





In the previous articles of this series, SQL Server Execution Plans overview , SQL Server Execution Plans types and How to Analyze SQL Execution Plan Graphical Components, we discussed the steps that are performed by the SQL Server Relational Engine to generate the Execution Plan of a submitted query and the steps performed by the SQL Server Storage Engine to retrieve the requested data or perform the requested modification operation.
在本系列的前几篇文章中, SQL Server执行计划概述 , SQL Server执行计划类型以及如何分析SQL执行计划图形组件 ,我们讨论了SQL Server关系引擎执行的步骤,以生成提交的执行计划。查询以及SQL Server存储引擎执行的步骤以检索请求的数据或执行请求的修改操作。
In addition, we clarified the different types and formats of the SQL Server Query Execution Plans that can be used for queries performance troubleshooting purposes. Finally, we discussed the graphical query plan components and how we can analyze it. In this article, we will go through the first set of SQL Query Plans operators.
此外,我们阐明了可用于查询性能故障排除目的SQL Server查询执行计划的不同类型和格式。 最后,我们讨论了图形查询计划组件以及如何对其进行分析。 在本文中,我们将介绍第一组SQL查询计划运算符。
Before starting with the Query Execution Plan operators, we will create a new simple table and fill it with testing data, using the T-SQL script below:
在开始使用Query Execution Plan运算符之前,我们将使用下面的T-SQL脚本创建一个新的简单表并将测试数据填充其中:
CREATE TABLE ExPlanOperator
( ID INT IDENTITY (1,1),
First_Name VARCHAR(50),
Last_name VARCHAR(50),
Address VARCHAR(MAX)
)
GO
INSERT INTO ExPlanOperator VALUES ('AA','BB','CC')
GO 1000
INSERT INTO ExPlanOperator VALUES ('DD','EE','FF')
GO 1000
SQL Server表扫描运算符 (SQL Server Table Scan Operator)
The previously created ExPlanOperator the table is a heap table, a table in which the data rows are not stored in any particular order within each data page, due to the fact that there is no Clustered index created over that table.
先前创建的ExPlanOperator表是堆表,该表中的数据行未按任何特定顺序存储在每个数据页中,原因是在该表上没有创建聚簇索引。
See the article SQL Server table structure overview for more details about the structure of the SQL Server tables.
请参阅文章SQL Server表结构概述,以获取有关SQL Server表结构的更多详细信息。
So that, in order to return the result of any query on that table, the SQL Server Engine will scan all the entire table row by row using the Table Scan operator.
因此,为了返回对该表的任何查询的结果,SQL Server引擎将使用表扫描运算符逐行扫描所有整个表。
Assume that we run the below T-SQL statement that retrieves all the records from the ExPlanOperator test table after including the Actual Execution Plan of the query to see how it will behave. You will see from the generated SQL Query Execution plan that the SQL Server Engine will scan all the entire table rows, using the Table Scan operator, in order to retrieve the requested data, as shown below:
假定我们运行下面的T-SQL语句,该语句在包括查询的实际执行计划以查看其行为后,从ExPlanOperator测试表中检索所有记录。 从生成SQL查询执行计划中,您将看到SQL Server Engine将使用表扫描运算符扫描所有表的所有行,以检索请求的数据,如下所示:
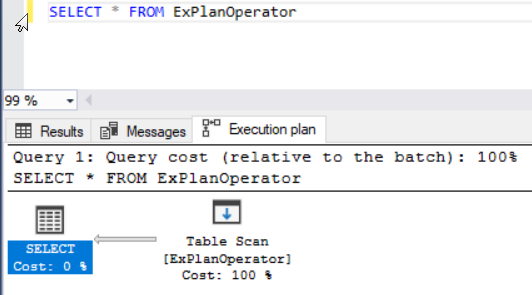
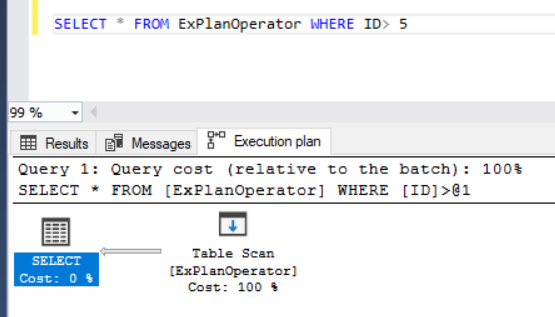
The SQL Server Engine will behave in the same way when we try to get a specific set of records by adding the WHERE clause. Where it will scan all the entire table rows using the Table Scan operator again, as there is no index created on that table to assist with the data retrieval, as shown below:
当我们尝试通过添加WHERE子句来获取一组特定的记录时,SQL Server引擎的行为将相同。 它将再次使用“表扫描”操作器扫描所有表的所有行,因为在该表上没有创建索引来辅助数据检索,如下所示:
If we create a Non-Clustered index on the ID column on the testing table, using the CREATE INDEX T-SQL statement below:
如果我们在测试表的ID列上创建非聚集索引,请使用以下CREATE INDEX T-SQL语句:
CREATE INDEX IX_ExPlanOperator_ID ON ExPlanOperator (ID)
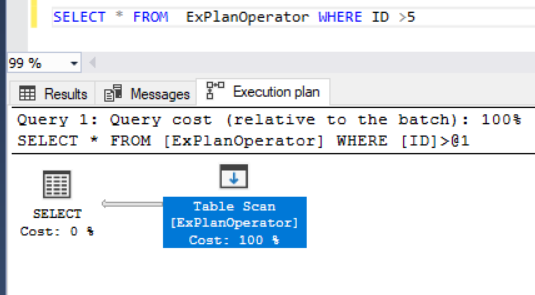
Then run the same SELECT statement to retrieve a specific set of IDs. You will see that the SQL Server Engine prefers to scan the entire table, row by row rather than using the created index. There are many reasons for such behavior. For example, the index is not useful, the table contains small number of rows or the query will return most of the table rows, as shown below:
然后运行相同的SELECT语句以检索一组特定的ID。 您将看到,SQL Server Engine倾向于逐行扫描整个表,而不是使用创建的索引。 出现这种现象的原因很多。 例如,索引没有用,表包含的行数少,否则查询将返回表的大部分行,如下所示:
SQL Server群集索引扫描运算符 (SQL Server Clustered Index Scan Operator)
When you create a Clustered index on the table, the table will be converted from a Heap table to a Clustered table. A clustered table is a table that has a predefined clustered index on one column or multiple columns of the table that defines the storing order of the rows within the data pages and the order of the pages within the table, based on the clustered index key.
当您在表上创建聚簇索引时,该表将从堆表转换为聚簇表。 聚集表是一种在表的一列或多列上具有预定义聚集索引的表,该索引基于聚集索引键定义数据页内行的存储顺序和表内页的顺序。
For more information about the Clustered table structure, see SQL Server table structure overview. And for more information about the Clustered index, see Designing effective SQL Server clustered indexes.
有关群集表结构的更多信息,请参见SQL Server表结构概述 。 有关聚集索引的更多信息,请参见设计有效SQL Server聚集索引 。
Let us drop the Non-Clustered index that we created previously on the ExPlanOperator table and replace it with a Clustered index on the ID column on the ExPlanOperator table, using the T-SQL script below:
让我们删除先前在ExPlanOperator表上创建的非聚集索引,并使用下面的T-SQL脚本将其替换为ExPlanOperator表的ID列上的聚集索引。
DROP INDEX IX_ExPlanOperator_ID on ExPlanOperator
CREATE CLUSTERED INDEX IX_ExPlanOperator_ID ON ExPlanOperator (ID)
If we run the same SELECT query that retrieves all rows from our testing table, and include the Actual SQL Query Execution plan of the query, you will see that the Table Scan operator will be replaced by the Clustered Index Scan operator, with the same arrow thickness as the one in the case of the Table Scan, as shown below:
如果运行与从测试表中检索所有行相同的SELECT查询,并包括查询的“实际SQL查询执行”计划,您将看到Table Scan操作符将被Clustered Index Scan操作符替换,并带有相同的箭头厚度为表扫描的厚度,如下所示:
From the previous SQL Query Execution plan, the SQL Server Engine decides to use the Clustered Index Scan operator, although it will traverse all the index rows similar to how the Table Scan operator behaves. This is due to the fact that, the Clustered Index can be considered as a sorted replacement for the underlying table that stores all the table data at the lowest level of the index, also known as the leaf, in addition to the index key. If there is no useful Non-Clustered index due to out of date statistics, or the query will return all or most of the table rows, the SQL Server Engine will decide that using the Clustered Index Scan operator to scan all the Clustered index rows is faster than using the keys provided by the index.
根据以前SQL查询执行计划,SQL Server引擎决定使用群集索引扫描运算符,尽管它会遍历所有索引行,类似于表扫描运算符的行为。 这是由于以下事实:“聚集索引”可以被视为基础表的排序替换,该基础表除了索引键之外,还以索引的最低级别(也称为叶子)存储所有表数据。 如果由于过期的统计信息而没有有用的非聚集索引,或者查询将返回所有或大多数表行,则SQL Server引擎将决定使用“聚集索引扫描”操作符扫描所有聚集索引行是比使用索引提供的键更快。
SQL Server群集索引查找运算符 (SQL Server Clustered Index Seek Operator)
If the previous SELECT query is modified to be more efficient by adding a data filtration statement in the WHERE clause, that limits the number of rows returned from the table, the SQL Server Query Optimizer decides to use a very fast way to retrieve the data using the Clustered Index Seek operator, as shown below:
如果通过在WHERE子句中添加数据过滤语句来修改前一个SELECT查询以提高效率,从而限制了从表返回的行数,则SQL Server Query Optimizer决定使用一种非常快速的方法来检索数据,方法是聚簇索引查找运算符,如下所示:
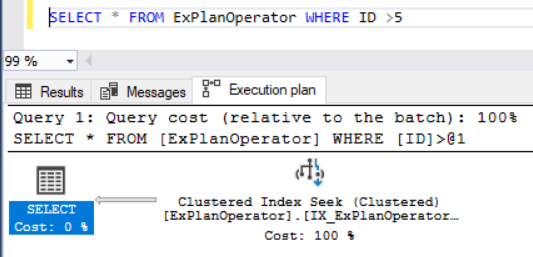
Rather than traversing all the table rows, the SQL Server Query Optimizer will locate the appropriate Clustered index and navigate it to retrieve the required rows by providing the SQL Server Storage Engine with the instructions to identify the required rows based on the key values of the selected index. In addition to processing the data quickly to retrieve the needed rows using the Clustered Index Seek operator, no extra steps required to retrieve the rest of the columns, as a full sorted copy of the table is stored in the leaf level nodes of the Clustered index.
SQL Server查询优化器将遍历表中的所有行,而不是遍历所有表行,而是通过向SQL Server Storage Engine提供基于选定键的值来标识所需行的指令,来定位适当的聚集索引并对其进行导航以检索所需的行。指数。 除了使用“聚簇索引查找”运算符快速处理数据以检索所需的行外,检索表的其余部分还不需要额外的步骤,因为表的完整排序副本存储在聚簇索引的叶级节点中。
SQL Server非聚集索引查找运算符 (SQL Server Non-clustered Index Seek Operator)
When the SQL Server Query Optimizer finds that all the data that is requested by the query can be provided by an available index, it will perform a seek against that Non-Clustered index, using the Index Seek operator.
当SQL Server查询优化器发现可用的索引可以提供查询所请求的所有数据时,它将使用Index Seek运算符针对该非聚集索引执行搜索。
For more information about the Non-Clustered index, see Designing effective SQL Server clustered indexes.
有关非聚集索引的更多信息,请参见设计有效SQL Server聚集索引 。
Assume that we have created a Non-Clustered index on the First_Name column of the ExPlanOperator testing table, using the CREATE INDEX T-SQL Command below:
假设我们已经使用以下CREATE INDEX T-SQL命令在ExPlanOperator测试表的First_Name列上创建了非聚集索引:
CREATE INDEX IX_ExPlanOperator_FirstName on ExPlanOperator(First_Name)
Then run the below SELECT statement that retrieves the First_Name column, after including the Actual Execution Plan of the query, as below:
然后,在包含查询的实际执行计划之后,运行下面的SELECT语句以检索First_Name列,如下所示:
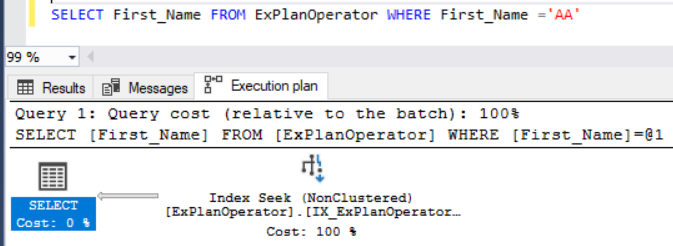
You will see from the SQL Query Execution plan that, the SQL Server Query Optimizer found that the created index contains all the data that is requested by the submitted query and that the fastest way to retrieve this data is seeking that Non-Clustered index. Recall that the Non-clustered index stores only the index key values and pointers to the rest of columns. If the SQL Server Query Optimizer is not able to find all the requested data in that index, it will look up for the additional data in the Clustered index, in the case of Clustered table, or in the underlying table, in the case of the Heap tables, affecting the query performance due to the additional I/O operations performed during the look up process, as we will see later in this series.
您将从SQL查询执行计划中看到,SQL Server查询优化器发现所创建的索引包含提交的查询所请求的所有数据,并且检索此数据的最快方法是查找该非聚集索引。 回想一下,非聚集索引仅存储索引键值和指向其余列的指针。 如果SQL Server Query Optimizer无法在该索引中找到所有请求的数据,则对于簇表,如果在簇表中,则将在簇索引中查找其他数据;对于簇表,则在基础表中查找其他数据。堆表,由于在查找过程中执行了额外的I / O操作,因此影响了查询性能,这将在本系列后面的内容中看到。
In the next article of this series, we will discuss the second set of the SQL Server Query Execution Plan operators. Stay tuned!
在本系列的下一篇文章中,我们将讨论第二组SQL Server查询执行计划运算符。 敬请关注!
目录 (Table of contents)
翻译自: https://www.sqlshack.com/sql-server-execution-plan-operators-part-1/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









