





索引sql server
In my previous article, SQL Server Table Structure Overview, we described, in detail, the difference between Heap table structure, in which the data pages are not sorted in any ordering criteria and the pages itself are not sorted or linked between each other, and Clustered tables, in which the data is sorted within the data pages and the pages will be also linked in a double linked list, based on the index key. In this article, we will go through the structure of the SQL Server index, itself.
在我的上一篇文章《 SQL Server表结构概述》中 ,我们详细描述了堆表结构之间的区别,在堆表结构中,数据页未按任何排序条件进行排序,而页面本身未进行排序或链接,并且聚簇表,其中数据在数据页内排序,并且这些页还将基于索引键链接在双链表中。 在本文中,我们将介绍SQL Server索引本身的结构。
SQL Server index is considered as one of the most important factors of the performance tuning process, that is created to speed up the data retrieval and the query processing operations from a database table or view, by providing swift access to the database table rows, without the need to scan all the table’s data, in order to retrieve the requested data. You can imagine the table index as a book’s index that allows you to find the requested information very fast within your book, rather than reading all the book pages in order to find a specific subject. An example of a book’s index that locates the page where you can find each word is shown below:
SQL Server索引被认为是性能调整过程中最重要的因素之一,它是通过提供对数据库表行的快速访问而创建的,以加快从数据库表或视图的数据检索和查询处理操作的速度,而无需需要扫描表的所有数据,以便检索请求的数据。 您可以将表索引想象为一本书的索引,它使您可以在书中快速找到所需的信息,而不是为了查找特定主题而阅读所有书页。 下面显示了一个书的索引示例,该索引可找到您可以找到每个单词的页面:

Assume that you have a query that retrieves list of employees’ information from the Employees table based on the EmployeeID column. Without having an index on the EmployeeID column, SQL Server will scan all the table rows to retrieve the requested data. If you create an index on the EmployeeID column on the Employees table, and perform a search based on the EmployeeID value, the SQL Server Engine will seek for the requested EmployeeID values in the index and use that index to locate the rest of the employees’ information from the related rows in the source table, providing a significant performance enhancement and reducing the effort required to locate the requested data, as shown in the figure below:
假设您有一个查询,该查询基于EmployeeID列从Employees表中检索雇员的信息列表。 如果在EmployeeID列上没有索引,SQL Server将扫描所有表行以检索请求的数据。 如果您在Employees表的EmployeeID列上创建索引,并基于EmployeeID值执行搜索,则SQL Server引擎将在索引中寻找请求的EmployeeID值,并使用该索引来查找其余员工的来自源表中相关行的信息,从而显着提高了性能并减少了查找所请求数据所需的工作量,如下图所示:
The rapid search capabilities provided by the index is achieved due to the fact that, the SQL Server index is created using the shape of B-Tree structure, that made up of 8K pages, with each page in that structure is called an index node. The B-Tree structure provides the SQL Server Engine with a fast way to move through the table rows based on index key, that decides to navigate let or right, to retrieve the requested values directly, without scanning all the underlying table rows. You can imagine the performance degradation that may occur due to scanning large database table.
索引提供的快速搜索功能是由于以下事实而实现的:SQL Server索引是使用B树结构(由8K页组成)的形状创建的,该结构中的每一页都称为索引节点。 B-Tree结构为SQL Server Engine提供了一种快速的方法,该方法可以基于索引键在表行中移动,该索引键决定导航let或right,直接检索请求的值,而无需扫描所有基础表行。 您可以想象由于扫描大型数据库表而导致的性能下降。
It is clear from the Index B-Tree Structure figure below, that the B-Tree structure of the index consists of three main levels: the Root Level, the top node that contains a single index page, form which SQL Server starts its data search, the Leaf Level, the bottom level of nodes that contains the data pages we are looking for, with the number of leaf pages depends on the amount of data stored in the index, and finally the Intermediate Level, one or multiple levels between the root and the leaf levels that holds the index key values and pointers to the next intermediate level pages or the leaf data pages. The number of intermediate levels depends on the amount of data stored in the index.
从下面的索引B树结构图中可以清楚地看到, 索引的B树结构包含三个主要级别: 根级别 ,包含单个索引页的顶部节点,SQL Server开始其数据搜索的形式, 叶子级别 ,包含我们要查找的数据页面的节点的最低级别,叶子页面的数量取决于索引中存储的数据量,最后取决于中间级别 ,即根之间的一个或多个级别叶子级包含索引键值和指向下一个中间级别页或叶子数据页的指针。 中间级别的数量取决于索引中存储的数据量。
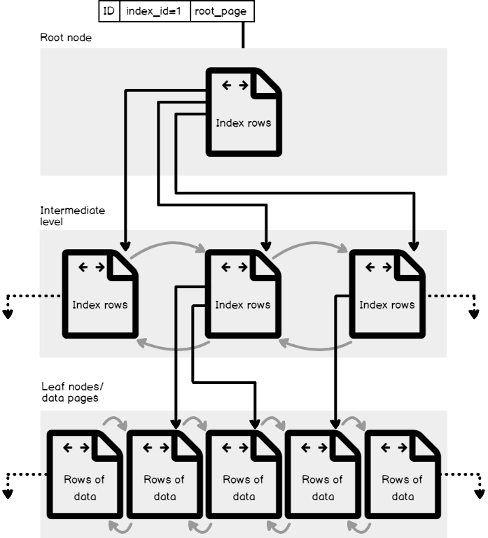
Assume that we create an index in one of our database tables on the ID column. When you run a query to search for specific rows from that table, based on the ID values of these rows, the SQL Server Engine will start navigating from the root node, to determine which page to reference in the top intermediate level, then continue down through the intermediate nodes to identify the address of the next intermediate node, until it reaches the target leaf node that contains the requested data row or pointer to that row in the main table, depends on the type of the index.
假设我们在ID列的数据库表之一中创建索引。 当您运行查询以从该表中搜索特定行时,基于这些行的ID值,SQL Server引擎将开始从根节点导航,以确定要在最高中间级别引用的页面,然后继续向下通过中间节点来标识下一个中间节点的地址,直到它到达目标叶节点为止,该目标叶节点包含所请求的数据行或指向主表中该行的指针,具体取决于索引的类型。
For example, if you issue a query that searches for the row with ID value equal to 57, the SQL Server Engine will start searching in the root node of the index, where it will find that the ID value of 57 exists in the second intermediate node. In the second intermediate node, it will find also that the ID value of 57 is located in the leaf node number 6, where the record with ID value equal to 57, or a pointer to that row will be found on the leaf node, as shown below:
例如,如果您发出查询以搜索ID值等于57的行,则SQL Server引擎将开始在索引的根节点中搜索,在该节点中它会发现ID值57在第二个中间节点中节点。 在第二个中间节点中,还将发现ID值57位于叶节点编号6中,其中ID值等于57的记录或指向该行的指针将在叶节点上找到,例如如下图所示:
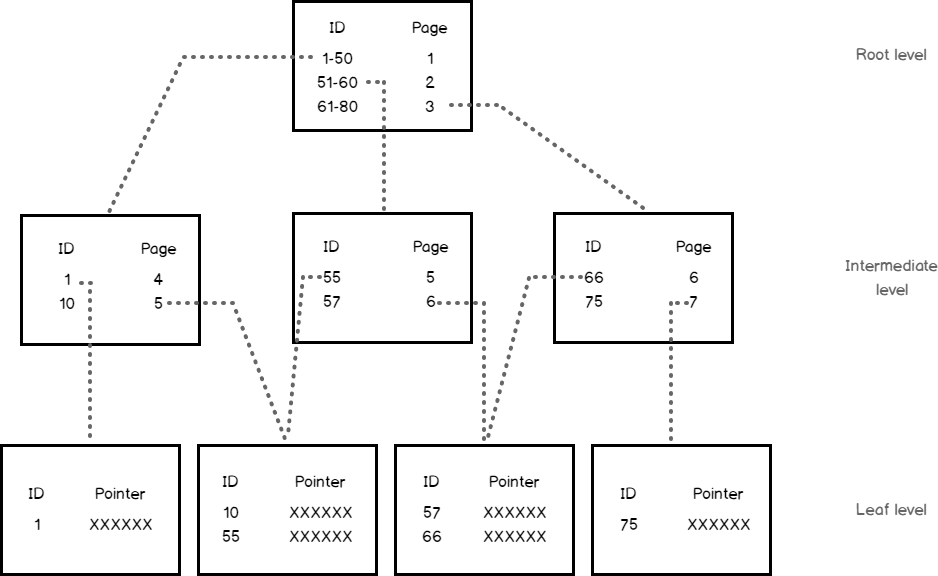
SQL Server indexes can have large number of nodes in each level. This helps in improving the efficiency of the created index by avoiding the need for excessive depth within the index. The index depth is the number of levels from the index root node to the leaf nodes. An index that is quite deep will suffer from performance degradation problem. In contrast, an index with large number of nodes in each level can produce a very flat index structure. An index with only 3 to 4 levels is very common.
SQL Server索引在每个级别中可以具有大量节点。 通过避免在索引内增加深度,这有助于提高创建索引的效率。 索引深度是从索引根节点到叶节点的级别数。 一个非常深的索引将遭受性能下降的问题。 相反,在每个级别具有大量节点的索引可以产生非常平坦的索引结构。 只有3到4级的索引非常常见。
In addition to the index depth, there are two other important index measurements that control the index effectiveness. The first property is the index density which is a measure of the lack of uniqueness of the data in a table. A dense column is one that has a high number of duplicates. The second property is the index selectivity, which is a measure of how many rows scanned compared to the total number of rows. An index with high selectivity means a small number of rows scanned when related to the total number of rows.
除索引深度外,还有两个其他重要的索引度量值可控制索引有效性。 第一个属性是索引密度 ,它衡量表中数据缺乏唯一性。 密集列是具有大量重复项的列。 第二个属性是索引选择性 ,它是与总行数相比扫描的行数的度量。 具有高选择性的索引意味着与总行数相关时扫描的行数很少。
SQL Server provides us with two main types of indexes, the Clustered index that stores the actual data rows of the table at the leaf level of the index, in addition to controlling the sorting criteria of the data within the data pages and the order of the pages itself, based on the clustered index key. This is the reason behind the ability to create only one clustered index on each table. The Non-clustered index contains only the values of the index key columns with a pointer to the actual data rows stored in the clustered index or the underlying table, without controlling the order of the data within the pages and the order of the index pages. SQL Server allows you to create up to 999 non-clustered indexes on each table. Recall from the previous article that the table with no clustered index is called Heap table, with no criteria that is controlling the data and pages order, and the table that is sorted using a clustered index is called a Clustered table. A clustered index will be created automatically when you define a Primary Key constraint in the table, if these is no predefined clustered index on that table.
SQL Server为我们提供了两种主要的索引类型,即聚集索引 ,它除了控制数据页内数据的排序标准和排序顺序外,还可以在索引的叶级存储表的实际数据行。页面本身,基于聚簇索引键。 这就是在每个表上只能创建一个聚集索引的原因。 非聚集索引仅包含索引键列的值,并且具有指向存储在聚集索引或基础表中的实际数据行的指针,而无需控制页面内数据的顺序和索引页的顺序。 SQL Server允许您在每个表上最多创建999个非聚集索引。 回顾上一篇文章,没有聚簇索引的表称为堆表,没有控制数据和页面顺序的条件,而使用聚簇索引排序的表称为聚簇表。 如果您在表中定义主键约束,则在该表上没有预定义的聚集索引时,将自动创建聚集索引。
There are other types of SQL Server indexes, such as the Unique index that enforces the column values uniqueness and created automatically when defining a unique constraint, the Composite index that contains more than one key column and the Covering index that contains all columns requested by a specific query. We will go through all these types in details in the coming articles of this series.
还有其他类型SQL Server索引,例如, Unique索引用于强制列值唯一性,并在定义唯一性约束时自动创建; Composite索引包含多个键列,而Covering索引包含一个列所请求的所有列。具体查询。 我们将在本系列的后续文章中详细介绍所有这些类型。
For this point, you should have a full understanding about the table structure, the index structure and the general benefits of adding the indexes. Before going through the index design, usage and improvement, you have to take into consideration that the index is a double-edged sword, where a well-designed index will enhance the performance of your system and speed up the data retrieval process. On the other hand, a badly-designed index will cause performance degradation on your system and will cost you extra disk space and delay in the data insertion and modification operations. It is better always to test the performance of the system before and after adding the index on the development environment, before adding it to the production environment.
为此,您应该对表结构,索引结构以及添加索引的一般好处有完整的了解。 在进行索引的设计,使用和改进之前,您必须考虑到索引是一把双刃剑 ,精心设计的索引将增强系统的性能并加快数据检索过程。 另一方面,索引设计不当会导致系统性能下降,并浪费额外的磁盘空间,并会延迟数据插入和修改操作。 最好始终在将索引添加到开发环境之前和之后将其添加到生产环境中之前测试系统的性能。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/sql-server-index-structure-and-concepts/
索引sql server















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









