





mysql单张表数据量极限
When we develop security testing within inconsistent data volume situations, we should consider our use of anti-malware applications that use behavioral analysis. Many of these applications are designed to catch and flag unusual behavior. This may help prevent attacks, but it may also cause ETL flows to be disrupted, potentially disrupting our customers or clients. While we may have a consistent flow of data throughout a time period – allowing for a normal window of behavior to occur – we may also have an inconsistent data schedule or inconsistent amount of data that cause these applications to flag files, directories, or the process itself.
在不一致的数据量情况下开发安全测试时,应考虑使用行为分析的反恶意软件应用程序。 这些应用程序中有许多旨在捕获并标记异常行为。 这可能有助于防止攻击,但也可能导致ETL流被中断,从而有可能破坏我们的客户。 尽管我们可能在一个时间段内保持一致的数据流-允许正常的行为窗口出现-但我们可能还存在不一致的数据调度或不一致的数据量,从而导致这些应用程序标记文件,目录或进程本身。
当反恶意软件导致报告中断时 (When Anti-Malware causes report outage)
In many environments, security testing involves checking for possible vulnerabilities against attack. In one example I had to investigate, the testing overlooked significant changes in data load and extract volumes that were possible. The assumption was that these loads and extracts would happen within a data range (such as “within 500GB per day”), but it only took one exceptional day to cause the anti-malware application to flag the load before the extract. The result of this was an outage with reports. It’s possible that we’re not checking for legitimate process ranges in our testing and this can be costly in the same manner as a breach in some contexts. In this case, the solution for future security testing required resources and time to improve the possible range of data volume during extracts and loads.
在许多环境中,安全测试都涉及检查可能的漏洞以防攻击。 在我不得不调查的一个示例中,测试忽略了可能的数据加载和提取量的重大变化。 假定这些负载和提取将在一个数据范围内发生(例如“每天500GB内”),但是只花了一个例外的一天就使反恶意软件应用程序在提取之前标记负载。 结果是报告中断。 我们很可能没有在测试中检查合法的过程范围,并且这在某些情况下可能会与违规相同,因此代价高昂。 在这种情况下,用于将来的安全测试的解决方案需要资源和时间来提高提取和加载期间数据量的可能范围。
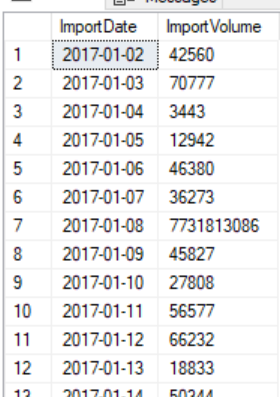
An example of inconsistent data loads daily showing the date and volume of data that can complicate security testing and prevention
每天不一致的数据加载示例显示了可能使安全测试和预防变得复杂的数据日期和数据量
识别数据量范围 (Identifying data volume ranges)
If we’ve seen this issue or if this may be a possible issue, we want to prevent it through tracking our data volume ranges in each environment. This means that following an extract or load, we want to track the amount of data – whether we want to use row counts, data size, etc. When we review this on reports, we want to know the average data volume and the maximum data volume. Consider that we may have an extract data volume of 100,000 records for 700 days consistently, then one day we have an extract data volume of 1,500,000 records. That one data point would not be enough to affect the average, but it may be flagged by anti-malware because it’s unusually high (this is similar in structure to the incident I reviewed). Depending on these numbers, we may want to review how we’re security testing for a possible false flag with anti-malware.
如果我们已经看到此问题,或者可能会出现此问题,则希望通过跟踪每个环境中的数据量范围来防止它发生。 这意味着在提取或加载之后,我们要跟踪数据量–是否要使用行数,数据大小等。当我们在报表上进行检查时,我们想知道平均数据量和最大数据量卷。 考虑到我们可能连续700天具有100,000条记录的提取数据量,那么有一天我们有1,500,000条记录的提取数据量。 该数据点不足以影响平均值,但是它可能会被反恶意软件标记,因为它异常高(这与我所审查的事件的结构相似)。 根据这些数字,我们可能想查看一下我们如何对反恶意软件可能的错误标记进行安全测试。
In the below script, we create a table for identifying data volume ranges over time and we include the environment in this table, as there may be variance in environments that we want to know about ahead of time. Because aggregates will generally be used when querying this table and new records will be infrequently added, I create it with a clustered columnstore index. We may use other derivatives of this table, such as storing the data size in gigabytes; the key is tracking how often we get unusually large extracts or loads, the size of these large extracts or loads, and whether our security testing will pass these situations.
在下面的脚本中,我们创建一个表来标识一段时间内的数据量范围,并且在此表中包括环境,因为我们想提前知道的环境可能会有差异。 因为在查询该表时通常会使用聚合,并且很少会添加新记录,所以我使用集群列存储索引创建它。 我们可能会使用该表的其他派生形式,例如以GB为单位存储数据大小; 关键是跟踪我们多久获得一次异常大的提取物或负载,这些庞大的提取物或负载的大小以及我们的安全测试是否会通过这些情况。
CREATE TABLE tbLoads(
Environment VARCHAR(15),
LoadDate DATETIME,
DataVolume BIGINT ---- Replacement could be SizeInGB
)
CREATE CLUSTERED COLUMNSTORE INDEX CCI_tbLoads ON tbLoads
当环境不同时 (When environments differ)
In some circumstances, we may have a development and QA environment that does not match the data volume of our production environment. In the below image from a query comparing data volumes across environments, we see a comparison between an average QA environment load and production environment load. Notice the extreme deviation from the average (measured by maximum data load divided by average data load) – production’s largest deviation from its average was seven multiples, while QA was 2 multiples:
在某些情况下,我们的开发和质量检查环境可能与生产环境的数据量不匹配。 在下图比较环境中数据量的查询中,我们看到了平均质量检查环境负载和生产环境负载之间的比较。 请注意,与平均值的极端偏差(用最大数据负载除以平均数据负载来衡量)–生产与平均值的最大偏差是7倍,而QA是2倍:
SELECT
Environment
, AVG(DataVolume) AvgLoad
, (MAX(DataVolume)/(AVG(DataVolume))) MaxLoadDivByAvg
FROM tbLoads
GROUP BY Environment
ORDER BY AVG(DataVolume) DESC
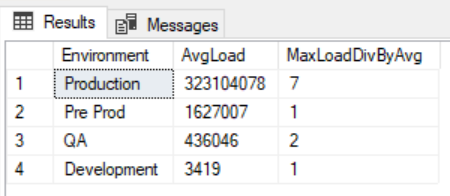
In this example, our security testing in QA would not catch the possible data volume range that would exist in production
在此示例中,我们在质量检查中进行的安全测试无法捕获生产中可能存在的数据量范围
This may give us false positives in our security testing if anti-malware software is involved because it may not flag our extracting or loading in development due to a low data range volume but flags it in production. It’s the production cost of an outage we want to avoid. The technique we can use in testing is to match the extreme range in our data volume that may exist in production. If production may have a data load that is seven multiples of the average load, we should duplicate the same type of multiple for development and QA. We must remember that it’s not the amount of data, but the range of data volume from the maximum load (or extract) to the average.
如果涉及到反恶意软件,这可能会给我们带来安全测试方面的误报,因为它可能不会由于数据范围较小而标记我们正在提取或正在开发中的负载,而是会在生产中对其进行标记。 这是我们要避免的停机生产成本。 我们可以在测试中使用的技术是匹配生产中可能存在的数据量的极端范围。 如果生产中的数据负载可能是平均负载的七倍,那么我们应该为开发和质量检查复制相同类型的倍数。 我们必须记住,这不是数据量,而是从最大负载(或提取)到平均值的数据量范围 。
可能的解决方案 (Possible solutions)
We will build our ETL flows around possible solutions that keep our environment protected while allowing legitimate data flow to occur. For these situations, we may do one or more of the following:
我们将围绕可能的解决方案构建ETL流,这些解决方案在保护环境的同时允许合法数据流的发生。 对于这些情况,我们可能会执行以下一项或多项操作:

(Example) Some anti-malware applications may allow us to exclude some file paths for scanning.
(示例)某些反恶意软件应用程序可能允许我们排除某些文件路径以进行扫描。
- Waive the folder path or specific file (if named consistently) for our ETL extracts and loads – including in our security testing environment, if the anti-malware allows for this option. We would want other monitoring to ensure that nothing outside extracts and loads occurs though 如果反恶意软件允许此选项,则放弃我们的ETL提取和加载的文件夹路径或特定文件(如果名称一致)–包括在我们的安全测试环境中。 我们希望通过其他监视来确保不会发生外部提取和负载的任何情况
- Determine the size of the extract, or load before importing or exporting, if we can determine this information and intervene if necessary (or automate an intervention if possible). Unfortunately, this may not assist us if the file is flagged due to size when the file source submits it 如果我们可以确定此信息并在必要时进行干预(或在可能的情况下自动进行干预),请确定提取物的大小,或在导入或导出之前加载。 不幸的是,如果在文件源提交文件时由于大小将文件标记出来,这可能对我们没有帮助
- Allow for more flexibility on the server if the scheduled time is consistent. This would be an ideal time to attack though, so this may only be appropriate with other techniques or in some situations 如果计划的时间一致,请在服务器上提供更大的灵活性。 不过,这将是理想的攻击时间,因此这仅适用于其他技术或在某些情况下
- Allow the increased security measures from the anti-malware (file or path flagging) and delay the reports – an appropriate technique in environments where security is the highest priority. Keep in mind that unless our ETL is inconsistent, a flagged operation may be malware 允许增加来自反恶意软件的安全措施(文件或路径标记)并延迟报告-在安全性是最高优先级的环境中的一种适当技术。 请记住,除非我们的ETL不一致,否则标记的操作可能是恶意软件
- Perform “false” extracting and loading in all environments (including production) and with our security testing to ensure that our data flow covers the possible range of volume (trains the anti-malware on what may be normal) 在所有环境(包括生产环境)中进行“虚假”提取和加载,并进行我们的安全测试,以确保我们的数据流覆盖可能的容量范围(对反恶意软件进行正常培训)
- Delineate our ETL extract and load server or servers where these have no anti-malware application. This would only be appropriate in environments where security is less of a concern 描述我们的ETL提取并加载没有反恶意软件应用程序的服务器。 这仅适用于安全性不太重要的环境
Attackers will often perform reconnaissance on a target before attacking so that they understand their target before they attack. This means that patterns like allowing folder paths, time flexibility, etc. may be discovered ahead of time.
攻击者通常会在攻击之前对目标执行侦察,以便在攻击之前了解目标。 这意味着可能会提前发现诸如允许文件夹路径,时间灵活性等模式。
摘要 (Summary)
Anti-malware applications can provide us with tools to prevent attacks or identify attacks. However, in large data volume environments with inconsistent extracting or loading, they may add complexity if they flag legitimate data functionality. Our security testing should involve identifying where this may occur and how we can prevent and work-around this while being cautious about what our solution may involve. While we want to ensure our data flow, we also want to be careful that we don’t open our environment to attacks.
反恶意软件应用程序可以为我们提供防止攻击或识别攻击的工具。 但是,在提取或加载不一致的大型数据量环境中,如果标记合法数据功能,它们可能会增加复杂性。 我们的安全测试应包括确定可能发生的位置以及如何预防和解决此问题,同时谨慎考虑解决方案可能涉及的内容。 虽然我们要确保数据流,但也要注意不要对环境开放攻击。
翻译自: https://www.sqlshack.com/security-testing-with-extreme-data-volume-ranges/
mysql单张表数据量极限















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









