





A relational database system uses SQL as the language for querying and maintaining databases. To see the data of two or more tables together, we need to join the tables; the joining can be further categorized into INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, and CROSS JOIN. All these types of joins that we use are actually based on the requirement of the users.
关系数据库系统使用SQL作为查询和维护数据库的语言。 要一起查看两个或多个表的数据,我们需要将这些表连接起来; 联接可以进一步分为内联接,左外联接,右外联接,全外联接和交叉联接。 我们使用的所有这些类型的联接实际上都是基于用户的需求。
SQL is a declarative language; we just write a query by the SQL language standard and ask for the database to fulfill the request. Now, it is the responsibility of the database to fulfill the user’s request optimally. Fortunately, SQL Server has the Query
SQL是一种声明性语言; 我们只是按照SQL语言标准编写查询,并要求数据库满足要求。 现在,数据库有责任以最佳方式满足用户的请求。 幸运的是,SQL Server拥有查询
Optimizer which is responsible for fulfilling the user requests optimally.
负责最优化地满足用户要求的优化器。
We need not to worry how things actually happen in the SQL Server, but it’s always good to know what’s happening behind the curtain sometimes so that we can figure out why a query is running slow.
我们不必担心SQL Server中实际发生的事情,但是总是知道有时幕后发生的事情总是很好的,这样我们就可以弄清楚为什么查询运行缓慢。
However, in the Execution plan, there are many iterators for different operations, but in this article, we will learn one iterator only, that is, the Nested Loop Join. It is a physical join type iterator. Whenever you join a table to another table logically, the Query Optimizer can choose one of the three physical join iterators based on some cost based decision, these are Hash Match, Nested Loop Join and Merge Join. This article only focuses on the Nested Loop Join, and hence let us quickly move to the joining part.
但是,在执行计划中,有许多用于不同操作的迭代器,但是在本文中,我们将仅学习一个迭代器,即嵌套循环联接。 它是一个物理连接类型的迭代器。 每当您将一个表逻辑地连接到另一个表时,查询优化器都可以基于一些基于成本的决策来选择三个物理连接迭代器之一,它们是哈希匹配 ,嵌套循环连接和合并连接 。 本文仅关注嵌套循环联接,因此让我们快速进入联接部分。
嵌套循环联接的基础 (Basics of Nested Loop Join )
In relational databases, a JOIN is the mechanism which we use to combine the data set of two or more tables, and a Nested Loop Join is the simplest physical implementation of joining two tables. For example, how would you match the following data manually, if you have these two tables given below:
在关系数据库中,JOIN是一种用于组合两个或多个表的数据集的机制,而嵌套循环联接是联接两个表的最简单的物理实现。 例如,如果您有以下两个表,将如何手动匹配以下数据:
| StudentInfo | Attendance | |||||
| RollNumber | Name | Address | RollNumber | Present | Date | |
| 1 | A | A’s Address | 1 | 1 | 1/1/2017 | |
| 2 | B | B’s Address | 2 | 1 | 1/1/2017 | |
| 3 | C | C’s Address | 3 | 1 | 1/1/2017 | |
| 1 | 1 | 1/2/2017 | ||||
| 2 | 0 | 1/2/2017 | ||||
| 3 | 1 | 1/2/2017 |
| 学生信息 | 出勤率 | |||||
| 卷号 | 名称 | 地址 | 卷号 | 当下 | 日期 | |
| 1个 | 一个 | A的地址 | 1个 | 1个 | 1/1/2017 | |
| 2 | 乙 | B的地址 | 2 | 1个 | 1/1/2017 | |
| 3 | C | C的地址 | 3 | 1个 | 1/1/2017 | |
| 1个 | 1个 | 2017/1/2 | ||||
| 2 | 0 | 2017/1/2 | ||||
| 3 | 1个 | 2017/1/2 |
Look at the above two result sets. StudentInfo table has student’s information; it has roll number, name and address columns. The attendance table contains daily attendance of the students; this table has the student’s roll number, present, and attendance date columns.
看上面两个结果集。 StudentInfo表包含学生的信息; 它具有卷号,名称和地址列。 出勤表包含学生的日常出勤情况; 该表包含学生的名册编号,现在和出勤日期列。
If you want to see a student’s name, address, present and attendance date in a new spreadsheet, you can only use one row at a time of a table. So, how would you do that?
如果要在新的电子表格中查看学生的姓名,地址,出勤日期和出勤日期,则一次只能使用一行。 那么,您将如何做呢?
In all probability, some of us will start with rollnumber 1 of the studentinfo table
很有可能,我们中的某些人将从studentinfo表的rollnumber 1开始
- We shall copy the student’s name and address from Attendance table, paste it into a new spreadsheet, 我们将从“出勤”表中复制学生的姓名和地址,并将其粘贴到新的电子表格中,
- Then we shall copy all the Present and date from the attendance table for roll number 1 and paste it in the spreadsheet. 然后,我们将从出勤表中复制第一卷的所有“出席”和“日期”,并将其粘贴到电子表格中。
The result set will look something like this after filling the data of roll number 1:
填充第1卷的数据后,结果集将如下所示:
| Name | Address | Present | Date |
| A | A’s Address | 1 | 1/1/2017 |
| A | A’s Address | 1 | 1/2/2017 |
| 名称 | 地址 | 当下 | 日期 |
| 一个 | A的地址 | 1个 | 1/1/2017 |
| 一个 | A的地址 | 1个 | 2017/1/2 |
Then we will repeat the same process for roll number 2 and roll number 3 after completing it all; your final result set will look somewhat like this:
完成所有步骤后,我们将对第2卷和第3卷重复相同的过程; 您的最终结果集将如下所示:
| Name | Address | Present | Date |
| A | A’s Address | 1 | 1/1/2017 |
| A | A’s Address | 1 | 1/2/2017 |
| B | B’s Address | 1 | 1/1/2017 |
| B | B’s Address | 0 | 1/2/2017 |
| C | C’s Address | 1 | 1/1/2017 |
| C | C’s Address | 1 | 1/2/2017 |
| 名称 | 地址 | 当下 | 日期 |
| 一个 | A的地址 | 1个 | 1/1/2017 |
| 一个 | A的地址 | 1个 | 2017/1/2 |
| 乙 | B的地址 | 1个 | 1/1/2017 |
| 乙 | B的地址 | 0 | 2017/1/2 |
| C | C的地址 | 1个 | 1/1/2017 |
| C | C的地址 | 1个 | 2017/1/2 |
If we try to convert what we did above in the pseudocode, then it will be like this:
如果我们尝试转换上面在伪代码中所做的操作,则将是这样的:
For each row from StudentInfo table until end of Attendance table
Match row from table2
If StudentInfo.rollnumber = Attendance.rollnumber
Return (StudentInfo.name , StudentInfo.Address, Attendance.Present, Attendance.AttandanceDate)
对于从StudentInfo表到出勤表结束的每一行
匹配table2中的行
如果StudentInfo.rollnumber = Attendance.rollnumber
返回(StudentInfo.name,StudentInfo.Address,Attendance.Present,Attendance.AttandanceDate)
Congratulations, now you already know how Nested Loop Join works.
恭喜,现在您已经知道嵌套循环连接的工作原理。
Now see this pseudocode about Nested Loop Join from Wikipedia:
现在,从Wikipedia上看到有关嵌套循环连接的伪代码:
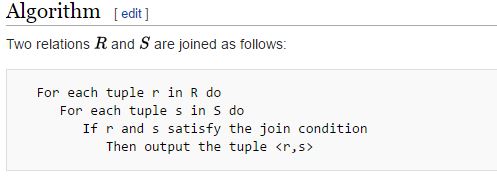
And here is something from Craig Freedman’s blog about Nested Loop Join:
以下是Craig Freedman博客中有关Nested Loop Join的内容 :

In a nutshell, the Nested Loop Join uses one joining table as an outer input table and the other one as the inner input table. The Nested Loop Join gets a row from the outer table and searches for the row in the inner table; this process continues until all the output rows of the outer table are searched in the inner table.
简而言之,嵌套循环联接将一个联接表用作外部输入表,将另一个联接表用作内部输入表。 嵌套循环联接从外部表中获取一行并在内部表中搜索该行; 此过程一直进行到在内部表中搜索外部表的所有输出行为止。
Nested Loop Join can be further categorized as Naive Nested Loop Join, Indexed Nested Loop Join and Temporary Index Nested Loop Join.
嵌套循环联接可以进一步分类为朴素的嵌套循环联接,索引嵌套循环联接和临时索引嵌套循环联接。
|
| |
| Naive Nested Loop Join | The Nested Loop Join searches for a row in the entire inner side of the table / index (except semi-join); this is called a Naive Nested Loop Join. |
| Indexed Nested Loop Join | The Nested Loop Join searches for a row in the inner side of the index and seeks the index’s B-tree for the searched value(s) and then stops looking further; it is called an Index Nested Loop Join. |
| Temporary Index Nested Loop Join | A Temporary index Nested Loop Join is exactly like the Index Nested Loop Join. The only difference is that the temporary index is created at the run time of query and destroyed upon completion of the query; it is called a temporary index nested loop join. |
|
| |
| 天真嵌套循环联接 | 嵌套循环联接在表/索引的整个内侧搜索一行(半联接除外); 这称为朴素嵌套循环联接。 |
| 索引嵌套循环联接 | 嵌套循环连接在索引的内侧搜索一行,并在索引的B树中搜索所搜索的值,然后停止进一步查找; 它称为索引嵌套循环联接。 |
| 临时索引嵌套循环连接 | 临时索引嵌套循环连接与索引嵌套循环连接完全相同。 唯一的区别是临时索引是在查询运行时创建的,并在查询完成时销毁; 它称为临时索引嵌套循环连接。 |
Now let us try to understand the Nested Loop Join with a few examples, and for that, we need to build at least two tables. In the example given below, we will use tables DBO.T1 and DBO.T2.
现在,让我们尝试通过一些示例来理解嵌套循环连接,为此,我们需要至少构建两个表。 在下面给出的示例中,我们将使用表DBO.T1和DBO.T2。
There are four columns in the DBO.T1 table: primarykey column, keycol column, searchcol column and somedata column. The DBO.T2 table is a replica of the DBO.T1 table, which consists only 300 rows, and it has one additional groupcol column which has repetitive integer values. Find the sample table structure and data in the following image:
DBO.T1表中有四列:主键列,keycol列,searchcol列和somedata列。 DBO.T2表是DBO.T1表的副本,该表仅包含300行,并且具有一个附加的groupcol列,该列具有重复的整数值。 在下图中找到示例表结构和数据:
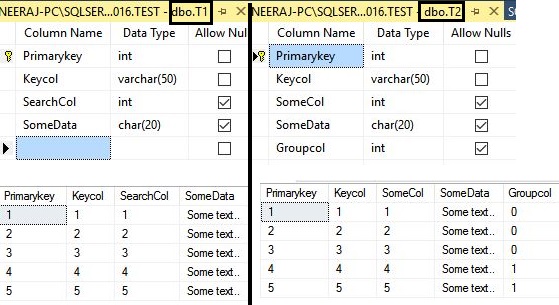
You can find the sample table script below in the article. Now we have an idea about tables, so we can start with the examples of Nested Loop Join:
您可以在下面的文章中找到示例表脚本。 现在我们有了关于表的想法,因此我们可以从嵌套循环联接的示例开始:
天真嵌套循环联接 ( Naive Nested Loop Join)
SELECT
*
FROM [DBO].[T1]
JOIN [DBO].[T2]
ON T1.keycol = T2.Keycol
WHERE T1.Primarykey > 0
AND T1.Primarykey < 11
ORDER BY T1.Primarykey
OPTION (RECOMPILE)
Look at the execution plan of the above query; you can see on the top right-hand side that there is a table named T1. In the execution plan, the table is displayed as tablename.indexname (if indexed), so here it is showing as T1.pk_T1; this is the outer table and the other one is the inner table.
查看上面查询的执行计划; 您可以在右上角看到一个名为T1的表。 在执行计划中,该表显示为tablename.indexname(如果已索引),因此此处显示为T1.pk_T1; 这是外部表,另一个是内部表。
As stated above in the article, data flow starts with the outer table. There is a range predicate on the DBO.T1 table and it starts with “>0”; so first it would seek for the first value which is 1 here and get all the associated columns of this row as requested by the query. The Nested Loop Join gets it and initiated the search to its associated keycol column in the entire inner table when it finds the matching row, then returns all the requested column as an output to the Nested Loop Join iterator; the Nested Loop Join merges both output columns and sends the result set to the parent iterator. This process keeps on repeating itself until the outer table stops sending rows to the Nested Loop Join. This entire process can be classified as a naive Nested Loop Join.
如上文所述,数据流从外部表开始。 DBO.T1表上有一个范围谓词,它以“> 0”开头; 因此,首先它将在此处寻找第一个值1,并根据查询的要求获取该行的所有关联列。 当找到匹配的行时,嵌套循环连接会获取它并开始搜索整个内部表中与其关联的keycol列,然后将所有请求的列作为输出返回给嵌套循环连接迭代器; 嵌套循环联接合并两个输出列,并将结果集发送到父迭代器。 该过程一直重复进行,直到外部表停止向嵌套循环联接发送行。 这整个过程可以归为朴素的嵌套循环联接。
索引嵌套循环联接 (Indexed Nested Loop Join)
SELECT
*
FROM DBO.[T1]
JOIN DBO.[T2]
ON T1.Primarykey = T2.Primarykey
WHERE T1.SearchCol > 0
AND T1.SearchCol < 11
ORDER BY T1.Primarykey
OPTION (RECOMPILE, FORCE ORDER, MAXDOP 1)
The above query is forced, so we all get the same execution plan shape. The above Nested Loop Join can be classified as indexed Nested Loop Join only for the reason that the inner side of the Nested Loop Join is indexed and seekable using the primarykey column; the explanation is almost same as Naive Nested Loop Join. Nested Loop Join gets the first value from the DBO.T1 table, then it seeks that value in the DBO.T2 table, but this time joining column is the primary key (unique clustered index) so there is no need to look for the entire index.
上面的查询是强制的,因此我们所有人都具有相同的执行计划形状。 上面的嵌套循环连接只能归类为索引嵌套循环连接,原因仅在于使用主键列对嵌套循环连接的内侧进行索引和查找; 解释几乎与朴素的嵌套循环联接相同。 嵌套循环连接从DBO.T1表中获取第一个值,然后在DBO.T2表中查找该值,但是这次连接列是主键(唯一的聚集索引),因此无需查找整个键。指数。
临时索引嵌套循环联接 (Temporary index nested loops join )
Getting a temporary index in the Nested Loop Join is not common, since creating an index at runtime in the table requires additional cost to the query. The Query Optimizer creates a temporary index on the table when it finds that its cheap to create an index in the column compared to the non-index version of the same query. If you try to get comma separated values for a non-indexed group then there are chances to see temporary index with the Nested Loop Join on the inner table.
在嵌套循环联接中获取临时索引并不常见,因为在表的运行时创建索引需要查询的额外费用。 当查询优化器发现与同一查询的非索引版本相比,在列中创建索引便宜时,它会在表上创建一个临时索引。 如果您尝试为非索引组获取逗号分隔的值,则可以在内部表上看到带有嵌套循环联接的临时索引。
In our example, we have a groupcol column in the DBO.T2 table, so let us use comma separated value in the groupcol column and see the query and Execution plan below:
在我们的示例中,我们在DBO.T2表中有一个groupcol列,因此让我们在groupcol列中使用逗号分隔的值,然后查看下面的查询和执行计划:
SELECT
Groupcol,
STUFF((SELECT
',' + CONVERT(varchar, T2c.SomeCol)
FROM [DBO].[T2] T2c
WHERE T2.groupcol = T2c.groupcol
FOR xml PATH ('')), 1, 1, ' ') CommaseperatedCOL
FROM [DBO].[T2]
GROUP BY Groupcol
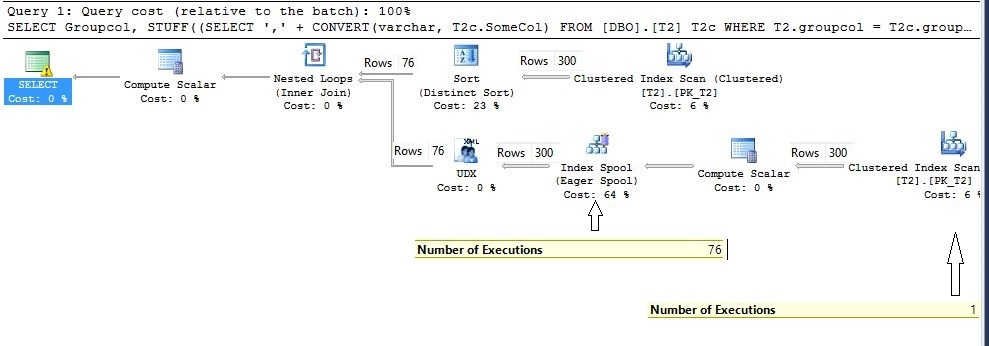
At the bottom of right side of an execution plan, there is an Index Spool (Eagar Spool), which is actually a temporary index on the groupcol column.
在执行计划的右侧底部,有一个索引缓冲池( Eagar Spool ),它实际上是groupcol列上的一个临时索引。
Explanation of execution plan:
执行计划说明:
Let’s now focus on the explanation, a bit more closely, this time. As usual, data flow starts from the top outer table, but this time our DBO.T2 table is the outer table, after fetching all the data from the top DBO.T2 table Distinct Sort iterator group all the data and passes the first value to the Nested Loop Join. On the other hand, execution starts from the inner side of DBO.T2 table, after concatenation of comma “,” (it is labeled as [Expr1002] column) this column is indexed, which is visible in the execution plan as Index spool, and after that all executions perform with this newly created index only. This can be confirmed by looking at the number of executions in the iterator’s properties. Just have a look at the execution plan above, inner side of the DBO.T2 table executed just once and index spool executed 76 times.
现在,让我们现在更加集中地说明一下。 像往常一样,数据流从顶部的外部表开始,但是这次我们的DBO.T2表是外部表,是从顶部的DBO.T2表中获取所有数据后,对所有数据进行离散排序迭代器组并将第一个值传递给嵌套循环联接。 另一方面,从DBO.T2表的内侧开始,在连接逗号“,”(标记为[Expr1002]列)之后,对该列进行索引,这在执行计划中显示为Index spool ,然后所有执行仅使用此新创建的索引执行。 这可以通过查看迭代器属性中的执行次数来确认。 只需看一下上面的执行计划,DBO.T2表的内部仅执行一次,而索引假脱机执行了76次。
Nested Loop Join的成本明细仅用于教育目的 (Costing details for Nested Loop Join for educational purpose only)
The cost of the execution plan, whether its CPU, IO or any other costs do not reflect the actual cost of your hardware; these numeric values are just units of measurement used by the Query Optimizer to compare the execution plans as a whole. So a natural question arises: where do these costs come from?
执行计划的成本,无论是其CPU,IO还是其他任何成本都不能反映您硬件的实际成本; 这些数字值只是查询优化器用来比较整个执行计划的度量单位。 因此,一个自然的问题出现了:这些成本从何而来?
The cost values were actually the number of seconds for which, that the query was expected to run on the engineer’s machine (“Nick’s machine”). Nick was the part of the Query Optimizer team and he was responsible for calculating query’s costs so he decided that if a query runs for 1 second on his own PC the cost will be 1 unit.
成本值实际上是期望查询在工程师的机器(“ 尼克的机器 ”)上运行的秒数。 Nick是Query Optimizer团队的成员,他负责计算查询的成本,因此他决定,如果查询在自己的PC上运行1秒,则成本为1个单位。
As this is a part of internal implementations, these costs may vary from version to version of the SQL Server. SQL Server’s Query Optimizer is a cost based optimizer, If a full cost-based optimization is performed, it creates multiple execution plans for the expressed query by the user and chooses the one which has the lowest overall cost. Each iterator in the execution plan has some cost which is roughly an addition of CPU, IO and some other variable information like histogram, data pages and statistics information etc.
由于这是内部实现的一部分,因此这些费用可能因SQL Server的版本而异。 SQL Server的查询优化器是一种基于成本的优化器 ,如果执行了基于成本的完全优化,它将为用户为所表达的查询创建多个执行计划,并选择总体成本最低的计划。 执行计划中的每个迭代器都有一些成本,这大约是CPU,IO和一些其他变量信息(如直方图,数据页和统计信息等)的增加。
The Nested Loop Join iterator does not have any initialization cost. Rather, it has got only cost per row and it does not require additional memory (except Batch sort or Implicit sort) like other join types such as hash join, which requires building a hash table in the memory and merge join requires to sort the inputs if not indexed on joining column(s).
嵌套循环联接迭代器没有任何初始化成本。 相反,它仅具有每行成本,并且不需要像其他联接类型(例如哈希联接)那样需要额外的内存 (批处理排序或隐式排序除外),哈希联接需要在内存中构建哈希表,而合并联接则需要对输入进行排序如果未在连接列上建立索引。
Nested Loop Join costing is not documented, so we can only assume and this might change in the future.*
未记录嵌套循环联接成本,因此我们只能 假设 ,将来可能会改变。 *
For the tests, we will create 2 basic tables with integer values, and then join those tables and finally try to identify CPU cost with different row counts, data pages count and with or without parallelism. With my quick testing, I came up with a rough formula for the CPU cost only, as there is no IO cost for the Nested Loop Join but operator costs may vary with other factors.
对于测试,我们将创建2个具有整数值的基本表,然后将这些表连接起来,最后尝试确定具有不同行数,数据页数以及有无并行度的CPU成本。 通过快速测试,我只为CPU成本提出了一个粗略的公式,因为嵌套循环连接没有IO成本,但操作员成本可能会因其他因素而异。
Below is the rough formula for CPU cost of Nested Loop Join:
以下是嵌套循环连接的CPU成本的大致公式:
| NL join CPU cost estimated formula | = 0.0000041800 * OTER * ITER |
| Parallel NL join CPU cost estimated formula | = (0.0000041800 * OTER *ITER ) / MIN (Cpu_for_query OR (Cpu_Count/2)) |
| NL加入CPU成本估算公式 | = 0.0000041800 * OTER * ITER |
| 并行NL加入CPU成本估算公式 | =(0.0000041800 * OTER * ITER)/ MIN(Cpu_for_query 或 (Cpu_Count / 2)) |
*OTER = Outer Table Estimated Rows.
* OTER =外表估计行。
*ITER = Inner Table Estimated Rows.
* ITER =内部表估计行。
*Cpu_for_query = Available CPU for the query at the runtime.
* Cpu_for_query =运行时用于查询的可用CPU。
*Cpu_Count= Available CPU for SQL Server instance.
* Cpu_Count = SQL Server实例的可用CPU。
*Results are calculated to decimal`s 7th place approx.
*结果计算到小数点后第七位。
For example, if a machine has 16 CPU available, but it’s running with 4 CPU (restricted by the user) then the calculation would be: Convert (Decimal (25 ,7 ),( 0.0000041800 * OTER *ITER )) / 4.
例如,如果一台机器有16个CPU可用,但它以4个CPU运行(受用户限制),则计算将为:Convert(Decimal(25,7),(0.0000041800 * OTER * ITER))/ 4。
If it’s running with all available CPUs then the calculation will be:
Convert (decimal (25 ,7), (0.0000041800 * OTER *ITER)) / 8, divided part is calculated as 16/2=8.
如果它与所有可用CPU一起运行,则计算将为:
转换(十进制(25,7),(0.0000041800 * OTER * ITER))/ 8,除法部分计算为16/2 = 8。
The interesting part about this test is NL’s CPU cost doesn’t change with the data types, data pages or with the table’s indexes. The testing is conducted with INT data type, but I tested it with CHAR, VARCHAR, NVARCHAR, NCHAR, DATETIME and CPU costing doesn’t change.
关于此测试的有趣之处在于,NL的CPU成本不会随数据类型,数据页或表的索引而变化。 该测试是使用INT数据类型进行的,但是我使用CHAR,VARCHAR,NVARCHAR,NCHAR,DATETIME进行了测试,并且CPU成本不变。
Unfortunately, my machine has only 4 virtual CPU available, so the CPU cost of the nested loop join won’t come down after DOP 2 as per the formula.
不幸的是,我的机器只有4个虚拟CPU可用,因此按照公式在DOP 2之后,嵌套循环连接的CPU成本不会降低。
Below are the tests that I had conducted to get the above formula.**
以下是我为获得上述公式而进行的测试。 **
Result and script below:
结果和脚本如下:
| Outer Table RC | Inner Table RC | Estimated Cpu Cost | Formula’s Calculation | Maxdrop |
| 1 | 1 | 0.0000042 | 0.0000042 | 1 |
| 1 | 10 | 0.0000418 | 0.0000418 | 1 |
| 1 | 766788 | 3.20517 | 3.2051738 | 1 |
| 88888 | 766788 | 284901 | 284901.4923 | 1 |
| 88888 | 766788 | 142451 | 142450.7461 | 2 |
| 88888 | 766788 | 142451 | 142450.7461 | 3 |
| 88888 | 766788 | 142451 | 142450.7461 | 4 |
| 外层RC | 内桌RC | 预估CPU费用 | 公式的计算 | Maxdrop |
| 1个 | 1个 | 0.0000042 | 0.0000042 | 1个 |
| 1个 | 10 | 0.0000418 | 0.0000418 | 1个 |
| 1个 | 766788 | 3.20517 | 3.2051738 | 1个 |
| 88888 | 766788 | 284901 | 284901.4923 | 1个 |
| 88888 | 766788 | 142451 | 142450.7461 | 2 |
| 88888 | 766788 | 142451 | 142450.7461 | 3 |
| 88888 | 766788 | 142451 | 142450.7461 | 4 |
*RC = Row Count
* RC =行数
CREATE TABLE A1 (
a INT
)
CREATE TABLE A2 (
a INT
)
UPDATE STATISTICS a2 WITH ROWCOUNT = 1
UPDATE STATISTICS a1 WITH ROWCOUNT = 1
SELECT CONVERT(decimal(25, 7), (0.0000041800 * 1 * 1)) -- 0.0000042
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE);
GO
UPDATE STATISTICS a2 WITH ROWCOUNT = 1 , pagecount =10000
UPDATE STATISTICS a1 WITH ROWCOUNT = 10 , pagecount =100000
SELECT CONVERT(decimal(25, 7), (0.0000041800 * 1 * 10)) --0.0000418
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE);
GO
UPDATE STATISTICS a2 WITH ROWCOUNT = 1
UPDATE STATISTICS a1 WITH ROWCOUNT = 766788
SELECT CONVERT(decimal(25, 7), (0.0000041800 * 1 * 766788)) --3.2051738
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE)
UPDATE STATISTICS a2 WITH ROWCOUNT = 88888
UPDATE STATISTICS a1 WITH ROWCOUNT = 766788
SELECT CONVERT(decimal(25, 7), (0.0000041800 * 88888 * 766788)) --284901.4922899
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE)
--Parallelism Test
SELECT CONVERT(decimal(25, 7), (0.0000041800 * 88888 * 766788)) / 2 --142450.746144950
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 2, RECOMPILE)
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 3, RECOMPILE)
SELECT
*
FROM a1
JOIN a2
ON a1.a = a2.a
OPTION (LOOP JOIN, MAXDOP 4, RECOMPILE)
This article is just an introduction to Nested Loop Join. It offers a lot of variety than what people can think of. The next part in this series will build on the foundations provided in this introduction.
本文只是对嵌套循环联接的介绍。 它提供了超出人们想象的多样性。 本系列的下一部分将以本简介中提供的基础为基础。
You can download the script to populate the Sample table here.
您可以在此处下载脚本以填充Sample表。
脚注 (Footnotes)
* I have tested it on Microsoft SQL Server 2016 (RTM) – 13.0.1601.5 and Microsoft SQL Server 2014 – 12.0.4100.1 (X64)
** In the test to influence the outer and inner table estimated rows, I used undocumented and unsupported update statistics options, which is not meant to be used for the production servers.
*我已经在Microsoft SQL Server 2016(RTM)– 13.0.1601.5和Microsoft SQL Server 2014 – 12.0.4100.1(X64)上进行了测试
**在影响外部和内部表估计行的测试中,我使用了未记录且不受支持的更新统计信息选项 ,该选项不用于生产服务器。
The next article in this series
本系列的下一篇文章
- Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates并行嵌套循环连接–嵌套循环连接和残留谓词的内侧
看更多 (See more)
Consider these free tools for SQL Server that improve database developer productivity.
考虑使用这些免费SQL Server工具来提高数据库开发人员的生产力。
有用的链接 (Useful links)
- Understanding Hash Joins 了解哈希联接
- Understanding Merge Joins 了解合并联接
- Execution plan costs 执行计划费用
- What estimated subtree cost means 估计的子树成本意味着什么
- Update statistics undocumented options 更新统计信息未记录的选项

翻译自: https://www.sqlshack.com/introduction-to-nested-loop-joins-in-sql-server/















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









