提供本地SQL Server上所有作业的列表以及相关的元数据。
- MSDB.dbo.sysschedules: Contains all job schedules defined on the local server, along with their details. MSDB.dbo.sysschedules :包含本地服务器上定义的所有作业计划及其详细信息。
- MSDB.dbo.sysjobhistory: Contains a row for each job and job step that is executed on the local server. MSDB.dbo.sysjobhistory :包含在本地服务器上执行的每个作业和作业步骤的行。
- MSDB.dbo.sysjobschedules: Contains a row per job/schedule relationship. MSDB.dbo.sysjobschedules :每个作业/计划关系包含一行。
- MSDB.dbo.sysjobactivity: Contains details on recent job activity, including accurate future runtimes. MSDB.dbo.sysjobactivity :包含有关最近作业活动的详细信息,包括准确的将来运行时。
These views provide valuable information but are not easy to read and consume. While Microsoft provides documentation on their purpose and contents, many of the data types are suboptimal, and the mixed contents of sysjobhistory are not intuitive.
这些视图提供了有价值的信息,但不容易阅读和使用。 尽管Microsoft提供了有关其用途和内容的文档,但是许多数据类型不是最佳的,并且sysjobhistory的混合内容也不直观。
For example, dates and times are stored as integers. 03:15:05 is stored as 31505 and 9/23/2016 is 20160923. Job run duration is stored as an integer in the format HHMMSS, such that 85 seconds would appear as 125 (one minute and twenty-five seconds). Job schedules are stored using numeric constants to represent how often they run, run time, and run intervals.
例如,日期和时间存储为整数。 03:15:05被存储为31505,而9/23/2016是20160923。作业运行持续时间以HHMMSS格式存储为整数,因此85秒将显示为125(一分钟二十五秒)。 使用数字常量存储作业计划,以表示它们的运行频率,运行时间和运行间隔。
Given the unintuitive interface for pulling job history data, it’s often seen as not worth the time to pull, convert, and present the data unless absolutely needed. Alternatively, enterprise job scheduler software can be purchased that will manage SQL Server Agent jobs. While convenient, software costs money and not all companies can or want to spend resources on this sort of software.
给定用于提取作业历史数据的直观界面,除非绝对需要,否则通常不值得花费时间来提取,转换和显示数据。 或者,可以购买企业作业计划程序软件来管理SQL Server代理作业。 虽然方便,但软件会花费金钱,并且并非所有公司都可以或希望在此类软件上花费资源。
构建工作绩效跟踪解决方案 (Building a Job Performance Tracking Solution)
Given the constraints presented thus far, we can choose to build our own solution for collecting and storing job performance metrics. Once collected, reporting on them becomes a simple matter of defining what we want to see and writing some simpler queries to crunch our data appropriately.
鉴于目前存在的限制,我们可以选择构建自己的解决方案以收集和存储工作绩效指标。 收集后,对其进行报告就变得很简单,即定义我们希望看到的内容并编写一些更简单的查询以适当地处理数据。
The steps we will follow to create a self-sufficient solution to the problem presented above are:
我们将为上述问题创建一个自给自足的解决方案的步骤如下:
- Create new tables that will store job performance metrics. 创建将存储作业绩效指标的新表。
- Create a stored procedure to collect job metrics and store them in the tables above. 创建一个存储过程来收集作业指标并将其存储在上表中。
- Clean up old data, as prescribed by whatever retention rules we deem necessary. 根据我们认为必要的保留规则,清理旧数据。
- Schedule a job to regularly collect our job performance data. 安排工作以定期收集我们的工作绩效数据。
- Create reports that consume this data and return useful results (see the next section). 创建使用此数据并返回有用结果的报告(请参阅下一节)。
As we build this solution, feel free to consider ways of customizing it. Add or remove columns or tables that you don’t think are important to your needs and adjust processes to fit the data you need. The beauty of any hand-built process is the ability to have complete control over customization and implementation!
在构建此解决方案时,请随时考虑自定义方法。 添加或删除对您的需求不重要的列或表,并调整流程以适合所需的数据。 任何手工构建过程的美丽之处在于可以完全控制自定义和实现!
桌子 (Tables)
We’ll create four tables to store data pertinent to our metrics. Two will be dimension tables that include basic information about jobs and schedules. The other two will contain job and job step execution results. These tables are structured like warehouse tables in order to facilitate easier consumption by reporting products or processes, though you are free to name & structure based on whatever standards you typically follow.
我们将创建四个表来存储与我们的指标相关的数据。 两个维度表将包含有关作业和时间表的基本信息。 其他两个将包含作业和作业步骤执行结果。 这些表的结构类似于仓库表,以便通过报告产品或过程来简化消耗,尽管您可以根据通常遵循的任何标准来命名和结构化。
CREATE TABLE dbo.dim_sql_agent_job
( dim_sql_agent_job_Id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_dim_sql_agent_job PRIMARY KEY CLUSTERED,
Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL,
Sql_Agent_Job_Name NVARCHAR(128) NOT NULL,
Job_Create_Datetime DATETIME NOT NULL,
Job_Last_Modified_Datetime DATETIME NOT NULL,
Is_Enabled BIT NOT NULL,
Is_Deleted BIT NOT NULL
);
CREATE NONCLUSTERED INDEX IX_dim_sql_agent_job_Sql_Agent_Job_Id ON dbo.dim_sql_agent_job (Sql_Agent_Job_Id);
This table stores a row per Agent job, with the Sql_Agent_Job_Id being pulled directly from MSDB.dbo.sysjobs. Since this is a GUID, we choose to create a surrogate key to represent the clustered primary key on the table to help improve performance when writing to this table.
该表为每个Agent作业存储一行,其中Sql_Agent_Job_Id直接从MSDB.dbo.sysjobs中提取 。 由于这是一个GUID,因此我们选择创建一个代理键来表示表上的集群主键,以帮助提高写入该表时的性能。
Persisting this data allows for retention of job data, even if a job is disabled or deleted on the server. This can be useful for understanding how a job previously performed, or how a new and old version of a process compare.
保留此数据可以保留作业数据,即使在服务器上禁用或删除了作业也是如此。 这对于了解先前的工作执行情况或流程的新旧版本之间的比较很有用。
CREATE TABLE dbo.dim_sql_agent_schedule
( Schedule_Id INT NOT NULL CONSTRAINT PK_fact_sql_agent_job_schedule PRIMARY KEY CLUSTERED,
Schedule_Name NVARCHAR(128) NOT NULL,
Is_Enabled BIT NOT NULL,
Is_Deleted BIT NOT NULL,
Schedule_Start_Date DATE NOT NULL,
Schedule_End_Date DATE NOT NULL,
Schedule_Occurrence VARCHAR(25) NOT NULL,
Schedule_Occurrence_Detail VARCHAR(256) NULL,
Schedule_Frequency VARCHAR(256) NULL,
Schedule_Created_Datetime DATETIME NOT NULL,
Schedule_Last_Modified_Datetime DATETIME NOT NULL
);
CREATE NONCLUSTERED INDEX IX_dim_sql_agent_schedule_Schedule_Last_Modified_Datetime ON dbo.dim_sql_agent_schedule (Schedule_Last_Modified_Datetime);
Similar to the previous dimension table, this one stores a row per schedule, as found in MSDB.dbo.sysschedules, with schedule_id being the unique identifier per schedule. This data is somewhat optional in that we do not need schedule details in order to understand when jobs run, for how long, and their results, but the added information is useful for understanding what schedules are used, and for what jobs.
与上一个维表类似,此表按MSDB.dbo.sysschedules中的每个时间表存储一行,schedule_id是每个时间表的唯一标识符。 该数据有些可选,因为我们不需要日程表详细信息即可了解作业的运行时间,持续时间及其结果,但是添加的信息对于了解使用了哪些日程表以及执行哪些作业很有用。
If desired, we could also create a linking table that illustrates the relationships between jobs and schedules, allowing us to understand when jobs are supposed to run, which schedules they run under, and predict future job schedules. This information is also not needed in order to fully comprehend job history but could be useful for predicting the best times for planned maintenance, outages, or to effectively schedule new jobs. Data for this task can be pulled from MSDB.dbo.sysjobschedules and is a linking table that contains a single row per job-schedule pairing (a one-to-many relationship). We can easily create a small table to store and maintain this data:
如果需要,我们还可以创建一个链接表,以说明作业和计划表之间的关系,使我们能够了解应该在何时运行作业,计划在哪个时间表下运行,并预测未来的作业计划。 为了完全理解工作历史,也不需要此信息,但是对于预测计划的维护,停机或最佳安排新工作的最佳时间可能有用。 可以从MSDB.dbo.sysjobschedules中提取此任务的数据,该数据是一个链接表,其中每个作业表对都包含一行(一对多关系)。 我们可以轻松地创建一个小表来存储和维护此数据:
CREATE TABLE dbo.fact_sql_agent_schedule_assignment
( fact_sql_agent_schedule_assignment_id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_fact_sql_agent_schedule_assignment PRIMARY KEY CLUSTERED,
Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL,
Schedule_Id INT NOT NULL,
Next_Run_Datetime DATETIME NULL
);
CREATE NONCLUSTERED INDEX IX_fact_sql_agent_schedule_assignment_Sql_Agent_Job_Id ON dbo.fact_sql_agent_schedule_assignment (Sql_Agent_Job_Id);
A surrogate key is used as a more reliable clustered index, but a combination of job_id and schedule_id would also work. Next_Run_Datetime is optional, but could be handy under some circumstances. Note that the accuracy of this column will be based on how frequently this data is updated. If the job runs more often than the collection of our job performance data, then this column will not always be up-to-date.
代理键用作更可靠的聚簇索引,但是job_id和schedule_id的组合也可以使用。 Next_Run_Datetime是可选的,但在某些情况下可能很方便。 请注意,此列的准确性将取决于此数据的更新频率。 如果该作业的运行频率比我们的工作绩效数据的收集频率高,那么此列将不会总是最新的。
CREATE TABLE dbo.fact_job_run_time
( Sql_Agent_Job_Run_Instance_Id INT NOT NULL CONSTRAINT PK_fact_job_run_time PRIMARY KEY CLUSTERED,
Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL,
Job_Start_Datetime DATETIME NOT NULL,
Job_End_Datetime AS DATEADD(SECOND, job_duration_seconds, Job_Start_Datetime) PERSISTED,
Job_Duration_Seconds INT NOT NULL,
Job_Status VARCHAR(8) NOT NULL
);
CREATE NONCLUSTERED INDEX IX_fact_job_run_time_job_start_time ON dbo.fact_job_run_time (Job_Start_Datetime);
CREATE NONCLUSTERED INDEX IX_fact_job_run_time_Sql_Agent_Job_Id ON dbo.fact_job_run_time (Sql_Agent_Job_Id);
Now we can introduce the table where job run statistics will be stored. Each row represents a single job run for a given job_id, when it started, its duration, and its completion status. The end time is a computed column, as we can determine it easily once the start time and duration are known. The status will contain a friendly string indicating the job result: Failure, Success, Retry, or Canceled. Note that the schedule that triggered the job is not referenced here. As a result, schedule data is not required for this to work but is nice to have in general.
现在我们可以介绍存储作业运行统计信息的表。 每行代表给定job_id的单个作业运行,启动时的时间,持续时间和完成状态。 结束时间是一个计算列,因为一旦知道开始时间和持续时间,我们就可以轻松确定它。 该状态将包含指示工作结果的友好字符串:“失败”,“成功”,“重试”或“已取消”。 请注意,此处未引用触发作业的计划。 因此,不需要时间表数据即可工作,但总体上来说很好。
CREATE TABLE dbo.fact_step_job_run_time
( Sql_Agent_Job_Run_Instance_Id INT NOT NULL CONSTRAINT PK_fact_step_job_run_time PRIMARY KEY CLUSTERED,
Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL,
Sql_Agent_Job_Step_Id INT NOT NULL,
Job_Step_Start_Datetime DATETIME NOT NULL,
Job_Step_End_Datetime AS DATEADD(SECOND, Job_Step_Duration_seconds, Job_Step_Start_Datetime) PERSISTED,
Job_Step_Duration_seconds INT NOT NULL,
Job_Step_Status VARCHAR(8) NOT NULL
);
CREATE NONCLUSTERED INDEX IX_fact_step_job_run_time_Sql_Agent_Job_Id_Sql_Agent_Job_Step_Id ON dbo.fact_step_job_run_time (Sql_Agent_Job_Id, Sql_Agent_Job_Step_Id);
CREATE NONCLUSTERED INDEX IX_fact_step_job_run_time_job_step_start_time ON dbo.fact_step_job_run_time (Job_Step_Start_Datetime);
This table is similar to our last one, and stores the metrics for individual job steps. Completed job data is omitted from this data as it is stored in the other table. In addition, steps in progress are not recorded—only those that have completed. Depending on your use-case, there could be value in combining job and job step data into a single table, much like how MSDB.dbo.sysjobhistory stores it. Here, we choose to separate them as we may not always want individual step data, and having to carve this out from a larger data set could be a nuisance in terms of report/script development and performance.
该表类似于我们的上一个表,并存储各个作业步骤的指标。 由于已完成的作业数据存储在另一个表中,因此将从该数据中省略。 此外,不记录进行中的步骤-仅记录已完成的步骤。 根据您的用例,将作业和作业步骤数据组合到一个表中可能会很有价值,就像MSDB.dbo.sysjobhistory如何存储它一样。 在这里,我们选择将它们分开,因为我们可能并不总是需要单独的步骤数据,而必须从更大的数据集中剔除这些数据可能会对报告/脚本开发和性能造成麻烦。
指标收集存储过程 (Metrics Collection Stored Procedure)
Now that we have built a number of custom tables to store our job performance data, the next step is to create a process that pulls the data from MSDB, transforms it into a more user-friendly form, and stores it in those tables. We will manage the gathering of data for each table separately, allowing for easier customization and testing of our code.
现在我们已经构建了许多自定义表来存储我们的工作绩效数据,下一步是创建一个流程,该流程从MSDB中提取数据,将其转换为更用户友好的形式,并将其存储在这些表中。 我们将分别管理每个表的数据收集,从而使自定义和测试代码更加容易。
CREATE PROCEDURE dbo.usp_get_job_execution_metrics
AS
BEGIN
SET NOCOUNT ON;
The name is arbitrary, but this seems descriptive enough. No parameters are used by the stored procedure as I intentionally want to keep this as simple as possible. If you have a need to pass in additional configuration or timing options, doing so should be relatively easy.
名称是任意的,但这似乎足以说明问题。 存储过程不使用任何参数,因为我有意希望使其尽可能简单。 如果您需要传递其他配置或计时选项,则这样做应该相对容易。
DECLARE @Schedule_Data_Last_Modify_Datetime DATETIME;
SELECT
@Schedule_Data_Last_Modify_Datetime = MAX(dim_sql_agent_schedule.Schedule_Last_Modified_Datetime)
FROM dbo.dim_sql_agent_schedule;
IF @Schedule_Data_Last_Modify_Datetime IS NULL
BEGIN
SELECT @Schedule_Data_Last_Modify_Datetime = '1/1/1900';
END
We’ll collect job schedules first as this data is relatively small & simple. The TSQL above allows us to find the date/time of the last change in our data set and only collect modifications that have occurred since then. If no data exists, then we set our last modify date/time to a very old date, in order to ensure we collect everything on the first job run.
我们将首先收集工作时间表,因为这些数据相对较小且简单。 上面的TSQL使我们能够找到数据集中最后一次更改的日期/时间,并且仅收集自那时以来发生的修改。 如果没有数据,那么我们将上次修改日期/时间设置为非常旧的日期,以确保我们在第一次作业运行时收集所有信息。
With this housekeeping out of the way, we can proceed to collect all schedule data from the local SQL Server. A MERGE statement is used for convenience, as it allows us to insert and update rows appropriately all at once. While this TSQL looks long, it’s messiness is primarily due to the need for us to convert integer identifiers in MSDB.dbo.sysschedules into more readable data types. These conversions are not pretty, and there are many ways to accomplish this, but by fixing our data now, we make using it later much, much easier.
有了这种整理工作,我们可以继续从本地SQL Server收集所有计划数据。 为了方便起见,使用MERGE语句是因为它允许我们一次适当地插入和更新行。 尽管此TSQL看起来很长,但它的混乱主要是因为我们需要将MSDB.dbo.sysschedules中的整数标识符转换为更具可读性的数据类型。 这些转换不是很漂亮,并且有很多方法可以完成此操作,但是通过立即修复数据,我们以后可以更轻松地使用它。
MERGE INTO dbo.dim_sql_agent_schedule AS SCHEDULE_TARGET
USING (
SELECT
sysschedules.schedule_id,
sysschedules.name AS Schedule_Name,
sysschedules.enabled AS Is_Enabled,
0 AS Is_Deleted,
CAST(SUBSTRING(CAST(sysschedules.active_start_date AS VARCHAR(MAX)), 5, 2) + '/' + SUBSTRING(CAST(sysschedules.active_start_date AS VARCHAR(MAX)), 7, 2) + '/' + SUBSTRING(CAST(sysschedules.active_start_date AS VARCHAR(MAX)), 1, 4) AS DATE) AS Schedule_Start_Date,
CAST(SUBSTRING(CAST(sysschedules.active_end_date AS VARCHAR(MAX)), 5, 2) + '/' + SUBSTRING(CAST(sysschedules.active_end_date AS VARCHAR(MAX)), 7, 2) + '/' + SUBSTRING(CAST(sysschedules.active_end_date AS VARCHAR(MAX)), 1, 4) AS DATE) AS Schedule_End_Date,
CASE sysschedules.freq_type
WHEN 1 THEN 'Once'
WHEN 4 THEN 'Daily'
WHEN 8 THEN 'Weekly'
WHEN 16 THEN 'Monthly'
WHEN 32 THEN 'Monthly (relative)'
WHEN 64 THEN 'At Agent Startup'
WHEN 128 THEN 'When CPU(s) idle'
END AS Schedule_Occurrence,
CASE sysschedules.freq_type
WHEN 1 THEN 'Once'
WHEN 4 THEN 'Every ' + CONVERT(VARCHAR, sysschedules.freq_interval) + ' day(s)'
WHEN 8 THEN 'Every ' + CONVERT(VARCHAR, sysschedules.freq_recurrence_factor) + ' weeks(s) on ' +
LEFT( CASE WHEN sysschedules.freq_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 2 = 2 THEN 'Monday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 32 = 32 THEN 'Friday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END ,
LEN( CASE WHEN sysschedules.freq_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 2 = 2 THEN 'Monday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 32 = 32 THEN 'Friday, ' ELSE '' END +
CASE WHEN sysschedules.freq_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END) - 1)
WHEN 16 THEN 'Day ' + CONVERT(VARCHAR, sysschedules.freq_interval) + ' of every ' + CONVERT(VARCHAR, sysschedules.freq_recurrence_factor) + ' month(s)'
WHEN 32 THEN 'The ' + CASE sysschedules.freq_relative_interval
WHEN 1 THEN 'First'
WHEN 2 THEN 'Second'
WHEN 4 THEN 'Third'
WHEN 8 THEN 'Fourth'
WHEN 16 THEN 'Last'
END +
CASE sysschedules.freq_interval
WHEN 1 THEN ' Sunday'
WHEN 2 THEN ' Monday'
WHEN 3 THEN ' Tuesday'
WHEN 4 THEN ' Wednesday'
WHEN 5 THEN ' Thursday'
WHEN 6 THEN ' Friday'
WHEN 7 THEN ' Saturday'
WHEN 8 THEN ' Day'
WHEN 9 THEN ' Weekday'
WHEN 10 THEN ' Weekend Day'
END + ' of every ' + CONVERT(VARCHAR, sysschedules.freq_recurrence_factor) + ' month(s)'
END AS Schedule_Occurrence_Detail,
CASE sysschedules.freq_subday_type
WHEN 1 THEN 'Occurs once at ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':')
WHEN 2 THEN 'Occurs every ' +
CONVERT(VARCHAR, sysschedules.freq_subday_interval) + ' Seconds(s) between ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') + ' and ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_end_time), 6), 5, 0, ':'), 3, 0, ':')
WHEN 4 THEN 'Occurs every ' +
CONVERT(VARCHAR, sysschedules.freq_subday_interval) + ' Minute(s) between ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') + ' and ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_end_time), 6), 5, 0, ':'), 3, 0, ':')
WHEN 8 THEN 'Occurs every ' +
CONVERT(VARCHAR, sysschedules.freq_subday_interval) + ' Hour(s) between ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') + ' and ' +
STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_end_time), 6), 5, 0, ':'), 3, 0, ':')
END AS Schedule_Frequency,
sysschedules.date_created AS Schedule_Created_Datetime,
sysschedules.date_modified AS Schedule_Last_Modified_Datetime
FROM msdb.dbo.sysschedules
WHERE sysschedules.date_modified > @Schedule_Data_Last_Modify_Datetime) AS SCHEDULE_SOURCE
ON (SCHEDULE_SOURCE.schedule_id = SCHEDULE_TARGET.schedule_id)
WHEN NOT MATCHED BY TARGET
THEN INSERT
(Schedule_Id, Schedule_Name, Is_Enabled, Is_Deleted, Schedule_Start_Date, Schedule_End_Date, Schedule_Occurrence, Schedule_Occurrence_Detail, Schedule_Frequency, Schedule_Created_Datetime, Schedule_Last_Modified_Datetime)
VALUES (
SCHEDULE_SOURCE.Schedule_Id,
SCHEDULE_SOURCE.Schedule_Name,
SCHEDULE_SOURCE.Is_Enabled,
SCHEDULE_SOURCE.Is_Deleted,
SCHEDULE_SOURCE.Schedule_Start_Date,
SCHEDULE_SOURCE.Schedule_End_Date,
SCHEDULE_SOURCE.Schedule_Occurrence,
SCHEDULE_SOURCE.Schedule_Occurrence_Detail,
SCHEDULE_SOURCE.Schedule_Frequency,
SCHEDULE_SOURCE.Schedule_Created_Datetime,
SCHEDULE_SOURCE.Schedule_Last_Modified_Datetime)
WHEN MATCHED
THEN UPDATE
SET Schedule_Name = SCHEDULE_SOURCE.Schedule_Name,
Is_Enabled = SCHEDULE_SOURCE.Is_Enabled,
Is_Deleted = SCHEDULE_SOURCE.Is_Deleted,
Schedule_Start_Date = SCHEDULE_SOURCE.Schedule_Start_Date,
Schedule_End_Date = SCHEDULE_SOURCE.Schedule_End_Date,
Schedule_Occurrence = SCHEDULE_SOURCE.Schedule_Occurrence,
Schedule_Occurrence_Detail = SCHEDULE_SOURCE.Schedule_Occurrence_Detail,
Schedule_Frequency = SCHEDULE_SOURCE.Schedule_Frequency,
Schedule_Created_Datetime = SCHEDULE_SOURCE.Schedule_Created_Datetime,
Schedule_Last_Modified_Datetime = SCHEDULE_SOURCE.Schedule_Last_Modified_Datetime;
Essentially, this code collects all schedule data for those modified since our last modified date/time and either inserts rows for new schedules or updates for those that already exist. All of the case statements are used to convert the schedule frequency, interval, intervals, and recurrence into strings that can be easily consumed by reports or metrics collection processes. The integers are easy to use for system processing, but not easy for humans to consume. Our primary goal here is to create a simple data store that is easy to use by anyone, even if the user is not someone terribly familiar with the underlying MSDB data.
本质上,此代码收集自上次修改日期/时间以来已修改的那些计划的所有计划数据,并为新计划插入行或为已存在的计划更新。 所有这些case语句都用于将调度频率,间隔,间隔和重复性转换为字符串,这些字符串可以被报表或指标收集过程轻松使用。 整数易于用于系统处理,但不便于人类使用。 我们这里的主要目标是创建一个简单的数据存储库,即使用户不是非常熟悉基础MSDB数据的人,任何人都可以轻松使用它。
An additional segment of code can be added to manage whether a schedule is deleted or not. This is optional, but a nice way to maintain some schedule history on those that had previously been used, but have been deleted:
可以添加其他代码段来管理是否删除计划。 这是可选的,但对于在以前使用但已删除的日程表上保留一些日程表历史记录是一种不错的方法:
UPDATE dim_sql_agent_schedule
SET Is_Enabled = 0,
Is_Deleted = 1
FROM dbo.dim_sql_agent_schedule
LEFT JOIN msdb.dbo.sysschedules
ON sysschedules.schedule_id = dim_sql_agent_schedule.Schedule_Id
WHERE sysschedules.schedule_id IS NULL;
For any schedule not found on the server, the Is_Enabled and Is_Deleted bits are set appropriately.
对于在服务器上找不到的任何计划,将适当设置Is_Enabled和Is_Deleted位。
With schedule data in hand, we can now pull job data, allowing us to maintain a full list of all SQL Server Agent jobs. Comparatively, job data is far simpler than schedules, as there is no date/time data or other temporal information encoded in suboptimal data types. To start off, we’ll collect the most recent job data update from our data set:
有了日程表数据,我们现在可以提取作业数据,从而可以维护所有SQL Server Agent作业的完整列表。 相比较而言,作业数据比计划表要简单得多,因为没有日期/时间数据或其他时间信息编码为次优数据类型。 首先,我们将从数据集中收集最新的职位数据更新:
DECLARE @Job_Data_Last_Modify_Datetime DATETIME;
SELECT
@Job_Data_Last_Modify_Datetime = MAX(dim_sql_agent_job.Job_Last_Modified_Datetime)
FROM dbo.dim_sql_agent_job;
IF @Job_Data_Last_Modify_Datetime IS NULL
BEGIN
SELECT @Job_Data_Last_Modify_Datetime = '1/1/1900';
END
As with schedules, this cuts down the data set we collect from MSDB to only include jobs that were created or updated since the last collection time. With that complete, we can use a MERGE statement to pull in jobs data from MSDB.dbo.sysjobs.
与时间表一样,这会将我们从MSDB收集的数据集减少为仅包括自上次收集时间以来创建或更新的作业。 完成后,我们可以使用MERGE语句从MSDB.dbo.sysjobs中提取作业数据。
MERGE INTO dbo.dim_sql_agent_job AS JOB_TARGET
USING (
SELECT
sysjobs.job_id AS Sql_Agent_Job_Id,
sysjobs.name AS Sql_Agent_Job_Name,
sysjobs.date_created AS Job_Create_Datetime,
sysjobs.date_modified AS Job_Last_Modified_Datetime,
sysjobs.enabled AS Is_Enabled,
0 AS Is_Deleted
FROM msdb.dbo.sysjobs
WHERE sysjobs.date_modified > @Job_Data_Last_Modify_Datetime) AS JOB_SOURCE
ON (JOB_SOURCE.Sql_Agent_Job_Id = JOB_TARGET.Sql_Agent_Job_Id)
WHEN NOT MATCHED BY TARGET
THEN INSERT
(Sql_Agent_Job_Id, Sql_Agent_Job_Name, Job_Create_Datetime, Job_Last_Modified_Datetime, Is_Enabled, Is_Deleted)
VALUES (
JOB_SOURCE.Sql_Agent_Job_Id,
JOB_SOURCE.Sql_Agent_Job_Name,
JOB_SOURCE.Job_Create_Datetime,
JOB_SOURCE.Job_Last_Modified_Datetime,
JOB_SOURCE.Is_Enabled,
JOB_SOURCE.Is_Deleted)
WHEN MATCHED
THEN UPDATE
SET Sql_Agent_Job_Id = JOB_SOURCE.Sql_Agent_Job_Id,
Sql_Agent_Job_Name = JOB_SOURCE.Sql_Agent_Job_Name,
Job_Create_Datetime = JOB_SOURCE.Job_Create_Datetime,
Job_Last_Modified_Datetime = JOB_SOURCE.Job_Last_Modified_Datetime,
Is_Enabled = JOB_SOURCE.Is_Enabled,
Is_Deleted = JOB_SOURCE.Is_Deleted;
When a job is not found in our data, it is inserted, and when it is found, it is updated. Lastly, we check for deleted jobs and update as appropriate, similar to with schedules:
在我们的数据中找不到作业时,将其插入,并在找到该作业时对其进行更新。 最后,我们检查已删除的作业并进行适当的更新,类似于时间表:
UPDATE dim_sql_agent_job
SET Is_Enabled = 0,
Is_Deleted = 1
FROM dbo.dim_sql_agent_job
LEFT JOIN msdb.dbo.sysjobs
ON sysjobs.Job_Id = dim_sql_agent_job.Sql_Agent_Job_Id
WHERE sysjobs.Job_Id IS NULL;
Job associations can be tracked by pulling directly from MSDB.dbo.sysjobschedules, but the next run date is not updated constantly. There is a delay in SQL Server before a background process runs and updates this data. If you need up-to-the-minute accuracy, then use MSDB.dbo.sysjobactivity, which is updated as jobs execute and complete. As a bonus, the date/time columns are actually stored in DATETIME data types!
可以通过直接从MSDB.dbo.sysjobschedules中提取来跟踪作业关联,但是下一个运行日期不会不断更新。 在SQL Server中,后台进程运行和更新此数据之前存在延迟。 如果您需要最新的准确性,请使用MSDB.dbo.sysjobactivity ,它会随着作业的执行和完成而更新。 另外,日期/时间列实际上存储在DATETIME数据类型中!
The following script pulls the assignment details first, and then joins back to pull the next run date/time:
以下脚本首先提取分配详细信息,然后再合并以提取下一个运行日期/时间:
MERGE INTO dbo.fact_sql_agent_schedule_assignment AS JOB_ASSIGNMENT_TARGET
USING (
SELECT
sysjobschedules.schedule_id,
sysjobschedules.job_id
FROM msdb.dbo.sysjobschedules) AS JOB_ASSIGNMENT_SOURCE
ON (JOB_ASSIGNMENT_SOURCE.job_id = JOB_ASSIGNMENT_TARGET.Sql_Agent_Job_Id
AND JOB_ASSIGNMENT_SOURCE.schedule_id = JOB_ASSIGNMENT_TARGET.schedule_id)
WHEN NOT MATCHED BY TARGET
THEN INSERT
(Sql_Agent_Job_Id, Schedule_Id)
VALUES (
JOB_ASSIGNMENT_SOURCE.job_id,
JOB_ASSIGNMENT_SOURCE.schedule_id)
WHEN NOT MATCHED BY SOURCE
THEN DELETE;
WITH CTE_LAST_RUN_TIME AS (
SELECT
sysjobactivity.job_id,
MIN(sysjobactivity.next_scheduled_run_date) AS Next_Run_Datetime
FROM msdb.dbo.sysjobactivity
WHERE sysjobactivity.next_scheduled_run_date > CURRENT_TIMESTAMP
GROUP BY sysjobactivity.job_id)
UPDATE fact_sql_agent_schedule_assignment
SET Next_Run_Datetime = CTE_LAST_RUN_TIME.Next_Run_Datetime
FROM CTE_LAST_RUN_TIME
INNER JOIN dbo.fact_sql_agent_schedule_assignment
ON CTE_LAST_RUN_TIME.job_id = fact_sql_agent_schedule_assignment.Sql_Agent_Job_Id;
The primary difference in this MERGE statement is that we will delete any associations that do not exist as there is little benefit in maintaining old relationships. The next run time is the same for all assigned schedules, in case more than one exists on a job. This keeps our data as simple as possible for future use.
此MERGE语句的主要区别在于,我们将删除不存在的任何关联,因为维护旧关系几乎没有好处。 如果作业中存在多个调度,则下一个运行时间对于所有分配的调度都是相同的。 这样可以使我们的数据尽可能简单,以备将来使用。
The next two blocks of TSQL comprise the bulk of our stored procedure and encompass the actual job duration metrics collection.
TSQL的后两个块构成了我们存储过程的大部分,并包含了实际的作业持续时间指标集合。
WITH CTE_NORMALIZE_DATETIME_DATA AS (
SELECT
sysjobhistory.instance_id AS Sql_Agent_Job_Run_Instance_Id,
sysjobhistory.job_id AS Sql_Agent_Job_Id,
CAST(sysjobhistory.run_date AS VARCHAR(MAX)) AS Run_Date_VARCHAR,
REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_time AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_time AS VARCHAR(MAX)) AS Run_Time_VARCHAR,
REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_duration AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_duration AS VARCHAR(MAX)) AS Run_Duration_VARCHAR,
sysjobhistory.run_status AS Run_Status
FROM msdb.dbo.sysjobhistory
WHERE sysjobhistory.instance_id NOT IN
(SELECT fact_job_run_time.Sql_Agent_Job_Run_Instance_Id FROM dbo.fact_job_run_time)
AND sysjobhistory.step_id = 0)
INSERT INTO dbo.fact_job_run_time
(Sql_Agent_Job_Run_Instance_Id, Sql_Agent_Job_Id, Job_Start_Datetime, Job_Duration_Seconds, Job_Status)
SELECT
CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Run_Instance_Id,
CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Id,
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 5, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 7, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 1, 4) AS DATETIME) +
CAST(STUFF(STUFF(CTE_NORMALIZE_DATETIME_DATA.Run_Time_VARCHAR, 5, 0, ':'), 3, 0, ':') AS DATETIME) AS Job_Start_Datetime,
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 1, 2) AS INT) * 3600 +
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 3, 2) AS INT) * 60 +
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 5, 2) AS INT) AS Job_Duration_Seconds,
CASE CTE_NORMALIZE_DATETIME_DATA.Run_Status
WHEN 0 THEN 'Failure'
WHEN 1 THEN 'Success'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Canceled'
ELSE 'Unknown'
END AS Job_Status
FROM CTE_NORMALIZE_DATETIME_DATA;
A common table expression (CTE) is used to reformat the date/time/duration data, and then the subsequent INSERT INTO…SELECT statement finishes the formatting and places the data into our tables.
使用公用表表达式(CTE)重新格式化日期/时间/持续时间数据,然后随后的INSERT INTO…SELECT语句完成格式化并将数据放入我们的表中。
To put the data types used in MSDB.dbo.sysjobhistory into perspective:
要将MSDB.dbo.sysjobhistory中使用的数据类型放在透视图中:
- Run_status is an integer that indicates 0 (failure), 1 (success), 2 (retry), and 3 (canceled). Run_status是一个整数,表示0(失败),1(成功),2(重试)和3(取消)。
- Run_date is an integer representation of the YYYMMDD date of the job execution. Run_date是作业执行的YYYMMDD日期的整数表示。
- Run_time is an integer representation of the HHMMSS time of the job execution Run_time是作业执行的HHMMSS时间的整数表示
- Run_duration is the amount of time the job ran for, formatted as HHMMSS. Run_duration是作业运行的时间,格式为HHMMSS。
Since integers are used for dates, times, and duration, there is the possibility that the number of digits will vary depending on the time of the day. For example, a time of “20001” would indicate 8:00:01 pm with no need for a leading zero. This added complexity ensures some necessary gnarly string manipulation in order to be certain that the resulting numbers are valid DATETIME values, rather than INT or VARCHAR representations.
由于整数用于日期,时间和持续时间,因此位数可能会根据一天中的时间而有所不同。 例如,时间“ 20001”表示下午8:00:01,不需要前导零。 这种增加的复杂性确保了一些必要的粗糙字符串操作,以确保结果数字是有效的DATETIME值,而不是INT或VARCHAR表示形式。
This TSQL pulls exclusively those rows with step_id = 0, which indicates overall job completion. Any job steps numbered 1 or higher correspond to each job step within a job, which are tracked in a separate fact table, as indicated below.
该TSQL仅提取step_id = 0的那些行,指示总体作业完成。 编号为1或更高的任何作业步骤都对应于该作业中的每个作业步骤,这些作业步骤在单独的事实表中进行跟踪,如下所示。
WITH CTE_NORMALIZE_DATETIME_DATA AS (
SELECT
sysjobhistory.instance_id AS Sql_Agent_Job_Run_Instance_Id,
sysjobhistory.job_id AS Sql_Agent_Job_Id,
sysjobhistory.step_id AS Sql_Agent_Job_Step_Id,
CAST(sysjobhistory.run_date AS VARCHAR(MAX)) AS Run_Date_VARCHAR,
REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_time AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_time AS VARCHAR(MAX)) AS Run_Time_VARCHAR,
REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_duration AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_duration AS VARCHAR(MAX)) AS Run_Duration_VARCHAR,
sysjobhistory.run_status AS Run_Status
FROM msdb.dbo.sysjobhistory
WHERE sysjobhistory.instance_id NOT IN
(SELECT fact_step_job_run_time.Sql_Agent_Job_Run_Instance_Id FROM dbo.fact_step_job_run_time)
AND sysjobhistory.step_id <> 0)
INSERT INTO dbo.fact_step_job_run_time
(Sql_Agent_Job_Run_Instance_Id, Sql_Agent_Job_Id, Sql_Agent_Job_Step_Id, Job_Step_Start_Datetime, Job_Step_Duration_seconds, Job_Step_Status)
SELECT
CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Run_Instance_Id,
CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Id,
CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Step_Id,
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 5, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 7, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 1, 4) AS DATETIME) +
CAST(STUFF(STUFF(CTE_NORMALIZE_DATETIME_DATA.Run_Time_VARCHAR, 5, 0, ':'), 3, 0, ':') AS DATETIME) AS Job_Step_Start_Datetime,
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 1, 2) AS INT) * 3600 +
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 3, 2) AS INT) * 60 +
CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 5, 2) AS INT) AS Job_Step_Duration_seconds,
CASE CTE_NORMALIZE_DATETIME_DATA.Run_Status
WHEN 0 THEN 'Failure'
WHEN 1 THEN 'Success'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Canceled'
ELSE 'Unknown'
END AS Job_Step_Status
FROM CTE_NORMALIZE_DATETIME_DATA;
This final segment of TSQL is almost identical to the previous job completion metrics collection script, except here we gather all rows in which the step_id is greater than zero. This intentionally omits overall job duration metrics and only includes individual step completion. Some notes on job step data:
TSQL的最后一部分与先前的工作完成指标收集脚本几乎相同,除了这里我们收集step_id大于零的所有行。 这有意省略了总体工时指标,仅包括单个步骤的完成情况。 关于作业步骤数据的一些注意事项:
- Step names and details are not included. If this is something you’d like to collect & save, they are easy to add. 不包括步骤名称和详细信息。 如果您要收集并保存这些内容,则很容易添加它们。
- If a job fails and exits before all steps complete, then any subsequent steps will not appear in the results for that execution as the job never actually reached them in the step list. In other words, if a step never executes, it will not be represented in this data. 如果作业失败并在所有步骤完成之前退出,那么后续执行的任何步骤都不会出现在该执行结果中,因为该作业从未真正到达步骤列表中。 换句话说,如果某个步骤从不执行,则该步骤将不会在该数据中表示。
-
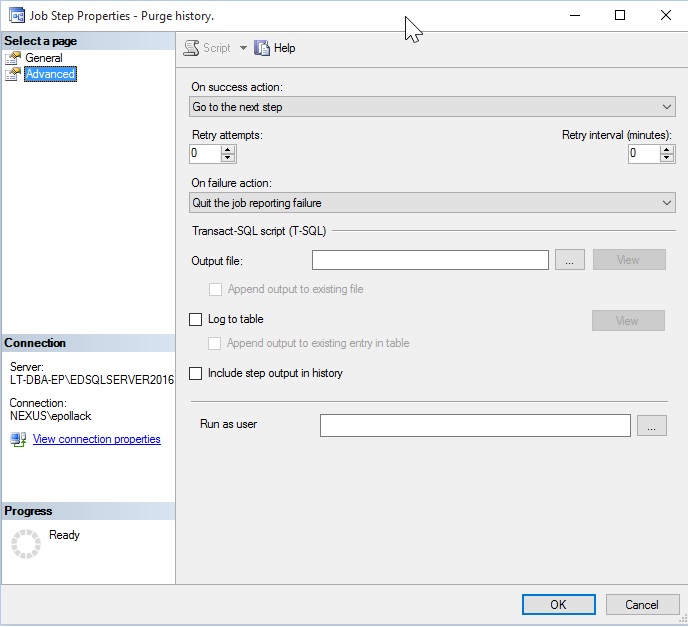
“On failure action” can be adjusted to continue through the job and post success, later on, assuming underlying issues are resolved or are deemed unimportant by this branching logic.
可以调整“失败时采取的措施”以继续完成工作并发布成功,此后,假设基础问题已解决或被该分支逻辑认为不重要,则可以对其进行调整。
At this point, we have a complete script that can be executed anytime in order to collect job execution statistics. All of the underlying work can be broken into five distinct sections: one for each table. From here, we need to figure out what to do with this data in order to make the best use of it!
至此,我们有了一个完整的脚本,可以随时执行以收集作业执行统计信息。 所有基础工作都可以分为五个不同的部分:每个表一个。 从这里开始,我们需要弄清楚该数据的处理方式,以便最好地利用它!
清理 (Cleanup)
As with any data collection process, we want to clean up or archive old data to ensure that we are not storing data so old that it has become irrelevant and overly space-consuming. Only two tables contain data that can accumulate heavily over time: Fact_Job_Run_Time and: Fact_Job_Step_Run_Time. Cleaning up data from these tables is as simple as choosing a cutoff period of some sort and enforcing it, either in the job that collects this data or in a more generalized process elsewhere on your server.
与任何数据收集过程一样,我们希望清理或存档旧数据,以确保我们不会存储太旧的数据,以至于它变得无关紧要且占用过多空间。 只有两个表包含随时间推移可能大量积累的数据: Fact_Job_Run_Time和: Fact_Job_Step_Run_Time 。 从这些表中清除数据非常简单,只需在收集数据的作业中或在服务器上其他位置更通用的过程中选择某种截止时间并强制执行。
The following TSQL removes all job execution data older than a year:
以下TSQL删除所有早于一年的作业执行数据:
DELETE fact_job_run_time
FROM dbo.fact_job_run_time
WHERE fact_job_run_time.Job_Start_Datetime < DATEADD(YEAR, -1, CURRENT_TIMESTAMP);
DELETE fact_step_job_run_time
FROM dbo.fact_step_job_run_time
WHERE fact_step_job_run_time.Job_Step_Start_Datetime < DATEADD(YEAR, -1, CURRENT_TIMESTAMP);
Alternatively, we could limit data storage by the number of rows per job, per job step, or via any other convention that matches your business needs. If this data is to be crunched into more generic metrics per server, such as average duration per day or number of failures per month, then it may be possible to hang onto far less than a year of detail data.
另外,我们可以通过每个作业,每个作业步骤的行数或通过其他符合您业务需求的约定来限制数据存储。 如果要将这些数据整理成每台服务器的更通用的指标,例如每天的平均持续时间或每月的故障数,则有可能会停留在不到一年的详细数据上。
It is important to distinguish between detail data, as stored in these tables and reporting data, that can be gleaned from these tables or stored elsewhere as needed. We’ll discuss reporting later in this article in order to create some examples of what we can do with job performance metrics.
重要的是要区分存储在这些表中的详细数据和报告数据,这些数据可以从这些表中收集或根据需要存储在其他位置。 我们将在本文后面讨论报告,以创建一些示例,说明如何使用工作绩效指标。
客制化 (Customization)
A process such as this begs for customization. Some of the tables shown here, such as job-schedule pairings or job step runtimes may or may not be important to you. There may be columns, such as job status, that you do not need. Alternatively, MSDB may have some columns in its tables that I did not include that may be useful to you.
诸如此类的过程要求定制。 此处显示的某些表,例如作业计划表配对或作业步骤运行时,可能对您很重要,也可能不重要。 可能不需要某些列,例如作业状态。 另外,MSDB的表中可能有一些我没有包括的列,这些列可能对您有用。
The collection procedures and reporting scripts created here are very flexible—feel free to customize as you see fit. The general process is the same:
此处创建的收集过程和报告脚本非常灵活-可以根据需要随意进行自定义。 一般过程是相同的:
- Collect detailed job execution data. 收集详细的作业执行数据。
- Store collected data in separate fact tables. 将收集的数据存储在单独的事实表中。
- Create further aggregation/number crunching as needed and store results in new tables. 根据需要创建进一步的汇总/数字运算,并将结果存储在新表中。
- Generate reports off of the crunched data in order to satisfy trending/monitoring needs. 根据处理过的数据生成报告,以满足趋势/监控需求。
I have provided many ideas for customization throughout this article. If you find any creative or interesting uses for this data that are not outlined here, feel free to contact me and let me know! I enjoy seeing how processes such as this are changed over time to solve new, complex, or unexpected challenges.
在本文中,我提供了许多用于自定义的想法。 如果您发现此处未概述此数据的任何创造性或有趣用途,请随时与我联系并让我知道! 我很高兴看到随着时间的流逝,诸如此类的流程如何变化,以解决新的,复杂的或意料之外的挑战。
结论 (Conclusion)
Collecting, aggregating, and reporting on job performance metrics is not something that we often consider when planning how to monitor our SQL Servers. Despite it being less obvious than CPU, memory, or contention metrics, these stats can be critical in an environment where SQL Server Agent jobs are relied upon in order to know when jobs run far too long or to see the trending of performance over time.
在计划如何监视SQL Server时,我们通常不会考虑收集,汇总和报告作业绩效指标。 尽管这些统计信息不如CPU,内存或争用指标那么明显,但是在依赖SQL Server Agent作业以了解作业何时运行时间过长或查看性能随时间变化趋势的环境中,这些统计数据可能至关重要。
Consider what metrics are needed in your environment, customize to get those details, and make the best use of the data collected. This sort of information allows us to identify and solve performance problems before they result in failures or timeouts, and can likewise avoid the emergencies and dreaded late-night wake-up calls that often follow.
考虑您的环境中需要哪些指标,进行自定义以获取这些详细信息,并充分利用收集到的数据。 这类信息使我们能够在性能问题导致失败或超时之前识别并解决性能问题,并且同样可以避免经常发生的紧急情况和令人恐惧的深夜唤醒呼叫。
翻译自: https://www.sqlshack.com/tracking-job-performance-sql-server/
sql server 跟踪















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









