





错误处理概述 (Error handling overview)
Error handling in SQL Server gives us control over the Transact-SQL code. For example, when things go wrong, we get a chance to do something about it and possibly make it right again. SQL Server error handling can be as simple as just logging that something happened, or it could be us trying to fix an error. It can even be translating the error in SQL language because we all know how technical SQL Server error messages could get making no sense and hard to understand. Luckily, we have a chance to translate those messages into something more meaningful to pass on to the users, developers, etc.
SQL Server中的错误处理使我们可以控制Transact-SQL代码。 例如,当出现问题时,我们就有机会对此做些事情,甚至有可能再次纠正。 SQL Server错误处理就像记录某些事情一样简单,也可以是我们尝试修复错误。 它甚至可以用SQL语言来翻译错误,因为我们都知道技术性SQL Server错误消息可能变得毫无意义且难以理解。 幸运的是,我们有机会将这些消息转换为更有意义的内容,以传递给用户,开发人员等。
In this article, we’ll take a closer look at the TRY… CATCH statement: the syntax, how it looks, how it works and what can be done when an error occurs. Furthermore, the method will be explained in a SQL Server case using a group of T-SQL statements/blocks, which is basically SQL Server way of handling errors. This is a very simple yet structured way of doing it and once you get the hang of it, it can be quite helpful in many cases.
在本文中,我们将仔细研究TRY…CATCH语句:语法,外观,工作方式以及发生错误时可以执行的操作。 此外,将在使用一组T-SQL语句/块SQL Server情况下解释该方法,这基本上是SQL Server处理错误的方式。 这是一种非常简单但结构化的方法,一旦掌握了它,在很多情况下它就会很有帮助。
On top of that, there is a RAISERROR function that can be used to generate our own custom error messages which is a great way to translate confusing error messages into something a little bit more meaningful that people would understand.
最重要的是,有一个RAISERROR函数可用于生成我们自己的自定义错误消息,这是一种将混乱的错误消息转换为人们会理解的更有意义的东西的好方法。
使用TRY…CATCH处理错误
(Handling errors using TRY…CATCH
)
Here’s how the syntax looks like. It’s pretty simple to get the hang of. We have two blocks of code:
语法如下所示。 掌握要点很简单。 我们有两个代码块:
BEGIN TRY
--code to try
END TRY
BEGIN CATCH
--code to run if an error occurs
--is generated in try
END CATCH
Anything between the BEGIN TRY and END TRY is the code that we want to monitor for an error. So, if an error would have happened inside this TRY statement, the control would have immediately get transferred to the CATCH statement and then it would have started executing code line by line.
BEGIN TRY和END TRY之间的任何内容都是我们要监视的错误代码。 因此,如果在该TRY语句内发生错误,则该控件将立即转移到CATCH语句,然后它将开始逐行执行代码。
Now, inside the CATCH statement, we can try to fix the error, report the error or even log the error, so we know when it happened, who did it by logging the username, all the useful stuff. We even have access to some special data only available inside the CATCH statement:
现在,在CATCH语句中,我们可以尝试修复错误,报告错误,甚至记录错误,因此我们知道发生的时间,记录用户名的人员,所有有用的东西。 我们甚至可以访问一些仅在CATCH语句中可用的特殊数据:
- ERROR_NUMBER – Returns the internal number of the error ERROR_NUMBER –返回错误的内部编号
- ERROR_STATE – Returns the information about the source ERROR_STATE –返回有关源的信息
- ERROR_SEVERITY – Returns the information about anything from informational errors to errors user of DBA can fix, etc. ERROR_SEVERITY –返回有关任何信息的信息,从信息错误到DBA用户可以修复的错误等。
- ERROR_LINE – Returns the line number at which an error happened on ERROR_LINE –返回发生错误的行号
- ERROR_PROCEDURE – Returns the name of the stored procedure or function ERROR_PROCEDURE –返回存储过程或函数的名称
- ERROR_MESSAGE – Returns the most essential information and that is the message text of the error ERROR_MESSAGE –返回最基本的信息,即错误的消息文本
That’s all that is needed when it comes to SQL Server error handling. Everything can be done with a simple TRY and CATCH statement and the only part when it can be tricky is when we’re dealing with transactions. Why? Because if there’s a BEGIN TRANSACTION, it always must end with a COMMIT or ROLLBACK transaction. The problem is if an error occurs after we begin but before we commit or rollback. In this particular case, there is a special function that can be used in the CATCH statement that allows checking whether a transaction is in a committable state or not, which then allows us to make a decision to rollback or to commit it.
当涉及到SQL Server错误处理时,仅此而已。 一切都可以通过一个简单的TRY和CATCH语句完成,而棘手的唯一部分是我们处理事务时。 为什么? 因为如果有BEGIN TRANSACTION,它总是必须以COMMIT或ROLLBACK事务结尾。 问题是在开始之后但在提交或回滚之前是否发生错误。 在这种特殊情况下,可以在CATCH语句中使用一个特殊功能,该功能允许检查事务是否处于可提交状态,然后允许我们做出回滚或提交决定。
Let’s head over to SQL Server Management Studio (SSMS) and start with basics of how to handle SQL Server errors. The AdventureWorks 2014 sample database is used throughout the article. The script below is as simple as it gets:
让我们转到SQL Server Management Studio (SSMS),并从如何处理SQL Server错误的基础开始。 整篇文章都使用AdventureWorks 2014示例数据库。 下面的脚本非常简单:
USE AdventureWorks2014
GO
-- Basic example of TRY...CATCH
BEGIN TRY
-- Generate a divide-by-zero error
SELECT
1 / 0 AS Error;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_STATE() AS ErrorState,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
END CATCH;
GO
This is an example of how it looks and how it works. The only thing we’re doing in the BEGIN TRY is dividing 1 by 0, which, of course, will cause an error. So, as soon as that block of code is hit, it’s going to transfer control into the CATCH block and then it’s going to select all of the properties using the built-in functions that we mentioned earlier. If we execute the script from above, this is what we get:
这是外观和工作方式的一个示例。 我们在BEGIN TRY中唯一要做的就是将1除以0,这当然会导致错误。 因此,一旦该代码块被命中,它将把控制权转移到CATCH块中,然后将使用我们前面提到的内置函数来选择所有属性。 如果我们从上面执行脚本,那么我们将得到:
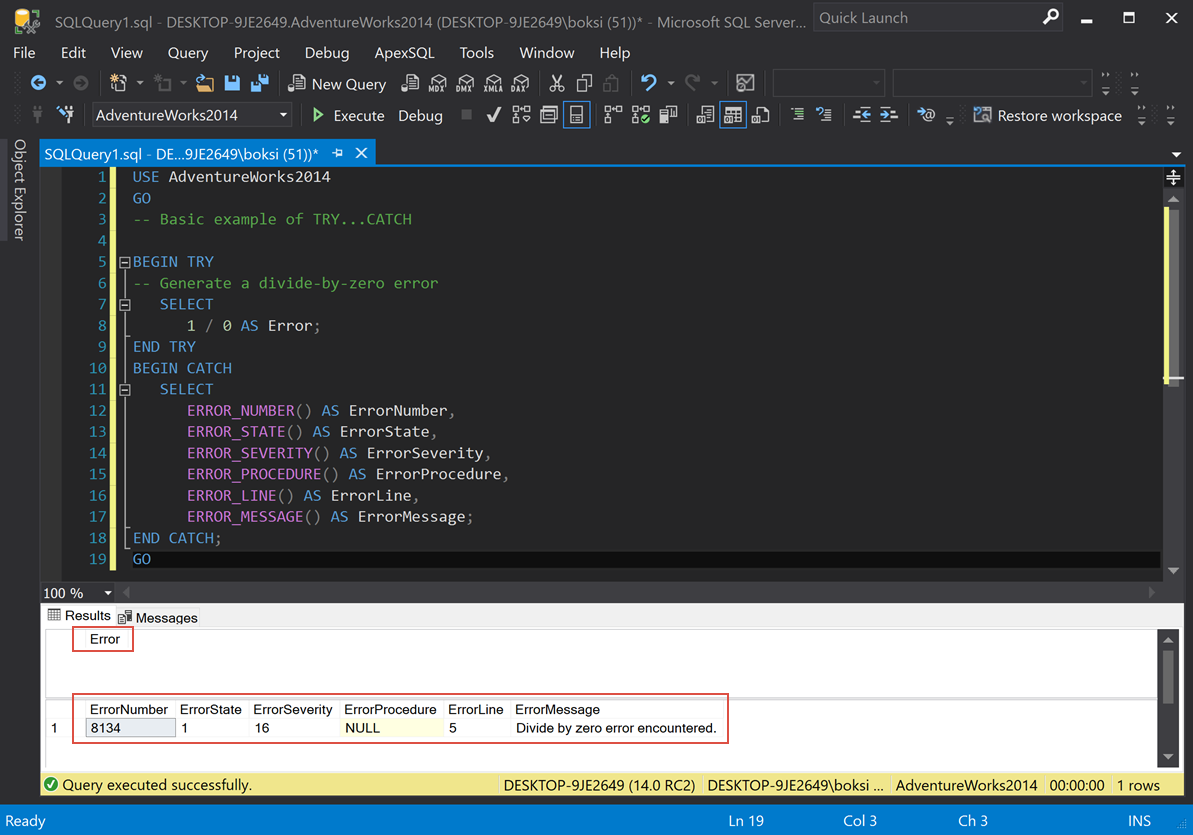
We got two result grids because of two SELECT statements: the first one is 1 divided by 0, which causes the error and the second one is the transferred control that actually gave us some results. From left to right, we got ErrorNumber, ErrorState, ErrorSeverity; there is no procedure in this case (NULL), ErrorLine, and ErrorMessage.
由于有两个SELECT语句,我们得到了两个结果网格:第一个是1除以0,这将导致错误;第二个是实际上已为我们提供一些结果的传递控件。 从左到右,我们得到了ErrorNumber,ErrorState,ErrorSeverity; 在这种情况下,没有过程(NULL),ErrorLine和ErrorMessage。
Now, let’s do something a little more meaningful. It’s a clever idea to track these errors. Things that are error-prone should be captured anyway and, at the very least, logged. You can also put triggers on these logged tables and even set up an email account and get a bit creative in the way of notifying people when an error occurs.
现在,让我们做一些更有意义的事情。 跟踪这些错误是一个聪明的主意。 容易出错的事物无论如何都应该被捕获,至少要记录下来。 您还可以在这些记录的表上放置触发器,甚至可以设置电子邮件帐户,并在出现错误时通知人们有一点创意。
If you’re unfamiliar with database email, check out this article for more information on the emailing system: How to configure database mail in SQL Server
如果您不熟悉数据库电子邮件,请查看本文以获取有关电子邮件系统的更多信息: 如何在SQL Server中配置数据库邮件
The script below creates a table called DB_Errors, which can be used to store tracking data:
下面的脚本创建一个名为DB_Errors的表,该表可用于存储跟踪数据:
-- Table to record errors
CREATE TABLE DB_Errors
(ErrorID INT IDENTITY(1, 1),
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME)
GO
Here we have a simple identity column, followed by username, so we know who generated the error and the rest is simply the exact information from the built-in functions we listed earlier.
在这里,我们有一个简单的标识列,后跟用户名,因此我们知道是谁产生了错误,其余的只是我们前面列出的内置函数的确切信息。
Now, let’s modify a custom stored procedure from the database and put an error handler in there:
现在,让我们从数据库中修改一个自定义存储过程,并在其中放置一个错误处理程序:
ALTER PROCEDURE dbo.AddSale @employeeid INT,
@productid INT,
@quantity SMALLINT,
@saleid UNIQUEIDENTIFIER OUTPUT
AS
SET @saleid = NEWID()
BEGIN TRY
INSERT INTO Sales.Sales
SELECT
@saleid,
@productid,
@employeeid,
@quantity
END TRY
BEGIN CATCH
INSERT INTO dbo.DB_Errors
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE());
END CATCH
GO
Altering this stored procedure simply wraps error handling in this case around the only statement inside the stored procedure. If we call this stored procedure and pass some valid data, here’s what happens:
在这种情况下,更改此存储过程只是将错误处理包装在存储过程中的唯一语句周围。 如果我们调用此存储过程并传递一些有效数据,则将发生以下情况:
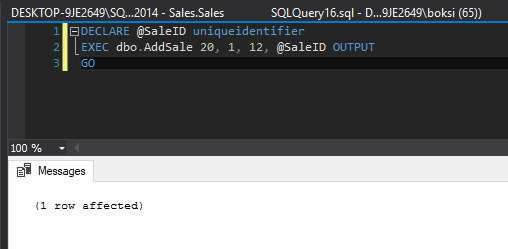
A quick Select statement indicates that the record has been successfully inserted:
快速Select语句指示记录已成功插入:
However, if we call the above-stored procedure one more time, passing the same parameters, the results grid will be populated differently:
但是,如果我们再次调用上述存储过程,并传递相同的参数,结果网格将以不同的方式填充:
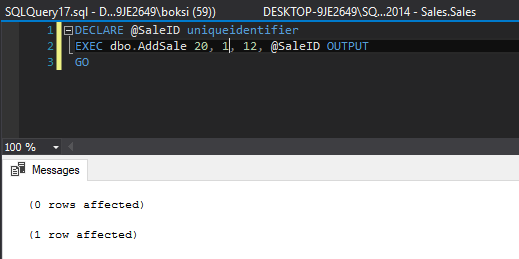
This time, we got two indicators in the results grid:
这次,我们在结果网格中获得了两个指标:
0 rows affected – this line indicated that nothing actually went into the Sales table
受影响的0行 –此行表示实际上没有任何数据进入Sales表
1 row affected – this line indicates that something went into our newly created logging table
受影响的1行 –此行表示某些内容已进入我们新创建的日志记录表
So, what we can do here is look at the errors table and see what happened. A simple Select statement will do the job:
因此,我们在这里可以做的就是查看错误表,看看发生了什么。 一个简单的Select语句即可完成工作:
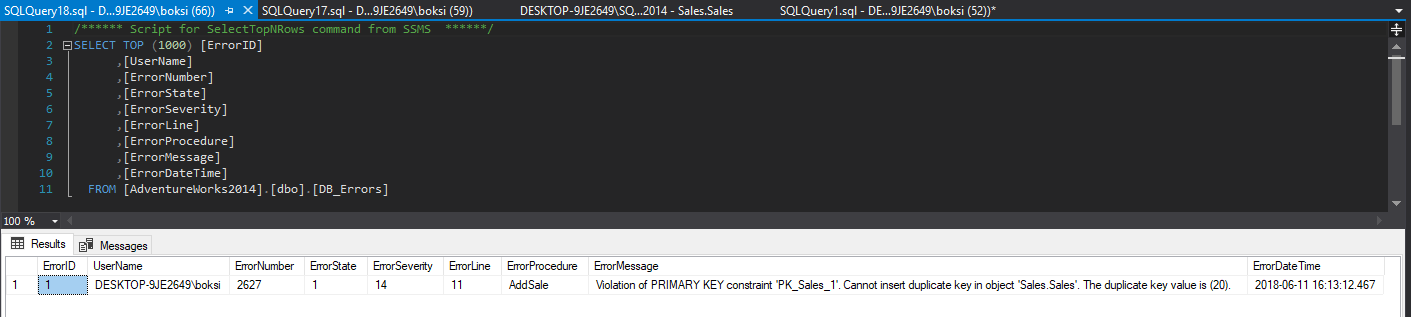
Here we have all the information we set previously to be logged, only this time we also got the procedure field filled out and of course the SQL Server “friendly” technical message that we have a violation:
在这里,我们拥有以前设置的所有信息要记录,仅这次,我们还填写了过程字段,当然还有违反我们SQL Server“友好”技术消息:
Violation of PRIMARY KEY constraint ‘PK_Sales_1′. Cannot insert duplicate key in object’ Sales.Sales’. The duplicate key value is (20).
违反主键约束'PK_Sales_1'。 无法在对象“ Sales.Sales”中插入重复键。 重复键值为(20)。
How this was a very artificial example, but the point is that in the real world, passing an invalid date is very common. For example, passing an employee ID that doesn’t exist in a case when we have a foreign key set up between the Sales table and the Employee table, meaning the Employee must exist in order to create a new record in the Sales table. This use case will cause a foreign key constraint violation.
这是一个非常人为的例子,但关键是在现实世界中,传递无效的日期非常普遍。 例如,如果在Sales表和Employee表之间设置了外键,则传递一个不存在的雇员ID,这意味着Employee必须存在才能在Sales表中创建新记录。 此用例将导致违反外键约束。
The general idea behind this is not to get the error fizzled out. We at least want to report to an individual that something went wrong and then also log it under the hood. In the real world, if there was an application relying on a stored procedure, developers would probably have SQL Server error handling coded somewhere as well because they would have known when an error occurred. This is also where it would be a clever idea to raise an error back to the user/application. This can be done by adding the RAISERROR function so we can throw our own version of the error.
这背后的一般想法不是使错误消失。 我们至少要向某人报告出现了问题,然后再将其记录下来。 在现实世界中,如果存在依赖存储过程的应用程序,则开发人员可能还会在某个地方编写SQL Server错误处理代码,因为他们会知道何时发生错误。 这也是将错误返回给用户/应用程序的一个好主意。 这可以通过添加RAISERROR函数来完成,以便我们可以抛出自己的错误版本。
For example, if we know that entering an employee ID that doesn’t exist is more likely to occur, then we can do a lookup. This lookup can check if the employee ID exists and if it doesn’t, then throw the exact error that occurred. Or in the worst-case scenario, if we had an unexpected error that we had no idea what it was, then we can just pass back what it was.
例如,如果我们知道输入不存在的员工ID的可能性更大,那么我们可以进行查找。 此查询可以检查员工ID是否存在,如果不存在,则抛出发生的确切错误。 或者在最坏的情况下,如果我们有一个意外错误,我们不知道它是什么,那么我们就可以传回它是什么。
高级SQL错误处理
(Advanced SQL error handling
)
We only briefly mentioned tricky part with transactions, so here’s a simple example of how to deal with them. We can use the same procedure as before, only this time let’s wrap a transaction around the Insert statement:
我们仅简要提到了交易中的棘手部分,因此这是一个如何处理交易的简单示例。 我们可以使用与之前相同的过程,只是这一次,我们将事务包装在Insert语句周围:
ALTER PROCEDURE dbo.AddSale @employeeid INT,
@productid INT,
@quantity SMALLINT,
@saleid UNIQUEIDENTIFIER OUTPUT
AS
SET @saleid = NEWID()
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO Sales.Sales
SELECT
@saleid,
@productid,
@employeeid,
@quantity
COMMIT TRANSACTION
END TRY
BEGIN CATCH
INSERT INTO dbo.DB_Errors
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE());
-- Transaction uncommittable
IF (XACT_STATE()) = -1
ROLLBACK TRANSACTION
-- Transaction committable
IF (XACT_STATE()) = 1
COMMIT TRANSACTION
END CATCH
GO
So, if everything executes successfully inside the Begin transaction, it will insert a record into Sales, and then it will commit it. But if something goes wrong before the commit takes place and it transfers control down to our Catch – the question is: How do we know if we commit or rollback the whole thing?
因此,如果一切都在Begin事务内成功执行,它将在Record中插入一条记录,然后将其提交。 但是,如果在提交之前出了点问题,并将控制权转移给了我们的Catch,问题是:我们怎么知道是提交还是回滚整个东西?
If the error isn’t serious, and it is in the committable state, we can still commit the transaction. But if something went wrong and is in an uncommittable state, then we can roll back the transaction. This can be done by simply running and analyzing the XACT_STATE function that reports transaction state.
如果错误不是很严重,并且处于可提交状态,我们仍然可以提交事务。 但是,如果出现问题并且处于不可提交的状态,那么我们可以回滚该事务。 这可以通过简单地运行和分析报告事务状态的XACT_STATE函数来完成。
This function returns one of the following three values:
此函数返回以下三个值之一:
1 – the transaction is committable
1 –事务是可提交的
-1 – the transaction is uncommittable and should be rolled back
-1 –事务不可提交,应回滚
0 – there are no pending transactions
0 –没有待处理的交易
The only catch here is to remember to actually do this inside the catch statement because you don’t want to start transactions and then not commit or roll them back:
这里唯一的陷阱是记住要在catch语句中实际执行此操作,因为您不想启动事务,然后不提交或回滚它们:
How, if we execute the same stored procedure providing e.g. invalid EmployeeID we’ll get the same errors as before generated inside out table:
如果执行相同的存储过程(例如提供无效的EmployeeID)的方式 ,将如何获得与之前由内而外的表生成的错误相同的错误:
The way we can tell that this wasn’t inserted is by executing a simple Select query, selecting everything from the Sales table where EmployeeID is 20:
我们可以通过执行简单的Select查询,从EmployeeID为20的Sales表中选择所有内容,来确定未插入此内容:
生成自定义引发错误SQL消息 (Generating custom raise error SQL message)
Let’s wrap things up by looking at how we can create our own custom error messages. These are good when we know that there’s a possible situation that might occur. As we mentioned earlier, it’s possible that someone will pass an invalid employee ID. In this particular case, we can do a check before then and sure enough, when this happens, we can raise our own custom message like saying employee ID does not exist. This can be easily done by altering our stored procedure one more time and adding the lookup in our TRY block:
让我们总结一下如何创建自己的自定义错误消息。 当我们知道可能发生的情况时,这些就很好。 如前所述,有人可能会传递无效的员工ID。 在这种情况下,我们可以在此之前进行检查,并且可以肯定的是,当发生这种情况时,我们可以提出自己的自定义消息,例如说员工ID不存在。 这可以通过再次更改存储过程并在TRY块中添加查找来轻松完成:
ALTER PROCEDURE dbo.AddSale @employeeid INT,
@productid INT,
@quantity SMALLINT,
@saleid UNIQUEIDENTIFIER OUTPUT
AS
SET @saleid = NEWID()
BEGIN TRY
IF (SELECT COUNT(*) FROM HumanResources.Employee e WHERE employeeid = @employeeid) = 0
RAISEERROR ('EmployeeID does not exist.', 11, 1)
INSERT INTO Sales.Sales
SELECT
@saleid,
@productid,
@employeeid,
@quantity
END TRY
BEGIN CATCH
INSERT INTO dbo.DB_Errors
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE());
DECLARE @Message varchar(MAX) = ERROR_MESSAGE(),
@Severity int = ERROR_SEVERITY(),
@State smallint = ERROR_STATE()
RAISEERROR (@Message, @Severity, @State)
END CATCH
GO
If this count comes back as zero, that means the employee with that ID doesn’t exist. Then we can call the RAISERROR where we define a user-defined message, and furthermore our custom severity and state. So, that would be a lot easier for someone using this stored procedure to understand what the problem is rather than seeing the very technical error message that SQL throws, in this case, about the foreign key validation.
如果该计数返回为零,则表示该ID的员工不存在。 然后,我们可以在定义用户定义的消息以及自定义严重性和状态的地方调用RAISERROR。 因此,对于使用这种存储过程的人来说,了解问题是要容易得多,而不是看到SQL抛出的关于外键验证的技术性错误消息,这要容易得多。
With the last changes in our store procedure, there also another RAISERROR in the Catch block. If another error occurred, rather than having it slip under, we can again call the RAISERROR and pass back exactly what happened. That’s why we have declared all the variables and the results of all the functions. This way, it will not only get logged but also report back to the application or user.
随着我们存储过程的最后更改,Catch块中还有另一个RAISERROR。 如果发生了另一个错误,而不是误入歧途,我们可以再次调用RAISERROR并准确返回发生的事情。 这就是为什么我们声明了所有变量和所有函数的结果的原因。 这样,它不仅会被记录,而且还会向应用程序或用户报告。
And now if we execute the same code from before, it will both get logged and it will also indicate that the employee ID does not exist:
现在,如果我们从以前执行相同的代码,那么它们都将被记录下来,并且还将指示该雇员ID不存在:
Another thing worth mentioning is that we can actually predefine this error message code, severity, and state. There is a stored procedure called sp_addmessage that is used to add our own error messages. This is useful when we need to call the message on multiple places; we can just use RAISERROR and pass the message number rather than retyping the stuff all over again. By executing the selected code from below, we then added this error into SQL Server:
值得一提的另一件事是,我们实际上可以预定义此错误消息的代码,严重性和状态。 有一个名为sp_addmessage的存储过程,用于添加我们自己的错误消息。 当我们需要在多个地方调用消息时,这很有用; 我们可以只使用RAISERROR并传递消息号,而不用重新键入内容。 通过从下面执行选择的代码,我们然后将此错误添加到SQL Server:
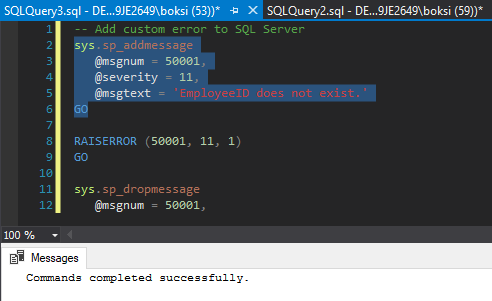
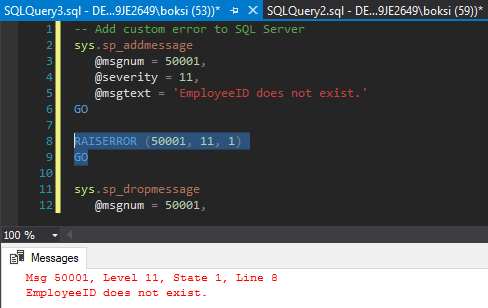
This means that now rather than doing it the way we did previously, we can just call the RAISERROR and pass in the error number and here’s what it looks like:
这意味着现在我们可以像以前那样做,而只需调用RAISERROR并传递错误号即可,结果如下所示:
The sp_dropmessage is, of course, used to drop a specified user-defined error message. We can also view all the messages in SQL Server by executing the query from below:
sp_dropmessage当然用于删除指定的用户定义的错误消息。 我们还可以通过从下面执行查询来查看SQL Server中的所有消息:
SELECT * FROM master.dbo.sysmessages
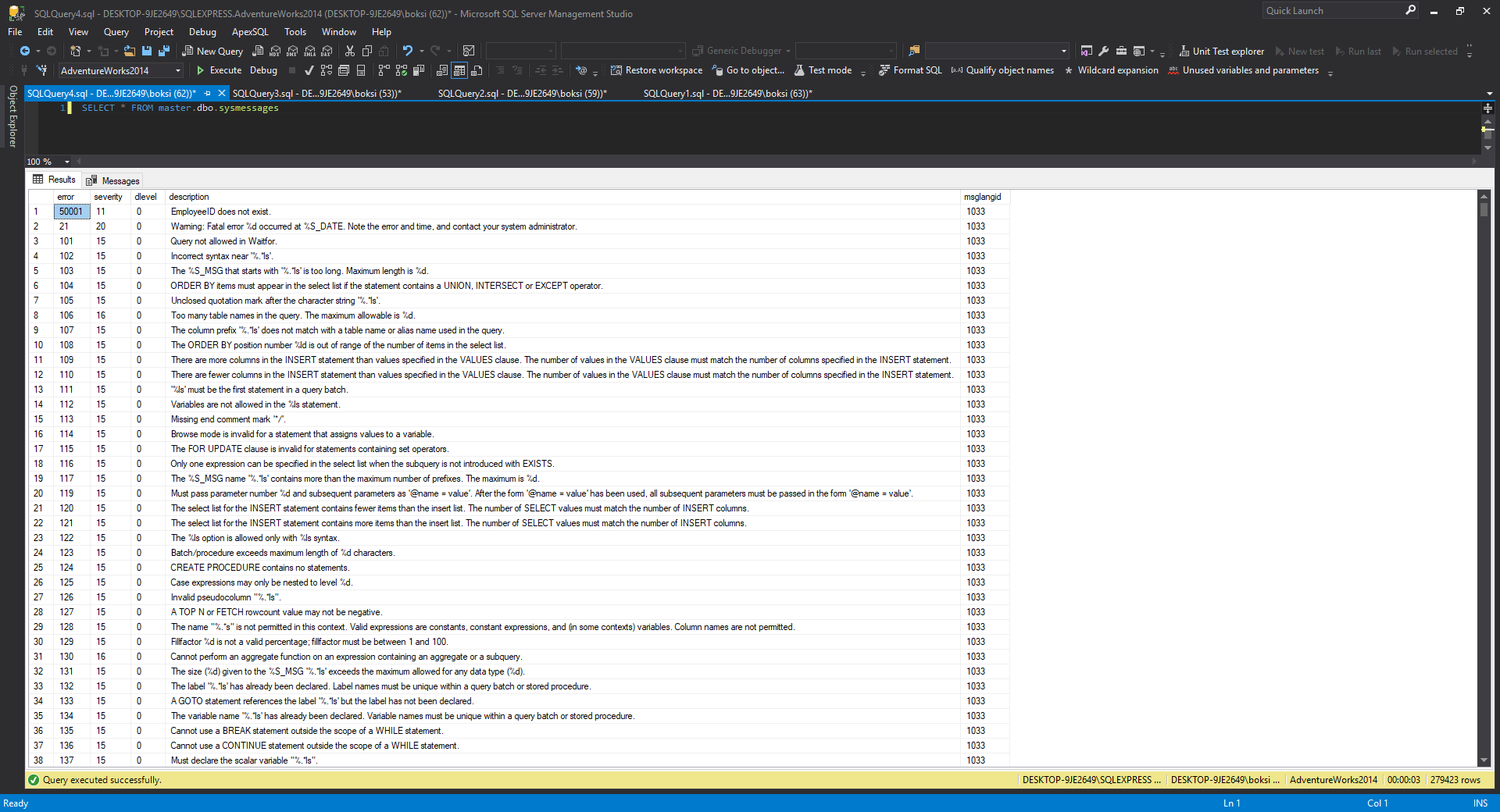
There’s a lot of them and you can see our custom raise error SQL message at the very top.
它们很多,您可以在顶部看到我们的自定义引发错误SQL消息。
I hope this article has been informative for you and I thank you for reading.
希望本文对您有所帮助,也感谢您的阅读。
参考资料 (References)
- TRY…CATCH (Transact-SQL) TRY…CATCH(Transact-SQL)
- RAISERROR (Transact-SQL) RAISERROR(Transact-SQL)
- System Functions (Transact-SQL) 系统功能(Transact-SQL)
翻译自: https://www.sqlshack.com/how-to-implement-error-handling-in-sql-server/















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









