





Some of my previous articles on Python provided insight of the basics and the usage of Python in SQL Server 2017.
我之前有关Python的一些文章提供了有关SQL Server 2017中Python的基础知识和用法的见解。
- Why would a SQL Server DBA be interested in Python 为什么SQL Server DBA对Python感兴趣
- An overview of Python vs PowerShell for SQL Server Database Administration 适用于SQL Server数据库管理的Python与PowerShell概述
- Data Interpolation and Transformation using Python in SQL Server 2017 在SQL Server 2017中使用Python进行数据插值和转换
This article is an effort to collect all the missing pieces and try to showcase the importance of using Python programming in SQL Server.
本文旨在收集所有遗漏的内容,并尝试展示在SQL Server中使用Python编程的重要性。
Many say that PowerShell has the upper hand over Python in some aspects of the database administration. I too am under the same impression as many technical enthusiasts, but with very limited knowledge, we can also see the power of Python. Perhaps, instead of pitting PowerShell and Python against each other, we can look at them as complementing technologies.
许多人说,PowerShell在数据库管理的某些方面胜过Python。 我对许多技术爱好者也有相同的印象,但是由于知识有限,我们还可以看到Python的强大功能。 也许,我们可以将它们视为补充技术,而不是使PowerShell和Python相互抵触。
In 2016, R, the statistical computing programming language was integrated with the SQL Server version, named for the same year. The other side of the coin was missing since Python is also a leading machine learning language and even having a large user base. In SQL Server 2017, Python is integrated. Now, R and Python are under the same umbrella of the feature called machine learning services.
2016年,R,统计计算编程语言与同年命名SQL Server版本集成在一起。 硬币的另一面不见了,因为Python还是一种领先的机器学习语言,甚至拥有庞大的用户群。 在SQL Server 2017中,集成了Python。 现在,R和Python在称为机器学习服务的功能的同一保护下。
As Python is being a common programming language adopted by data scientists and database administrators, the ability to run Python code as T-SQL script enables the machine learning capabilities, directly when it comes to dealing with large amounts of data. First, data no longer needs to be extracted from the database before it can be processed through a client program. This provides us with significant benefits in terms of security, integrity, and compliance that arise when data is otherwise moved outside of the highly controlled environment within the database engine. Further, computations are performed on the server itself without having to first transfer the data to a client, thereby placing a large load on network traffic. This also means that you can perform computations across the entire dataset without having to take representative samples as is common when processing data on a separate machine. And because the data stays in place, you can take full advantage of the performance benefits brought by SQL Server technologies such as in-memory tables and column-store indexes. Python code is also very easy to deploy and can be written directly inside of any Transact-SQL command.
由于Python是数据科学家和数据库管理员采用的通用编程语言,因此将Python代码作为T-SQL脚本运行的功能可直接在处理大量数据时启用机器学习功能。 首先,在可以通过客户端程序处理数据之前,不再需要从数据库中提取数据。 这在数据安全性,完整性和合规性方面为我们提供了显着的好处,否则这些数据会从数据库引擎内的高度受控环境中移出。 此外,无需先将数据传输到客户端即可在服务器本身上执行计算,从而给网络流量带来很大负担。 这也意味着您可以在整个数据集上执行计算,而不必像在单独的计算机上处理数据时那样获取代表性样本。 并且由于数据保持原样,因此您可以充分利用SQL Server技术带来的性能优势,例如内存表和列存储索引。 Python代码也非常易于部署,可以直接在任何Transact-SQL命令中编写。
Next, SQL Server 2017 supports the installation of any Python packages that we might need so you can build on top of the extensive collection of open source capabilities that have been developed by the wider Python community. And finally, Python integration is available in every edition of SQL Server 2017, even the free-to-use Express edition. So, no matter the scale of your application, you can take advantage of Python integration.
接下来,SQL Server 2017支持安装我们可能需要的任何Python软件包,因此您可以在更广泛的Python社区已经开发的大量开源功能的基础上构建。 最后,在SQL Server 2017的每个版本中都可以使用Python集成,甚至可以免费使用Express版本。 因此,无论您的应用程序规模如何,都可以利用Python集成。
To get you started, SQL Server 2017 includes a number of libraries from Anaconda, a very popular data science platform. In addition to that, Microsoft has created two libraries that are installed with Machine Learning Services.
为使您入门,SQL Server 2017包含许多来自Anaconda的库, Anaconda是一个非常流行的数据科学平台。 除此之外,Microsoft还创建了两个随机器学习服务一起安装的库。
- Revoscalepy 反比例
Revoscalepy is a library of functions that supports distributed computing, remote compute contexts, and high performance algorithms
Revoscalepy是一个功能库,支持分布式计算,远程计算上下文和高性能算法
- Microsoftml 微软
The Microsoftml library contains functions for machine learning algorithms including the creation of linear models, decision trees, logistic regression, neural networks, and anomaly detection.
Microsoftml库包含用于机器学习算法的功能,包括创建线性模型,决策树,逻辑回归,神经网络和异常检测。
让我们开始 (Let’s begin)
The traditional ways of analysis within SQL Server using various Microsoft components such as SQL, MDX, DAX in PowerPivot gives the flexibility to transform data. Now, the R language, another rich superset of machine learning modules for data analytics is directly integrated with SQL Server 2016. R is another language which has a large user base, along with Python. With the available modules in Python, data analysis becomes more efficient and effective.
使用PowerPivot中的各种Microsoft组件(例如SQL,MDX,DAX)在SQL Server中进行传统分析的方式可以灵活地转换数据。 现在,R语言是用于数据分析的另一种丰富的机器学习模块超集,直接与SQL Server 2016集成。R是另一种语言,具有庞大的用户群以及Python。 使用Python中的可用模块,数据分析变得更加高效。
Let me take you through a few examples to prove that the use of Python within SQL Server is an efficient way to pull data from remote servers.
让我通过几个示例来证明SQL Server中使用Python是从远程服务器提取数据的有效方法。
- See how to connect to a SQL Server data source using pyodbc 了解如何使用pyodbc连接到SQL Server数据源
- Execute the SQL query, in this case build the connecting string which points to remote SQL instance and execute the Dynamic Management View query sys.dm_os_waitstas 执行SQL查询,在这种情况下,构建指向远程SQL实例的连接字符串,并执行动态管理视图查询sys.dm_os_waitstas
- Assign the SQL output to the data frames 将SQL输出分配给数据框
The head command is used to display the first ‘n’ rows of the dataframe. This is just like the top command of the SQL Server. The first column (showing 0 to 9) is the default index for the dataframe
head命令用于显示数据帧的前“ n”行。 这就像SQL Server的top命令一样。 第一列(显示0到9)是数据框的默认索引- In order to convert the dataframe data into related SQL columns, the WITH RESULTS SET clause is defined at the end of the code. This gives us the flexibility to define the column and associated types of each column. 为了将数据帧数据转换为相关SQL列,在代码末尾定义了WITH RESULTS SET子句。 这使我们可以灵活地定义列和每个列的关联类型。
- WITH RESULT SETS requires that the number of columns in the result definition must be equal to the number of columns returned by the stored procedure/SQL query. In the following examples, the output of the SQL query returns four columns: servername, waiting_type, waiting_tasks_count, wait_time_ms. These match the definition of the with result sets clause. WITH RESULT SETS要求结果定义中的列数必须等于存储过程/ SQL查询返回的列数。 在以下示例中,SQL查询的输出返回四列:服务器名,waiting_type,waiting_tasks_count,wait_time_ms。 这些匹配with结果集子句的定义。
EXEC sp_execute_external_script
@language = N'python',
@script =
N'import pyodbc
import pandas as pd
connection = pyodbc.connect(''DRIVER={ODBC Driver 13 for SQL Server};SERVER=hqdbsp18;UID=sa;PWD=api1401'')
cursor = connection.cursor()
query = ''SELECT wait_type,waiting_tasks_count,wait_time_ms FROM sys.dm_os_wait_stats''
df = pd.read_sql(query,connection)
print(df.head(5))
connection.close()
'
The above SQL query output can also be returned as a SQL table using with result clause.
上面SQL查询输出也可以使用with result子句作为SQL表返回。
EXEC sp_execute_external_script
@language = N'python',
@script =
N'import pyodbc
import pandas as pa
connection = pyodbc.connect(''DRIVER={ODBC Driver 13 for SQL Server};SERVER=hqdbsp18;UID=sa;PWD=sqlshackai1401'')
query = ''SELECT @@servername,wait_type,waiting_tasks_count,wait_time_ms FROM sys.dm_os_wait_stats''
pa.read_sql(query,connection)
OutputDataSet = pa.read_sql(query,connection)
'
WITH RESULT SETS((servername varchar(20),waiting_Type varchar(256), waiting_tasks_count bigint, wait_time_ms decimal(20,5)))
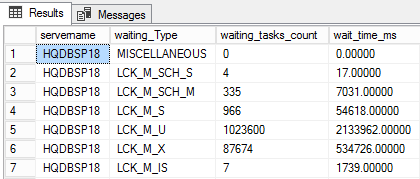
Let us look at an example to push the sample data into the table. The following SQL query sample yields the database internal information, printed as a string output.
让我们看一个将样本数据推送到表中的示例。 下面SQL查询示例将产生数据库内部信息,并以字符串输出形式输出。
EXEC sp_execute_external_script
@language = N'Python'
, @script = N'import pyodbc
import pandas as pa
with open("f:\PowerSQL\server.txt", "r") as infile :
lines = infile.read().splitlines()
for line in lines:
server = line
print(server)
database = "Master"
cnxn = pyodbc.connect("DRIVER={ODBC Driver 13 for SQL Server};SERVER="+server+";PORT=1443;DATABASE="+database+";UID=sa;PWD=api1401")
tsql = """
SELECT
@@SERVERNAME serverName,
CONVERT(VARCHAR(25), DB.name) AS DatabaseName,
(SELECT count(1) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0) AS [DataFiles],
(SELECT cast(SUM((size*8)/1024) as decimal(10,2)) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0) AS [DataMB],
(SELECT count(1) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) AS [LogMB],
(SELECT cast(SUM((size*8)/1024) as decimal(10,2)) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) AS [LogMB]
FROM sys.databases DB
ORDER BY DatabaseName"""
print(pa.read_sql(tsql,cnxn))'
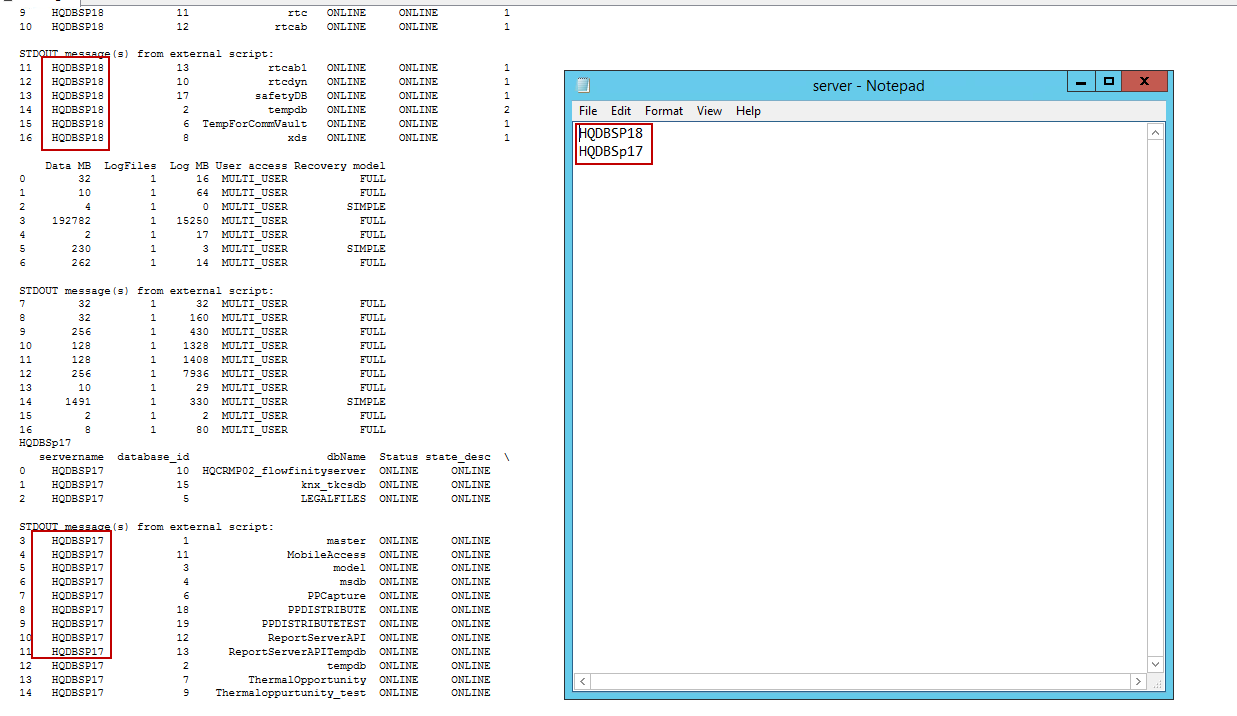
The following SQL creates a demo table on the target instance. SQLShackDemoDB is the name of the target database.
以下SQL在目标实例上创建一个演示表。 SQLShackDemoDB是目标数据库的名称。
USE [SQLShackDemoDB]
GO
CREATE TABLE [dbo].[tbl_databaseInventory](
[ServerName] [varchar](100) NOT NULL,
[databaseName] [varchar](25) NULL,
[DataFiles] [int] NULL,
[DataMB] [int] NULL,
[LogFiles] [int] NULL,
[LogMB] [int] NULL
) ON [PRIMARY]
GO
The stored procedure named P_SampleDBInventory_Python is created with two connections.
使用两个连接创建名为P_SampleDBInventory_Python的存储过程。
- pyodbc Python module for data connectivity pyodbc Python模块进行数据连接
- Build the target connection string. It includes the destination object details such as target instance, database and table 生成目标连接字符串。 它包含目标对象的详细信息,例如目标实例,数据库和表
For the target connection string,
对于目标连接字符串,
- Open the cursor 打开游标
- The second connection string is built using a file. The file is the source of the input server names. The query should traverse across the lists to generate the data sets. Then the dataset is traversed to pull the column details in the destination using the target connection string 第二个连接字符串是使用文件构建的。 该文件是输入服务器名称的来源。 该查询应遍历列表以生成数据集。 然后遍历数据集以使用目标连接字符串在目标中提取列详细信息
- Build the SQL statement using triple quotation marks. The triple quotes are used to build regular strings that can span into multiple lines 使用三引号生成SQL语句。 三重引号用于构建可以跨越多行的常规字符串
- The SQL statement is executed using the defined cursor 使用定义的游标执行SQL语句
- Results are loaded into the destination table 结果被加载到目标表中
EXEC P_SampleDBInventory_Python- Verify the SQL Output 验证SQL输出
CREATE Procedure P_SampleDBInventory_Python
AS
EXEC sp_execute_external_script
@language = N'Python'
, @script = N'
import pyodbc
import pandas as pa
Instance = ''HQBT01''
Database = ''SQLShackDemoDB''
uname = ''thanVitha2017''
pwd = ''thanVitha2017401$''
conn1 = pyodbc.connect(''DRIVER={ODBC Driver 13 for SQL Server};SERVER=''+Instance+'';PORT=1443;DATABASE=''+Database+'';UID=''+uname+'';PWD=''+ pwd)
cur1 = conn1.cursor()
with open("f:\PowerSQL\server.txt", "r") as infile :
Input = infile.read().splitlines()
for sInput in Input:
srv = sInput
print(srv)
db = "master"
conn2 = pyodbc.connect("DRIVER={ODBC Driver 13 for SQL Server};SERVER="+srv+";PORT=1443;DATABASE="+db+";UID=sa;PWD=as21201")
cur2 = conn2.cursor()
SQL1 = """
SELECT
@@SERVERNAME serverName,
CONVERT(VARCHAR(25), DB.name) AS DatabaseName,
(SELECT count(1) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0) AS [DataFiles],
(SELECT cast(SUM((size*8)/1024) as decimal(10,2)) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0) AS [DataMB],
(SELECT count(1) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) AS [LogFiles],
(SELECT cast(SUM((size*8)/1024) as decimal(10,2)) FROM sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) AS [LogMB]
FROM sys.databases DB
ORDER BY DatabaseName;"""
with cur2.execute(SQL1):
row = cursor.fetchone()
while row:
print (str(row[0])+" "+str(row[1])+" "+str(row[2])+ " "+str(row[3])+" "+str(row[4])+" "+str(row[5]))
SQL2 = "INSERT INTO [tbl_DatabaseInventory] (ServerName, DatabaseName, DataFiles, DataMB, LogFiles, LogMB) VALUES (?,?,?,?,?,?);"
with cur1.execute(SQL2,str(row[0]),str(row[1]),row[2],row[3],row[4],row[5]):
print (''Successfuly Inserted!'')
row = cursor.fetchone()'
END
Output:
输出:
结语 (Wrapping Up)
So, there you have it. While the examples provided were fairly straightforward, I hope you can see how useful Python could be for a database administrator as well, and not just a BI or Data Scientist.
所以你有它。 尽管所提供的示例相当简单,但我希望您能看到Python对数据库管理员(而不只是BI或数据科学家)的有用性。
The real beauty is that all this code could happily sit inside a stored procedure; something that you can’t do all that well with PowerShell.
真正的美在于,所有这些代码都可以愉快地位于存储过程中; 使用PowerShell无法做到所有这些。
Python integration in SQL Server 2017 gives data scientists an easy way to interact with their data directly in the database engine and it gives developers an easy way to integrate Python models into their application through simple stored procedures.
SQL Server 2017中的Python集成为数据科学家提供了一种直接在数据库引擎中与其数据进行交互的简便方法,并且为开发人员提供了一种通过简单的存储过程将Python模型集成到其应用程序中的简便方法。
翻译自: https://www.sqlshack.com/importance-python-sql-server-administration/















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









