





In this article, we will demonstrate specific ways to automate table partitioning in SQL Server. This article aims to help you avoid manual table activities of partition maintenance by automating it with T-SQL scripts and SQL Server jobs.
在本文中,我们将演示在SQL Server中自动进行表分区的特定方法。 本文旨在通过使用T-SQL脚本和SQL Server作业自动进行分区维护,从而避免手动进行分区维护。
Automation with the partition task is required when the range of partition function is not enough to proceed for the newly inserted data. For example, when a partition function does not have a range for new rows and inserting rows into the table is out of the existing range. However, those rows will be inserted into the table but do not move to the appropriate filegroup and its files. Most probably, a partition is required on tables that are having a large number of rows. For those tables, the partition function separates the rows by month, year, or any other valuable column.
当分区功能的范围不足以继续处理新插入的数据时,需要使用分区任务进行自动化。 例如,当分区函数没有新行的范围,并且在表中插入行超出现有范围时。 但是,这些行将被插入表中,但不会移动到适当的文件组及其文件。 最有可能的是,在具有大量行的表上需要一个分区。 对于那些表,分区功能按月,年或任何其他有价值的列分隔行。
Initially, a database team will plan the predicted maximum range by adding a filegroup to the partition scheme and adding a range to the partition function. A new range with partition function and filegroup with the partition scheme is required when the existing range is near about to the ending. Adding a new range and filegroup to the current partitioning is the manual activity, and that can be performed by the database administrator while monitoring the range. A database administrator will split the range when partition’s range is near about the end. Here, this article suggests some ordinary solutions to automate with the help of the SQL Server scheduler.
最初,数据库团队将通过将文件组添加到分区方案并将范围添加到分区功能来计划预测的最大范围。 当现有范围即将结束时,需要具有分区功能的新范围和具有分区方案的文件组。 手动活动是将新范围和文件组添加到当前分区中,可以由数据库管理员在监视范围时执行。 当分区的范围接近末尾时,数据库管理员将划分范围。 在这里,本文提出了一些在SQL Server调度程序的帮助下实现自动化的常规解决方案。
SQL Server scheduler can help with splitting a new partition range and adding new filegroups as it is required for the partition functions and schemes. Users can write a short program to automate the partition with the help of T-SQL, and that program can be executed using a SQL Server job. Before designing the maintenance for partitioning in SQL Server, users should be aware of what is table partitioning in SQL Server? And why is partitioning required in SQL Server?
SQL Server调度程序可以帮助您分割新的分区范围,并根据分区功能和方案的需要添加新的文件组。 用户可以在T-SQL的帮助下编写一个简短的程序来自动化分区,并且可以使用SQL Server作业来执行该程序。 在设计维护以在SQL Server中进行分区之前,用户应了解SQL Server中的表分区是什么? 为什么在SQL Server中需要分区?
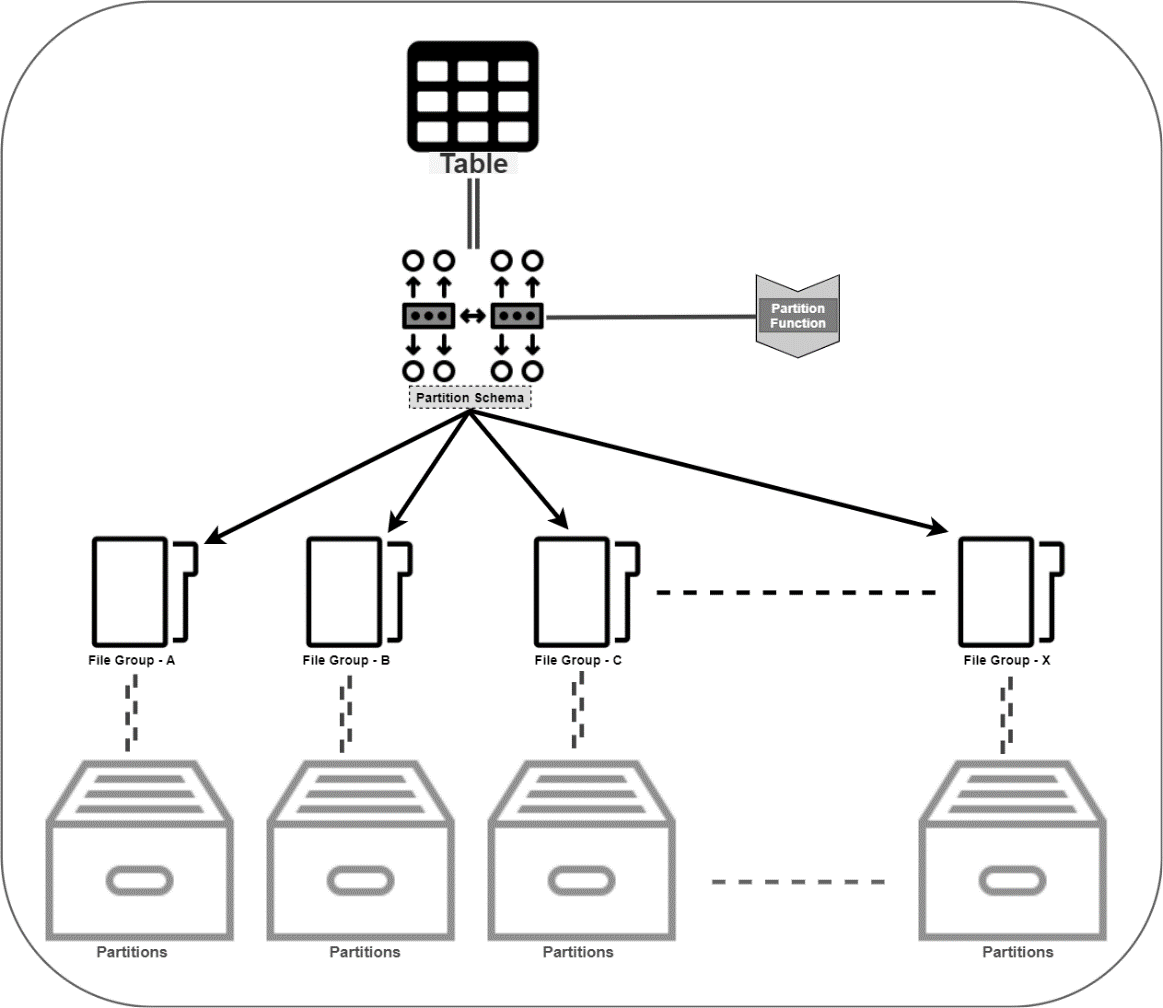
什么是SQL Server中的表分区? 为什么在SQL Server中需要分区? (What is Table Partitioning in SQL Server? Why is partitioning required in SQL Server?)
Table Partition is the logical division of information with the physical distribution in the filegroups. A table can be partitioned by applying the partition schema over the table schema. The role of the partition function is to divide the information in a logical division by partition range and partition scheme indexing the partition range to the filegroup. After applying the partition on the table, rows of the table will be distributed in different secondary files by the filegroup.
表分区是信息的逻辑划分,其中文件组具有物理分布。 可以通过在表架构上应用分区架构来对表进行分区。 分区功能的作用是按分区范围和将分区范围索引到文件组的分区方案按逻辑划分信息。 在表上应用分区之后,表的行将由文件组分布在不同的辅助文件中。
Day by day density of the information is increasing more and more, and the database size increases with storing more and more pieces of information. Ideally, companies maintain several databases for the product to generate a query result set from multiple tables to fulfill the business requirements. With the increase in the size of databases, table performance becomes slower for the client queries. But, proper indexes and index maintenance will exist in the database, but at last, records will be scanned out from the broad set of the index pointer value. What can the user do more? And How?
信息的密度日益增加,并且随着存储越来越多的信息,数据库的大小也随之增加。 理想情况下,公司为产品维护几个数据库,以从多个表中生成查询结果集,以满足业务需求。 随着数据库大小的增加,客户端查询的表性能会降低。 但是,适当的索引和索引维护将存在于数据库中,但是最后,将从广泛的索引指针值集中扫描出记录。 用户还能做些什么? 如何?
Partition is one of the beneficial approaches for query performance over the large table. Table Index will be a part of each partition in SQL Server to return a quick query response. Actual partition performance will be achieved when you use a query with the partition column because the partition column will target those partitions only, which are required by the partition column. It wouldn’t scan the information in all filegroups.
分区是提高大表查询性能的有益方法之一。 表索引将成为SQL Server中每个分区的一部分,以返回快速查询响应。 当您对分区列使用查询时,将实现实际的分区性能,因为分区列将仅定位分区列所要求的那些分区。 它不会扫描所有文件组中的信息。
Partitioning in SQL Server divides the information into the smaller storage groups; It is about table data and indexes. Partition function can be used with the table column when a table creates. A partition can be defined with the name and its storage attributes. Let’s have a sample partition before setting up an automated task on table partitioning in SQL Server.
SQL Server中的分区将信息分为较小的存储组。 它与表数据和索引有关。 创建表时,分区函数可与表列一起使用。 可以使用名称及其存储属性来定义分区。 在对SQL Server中的表分区设置自动化任务之前,让我们先进行一个示例分区。
SQL Server中的表分区–分步 (Table Partitioning in SQL Server – Step by Step)
Partitioning in SQL Server task is divided into four steps:
在SQL Server中进行分区任务分为四个步骤:
- Create a File Group 创建一个文件组
- Add Files to File Group 将文件添加到文件组
- Create a Partition Function with Ranges 创建具有范围的分区函数
- Create a Partition Schema with File Groups 创建具有文件组的分区架构
创建示例数据库以在SQL Server中执行表分区: (Creating a sample database to perform Table Partitioning in SQL Server:)
CREATE DATABASE AutoPartition
Adding File Groups to the database:
将文件组添加到数据库:
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_01_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_02_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_03_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_04_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_05_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_06_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_07_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_08_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_09_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_10_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_11_2020
GO
ALTER DATABASE AutoPartition
ADD FILEGROUP FG_12_2020
GO
Here, we are going to set up a month-wise partition for the table. So, initially, we are creating 12 File Groups for the year 2020.
在这里,我们将为该表设置按月分区。 因此,最初,我们将为2020年创建12个文件组。
将文件添加到每个文件组 (Adding Files to each File Group)
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_012020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_012020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_01_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_022020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_022020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_02_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_032020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_032020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_03_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_042020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_042020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_04_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_052020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_052020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_05_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_062020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_062020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_06_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_072020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_072020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_07_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_082020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_082020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_08_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_092020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_092020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_09_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_102020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_102020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_10_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_112020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_112020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_11_2020
GO
ALTER DATABASE AutoPartition
ADD FILE
(
NAME = [File_122020],
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\File_122020.ndf',
SIZE = 5 MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 10 MB
) TO FILEGROUP FG_12_2020
GO
Here, adding one file to each filegroup for data distribution to the physical storage to perform the table partitioning in SQL Server. If you have crores of row per day, then you can add multiple files to the single file group as well, and data will be distributed to the number of files in the filegroup.
在此,向每个文件组添加一个文件,以将数据分配到物理存储,以在SQL Server中执行表分区。 如果您每天有成千上万的行,那么您也可以将多个文件添加到单个文件组,并且数据将分配到该文件组中的文件数。
在月份范围内添加分区函数 (Adding a Partition Function with Month wise range)
USE AutoPartition
GO
CREATE PARTITION FUNCTION [PF_MonthlyPartition] (DATETIME)
AS RANGE RIGHT FOR VALUES
(
'2020-01-31 23:59:59.997', '2020-02-29 23:59:59.997', '2020-03-31 23:59:59.997',
'2020-04-30 23:59:59.997', '2020-05-31 23:59:59.997', '2020-06-30 23:59:59.997',
'2020-07-31 23:59:59.997', '2020-08-31 23:59:59.997', '2020-09-30 23:59:59.997',
'2020-10-31 23:59:59.997', '2020-11-30 23:59:59.997', '2020-12-31 23:59:59.997'
);
Here, 12 ranges are defined with the last day of the month and last ms of the day. Users can use the month and year combination as well to perform the table partitioning in SQL Server. But I would recommend to define it with full datetime to perform insert operations quickly. In the above sample code, the partition function is defined with the Right direction.
此处,使用每月的最后一天和一天的最后ms定义12个范围。 用户还可以使用月份和年份的组合来在SQL Server中执行表分区。 但是我建议使用完整的日期时间对其进行定义,以快速执行插入操作。 在上面的示例代码中,分区函数是用“向右”方向定义的。
将具有文件组的分区方案添加到分区功能 (Adding a Partition Scheme with File Groups to the Partition Function)
USE AutoPartition
GO
CREATE PARTITION SCHEME PS_MonthWise
AS PARTITION PF_MonthlyPartition
TO
(
'FG_01_2020', 'FG_02_2020', 'FG_03_2020',
'FG_04_2020', 'FG_05_2020', 'FG_06_2020',
'FG_07_2020', 'FG_08_2020', 'FG_09_2020',
'FG_10_2020', 'FG_11_2020', 'FG_12_2020',
'Primary'
);
通过附加分区功能将文件组添加到分区架构 (Adding a filegroup to the partition schema with attaching the partition function)
Here, the Primary filegroup is an additional filegroup in the partition scheme definition. The primary filegroup is used to store those rows which are exceeding the partition range in the function. It works when users forget to add new ranges and new filegroups with the file.
在这里,主文件组是分区方案定义中的另一个文件组。 主文件组用于存储功能中超出分区范围的那些行。 当用户忘记为文件添加新范围和新文件组时,它可以工作。
使用分区方案创建表 (Creating a Table with the Partition Scheme)
USE AutoPartition
GO
CREATE TABLE orders
(
[order_id] BIGINT IDENTITY(1,1) NOT NULL,
[user_id] BIGINT,
[order_amt] DECIMAL(10,2),
[address_id] BIGINT,
[status_id] TINYINT,
[is_active] BIT,
[order_date] [datetime]
) ON PS_MonthWise ([order_date]);
GO
CREATE CLUSTERED INDEX CI_orders_order_id ON orders(order_id)
GO
CREATE NONCLUSTERED INDEX IX_user_id ON orders(user_id)
GO
Here, the table is defined with applying the Partition to the column [order_date] of table orders.
在此,表是用施加分区以表订单的柱[order_date的]中定义。
将数据插入表[顺序] (Inserting data into Table [orders])
INSERT INTO orders (user_id, order_amt, address_id, status_id, is_active, order_date)
VALUES
(43, 1623.78, 51, 1, 1, '2020-01-14 13:21:51.869'),
(51, 8963.17, 43, 1, 1, '2020-02-17 05:07:43.193'),
(27, 7416.93, 66, 1, 1, '2020-03-21 07:53:07.743'),
(58, 9371.54, 45, 1, 1, '2020-04-26 16:19:27.852'),
(53, 8541.56, 65, 1, 1, '2020-05-08 19:21:58.654'),
(98, 6971.85, 54, 1, 1, '2020-06-17 21:34:52.426'),
(69, 5217.74, 78, 1, 1, '2020-07-03 07:37:51.391'),
(21, 9674.14, 98, 1, 1, '2020-08-27 23:49:53.813'),
(52, 1539.96, 32, 1, 1, '2020-09-01 17:17:07.317'),
(17, 7193.63, 21, 1, 1, '2020-10-23 10:23:37.307'),
(68, 3971.25, 19, 1, 1, '2020-11-30 09:01:27.079'),
(97, 5973.58, 97, 1, 1, '2020-12-06 13:43:21.190'),
(76, 4163.95, 76, 1, 1, '2021-01-03 18:51:17.764')
GO
We have inserted sample rows with each partition range of the partition function. Now let’s check how many rows exist with partition and its filegroups.
我们在分区函数的每个分区范围内插入了示例行。 现在,让我们检查分区及其文件组中存在多少行。
分区明细和行数 (Partition details with Row count)
Below are the DMVs that return the number of rows that exist in the filegroup with partition range.
以下是DMV,它们返回具有分区范围的文件组中存在的行数。
SELECT DISTINCT o.name as table_name, rv.value as partition_range, fg.name as file_groupName, p.partition_number, p.rows as number_of_rows
FROM sys.partitions p
INNER JOIN sys.indexes i ON p.object_id = i.object_id AND p.index_id = i.index_id
INNER JOIN sys.objects o ON p.object_id = o.object_id
INNER JOIN sys.system_internals_allocation_units au ON p.partition_id = au.container_id
INNER JOIN sys.partition_schemes ps ON ps.data_space_id = i.data_space_id
INNER JOIN sys.partition_functions f ON f.function_id = ps.function_id
INNER JOIN sys.destination_data_spaces dds ON dds.partition_scheme_id = ps.data_space_id AND dds.destination_id = p.partition_number
INNER JOIN sys.filegroups fg ON dds.data_space_id = fg.data_space_id
LEFT OUTER JOIN sys.partition_range_values rv ON f.function_id = rv.function_id AND p.partition_number = rv.boundary_id
WHERE o.object_id = OBJECT_ID('orders');
Here, the partition range was not defined for January 2021. But we added the last file group with the Primary. Therefore, if rows are exceeding the range, then those will be allocated to the primary filegroup.
在这里,未定义2021年1月的分区范围。但是,我们在最后一个文件组中添加了Primary。 因此,如果行超出了范围,则将这些行分配给主文件组。
具有分区号的表行 (Table Rows with Partition Number)
Users can find the partition number with each row of the table as well. Users can bifurcate the row allocation to the logical partition number with the help of a $PARTITION() function.
用户还可以在表的每一行中找到分区号。 用户可以借助$ PARTITION()函数将行分配分为逻辑分区号。
SELECT $PARTITION.PF_MonthlyPartition(order_date) AS PartitionNumber, *
FROM orders
自动化分区流程 (Automate the Partition flow)
We have explained the above examples to understand the requirement of post activities and maintenance on the partition function. A primary filegroup is defined to manage those rows which are out of the partition range. However, the database team has to monitor that the range of any partition function is ending or not? To avoid some manual tasks, users can set up the SQL Server job to perform it automatically.
我们已经解释了以上示例,以了解发布活动和对分区功能进行维护的要求。 定义了一个主文件组来管理那些不在分区范围内的行。 但是,数据库团队必须监视任何分区功能的范围是否结束? 为了避免执行某些手动任务,用户可以将SQL Server作业设置为自动执行。
SQL Server job will be executed in a pre-defined scheduled time (monthly or weekly) and helps to find out the partition functions which are needed to be maintained. In the above sample, we used the DATETIME column type for the partition range. Users can write a program with T-SQL statements as below:
SQL Server作业将在预定义的计划时间(每月或每周)中执行,并有助于找出需要维护的分区功能。 在上面的示例中,我们将DATETIME列类型用于分区范围。 用户可以使用T-SQL语句编写程序,如下所示:
Find the Partition Function whose range does not exist for the next month. For example, in the above example, partition range is defined till Dec 2020, and a current timestamp is 2020-12-27 16:27:09.500. After three days, the partition range will be exceeded because the maximum range is 2020-12-31 23:59:59.997 for the order table. Now, we will find the partition functions which are required to be maintained using the below T-SQL.
查找下个月不存在范围的分区函数。 例如,在上面的示例中,分区范围定义为直到2020年12月,并且当前时间戳为2020-12-27 16:27:09.500。 三天后,将超出分区范围,因为订单表的最大范围是2020-12-31 23:59:59.997。 现在,我们将找到需要使用以下T-SQL维护的分区功能。
SELECT o.name as table_name,
pf.name as PartitionFunction,
ps.name as PartitionScheme,
MAX(rv.value) AS LastPartitionRange,
CASE WHEN MAX(rv.value) <= DATEADD(MONTH, 2, GETDATE()) THEN 1 else 0 END AS isRequiredMaintenance
--INTO #temp
FROM sys.partitions p
INNER JOIN sys.indexes i ON p.object_id = i.object_id AND p.index_id = i.index_id
INNER JOIN sys.objects o ON p.object_id = o.object_id
INNER JOIN sys.system_internals_allocation_units au ON p.partition_id = au.container_id
INNER JOIN sys.partition_schemes ps ON ps.data_space_id = i.data_space_id
INNER JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
INNER JOIN sys.partition_range_values rv ON pf.function_id = rv.function_id AND p.partition_number = rv.boundary_id
GROUP BY o.name, pf.name, ps.name

Here, the above result set returned the partition function (PF_MonthlyPartition) for adding the new range.
在这里,上述结果集返回了用于添加新范围的分区函数( PF_MonthlyPartition) 。
The following code helps to insert information to the new temp table for those partition functions that are required to SPLIT.
以下代码有助于将信息插入到新的临时表中,以获取SPLIT所需的那些分区功能。
SELECT table_name,
PartitionFunction,
PartitionScheme,
LastPartitionRange,
CONVERT(VARCHAR, DATEADD(MONTH, 1, LastPartitionRange), 25) AS NewRange,
'FG_' + CAST(FORMAT(DATEADD(MONTH, 1, LastPartitionRange),'MM') AS VARCHAR(2)) +
'_' +
CAST(YEAR(DATEADD(MONTH, 1, LastPartitionRange)) AS VARCHAR(4)) AS NewFileGroup,
'File_'+ CAST(FORMAT(DATEADD(MONTH, 1, LastPartitionRange),'MM') AS VARCHAR(2)) +
CAST(YEAR(DATEADD(MONTH, 1, LastPartitionRange)) AS VARCHAR(4)) AS FileName,
'C:\Program Files\Microsoft SQL Server\MSSQL13.JRAIYANI\MSSQL\DATA\' AS file_path
INTO #generateScript
FROM #temp
WHERE isRequiredMaintenance = 1
We can also generate a dynamic script to create File Group, File, add a new file group to partition scheme, and new range to the partition function as below:
我们还可以生成一个动态脚本来创建文件组,文件,向分区方案添加新的文件组以及为分区功能添加新的范围,如下所示:
DECLARE @filegroup NVARCHAR(MAX) = ''
DECLARE @file NVARCHAR(MAX) = ''
DECLARE @PScheme NVARCHAR(MAX) = ''
DECLARE @PFunction NVARCHAR(MAX) = ''
SELECT @filegroup = @filegroup +
CONCAT('IF NOT EXISTS(SELECT 1 FROM AutoPartition.sys.filegroups WHERE name = ''',NewFileGroup,''')
BEGIN
ALTER DATABASE AutoPartition ADD FileGroup ',NewFileGroup,'
END;'),
@file = @file + CONCAT('IF NOT EXISTS(SELECT 1 FROM AutoPartition.sys.database_files WHERE name = ''',FileName,''')
BEGIN
ALTER DATABASE AutoPartition ADD FILE
(NAME = ''',FileName,''',
FILENAME = ''',File_Path,FileName,'.ndf'',
SIZE = 5MB, MAXSIZE = UNLIMITED,
FILEGROWTH = 10MB )
TO FILEGROUP ',NewFileGroup, '
END;'),
@PScheme = @PScheme + CONCAT('ALTER PARTITION SCHEME ', PartitionScheme, ' NEXT USED ',NewFileGroup,';'),
@PFunction = @PFunction + CONCAT('ALTER PARTITION FUNCTION ', PartitionFunction, '() SPLIT RANGE (''',NewRange,''');')
FROM #generateScript
EXEC (@filegroup)
EXEC (@file)
EXEC (@PScheme)
EXEC (@PFunction)
Here, the script is generated with individual variables, and the dynamic code is executed in the sequence. We have utilized most of the static values, but users can prepare them completely dynamic too. The above snippets should be taken in a single procedure, and that procedure can be configured with the SQL Server job.
在此,脚本是使用各个变量生成的,动态代码按顺序执行。 我们已经利用了大多数静态值,但用户也可以完全动态地准备它们。 以上代码段应在单个过程中进行,并且可以使用SQL Server作业配置该过程。
结论 (Conclusion)
Adding a new range to the partition function should be an automated task always. The partition range is always depending on the row size in the partition function. Table partitioning in SQL Server is always helpful in terms of maintaining large tables.
向分区功能添加新范围应该始终是一项自动化任务。 分区范围始终取决于分区功能中的行大小。 在维护大型表方面,SQL Server中的表分区总是很有帮助的。
翻译自: https://www.sqlshack.com/how-to-automate-table-partitioning-in-sql-server/















 3152
3152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









